
信息茧房与准确率:基于复合型算法的个性化模拟推荐系统
2020-01-18 05:52严宇桥张蔚坪
电子技术与软件工程 2019年24期
文/严宇桥 张蔚坪
随着智媒时代的到来,以算法型信息分发技术渗透到了各个媒体当中。算法推送带来的收益和效果正在影响各行各业,也引起了媒介研究的兴趣。算法与传媒业的深度融合,不断形塑着传媒业的实践,同时也给传播伦理造成了相当大的影响。本文在分析算法型信息分发的主要推荐机制基础上,指出了在实际的研究中,算法推荐的准确率如何衡量的一种方法,并结合了协同过滤和文本分析两种主流推荐机制设计了基于复合型推荐算法的模拟个性化信息推荐系统。
1 算法信息分发的推荐机制综述
对于推荐系统,最重要的任务是连接信息和用户之间的关系。该系统应帮助用户找到对他们有价值的信息,同时让该信息在感兴趣的用户面前显示和推荐,从而达到信息消费与生产双赢的局面。当前,推荐系统主要有三种推荐模式:基于协同过滤的推荐,基于关联规则的推荐和基于文本的推荐。
对于协同过滤推荐来说,最基本的策略是计算用户之间的相似度,例如余弦相似度。根据相似度排序,设置相似度阈值或设置最近邻阈值,选择一定数量的用户,并让这些用户评估的产品形成候选集,对这些项目进行加权以计算分数,最后排序,向用户推荐评分最高的项目。

公式(1)余弦相似度计算方法
但是,基于内存的协同过滤推荐的问题在于它们过于依赖历史数据库。历史数据库是系统中整个推荐功能的原始资料。当缺乏数据资料时,将出现一系列的问题,诸如冷启动结果不令人满意,以及推荐的准确性降低等。
基于内容的推荐是基于用户历史项提取,过滤和生成文本信息特征模型,并最终向用户推荐类似于历史浏览文本内容的信息。该算法在提取和分析文本信息的特征方面比较擅长,但是在非结构化数据的分析能力方面存在缺陷。基于关联规则的推荐基于用户的历史资料,以挖掘用户数据背后的相关关联,从而为用户的潜在需求分析提供推荐。
综上所述,这三种方法都有一定程度的局限性,每种方法都有一些难以解决的问题。目前,商业算法处理方法使用复合推荐方法进行推荐。
2 信息茧房的争论与自变量缺失:如何从量化上评估算法推荐效果?
伴随信息量的激增和网络技术的日益普及,每个人对于关注的话题都可以自主选择。桑斯坦认为,这种技术趋势将导致“信息茧房”的问题,导致观念封闭甚至两极分化,这将造成非理性的极端主义。在传统媒体时代,媒体组织向大众传播新闻,受众意识不强。基于算法推荐的内容分发以用户的个人特征为标准在技术层面上筛选信息,并向用户推荐与其价值观,偏好和个人兴趣相匹配的信息,形成了``一千个人就有一千个哈姆雷特的''内容消费形式。近年来相关专家学者对于“信息茧房”的讨论越来越激烈。传统媒介伦理和媒介道德的鼓吹者认为,算法推送导致的用户接受信息的窄化是导致近年来群体极化的罪魁祸首,而愈演愈烈的舆论极端化事件和舆论反转现象就是他们的佐证。然而以喻国明为主要代表的技术乐观主义者则坚持称,信息偏食现象从传播现象开始时就有,并非算法推送带来的问题。
如果需要从研究方面解决目前关于“信息茧房”的争论,就需要研究“算法推荐的进步”这个变量会对用户产生何种效果。对于因果关系的证明,最有效的方法是通过实验室控制变量的实验来解决。从目前的研究中相关性研究居多而缺乏因果关系的讨论来看,这个问题还缺乏一个切实有效的研究工具。二战以来,效果研究都是心理学、传播学等主流社会科学研究的议题,因此并不缺少该问题的因变量操作工具。但是,因此人们无法将“算法推荐”这个自变量进行量化,由此来看,如何将算法推荐作出有效的量化计算,是研究该问题的关键。因此,本研究就围绕着这一问题设计了能够有效将该变量操作化的工具。
3 推荐水平评测:程序设计的理论依据及程序用途
信息推荐水平如何去测量和评价,是评测工具上的技术难点。比如,在用户数量远大于产品数量的系统上,基于协同过滤算法的用户反馈很高;否则,它很低。相关的影响因素还包括评分量表和稀疏性,以及评估数据集其他特征的目的。但是,大多数推荐系统可以使用准确性来评估推荐算法的级别。假设用户可以检查所有产品的信息,并可以根据其对产品的偏好对产品分类,则准确度可以定义为推荐算法的预测排名与用户的实际排名的接近程度。包含准确率和召回率的分类准确度指标在计算机领域应用最为广泛。其具体计算方法采用Billsusd的逻辑,Billsusd也是率先准确度与召回率引入到推荐系统的评价中的学者。
例如,整个平台中所有的产品数量为N,被推荐给用户产品的总数为Ns,其中Ns=Nrs+Nis,Nrs和Nis分别为在被推荐产品中,用户喜欢的产品数量与不喜欢的产品数量。相应地,Nrn和Nin分别为未被推荐产品中用户喜欢和不喜欢的产品数。
综上所述,准确率的计算就应当是:P=N(用户喜欢的产品数量)/N(所有向用户呈现的产品的数量)。
也就是说,对于一个算法推送式的平台,可以将个性化水平也就是准确率分解成:(准确率=用户喜好的信息条数/用户看到的信息总条数)
因此,本研究的自变量和因变量分解就是:
自变量:个性化推送的准确率
因变量:点赞数、转发数、转发情况(数量、关系等)
4 本程序的设计逻辑及用户界面
因此,本程序使用java环境进行开发,设置出可调节准确率的用户文本库。总体来说程序设计思路是:输入用户兴趣的关键词语,进行文本匹配以及协同过滤生成偏好关键词,根据关键词在微博进行搜索并爬取文本或图片信息,制作成信息库。最终用户浏览信息库文本、并利用虚拟按键统计用户的行为。在本系统中,操作信息推荐水平只需要操作:相关信息与无关信息的比例即可。
如图1,首先以python为开发语言,在以Google Crome浏览器中进行的微博搜索中嵌套了一个用户头部信息的储存机制,实现用户信息的“冷启动”。第二步是整个程序设计的关键一步,也就是基于用户个人偏好数据的挖掘和主体实验材料的生成。主体流程就是:根据兴趣标签、搜索历史、点开的链接等进行个性化特征采集,形成基于协同过滤和文本匹配的用户特征,再在全网文本上采集与该特征相符合的信息。在此之后,随机在网上采集排除掉相关特征的信息,然后二者按比例混合,生成不同准确率下根据个人兴趣爱好的可操作实验资料库。第三步是总体的实验界面。第一步测过的用户依次再次进入实验室,这次就让他们查看已经根据他们之前的用户习惯编好的资料库,然后不计时,只统计下不同比例的资料库中,被试的传播行为和传播偏向。
最后将这三个步骤统一起来,展示的界面能够查看视频和图片,并且可以实时进行关键词联想,最终整合成为一个在线测试系统呈现给被试,如图2。
经过与《被试情感倾向量表》、《批判性思维量表》等因变量研究工具结合,本系统已经得到验证可以平稳进行并准确记录行为数据。该系统可以通过控制推荐信息的准确率,来将算法推荐水平做出量化操作,可以以此为自变量观测用户的行为数据、认知数据和用户态度的改变等。同时该系统可以对接大多数心理学和用户体验量表,使得研究者能够在实验室环境测量算法推荐的准确率造成的用户效果上的影响,从而为解决技术伦理层面争论多年的“信息茧房”命题提供了一种可用的研究工具。

图1:程序设计逻辑示意图
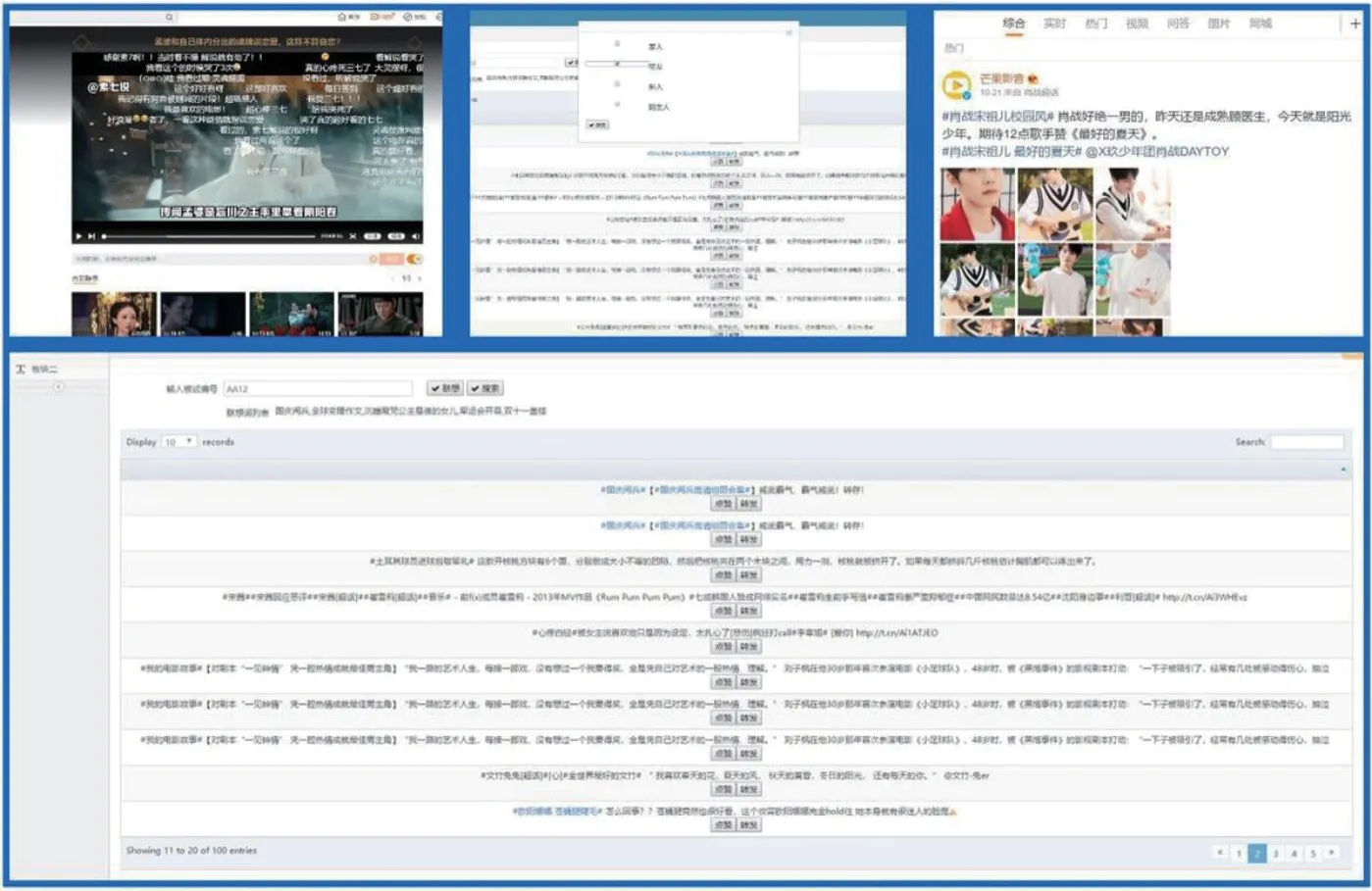
图2:用户界面与操作设计
猜你喜欢
青年文摘(彩版)(2023年7期)2023-11-21
知音·上半月(2022年5期)2022-05-12
医学食疗与健康(2021年27期)2021-05-13
科学大观园(2020年17期)2020-09-02
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
中国交通信息化(2018年5期)2018-08-21
小学教学参考(2015年20期)2016-01-15
语文知识(2014年1期)2014-02-28
