
基于多尺度特征的条形码快速检测算法
2020-02-08 04:11李功燕许绍云
计算机工程与设计 2020年1期
易 帆,李功燕,许绍云
(1.中国科学院微电子研究所 智能制造电子研发中心,北京 100029;2.中国科学院大学 电子电气与通信工程学院,北京 100049)
0 引 言
目前,国内外电商和快递业务迅速发展,包裹快件量呈倍数增长,市场对于物流快递包裹的分拣效率和准确率提出更高的要求。条形码检测定位的方法多是基于传统图像算法,文献[1]采用提取条形码边缘纹理特征信息的方法,文献[2]借助形态学处理算法腐蚀膨胀获得条形码区域,文献[3]采用霍夫变换算法检测条形码边缘直线,文献[4]采用区域检测算法得到条形码候选区域等。一般地,这些算法仅在特定物理环境下具有较好的检测效果。然而,现实中,在物流包裹自动分拣场景下,由于光照条件、现场环境等影响,采集到的图片质量参差不齐,比如光照变化剧烈、背景干扰复杂、条形码扭曲形变、条形码目标小等容易造成误检和漏检,导致条形码检测难度提升。因此,研究高可靠、强稳定的条码检测定位方法,对实现复杂环境下物流包裹的高效自动分拣具有重要意义。
近年来,深度学习的迅速崛起促进了图像研究领域更进一步的发展,相比于传统图像算法需要手工设计特征,深度学习算法可通过自学习提取相关特征,并能将特征提取、筛选、分类等任务融合在一个网络中进行优化,具备显著优势。特别地,卷积神经网络(convolutional neural network,CNN)[5]针对图像识别、图像理解、目标检测、语义分割等任务实现了远超传统图像算法的解决功能,并且凭借良好的鲁棒性能够适用于任何场景任务。本文将借鉴CNN的思想,针对条形码检测问题,设计快速有效的算法以达到实际运用场景的需求。
1 基于卷积神经网络的条形码检测分析
当前,基于卷积神经网络的目标检测模型主要分为两种:一种是以Faster-Rcnn[6]为代表的基于候选区域的two-stage检测器,其原理是先使用深度卷积神经网络来获取图片的特征图,再将特征图通过区域提议网络(region proposal network,RPN)生成候选区域,并结合分类器、边界回归器以及非极大值抑制算法等对候选区域进行分类和调整,进而获取有效目标;另一种是以YOLO[7]和SSD[8]为代表的基于回归的one-stage检测器,如图1所示,主要原理是选取输出层或者中间层的特征图直接进行分类和坐标回归。与two-stage检测器不同,基于回归的one-stage检测器省略了区域提议网络生成候选区域过程,直接将目标识别和目标判定融合在一起,较大程度节省了计算成本和时间消耗,对实现实时的端到端的目标检测具有重要作用。
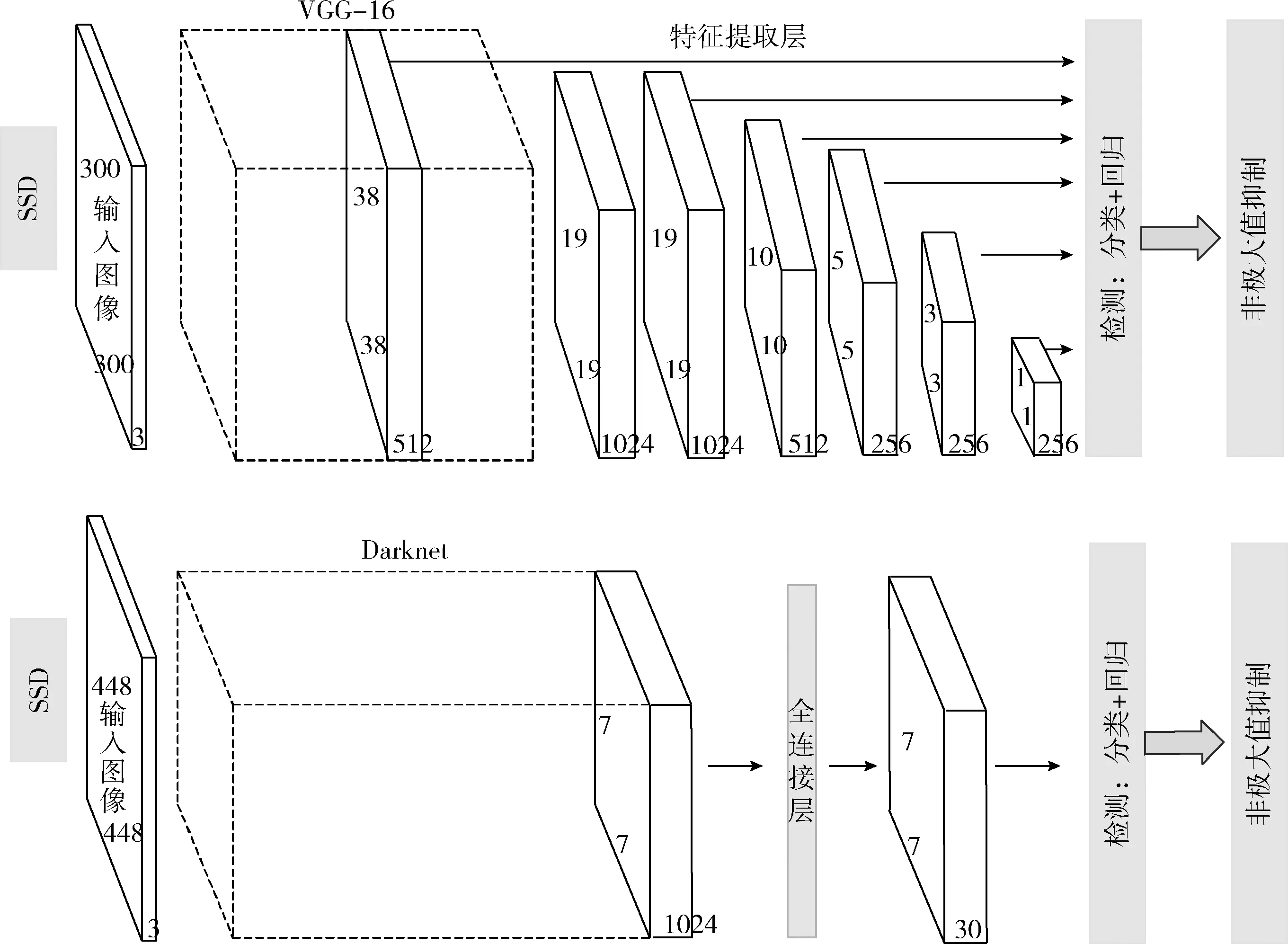
图1 YOLO和SSD结构
通常,目标检测中的公共数据集如coco、imagenet等拥有多类别、相对大尺寸的检测对象。而在物流包裹分拣系统场景中,检测对象条形码类别相对单一且占整张图片尺寸的比例偏小,如图2所示。本文采用聚类统计方法对现场采集的15 000多张图片进行了分析,得到条形码尺寸占比整张图片大小多集中在1/20~1/8之间。对于以公共数据集为基础设计的YOLO和SSD等模型结构存在冗余性,并不能针对性地解决条形码小目标快速检测问题,本文将结合条形码特征对现有检测模型进行设计和改进,构建一种快速、准确、鲁棒性高的条形码检测算法。

图2 包裹分拣现场条形码图片
2 级联多尺度特征融合网络模型
根据包裹分拣的特殊场景和待检测目标条形码的特殊性,以one-stage检测器作为基础框架,设计一种轻量化的级联多尺度特征融合网络,直接通过卷积提取特征、分类回归定位条形码。模型结构如图3所示,其中特征提取部分主要包括两个网络:特征缩减网络、特征保持网络。特征缩减网络主要实现特征图尺寸缩减和特征信息提取;特征保持网络则在维持特征图大小不变前提下进一步对特征语意信息融合。检测部分由分类器和回归器组成,对前述得到的特征图进行坐标回归,进而得到目标的检测框。
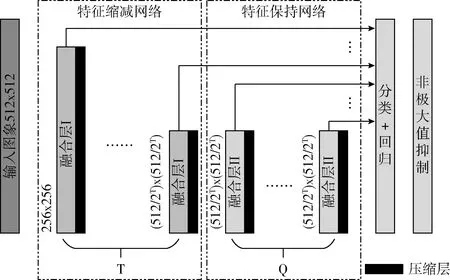
图3 级联多尺度特征融合网络
2.1 针对条形码目标的anchor设置
在目标检测中,anchor为预设锚框,合理设置anchor的类型对于后期准确检测到目标有着重要作用。anchor类型的设置主要是调节两类超参数,即长宽比R和面积大小S。在常见的目标检测模型如YOLO和SSD中,anchor类型的典型值S为{642,1282,2562},R为{1∶1,1∶2,2∶1}。而由第1节条形码尺寸分析知,条形码尺寸占比小并且考虑到有倾斜情况,因此将集合S设置为{322,482,642,802,962},R集合设置为{1∶1,1∶2,1∶3,1∶4,4∶1,3∶1,2∶1,1∶1}。这样anchor能够覆盖条形码数据集中所有条形码的尺寸范围,可有效提升最后检测条形码的准确率。
2.2 特征缩减网络
卷积神经网络与人脑视觉神经类似,通过多个卷积层进行特征提取。浅层的卷积神经网络输出特征图较大,小目标特征能够得到保留,但缺点是语义信息不够充分;随着卷积神经网络的不断加深,卷积层提取的特征更加抽象,但也带来特征图的缩减,极易导致小目标特征消失。本文的条形码检测属于小目标检测,为了有效提高检测结果的精确性,设计一种多尺度特征融合层I,通过融合不同层次尺度的语义信息增强条形码特征,如图4所示。此模块由3个3×3卷积层组成,区别于一般卷积神经网络通过最大值池化降低特征图尺寸而导致特征信息损失严重,本模块全部通过设置步长(stride)为2的3×3卷积来达到特征图缩减的效果,并进一步提取整合特征语意信息。融合层I的输出由这3个卷积之后的特征图进行拼接(concat)而得,通过转置卷积(Deconvolution)上采样第二个和第三个3×3卷积层来调整特征图尺寸大小相同,进而完成拼接。这样,特征图的尺寸每经过一个多尺度特征融合层I被降采样2倍,重复叠加多个则会使得特征图尺寸迅速下降。为了保证在一系列的降采样下条形码的特征点不会消失,设定特征融合模块的数量为T=4,即级联4个多尺度特征融合层I,使得最后一层特征图降采样为输入图像的1/16,从而在充分提取语义信息的同时尽可能地保持条形码特征的完整性。
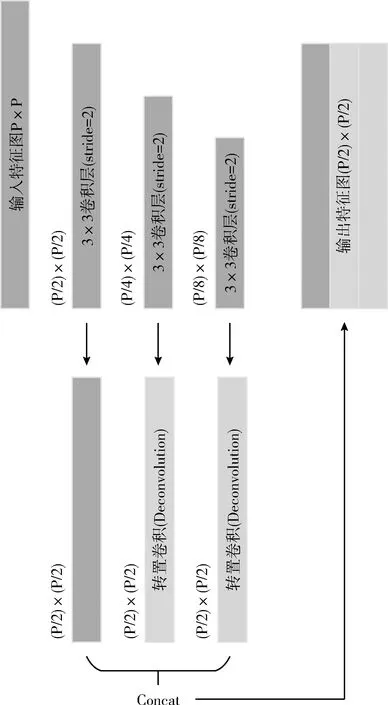
图4 特征融合层I的结构
2.3 特征保持网络
在特征缩减网络中,由于特征图尺寸限制而只设置了有限个特征融合层I,为更进一步提取语义信息特征,考虑在特征缩减网络之后设计加入特征融合层II,在特征融合层I的基础上对特征图语义信息进行深层次的提取。特征融合层II的结构如图5所示,主要由3个3×3膨胀卷积(dilated convolution)[9]层组成,每层卷积步长stride=1,3个卷积直接拼接可输出同等尺寸的特征图。模块中采用膨胀卷积替代传统标准卷积,在保持特征图尺寸大小不变的同时,能够较好地提升感受野,进而丰富语义特征。膨胀卷积的感受野计算方式为
RF=(K+1)×(DR-1)+K
其中,RF表示膨胀卷积输出的感受野,K表示卷积核尺寸大小,DR表示膨胀率。

图5 特征融合层II的结构
图6展示了膨胀率(dilated rate)为2的卷积可将原来3×3标准卷积的感受野扩大为7×7。

图6 标准卷积和膨胀卷积(膨胀率为2)的感受野变化
2.4 网络模型的优化加速
本文设计的模型主要面向包裹自动分拣环境中的条形码实时检测,并考虑到未来将算法移植到像FPGA等计算资源有限的嵌入式设备中,故对模型的处理速度要求较高。为解决这一问题,重点针对模型的输出通道和卷积深度两方面分别做加速改进。
(1)输出特征图通道压缩
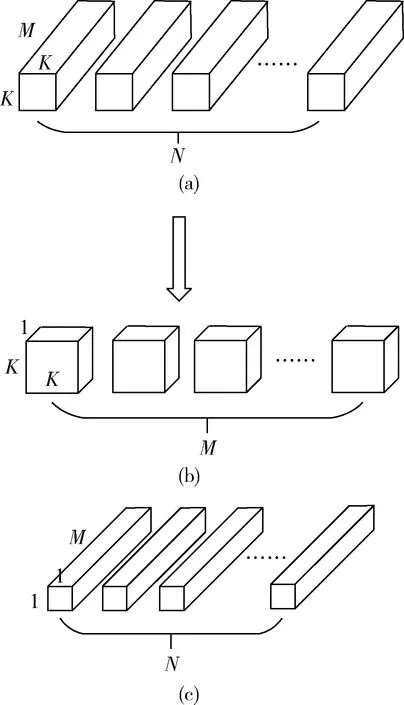
在特征融合模块中,在对输出的特征图进行拼接后,特征图通道数量激增,导致模型复杂度和计算量加大。为此,考虑在相邻融合模块之间加入一个1×1卷积压缩层。该压缩层可对模块输出后的特征图数量进行缩减,进而保持模型的轻量化。具体地,设置1×1卷积核个数V,使其少于输入特征图通道数M,即V 图7 特征图通道压缩 (2)卷积核深度分离 在卷积计算中,将3×3标准卷积全部转换为改进的深度可分离卷积(depthwise separable convolution)[10],以有效提高卷积层计算速度。以空间尺寸为K、深度为M的标准卷积核为例(图8(a)),总卷积核数量为N,通过转换,可拆分为深度卷积(depthwise convolution)(图8(b))和点乘卷积(pointwise convolution)(图8(c))。其中,深度卷积的卷积核通道数为1,即特征图的每个通道都有一个独立的卷积核,剥离了标准卷积中跨通道的特性,关注特征图空间维度特征的提取。点乘卷积的卷积核空间尺寸为1,相当于1×1的卷积核,与深度卷积相反,点乘卷积实现跨通道特征信息的混合与流动。 图8 标准卷积核和深度可分离卷积核 一般来说,卷积核个数N设置较大(如128,256等),而卷积核大小主要是3×3或者5×5,因此深度可分离卷积的计算量主要集中在点乘卷积上。采用分组卷积可进一步优化1×1点乘卷积,通过将点乘卷积核分割成g组,然后分别进行卷积,最后将结果合并输出,计算量可减少g倍。然而分组卷积易造成通道间信息独立,与1×1点乘卷积的跨通道信息混合作用相悖,因此在分组卷积之后加入通道重组(图9),将不同组的特征图交叉混合。 图9 通道重组 经过上述改进,3×3卷积层结构变化如图10所示。 图10 标准3×3卷积层结构(左)和改进的3×3深度可分离卷积层结构(右) 假设输出特征图尺寸大小为D×D,标准卷积和改进的深度可分离卷积的计算量对比为 在本文中,卷积核大小为3×3,点乘卷积的分组数g为2,卷积核个数N一般较大,比值第二项可以暂时忽略,因此采用改进的深度可分离卷积能够比标准卷积理论上加速18倍左右,其有效降低了模型的复杂度和参数量,提升了模型的速度。 实验数据来源于从实际包裹分拣现场采集的15 372张图片,其中随机取出20%作为测试集,其余作为训练集。为保证实验效果,所有图片统一进行数据预处理,主要包括去均值和数据增强,其中,数据增强涉及随机裁剪(保留区域80%)、平移变换、随机角度旋转、水平垂直镜像翻转、饱和度和对比度拉伸等,可丰富训练样本,保证算法的泛化性能。硬件的配置是:CPU为56 Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz;GPU为6块NVIDIA TITAN Xp,每块12G显存。使用的深度学习架构是keras。软件环境为Ubuntu 16.04 LTS。 网络模型输入图片大小为512×512,初始学习率为10-7。最大循环次数为60 000次,前30 000次采用自适应优化算法Adam,后30 000次采用学习率衰减优化算法SGD,其中每隔10 000次学习率衰减为原来的1/10。权重采用Xavier初始化,激活函数选择PReLu,batch_size设置为16。评价标准选择AP(average precision),其IoU阈值设置为0.6。分类损失函数选择Softmax交叉熵损失,回归损失函数选择Smooth_L1损失。 表1列举出4个融合层I、3个融合层II、7个压缩层具体的卷积核个数,其中每个融合层I包括3个3×3卷积和两个转置卷积,每个融合层II包括3个3×3卷积,每个压缩层包括1个1×1卷积。 表1 网络各层的卷积核个数设置 由之前的分析可知,特征衰减网络中融合层I的个数固定为T=4,因此实验过程只对特征保持网络中融合层II个数Q进行调整,并且和YoLo-v3以及Vgg-SSD网络进行对比。 实验结果见表2,首先,本文设计的级联多尺度特征融合网络模型在准确率AP上与YoLo-v3以及Vgg-SSD相差无几;其次,特征保持网络的加入对于准确度AP有接近两个百分点的提升,并且融合层II的个数N越大并没有带来准确率AP明显的提升;最后,本文设计的模型在速度上比YoLo-v3以及Vgg-SSD有明显优势。 表2 实验结果对照 综合分析,在针对物流包裹分拣场景下的条形码检测任务中,除去图片传输通信、预处理和后处理等耗时,条形码检测算法耗时需控制在80 ms以内,并考虑到设计裕量和未来移植到FPGA等嵌入式平台中,实际算法运行速度越快越好。本文提出的级联多尺度特征融合网络模型能够在保证准确度AP的前提下,耗时更少,而YoLo-v3以及Vgg-SSD由于网络结构存在冗余性导致耗时较多;在考虑准确度AP和速度前提下,Q值为1的级联多尺度特征融合网络最优。图11展示了级联多尺度特征融合网络的检测效果,偏小的条形码目标能够很好的被检测出来,可满足实际包裹分拣场景的需求。 图11 条形码检测结果 本文在物流包裹分拣场景下,提出了一种针对条形码小目标的级联多尺度特征融合网络快速检测算法。该算法以one-stage检测器作为基础框架,通过设计特征缩减网络和特征保持网络实现对条形码特征的充分抽取,同时,结合膨胀卷积和深度可分离卷积,对模型的表现能力和速度进行优化提升,最后通过实验验证了算法的有效性和可行性。此外,文中提出的级联多尺度特征融合网络在实际运用环境中可自行实验设计T、Q取值,具有一定普适性,对于相似场景任务可直接部署并取得快速准确的检测效果。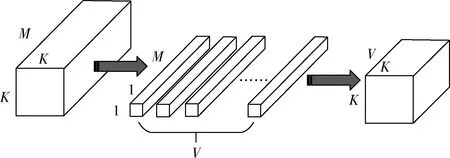



3 实 验
3.1 实验准备
3.2 实验参数设置

3.3 实验结果与分析


4 结束语
猜你喜欢
China’s foreign Trade(2021年6期)2021-12-26
北京航空航天大学学报(2021年9期)2021-11-02
少年文艺·开心阅读作文(2021年8期)2021-09-05
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
小学科学(学生版)(2019年5期)2019-05-21
少儿美术(快乐历史地理)(2019年11期)2019-04-20
北京航空航天大学学报(2018年1期)2018-04-20
汽车与新动力(2017年3期)2017-06-29
小学生导刊(2017年13期)2017-06-15
