
基于像素级注意力机制的人群计数方法
2020-03-06 12:55陈美云王必胜梁永博
计算机应用 2020年1期
陈美云,王必胜,曹 国,梁永博
(南京理工大学 计算机科学与工程学院,南京 210094)
0 引言
人群计数[1]旨在统计拥挤场景中的人数,通常存在遮挡、分辨率低、人员分布不均匀、场景复杂等干扰因素,是非常值得探究的一个方向。目前,城市的人口数量随着城市化的发展急剧增长,人口暴增导致各类人群活动显著增加,如演唱会、路演、竞技赛等。为了更好地保障社会治安,对这些场景进行准确的人群计数是非常必要的一项工作[2]。卓越的人群计数工作对构建高层次认知能力有极大的作用,例如分析道路拥塞[3-4]、检测异常状况[5]、检测特定事件[6]等。除此以外,优秀的人群计数方法还可以推广到车辆计数[7]、野生动物密度估计[8]和计量显微图像中的细胞[9]等多个领域。
在深度学习方法盛行之前,人群计数的方法主要以检测和回归为主。
以检测为主的人群计数算法先训练检测器用以识别输入图中的个体,继而将识别个体进行累加得出总人群数。过去采用检测的人群计数算法是根据某些特征如方向梯度直方图(Histogram of Oriented Gradients, HOG)[10]、Haar小波[11]等来训练检测器,从而将人体检测出来。不过,当这种方式用来计数高密度人群时,就会受到遮挡、重叠等因素的严重干扰,而且这种方式在计算时间和计算资源方面占用比较大,性能不够优异。
针对高密度场景,有研究人员提出了回归人群数目和人群特征两者间映射关系的方法。回归算法先进行底层特征提取,然后进行模型回归。其中,底层特征由场景的纹理特征(如LBP(Local Binary Pattern))[12-13]、局部特征(如边缘特征)、全局特征得来;然而,回归算法在进行模型回归时会丢失掉部分关键的空间信息。
如今,科技的进步使得图形处理器(Graphics Processing Unit, GPU)极大地提升了计算能力,时间的推移使得大型数据库更多地涌现,而这两者的发展则使得深度学习[14]在提取特征和泛化模型方面性能优越,甚至在许多方面已经完全超越了传统算法。
鉴于卷积神经网络(Convolutional Neural Network, CNN)显著提升了目标识别、图像分类[14-15]等多个计算机视觉领域的准确度,人群计数的研究人员也开始尝试采用卷积神经网络来探索人群密度与人群图像两者的非线性关系。实验证明卷积神经网络在人群计数准确性方面相比前两种传统方法提升显著。
其实,采用卷积神经网络方式进行人群计数也属于回归算法的一种。卷积神经网络先提取输入图片中的人群特征,然后通过回归方式计算出人群总数。回归方式分为两种:一种是卷积神经网络学习输入图片与人数间的映射关系,然后直接回归计算出人群总数;另一种是卷积神经网络学习输入图片和人群密度图的映射关系,然后对密度图进行积分得出人群总数。
Zhang等[16]是第一个采用CNN来解决人群计数问题的,不过,该方法回归结果并非人群总数而是人群的密度等级。此后,Zhang等[17]针对提升跨场景计数性能不佳问题,提出了一种先训练一些场景图片,测试时从训练集中找到相似场景图来微调网络。虽然该算法提升了跨场景人群计数的准确性,但占用的资源过多。Sindagi等[18]提出了一种输入为整幅原始图片的卷积神经网络,这是因为图片切块存在重叠部分,会造成计算重复。Zhang等[19]提出了一种包含三列卷积核尺寸各异的多列卷积神经网络,各列子网络对应处理不同尺度的人群。该算法还考虑到了图片拍摄角度的问题,因此使用自适应卷积核来生成密度图。
可见针对人群计数这一课题,研究者们已经提出了许多以卷积神经网络[14,20-21]为基础的算法[16,18-19,22-23],虽然识别效果不错,但仍然有一些基本问题没有得到很好解决。
由于人头在不同地方的分布存在很大的差异,许多人群计数算法会将人群图像划分为不同人群密度等级的图像块[18,22];然而由于真实密度图是基于像素的,所以这种基于图像块图像的分类方法无法与真实密度图完美匹配,使得最终估计的密度图中会造成模糊。针对这一问题,本文采用了一种新的不同于传统注意力机制的像素级注意力机制。这种新方法不再对图像块进行分类,而是生成像素级的像素掩码,从而指导密度估计网络获得更精确的密度值。
综上所述,本文提出了相应的改进方法,采用了一种基于像素的注意力机制来处理人群非均匀分布的问题。设计了一种新的以更少的学习参数学习到更多代表性特征的单列网络,可以得到高效的人群计数结果。
1 算法分析
本章将介绍本文的整体算法结构。如图1所示,本文算法结构主要包括两个部分:像素级注意力机制(Pixel-level Attention Mechanism, PAM)和人群密度估计网络。
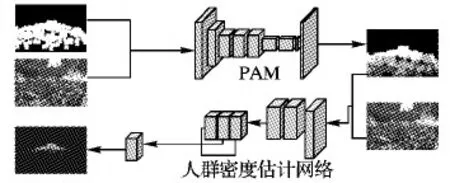
图1 整体网络架构Fig. 1 Overall network architecture
1.1 标签密度图的生成
人群图像的标注是在人头部中心作的点标注。图2(a)采用一个3×3大小的方格来代表人群图像的局部区域,像素点值为1表示人,值为0则表示背景。
在图像中假设每个人头大小都是3×3像素,图2(b)就是图2(a)对应的使用卷积神经网络进行人群计数的标签密度图,各个人头区域的概率之和为1,得到完整的人群图像密度图后,对其进行积分(求和)就是人群数目。

图2 标签密度图的生成Fig. 2 Generation of label density map
为了保存更多的空间信息,本文实际使用归一化高斯核将每个头部标注模糊,估计图像中每个人头的大小并转换为密度图。步骤如下:
xi表示人头中心坐标位置,用函数δ(x-xi)表示,对于一幅有N个人头标注的人群图像来说,可以表示为H(x)函数:
(1)
将式(1)与高斯核进行卷积,转化为连续密度函数,如式(2)所示:
(2)
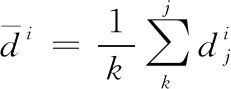

图3 原图和对应生成的标签密度图Fig. 3 Original image and corresponding generated label density map
1.2 像素注意力机制
人群计数的一些方法[22]将整幅图像上的小块分割成不同的密度类,然后利用分类结果提高局部密度估计的精度。这种图像小块级的注意力机制并不能很好地与真实值相匹配,因为真实值反映的是每个特定像素的密度信息,因此,本文提出了一种像素级注意力机制来定量模拟图像的局部密度信息。
生成的标签密度图的每个像素都表示一个密度值。根据这些像素的密度值设定阈值,分成不同密度程度的类别,以反映人群的多样性。举例来说,类别标号为{0,1,2,3,4},其中,{0}表示背景,{1,2,3,4}表示4种不同密集程度的人群。需要注意的是,针对不同的数据集,设置的密度等级会有所不同。至于设置多少类别以及密度等级阈值大小可根据实验确定。本文根据局部区域的人头大小通过实验设置了阈值,而类别数量则由实验对比决定。具体实验结果见第2.2节。
将每个像素划分到特定类别是一个像素对像素的语义分割问题,因此本文使用了表现性能优异的全卷积网络(Fully Convolutional Network, FCN)[24]来解决像素划分问题。
直观来看,用卷积层替换卷积神经网络的全连接层就得到了全卷积神经网络。全卷积神经网络的输出是一幅已经完成标记的图。
全卷积神经网络的输入是大小为h*w的原图,原图经过第1次卷积、池化以后缩小为原来的1/2;然后继续进行第2次卷积、池化,图像变为原来的1/4;第3次卷积、池化后输出图像是原始图像的1/8,保留本次池化后的特征图(featureMap);然后经历第4次卷积、池化,输出图像是原始图像的1/16,同样保留本次池化后的特征图(featureMap);继续进行第5次卷积、池化,输出图像是原始图像的1/32;接着进行第6次卷积、第7次卷积操作,此时,输出的图像依然是原始图像的1/32大小,但是featureMap数量改变了,此时的图像称作热图(heatMap)。
上述保留的热图通过上采样来还原图片,但是得到的只是第5次卷积操作的卷积核特征,精度还不够高,所以需要继续向前迭代,具体的操作是先使用第4次卷积中的卷积核来反卷积上一个上采样还原图,其实就是作差值的过程,然后用第3次卷积中的卷积核来反卷积刚刚的上采样还原图,实现图像的整体还原,其中两次反卷积都是为了补充细节。
PAM的网络如图4所示,使用了全卷积神经网络的网络结构,输入为任意尺寸的自然图,输出则是与输入图大小相同的分类图。采用反卷积操作对相应卷积层特征图上采样,在保留原始图空间信息的同时还能够预测每个像素,实现逐个像素的分类。采用归一化指数函数(Softmax函数)来计算每个像素的损失,等同于一个训练样本对应一个像素。针对不同数据集,PAM网络对FCN模型分别进行微调,只需要重新定义网络的输出类别数(保证输出的类别数与数据集对应的密度级别种类数一致),从而输出对应的分类图。

图4 PAM网络(基于FCN结构的像素级注意掩码生成网络)Fig. 4 PAM network (pixel level attention mask generation network based on FCN structure)
1.3 改进的人群密度估计网络
人群密度估计[18,25]网络的作用是将输入图像转换成密度图。由于图像中不同位置的人头尺度存在很大差异,现有的方法多是采用不同卷积核大小的多列网络来求解;然而,多列网络往往需要更多的时间,而且难以收敛。通过实验发现,设计合理的单列网络不仅同样可以得到良好的计算结果,而且还降低了计算复杂度。本文设计的单列人群密度估计网络结构如图5所示。
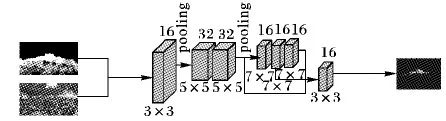
图5 人群密度估计网络Fig. 5 Crowd density estimation network
本文进行了大量的实验来分析不同因素对最终结果的影响,这些因素包括深度、卷积核大小、卷积核大小顺序和不同层的连接。为了与基准方法进行比较,本部分只使用原始RGB图像作为输入。通常,头部较大的密度图需要使用具有较大感受野的滤波器来提取特征,头部较小的密度图则应使用感受野较小的滤波器提取特征,而一般来说,合理的深层次网络效果要优于浅层网络。
本文的人群密度估计网络属于卷积神经网络,设计思想来源于Zhang等[19]发表的多列卷积神经网络(MCNN),本文设计的网络如图5所示,将MCNN并行的3列融合成单列,借鉴其卷积核大小将本文网络参数设定如下:7层网络并且进行PAM处理,卷积核分别为3×3、5×5、5×5、7×7、7×7、7×7、3×3(融合第3、5、6层输出作为第7层输入)。
每层卷积层的激活函数均采用修正线性单元(Rectified Linear Unit, ReLU):
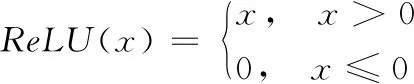
(3)
由于池化操作会丢失细节信息,所以仅在第一层和第三层卷积后设置了步长为2(stride=2)的最大池化操作;融合第3、5、6层输出作为第7层输入的设置,将合并的特征输出到卷积核大小为3×3的第7层,在保证了网络可以收敛的同时提高了网络效果。把第3、5、6层提取的特征合并后输出到卷积核大小为3×3的第7层卷积层,使用3×3卷积核替代1×1卷积核,可以估计出密度图。该网络有3个特点:
1)更深层次的单列架构。内核的大小和深度对于CNN来说是至关重要的。
2)不同层次的拼接。受文献[14,26-27]的启发,将低层和高层连接在一起,学习底层信息(如形状、颜色、纹理)和语义信息。
3)卷积核大小的逆序。在本文的网络中,小卷积核在较低的层中选择,而大卷积核在较高的层中选择。这种策略的优点有两个:首先,使用反序的卷积核大小具有更大的感受野,可以获得更多的上下文信息;其次,在合并相邻层时,起到组合浅层和高层不同类型信息的作用,提高预测准确性。这是一个与现有的卷积神经网络完全不同的考虑。
通过这些设计,本文的网络与MCNN[17]和Sindagi[18]相比具有更少的参数,但得到了更好的结果。
1.4 损失函数
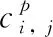
(4)
对于人群密度估计网络模块,采用欧几里德损失层来测量真实值与估计密度图之间的差异。损失函数定义如下:
(5)
其中:θ表示网络中的可学习参数,Xi是输入图像,F(Xi;θ)和Fi分别为预测密度图和真实值。
2 实验
在4个公开的具有不同挑战性的数据集上,将本文方法与上下文金字塔神经网络(Contextual Pyramid Convolutional Neural Network, CP-CNN)、多列卷积神经网络(MCNN)、交换卷积神经网络(Switching Convolutional Neural Network, Switch-CNN)[22]、拥塞场景识别网络(Network for Congested Scene Recognition, CSRNet)[28]、检测和密度估计网络(Detection and Density Estimation Network, DecideNet)[29]等方法进行了比较。这4个数据集分别是Shanghaitech数据集(包括part_A和part_B两部分)、UCF_CC_50数据集以及WorldExpo_2010(Expo’10)数据集。有关这些数据集的数据信息详见表1。

表1 各数据集相关信息 Tab. 1 Information about each dataset
2.1 评价指标
根据现有的人群统计工作[19,22,28],本文采用较为通用的两个评价指标——平均绝对误差(Mean Absolute Error, MAE)和均方误差(Mean Squared Error, MSE),来对本文方法与现有方法的性能进行比较。MAE和MSE定义如下:
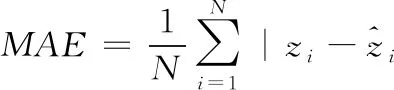
(6)
(7)
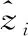
2.2 PAM模块的阈值选取
正如在2.2节中分析的那样,对于不同的数据集需要人为地定义合适的PAM阈值和类数,以优化性能。本文通过观察对比根据真实值(Ground Truth)生成的密度图对应原图的人群密集程度,从而划分出人群密度等级以及阈值。结果划分如表2。图6(a)~(d)左图为各数据集中选取的一幅原始图片,图6(a)~(d)右图为对应原始图片经PAM分割后得到的分类图。

表2 PAM模块阈值划分 Tab. 2 PAM module threshold division

图6 各数据集经PAM所得分类图Fig. 6 Classification map of each dataset obtained by PAM
2.3 参数设置及训练步骤
2.3.1 参数设置
本文模型是在配置为i7- 6700K CPU、NVIDIA GTX 1080 GPU(显卡内存为8 GB)的台式机的Ubuntu系统下的Caffe框架下运行的。训练过程采用随机梯度下降法(Stochastic Gradient Descent, SGD),训练阶段的batchsize设置为1,为了提高模型的拟合速度,冲量设置为0.9,权重衰减设置为0.000 5来控制模型的过拟合。具体的模型参数设置见表3,其中base_lr为学习率,max_iter为最大迭代次数,lr_policy为学习策略。

表3 训练参数设置 Tab. 3 Training parameter setting
2.3.2 训练步骤
1)根据数据集的真实标注Ground Truth采用归一化高斯核生成标签密度图density_map;
2)根据设定的阈值参数将density_map转变为划分了像素等级的掩码标签图gt,采用FCN对原图和掩码标签图gt进行训练;
3)使用训练的FCN获取图像n通道标签图(n为该数据集划分的密度级别数),然后与原图(3通道)融合为n+3通道图,作为人群密度估计网络的输入;
4)训练人群密度估计网络,使用训练的模型来估计图片的人群密度,采用回归计算得到人群总数。
算法伪代码:
Train(){
初始化network的权和阈值;
while 终止条件不满足{
for samples中的每个训练样本X{
向前传播输入;
for 隐藏或输出层每个单元j{
相对于前一层i,计算单元j的净输入;
计算单元j的输出;
}
反向传播误差;
for 输出层每个单元j{
计算误差,选择ReLU函数作为激活函数;
}
for network中每个权重ωij{
权重增值;
权重更新;
}
for network中每个偏差Qj{
偏差增值;
偏差更新;
}
}
}
2.4 Shanghaitech数据集
MCNN[19]中首次建立Shanghaitech数据集,数据集分为part_A和part_B两部分:part_A的图片总共482幅,是从互联网上随机收集的;而part_B的图片总共716幅,是上海市区繁华的街道图片。此外,part_B图片中的人群分布相比part_A图片中的人群分布更为稀疏。
该数据集总共有1 198幅标记图片:part_A部分300幅用于训练,182幅用于测试;part_B部分400幅用于训练,316幅用于测试。具体的信息可以在MCNN[19]中找到。表4是本文方法与其他方法在Shanghaitech数据集上的结果对比。
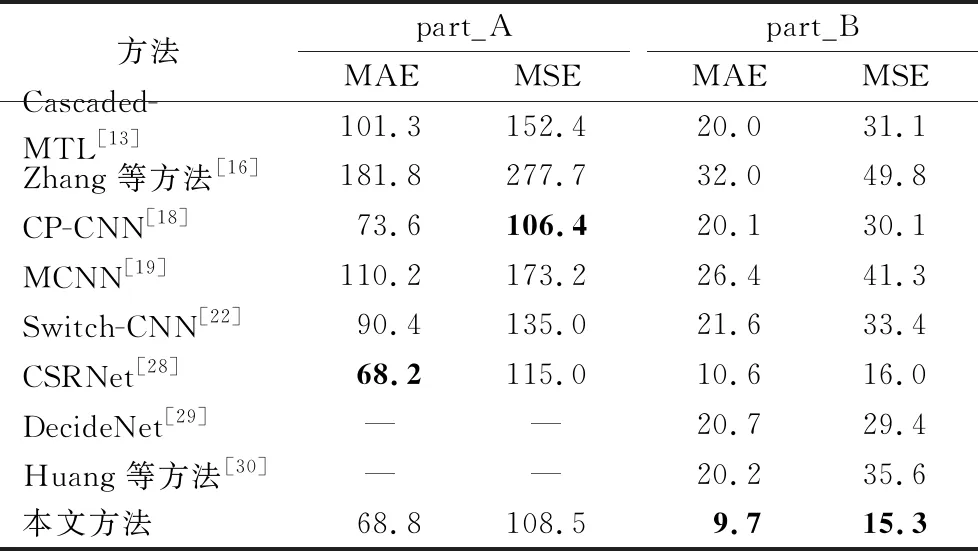
表4 Shanghaitech数据集上不同方法结果对比 Tab. 4 Comparison of results of different methods on Shanghaitech dataset
2.5 UCF_CC_50 数据集
UCF_CC_50数据集包含来自互联网的50幅图像。这是一个非常具有挑战性的数据集,因为它不仅图像数量非常有限,而且图像的人群数量也变化巨大。人头计数范围在94~4 543,每幅图像平均有1 280人。作者总共为这50幅图像提供了63 974条标注。
本文将这50幅图像以7∶3的比例分成训练集和测试集。表5是本文方法与其他方法在UCF_CC_50数据集上的结果对比。
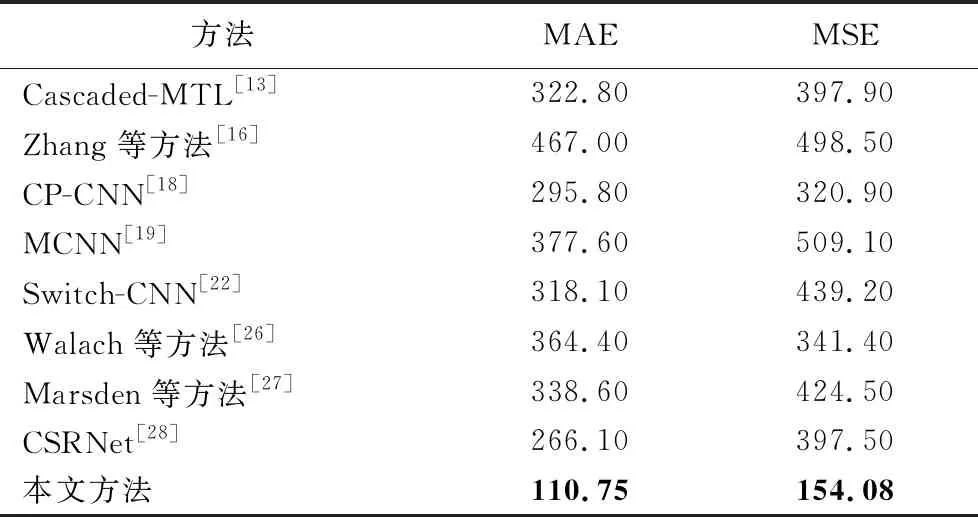
表5 UCF_CC_50数据集上不同方法的结果对比 Tab. 5 Comparison of results of different methods on UCF_CC_50 dataset
2.6 WorldExpo’10 数据集
WorldExpo’10 数据集是由Zhang等提出的[16]。该数据集包含1 132个带注释的视频序列,由108个监视枪摄像机拍摄,来自于2010年举办的上海世界博览会。此数据集提供了3 980帧图像,共计199 923个行人头部中心标注。其中3 380帧为训练集,另外600帧为测试集,测试数据集包含5个不同场景,每个场景有120个标记帧。测试场景提供了5个不同的感兴趣区域(Regions Of Interest, ROI),因此人群计数只在ROI部分进行。与其他数据集相比,该数据集人群数量相对较小,平均每个图像有50人。表6是本文方法与其他方法在WorldExpo’10数据集上的结果对比。
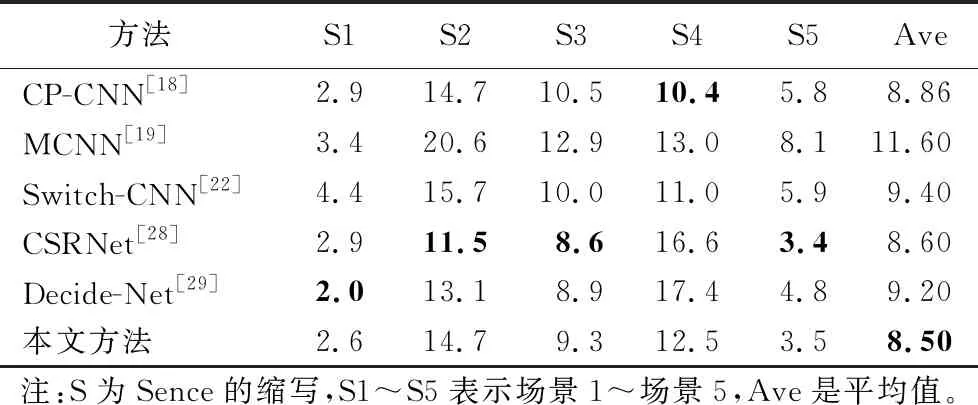
表6 Expo’10数据集上不同方法的MAE比较结果 Tab. 6 MAE comparison of different methods on Expo ’10
3 结语
人群计数的任务是准确估计出图像中人群的总人数,同时给出人群密度的分布情况。人群计数可以用于事故预防、空间规划、消费习惯分析和交通调度等多个领域。除此之外,图像人群计数算法还可以应用到一些其他的计数领域,例如野生动物计数、车辆计数、细胞计数等领域,因此,人群计数的研究具有十分重要的意义。
本文提出了一种由两个模块生成高质量人群密度图,达到精确的人群计数效果的新体系结构。首先,与现有的采用分块注意机制方法相比,生成像素级掩码并与原图结合,能够更精确地估计局部密度。此外,本文所采用的单列网络与其他估计器相比,该网络可以用更少的参数得到相似甚至更好的结果。最后,在三个高挑战性的数据集上进行了实验,通过对比表明本文方法具有更好的性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小学生学习指导(低年级)(2020年4期)2020-06-02
数学大王·低年级(2019年8期)2019-08-27
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
中学生数理化·八年级物理人教版(2015年12期)2016-01-25
