
基于大数据的铁路时间同步网异常流量检测系统的研究
2020-03-16 12:46张友鹏李响兰丽周净毓刘思雨张妍
铁道科学与工程学报 2020年2期
张友鹏,李响,兰丽, 2, 3,周净毓,刘思雨,张妍
基于大数据的铁路时间同步网异常流量检测系统的研究
张友鹏1,李响1,兰丽1, 2, 3,周净毓1,刘思雨4,张妍5
(1. 兰州交通大学 自动化与电气工程学院,甘肃 兰州 730070;2. 兰州交通大学 电子信息工程学院,甘肃 兰州 730070;3. 兰州交通大学 光电技术与智能控制教育部重点实验室,甘肃 兰州 730070;4. 西安市轨道交通集团有限公司,陕西 西安 710016;5. 中国铁路太原局集团有限公司党干校 科研开发中心,山西 太原 030013)
为快速准确地识别铁路时间同步网所受到的恶意攻击,设计一种基于大数据的铁路时间同步网异常流量检测系统。该系统首先采用无监督学习算法K-Means对部分数据进行训练,形成最优聚类模型,并通过该模型实现对异常流量的检测。将已标记的时间同步网数据输入系统,测试系统对异常流量的检测准确率及速度是否满足铁路时间同步网的要求。对系统识别出的异常流量特征进行分析,找出相关性较高的典型特征类型,并结合铁路时间同步网结构,针对该类型特征提出初步的攻击防御建议。研究结果表明:基于大数据的异常流量检测系统聚类时间70.434 682 s及准确率98.36%均满足大数据网络环境下铁路时间同步网的要求;基于时间和主机的网络流量统计特征可以为提升铁路时间同步网的安全性提供参考。
网络流量;异常流量检测系统;K-Means;Spark;铁路时间同步网

标准统一的时间信息是高速列车安全高效跨线跨区行驶的重要保障,因此有必要建立完善的铁路时间同步网系统。铁路时间同步网是铁路通信网的重要支撑子网之一,包括地面时间同步网和列车时间同步网[1−2]。铁路时间同步网能准确记录各部门的运行时间,并向各部门提供标准统一的时间信息,从而提升铁路运输效率,避免因时间不同步造成的安全事故。铁路时间同步网是铁路通信网的独立支撑子网,这意味着由于二者之间的重叠部分很少,可以将铁路时间同步网作为一个独立的网络来进行研究。铁路时间同步网的本质是具有三级树型拓扑结构的时间同步网,而该结构正是铁路时间同步网和其他通信系统时间同步网之间的主要区 别[3]。因此,在研究铁路时间同步网时,可先对普通通信网络的时间同步网进行研究,之后结合铁路时间同步网的拓扑结构,分析该网络的具体特点及存在的问题。时间同步网使用网络时间协议(Network Time Protocol, NTP),该协议基于用户数据报协议(User Datagram Protocol, UDP)传输标准时间信息。NTP是一种提供精确时间校正服务的协议,其可以实现互联网上所有计算机、服务器和其他设备的时间同步。然而,由于NTP的传输层协议UDP提供了无连接通信服务,即其在传输信息时无法对源地址和目标地址进行确认,导致黑客更容易伪装源地址,从而攻击NTP并破坏时间同步网。针对上述缺陷,在铁路时间同步网的安全性研究方面,众多专家学者将研究重点置于铁路时间同步网所采用的NTP协议的脆弱性上。他们的研究过程一般首先对协议流程进行分析,然后建立状态变迁模型,最后分析协议的不安全状态与协议相关安全性指标之间的关系,进而验证协议中是否存在隐藏的弱点[4−6]。然而上述研究均从NTP协议自身出发,着重强调提升网络内部的安全等级,忽略了检测和防御外部攻击的重要性。网络攻击是不断进化发展的,仅对网络的内部安全进行研究和优化显然无法满足当前铁路时间同步网对安全性的要求,故本文将研究重点放于外部攻击及其检测方案上,以一个崭新的角度对铁路时间同步网的安全性进行研究。针对NTP网络的恶意攻击可实现对网络资源的大量占用,从而导致整个网络的阻塞甚至崩溃。该类攻击最显著的特点之一是流量变化。因此,国内外的异常流量检测系统多以流量为基础来进行系统的设计。目前的异常流量检测系统设计多采用机器学习算法,然而由于流量数据量过大,报文字段过多,给机器学习算法的数据处理带来一定困难[7−9]。基于云计算的数据处理平台可通过由多台计算机组成的计算机集群来对海量数据进行处理。由于该类平台具有计算可扩展和广播计算的优点,故其可高效准确地对海量数据进行处理、统计及分析,十分适用于当今数据量庞大的网络环境[10−12]。因此,利用云计算数据处理平台对异常网络流量数据进行识别是实现恶意攻击检测的一种很好的方法。为了满足铁路时间同步网对检测速度和准确率的要求,本文提出了一种基于云计算平台Spark的异常流量检测系统,该系统可对恶意攻击进行检测。本文首先分析了云计算平台Spark的组成及工作流程,介绍了现有的基于无监督学习的异常流量检测系统。然后结合两者的优点,设计了一个Spark平台下的基于无监督学习K-Means算法的NTP异常流量检测系统,该系统能够对异常流量进行识别,进而实现对恶意攻击的检测。最后,针对检测到的异常网络流量的典型特征类型,同时考虑铁路时间同步网的树型拓扑结构,本文初步提出了防御建议,以提高铁路时间同步网的安全性。
1 相关研究
1.1 Spark云计算平台
现有的云计算平台主要包括Hadoop平台和Spark平台。与Spark平台相比,Hadoop的工作原理相对简单,但由于Hadoop每次迭代生成的临时数据都会被读写到硬盘中,故其存在数据处理效率低下的缺点,运算速度较慢。而Spark平台在内部存储器中对临时数据进行读写,故其在运算复杂算法时可以高效快速地处理数据[13]。因此本文在Spark平台下,利用Python语言进行编程,设计了一个基于无监督学习算法K-Means的异常流量检测系统。
Spark的工作流程如图1所示。
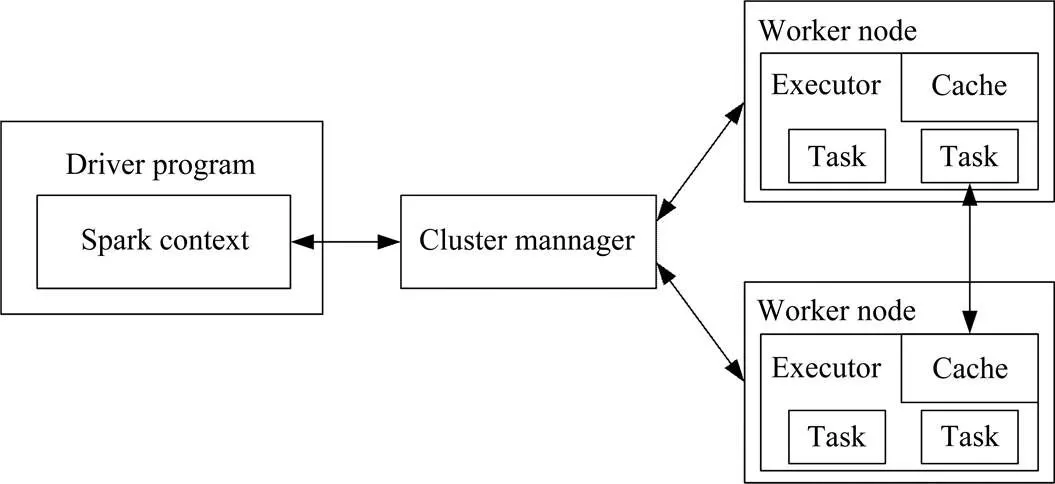
图1 Spark工作流程
从图1可以看出,Spark的工作核心是Spark Context和Executor部分。其中,Executor部分负责执行任务,其由Worker Node运行。SparkContext部分由Drive Program启动,通过Cluster Manager与Executor进行通信。SparkContext和Executor在各种操作模式下内核代码可以共用,其上层部分则根据不同的部署模式,包装相应的调度模块和相关代码[14]。
SparkContext是程序运行的总入口。在启动过程中,Spark会创建两级调度模块模块,包括DAGScheduler(作业调度)和TASKScheduler(任务调度)。DAGScheduler是基于任务的高层调度模块。它首先给出每个Spark任务的多个调度阶段,根据shuffle对这些阶段进行划分,之后根据数据本地性为每个调度阶段构建一组待办任务。最后由Spark的任务调度模块来执行所提交的TaskSets。任务调度模块还可实现任务的启动及任务的运行情况的监视和汇报。
1.2 K-Means聚类算法
在实际网络环境中,由于系统所采集到的网络流量信息未经标记,故若欲识别该网络流量是否异常,检测系统需要采用无监督算法对其进行聚类,从而划分其是否属于异常流量。国内外专家提出许多无监督学习聚类算法,其中K-Means算法作为聚类中常用的经典算法,具有简单、计算高效快速等特点,且当数据量庞大时,该算法准确率较高,故其广泛应用于各种检测系统的研究中。K-Means算法流程图如图2所示。
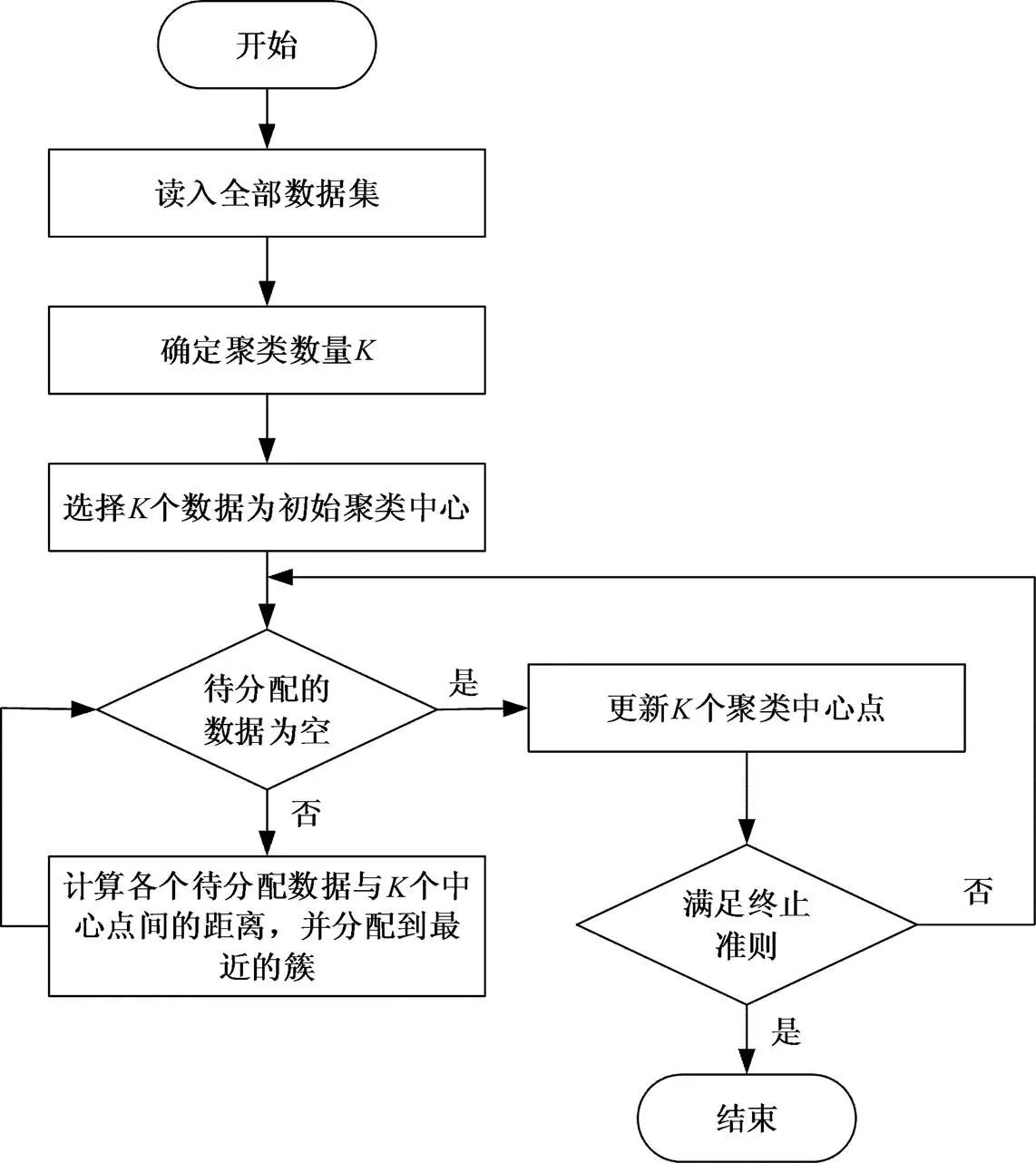
图2 K-Means工作流程
从图2可以看出,该算法的最终目标是在无特征指导的情况下将数据集划分为个簇。该算法的具体步骤如下:首先设置个聚类中心并计算所设置聚类中心和数据集每个点之间距离的平均值;之后重置值并重复上一步,得到不同值下的平均值;最后比较各平均值,取平均值最小的值为最优值。
2 基于大数据的异常流量检测系统
传统的异常流量检测系统很难实现对新型隐蔽网络攻击的全方位检测,攻击者甚至可以花10 a时间分析和渗透目标网络。故一旦攻击开始,运营和维护人员几乎没有时间对攻击进行防御。正是这种时间上的不对称性使攻击者可以有更多的时间对网络进行攻击。应对上述问题的一种有效方法是利用高性能的数据分析平台对网络中的海量数据进行检测和分析,而本文实现的基于Spark的异常流量检测系统显然可以通过高效数据处理平台Spark实现对海量数据的及时甄别。
2.1 系统框架
本文提出的异常流量检测系统的目标是识别异常流量,判断其是否由恶意攻击产生,并最终实现对异常流量的检测。系统框架如图3所示。

图3 系统框架
本文所提出的基于K-Means算法的异常流量检测系统包括6个模块。
1) 数据载入模块
通过SparkContext将流量数据文件载入到SPARK RDD中。
2) 数据预处理模块
将流量数据文件中的非数值型数据进行预处理,从而转换为数值型数据,统一的数据类型有助于提高系统的效率和准确性。
3) 数据规整化模块
经过第2步的预处理后,数据矩阵存在严重的稀疏性,因此需要将其转换为密集矩阵,以便提高数据处理效率。
4) 算法训练模块
通过K-Means算法可以得到不同值下的聚类模型。在所有模型中,选择聚类中心与各点之间距离均值最小的模型作为最优模型。
5) 预测模块
利用最优模型对网络流量进行预测和分类。
6) 比对模块
预测该网络流量所属的类群,并与标记样本进行比较,计算出检测准确率。
2.2 核心模块
由于本文设计的异常流量检测系统的其他模块都可以通过调用API函数来实现,故本文的研究重点在于核心模块的实现,包括数据预处理模块、算法训练模块和比对模块。
2.2.1 数据预处理模块
通过Python实现数据预处理模块,该模块工作流程如图4所示。
数据预处理模块包含6个步骤:
1) 使用Python open()函数以只读的形式打开数据文件并将其载入到内存中。
2) 使用Python readlines()函数将文件描述符转换为迭代器。
3) 对于迭代器返回的每一行文件,使用split()函数对其用逗号进行分割。
4) 使用计数函数找出非数值型数据的位置,并返回该位置。
5) 计算非数值型数据的替换值,并将该替换值替换原有数据。
6) 将经过预处理的数据文件另存为新文件。
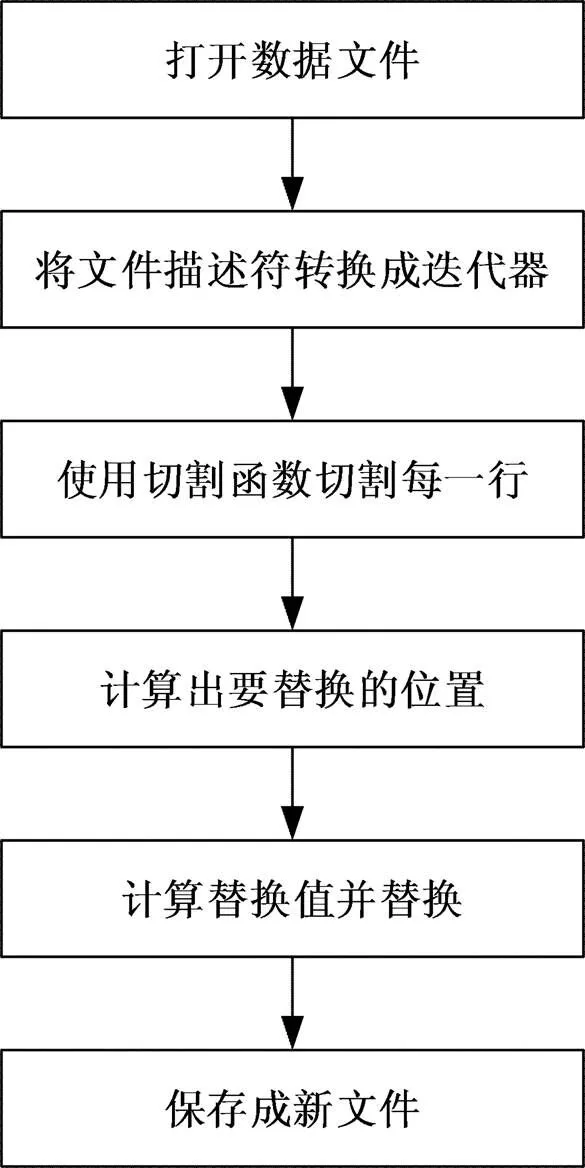
图4 数据预处理流程
2.2.2 算法训练模块
本文提出的异常流量检测系统采用无监督算法K-Means实现对数据的训练。Spark的MLlib函数库中K-Means算法的实现需要配置部分参数。参数是期望聚类的类簇数量。参数maxInternations是算法在单次运行时所能达到的最大迭代次数。由于K-Means算法不能一次找出最优聚类模型,故需设定不同的值,并在设定的值下对数据文件运行该算法,从而得到对应的模型,经过对比后最终获得最优聚类模型。runs是运行次数。Initialization Mode是初始聚类中心的选择方法,其包括2种方法,即默认方法K-Means++及随机选择中心位置的方法。initializationSteps是K-Means++的步数。epsilon是K-Means迭代收敛的阈值。seed是集群初始化的随机种子。
2.2.3 比对模块
比对模块的工作流程如图5所示。
比对模块包括4步:
1) 使用Python open()函数将2个文件(数据文件和最优模型文件)加载到内存中;
2) 通过读取2个文件内部数据,并对其相同行数进行链接,从而实现2个文件的合并;
3) 将属于同一簇的数据放入一个文件中;
4) 统计同一簇中的数据数量。

图5 比对模块流程
3 系统性能测试及结果分析
3.1 基于Spark的异常流量检测系统
本文所采用的实验数据为时间同步网流量数据,通过该数据可以对本文提出的异常流量检测系统进行测试。实验所用时间同步网流量数据为协议传输的数据报文,其不同的报文段代表不同的特征,每项数据包括41个特征,数据包含特征如表1所示。所有数据都已被提前标注是否为正常网络流量,若非正常流量,则该流量将被标记为属于哪个攻击类型。
值的选择是设计异常流量检测系统的一个关键步骤,应对测试步数进行设置以寻找最优聚类模型。本文设置值的测试步数为10,即每增加一次,值增加10。经过对不同值所生成的聚类模型进行对比,可进一步确定最佳值,即在该值下可生成均值最小的最佳模型。之后,异常流量检测系统通过最优模型对网络流量进行分类,实现对网络流量所属簇的预测。
每个簇的聚类准确率的计算公式如下:

其中:是该簇中数量最多的类型的网络流量数据的数量;是该簇中所有数据的数量。

表1 流量数据特征
数据集的总聚类准确率的计算公式如下:
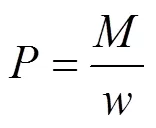
其中:是所有类簇中所有数量最多的类型的数据量之和;是所有数据的数量。
将采集的网络流量数据集输入系统得到聚类结果,并对该结果进行分析,结论如表2所示。
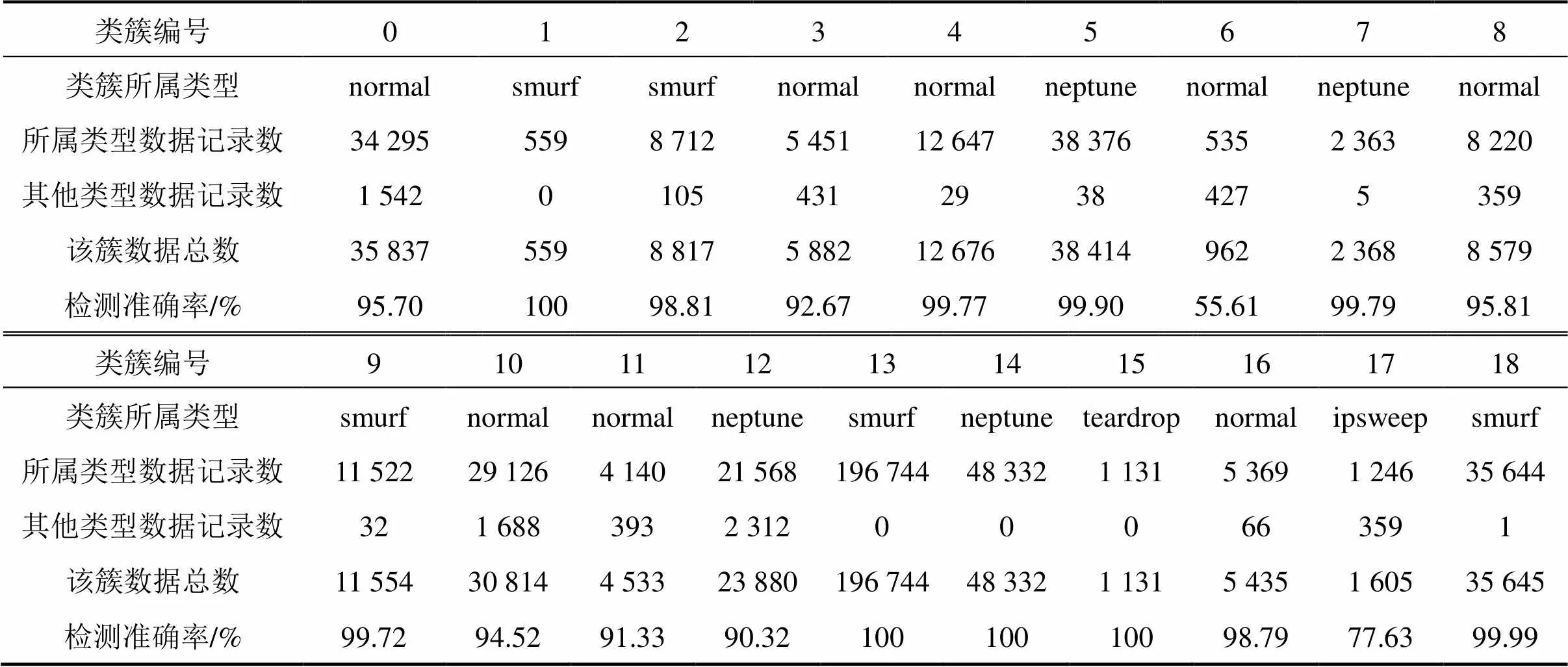
表2 异常流量检测系统聚类结果及统计
如表2所示,数据被聚类为19簇。聚类总准确率为98.36%,聚类时间为70.434 682 s,其检测准确率和检测速度均优于基于机器学习的异常流量检测系统[15]。由上述结果可得,本文的异常流量检测系统可以满足大数据网络环境下时间同步网异常检测效率和准确性的要求。
3.2 异常流量特征分析
3.2.1 异常流量特征分析
本文对检测系统所得异常流量数据和正常流量数据的特征进行了进一步对比分析,从而得到部分变化显著的报文段,可称为典型特征。为进一步在这些典型特征中找到共性,本文计算了各典型特征之间的皮尔逊相关系数。皮尔逊相关系数可以表现特征和响应变量之间的关系,其取值范围为[−1,1],其中当该系数取值为−1时表示特征与响应变量之间完全负相关,该系数取值为1时表示完全正相关,0表示非线性相关。当两特征间的皮尔逊相关系数绝对值较大时,其相关性越强。本文计算了典型流量特征间的皮尔逊系数,并绘制其热力图,如图6所示。
图6中两特征间方块颜色越趋于红色,二者正相关性越强;颜色越趋于绿色,两特征的负相关性越强。而相关性绝对值强的特征越具有代表性。由图6可以看出,尼尔逊相关系数绝对值高的特征具有高度集中性,其中大部分特征包含关键字_srv_及关键字_host_。

图6 典型特征尼尔逊系数热力图
其中,包含关键字_srv_的特征为基于时间的网络流量统计特征。可以看出该类特征诸如srv_ serror_rate(过去2 s内与当前连接具有相同服务的连接出现错误REJ比例)或是same_srv_rate(过去2 s内与当前连接具有相同服务的连接的比例),均为在过去2 s内与当前连接具有相同服务的连接的某些表现。由于网络攻击多与时间有关,故当当前连接与过去某时刻连接具有相同服务时,探查二连接间隔这段时间内产生的连接及这些连接间的内在联系或可找到部分报文段的异常变化。
然而对于包含慢速攻击模式的网络攻击来说,当主机或端口的入侵扫描频率大于2 s时,时间特征就很难表现出攻击给网络流量数据带来的变化。由于恶意攻击的信息传输依赖主机作为载体,故部分包含目标主机相关信息的特征也可一定程度上表现出流量的异常变化。由图6可看出,另一部分具有高集中性的特征均包含关键字_host_,即为基于主机的网络流量统计特征。该类特征诸如dst_host_srv_count(在前一百个连接中与当前连接的服务相同且目标主机相同的连接数)或dst_host_ same_srv_rate(在前一百个连接中与当前连接的目标主机相同的连接的比例),均为前一定数目的连接中与当前连接具有相同的目标主机的连接的表现。
由图6及分析可知,当网络攻击产生时,基于时间的网络流量统计特征和基于主机的网络流量统计特征会产生较其他特征而言相对显著且迅速的变化。针对这2项特征进行攻击防御和异常流量的检测将会大大提高铁路时间同步网防御系统的攻击识别速度、识别准确率及整个网络的安全性。
3.2.2 初步防御建议
由上述分析可以看出,与异常网络流量具有高度相关性的2种典型特征是基于时间的特征和基于主机的特征。根据铁路时间同步网的三级树拓扑结构,并结合时间信息从上到下的传输顺序,或可在二三级节点主机处设置一种内置于铁路通信网络、对时间和主机敏感的攻击触发机制。而触发条件可以设定如下,当连接到同一一级或二级主机的连接数超过某个值时,或某下位机在过去一段时间内连接超过设定次数的情况下,将触发报警功能。
本文提出的攻击触发机制只是一个初步设想,若要实现其功能,还需要进一步研究及实验来确定合适的触发条件诸如连接时长和主机数量。此外,由于铁路时间同步网的真实环境与实验室的理想环境存在差异,因此必须对实际的网络环境进行考察,并在此基础上对研究成果进行优化才能将其实际应用到铁路时间同步网的环境中。
4 结论
1) 为提升大数据网络环境下铁路时间同步网的安全性,本文提出一种基于Spark平台的铁路时间同步网异常流量检测系统。该系统聚类准确率高,达到98.36%,聚类速度快,达到70.434 682 s,上述指标均可满足大数据网络环境下铁路时间同步网对检测速度和检测准确率的要求。
2) 本文分析讨论了异常网络流量的典型特征,发现基于时间的网络流量统计特征及基于主机的网络流量统计特征与异常流量的相关性极高。在此基础上,初步提出了铁路时间同步网的恶意攻击防御建议——一种攻击触发机制,为后续铁路时间同步网的研究提供了全新角度。
[1] 曲博. 铁路时间同步网概述[J]. 铁路通信信号工程技术, 2010, 7(4): 43−45. QU Bo. Introduction of railway time synchronization network[J]. Railway Signalling & Communication Engineering, 2010, 7(4): 43−45.
[2] 北京全路通信信号研究设计院.铁路时间同步网技术条件[R]. 北京: 中国铁道年鉴, 2012. China Railway Signal & Communication Research & Design Institute Group Co., Ltd. Technical conditions for railway time synchronization network[R]. Beijing: China Railway Press, 2012.
[3] 詹秀峰. 铁路局时间同步系统的设计[J]. 铁路通信信号工程技术, 2017, 14(3): 29−31. ZHAN Xiufeng. Design of time synchronization system for railway administration[J]. Railway Signalling & Communication Engineering, 2017, 14(3): 29−31.
[4] 张友鹏, 张昊磊, 王虹. 基于有色Petri网的铁路时间同步网协议安全性分析[J]. 铁道学报, 2017, 39(10): 82−88. ZHANG Youpeng, ZHANG Haolei, WANG Hong. Security analysis on railway network time protocol based on colored Petri nets[J]. Journal of the China Railway Society, 2017, 39(10): 82−88.
[5] 兰丽, 张友鹏. 基于随机Petri网的铁路时间同步网协议脆弱性分析[J]. 铁道学报, 2017, 39(8): 85−92. LAN Li, ZHANG Youpeng. Vulnerability analysis of railway time synchronization network protocol based on stochastic Petri net[J]. Journal of the China Railway Society, 2017, 39(8): 85−92.
[6] 张友鹏, 王锋, 张珊, 等. 基于模糊贝叶斯网络的铁路时间同步网可靠性分析[J]. 铁道学报, 2015, 37(5): 57− 63. ZHANG Youpeng, WANG Feng, ZHANG Shan, et al. Dependability assessment of railway time synchronization network based on fuzzy Bayesian network[J]. Journal of the China Railway Society, 2015, 37(5): 57−63.
[7] 孟浩, 王劲松, 黄静耘, 等. 基于TcpFlow的网络可视分析系统研究与实现[J]. 信息网络安全, 2016(2): 40−46. MENG Hao, WANG Jinsong, HUANG Jingyun, et al. Research and implement on network visual analytic system based on TcpFlow[J]. Netinfo Security, 2016(2): 40−46.
[8] Renuka Devi S. A hybrid approach to counter application layer DDOS attacks[J]. International Journal on Cryptography and Information Security, 2012, 2(2): 45− 52.
[9] Bolzoni D, Crispo B, Etalle S. Atlantides: An architecture for alert verification in network intrusion detection system[C]// Dallas, Texas. Berkeley: USENIX, 2007: 141−152.
[10] 李凯, 薛一波, 王春露, 等. 千兆网络入侵防御系统高速数据包处理的研究与实现[J]. 小型微型计算机系统, 2006, 27(9): 1677−1681. LI Kai, XUE Yibo, WANG Chunlu, et al. Research and implementation of high-speed packet processing in gigabit network IPS[J]. Journal of Chinese Computer Systems, 2006, 27(9): 1677−1681.
[11] 何鹏程, 方勇. 一种基于Web日志和网站参数的入侵检测和风险评估模型的研究[J]. 信息网络安全, 2015(1): 61−65. HE Pengcheng, FANG Yong. A risk assessment model of intrusion detection for web applications based on Web server logs and website parameters[J]. Netinfo Security, 2015(1): 61−65.
[12] GB/T 20984—2007, Risk Assessment Specification for Information Security[S].
[13] Ryza S, Laserson U, Owen S, et al. Advanced Analytics with Spark[EB/OL]. http://www.bokus.com/bok/978149 1912713/advanced-analytics-with-spark/,2016−01−22/2019−04−28.
[14] Harrinton P. Machine learning in action[M]. Greenwich: Manning Publications Co., 2012: 42−45.
[15] 陈胜, 朱国胜, 祁小云, 等. 基于机器学习的网络异常流量检测研究[J]. 信息通信, 2017, 30(12): 39−42. CHEN Sheng, ZHU Guosheng, QI Xiaoyun, et al. Research on abnormal network traffic detection based on machine learning[J]. Information & Communications, 2017, 30(12): 39−42.
Research on big-data-based anomaly detection system of railway time synchronization network
ZHANG Youpeng1, LI Xiang1, LAN Li1, 2, 3, ZHOU Jingyu1, LIU Siyu4, ZHANG Yan5
(1. School of Automatic & Electrical Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China; 2. School of Electronic & Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China; 3. Key Laboratory of Opto-technology and Intelligent Control, Ministry of Education, Lanzhou Jiaotong University, Lanzhou 730070, China;4. Xi’an Rail Transit Group Company Limited, Xi’an 71006, China;5. Party Cadre School of China Railway Taiyuan Group Co., Ltd, Taiyuan 030013, China)
In order to detect the hostile attack on railway time synchronization network (RTSN) quickly and accurately, a big-data-based anomaly detection system of RTSN was designed in this paper. First, K-Means, an unsupervised learning algorithm, was used to train partial data and find out the optimal clustering model, through which the system could identify the abnormal traffic flows. Then the system was tested by inputting some labeled data of time synchronization network (TSN) to see if it could satisfy the requirement of RTSN in both accuracy and speed. After the analysis of characteristics of identified abnormal traffic flows, the characteristics with strong correlation were obtained. By aiming at these characteristics and considering the structure of RTSN, a defense proposal was initially given to prevent hostile attack. The following conclusions are made: the clustering time of 70.434 682 s and accuracy of 98.36% of the system were able to meet the requirement of RTSN under a big data network environment. The representative characteristics of identified traffic flows, including time-based statistic characteristics and host-based statistic characteristics, can also offer technical references to improve the safety of RTSN.
traffic flow; anomaly detection system; K-Means; Spark; RTSN
U285.5
A
1672 − 7029(2020)02 − 0306 − 08
10.19713/j.cnki.43−1423/u.T20190478
2019−05−30
中国铁路总公司科技研究开发计划课题资助项目(2015X007-H);光电技术与智能控制教育部重点实验室(兰州交通大学)开放课題资助项目(KFKT2018-12)
张友鹏(1965−),男,甘肃庆阳人,教授,从事轨道交通自动化方向研究;E−mail:zhangyoupengypz@126.com
(编辑 蒋学东)
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
微型电脑应用(2019年8期)2019-08-22
北京航空航天大学学报(2017年7期)2017-11-24
雷达学报(2017年6期)2017-03-26
电子制作(2017年23期)2017-02-02
互联网天地(2016年1期)2016-05-04
