
基于胶囊网络的可变维度胶囊的研究
2020-03-16 03:17任强何良华
电脑知识与技术 2020年2期
关键词:图像分类
任强 何良华

摘要:胶囊网络是深度学习领域中最令人激动的创新,它通过将特征堆叠成向量中来表示不同特征之间的相关关系,并使用了动态路由算法计算相邻胶囊层之间的耦合系数。但是原始的胶囊网络中是存在缺点的,在原始的胶囊网络中胶囊维度是固定,而胶囊维度的多少和其包含的信息量是有关的,固定维度的胶囊并不能很好阐述胶囊的概念和表述模型的良好。针对胶囊网络这一缺点,我们提出了可变维度的胶囊网络这一想法,进行了简单的改进和初步的实验后,可变维度的胶囊在简单的数据集上取得了令人满意的效果,但也在较复杂的数据集上得到较差的结果。我们分析了它的原因,并计划为了对可变维度的胶囊网络进行进一步的改进。
关键词:胶囊网络;可变维度胶囊;图像分类
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)02-0204-02
1 概述
在过去的几年中,深度学习在许多计算机视觉任务中取得了巨大的成就,特别是卷积神经网络的发展给该领域带来了最先进的模型和算法。在传统的卷积神经网络中,神经元是标量的,模型无法学习神经元之间的复杂的位置等相关关系。但是在人的大脑中,神经元通常会协同工作,而不是单独工作。为了克服卷积神经网络的这一缺点,Hitton提出了“胶囊”的概念[1],胶囊是一组神经元的组合,它不仅表示特征(实体)存在的概率,而且也包含特征(实体)之间的位置关系。胶囊将经过特征提取之后的特征图中的标量(神经元)堆叠形成向量(胶囊)。在胶囊网络中,模型不仅在训练时考虑了特征的属性,而且考虑了特征之间的关系。
为了使得新提出的胶囊可以在模型中训练,不久后,Hitton提出了动态路由算法[2]使“胶囊网络”的想法得以实现。将神经元堆叠成向量(胶囊)后,可通过动态路由算法学习低层胶囊与高层胶囊之间的耦合系数[cij],通过耦合系数得到他们之间的映射关系,从而使得胶囊网络的模型得以训练。新提出的胶囊网络模型在MNIST[3]上实现了最先进的性能,并且在识别高度重叠的数字方面比卷积神经网络有更好的效果。
在原始的胶囊网络中,将低层上的所有胶囊与耦合系数[cij]相乘,得到高层上的胶囊。 新提出的胶囊网络模型有一些缺点。 首先,在原始模型中,胶囊被分为32组,每组由8个不同的卷积核所提取的特征图组成,因为用于提取特征的卷积核是不同的,所以每组的类型可以被认为是不同的。其次,因为每组胶囊的特征相关性不同,比如有的分组中不同卷积核的相关性较大,他们堆叠形成的胶囊就不能很好的体现特征的复杂性,将胶囊统一分为每组8个并不能很好地对模型进行训练。最后将胶囊维度进行人为分组相当于对模型的搭建添加了人为噪音,不好很好的训练得到参数的最优解。
为了解决以上提出的问题,本文对可变维度胶囊进行了深入研究,提出了基于随机数的胶囊维度划分方法和基于方差的胶囊选择方法。并在公开的图像数据集MNIST、Fashion-MNIST[4]、CIFAR10[5]和SVHN[6]上进行实验。
2 相关工作
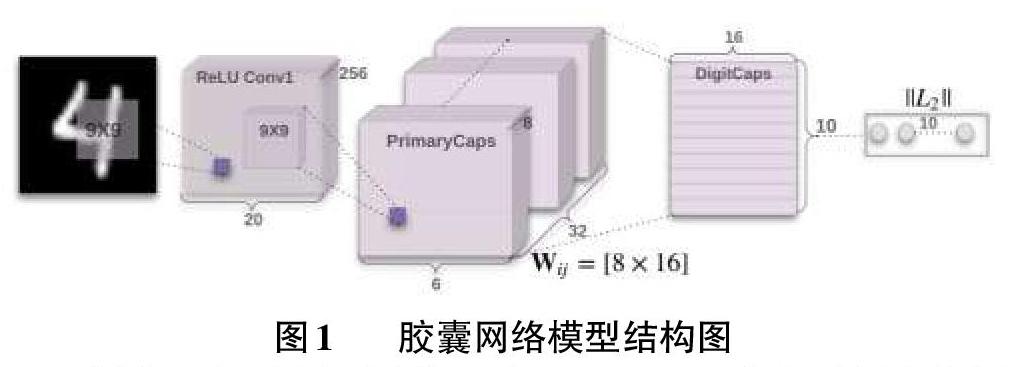
胶囊网络是Hitton提出的一种新的神经网络模型,旨在解决卷积神经网络的一些缺点。2017年,Hitton提出了胶囊网络的原始结构,该结构使用动态路由算法来训练胶囊层之间的参数,他们希望胶囊的输出向量的长度代表实体存在的概率。为了使胶囊更非线性,使用非线性挤压功能来确保将较短的胶囊收缩至几乎为零的长度,将较长的胶囊收缩至0~1之间的长度。胶囊网络的模型如图1所示。
从图1可以得出,图像经过ReLU Conv1卷积层提取特征后,由28[×]28[×]1变成了20[×]20[×]256,再经过PrimaryCaps层提取特征形成6[×]6[×]256的特征圖,接着将256个特征图分成32组,每组8个。这样,在原始胶囊网络结构中,每个胶囊的维度是8维。
胶囊的是一组神经元的集合,所以胶囊的长度可以看作胶囊中所含信息的多少。通过人为的设定参数,将胶囊网络中胶囊的维度设定为8维,针对不同的胶囊所包含的信息不同,统一设定为8维的胶囊并不能很好的表述模型。
3 可变维度胶囊
在原始胶囊网络论文中,胶囊的维度是固定的(8维),胶囊维度的多少代表胶囊中所含信息的多少。不同的卷积核提取的特征图,经过堆叠形成胶囊后所代表的信息是不同的,用固定的胶囊维度代表不确定的信息量是不合适的,所以我们提出了可变维度的胶囊。
3.1 利用随机数生成胶囊维度
在原始胶囊网络中,256个特征图被分为了32组,每组8个胶囊。我们仍然保留胶囊网络特征提取和之后动态路由的结构不变。使用256个特征图对胶囊进行分组,不同的是,我们使用随机数生成器,生成一系列随机数[r1,r2,... ,rn]([r1+r2+... +rn=256]),[r1,r2,... ,rn]代表胶囊的不同维度分组,随机数的生成如公式(1)所示。
公式(1)中的[random]()是一个随机中生成器,产生1~16的随机数整数,且这些随机数的和为256.
然后根据生成的随机数[r1,r2,... ,rn]对胶囊对维度进行划分,划分后对胶囊分为[n]组,每组分别为[r1,r2,... ,rn]个,然后根据动态路由算法求得耦合系数[cij],进而根据低层胶囊和耦合系数[cij]得到高层胶囊。
3.2 选择信息量最大的胶囊分组
通过3.1所述的方法,我们得到了由随机数生成的胶囊维度的低层胶囊。随机数的引入给胶囊的生成加入了一定的随机性,可能产生更好的分组,也可能产生更差的分组,因此我们使用了三组随机维度的胶囊。在一定的分布下,向量的方差越大,所包含的信息量就越大。因为经过特征提取后,特征图的分布是相同的。在训练过程中,我们根据胶囊的方差选择信息量更大的分组。
计算不同分组胶囊的方差总和,在每次训练的过程中,选择方差最大的那个胶囊分组,它包含的信息量最大。在进行训练时,信息量越大,对分类结果的预测的时候产生的贡献就越大,模型可以得到更好的性能。
4 实验
为了测试我们提出的可变维度胶囊对模型性能的影响,我们在4个公开数据集MNIST、Fashion-MNIST、CIFAR10和SVHN上对模型的分类结果进行了测试。对于数据集MNIST和Fashion-MNIST,我们使用和原始胶囊网络一样的数据预处理。对于数据集CIFAR-10,和SVHN,我们将图像的大小调整为32[×]32[×]3,并在每个方向上最多填充2个像素,且填充为零,并且不使用其他数据增强/变形。除了胶囊维度的改变,我们使用和原始胶囊网络一样的网络结构。
我们使用pytorch[7]深度学习库进行实验开发。对于训练过程,我们使用了Adam[8]优化器,其初始学习率为0.001,在每个时期之后降低了5%。我们将batchsize设置为128,每次训练128张图像。 该模型在GTX-1080Ti上进行了训练,每次实验训练了150轮。所有实验进行了三次,并对结果取平均值。
从表1可以看出,可变维度的胶囊在数据集MNIST和Fashion-MNIST上取得了和原始固定胶囊维度相似甚至高一些的结果。但是在数据集CIFAR10和SVHN上却取得了令人惋惜的结果。数据集MNIST和Fashion-MNIST是比较简单的图像数据集,它的分辨率是28[×]28[×]1的灰度图像,但是数据集CIFAR10和SVHN是32[×32×]3的彩色图像,相较于MNIST类的数据集,特征更加复杂,参数也需要更多。可变维度胶囊虽然胶囊的维度是随机的,但是也是在一定范围内随机,可能在这个范围内的胶囊维度对于复杂的数据集都不是很合适,所以采用了可变维度胶囊的模型,反而取得了较差的效果。
5 总结
在原始的胶囊网络中胶囊维度是固定,而胶囊维度的多少和其包含的信息量是有关的,固定维度的胶囊并不能很好阐述胶囊的概念和表述模型的良好。针对胶囊网络这一缺点,我们提出了可变维度的胶囊网络这一想法,进行了简单的改进和初步的实验后,可变维度的胶囊在简单的数据集上取得了令人满意的效果,但也在较复杂的数据集上得到较差的结果。我们分析了它的原因,并计划为了对可变维度的胶囊网络进行进一步的改进。
参考文献:
[1] Hinton G E,Krizhevsky A,Wang S D.Transforming auto-encoders[M]//Lecture Notes in Computer Science. Berlin, Heidelberg: Springer Berlin Heidelberg, 2011: 44-51.
[2] SABOUR S, FROSST N, HINTON G E. Dynamic Routing Between Capsules. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4-9 December 2017, Long Beach, CA, USA.
[3] LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE, 1998,86(11):2278-2324.
[4] . XIAO H, RASUL K, VOLLGRAF R. Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. CoRR, 2017, abs/1708.07747.
[5] KRIZHEVSKY A, HINTON G, OTHERS. Learning multiple layers of features from tiny images. Citeseer, 2009.
[6] NETZER Y, WANG T, COATES A, et al Reading Digits in Natural Images with Unsupervised Feature Learning. Neural Information Processing Systems Workshop.
[7] PASZKE A, GROSS S, MASSA F, et al PyTorch: An Imperative Style, High-Performance Deep Learning Library. Advances in Neural Information Processing Systems 32Curran Associates, Inc., 2019: 8024-8035.
[8] KINGMA D P, BA J. Adam: A Method for Stochastic Optimization. 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, Conference Track Proceedings,2015.
【通聯编辑:梁书】
猜你喜欢
计算技术与自动化(2017年2期)2017-07-12
现代电子技术(2017年10期)2017-05-17
现代电子技术(2017年3期)2017-03-04
现代电子技术(2017年1期)2017-02-16
现代电子技术(2016年22期)2016-12-26
