
基于唯密文数据的序列密码识别*
2020-03-25 07:34吉庆兵
通信技术 2020年1期
谈 程,陈 曼,吉庆兵
(中国电子科技集团公司第三十研究所,四川 成都 610041)
0 引 言
加密的基本原理是通过扩散和混淆的原则将有意义的明文信息变换成无意义的且随机性良好的密文。在不同的密码算法下,密文的随机程度必然存在一定的差异性,通过度量这些差异可在一定程度上实现对不同加密算法的识别。基于唯密文的密码识别技术的本质是挖掘出未知密文数据的表征其随机性的特征,将提取得到的特征与先验特征通过某种方式进行匹配,然后分析匹配结果,从而识别出该密文数据对应的密码算法。
基于唯密文数据的密码识别研究过去一直是研究热点,尤其是针对分组密码识别的研究。在前期工作中,针对几种常见分组密码开展了识别研究[1],当训练和测试密文样本用不同密钥生成时,AES与其他分组密码能够以90%以上的识别率进行区分,表明了不同算法下的密文数据中存在可区分的特征。
机器学习方法在基于唯密文数据的密码识别研究领域具有重要作用。Mishra等人将块长度和流检测法、熵重现分析法和决策树算法相结合[2],得到一种联合方法用于分析AES、DES和Blowfish算法的密文模式。Chopra等分别采用朴素贝叶斯法和K近邻法,对AES、3DES和Rijndael算法进行识别[3]。
分组密码识别研究主要集中于ECB模式,但是很多密码应用场景更多地采用了CBC或者与CBC相关的模式。也有文献对CBC模式下加密的密文数据进行了区分研究[4]。文献中的实验结果表明,CBC模式下的密码识别难度明显要高于ECB模式。
序列密码也称作“流密码”,与分组密码同属对称密码体制。对于分组密码,以一个分组或块为单位进行加密,先将明文数据分为多个固定长度的分组,然后对每个分组使用相同的加密函数和密钥进行加密。对于序列密码,初始密钥用于生成密钥流,密钥流长度一般等于待加密明文的长度。序列密码以比特或字节为单位进行加密,使用相同的加密函数(即异或)和不同的密钥(即密钥流的每个比特或字节)加密。因此,在相同长度密文段内,序列密码的密文特征没有分组密码明显,其密文特征分布比分组密码更发散,对序列密码的识别难度高于分组密码。本文主要针对RC4、A5/1和Trivium这3种常见的序列密码进行识别。
1 识别方案
1.1 密文特征提取
(1)设第k块中的4个字节值分别为A、B、C、D,令 g(A,B,C,D)=256A+B+(C+1)(D+1);
(2)变换A、B、C、D的顺序,由于g中第3和4个变量位置对等,则有12种排序方式,分别求得各排序方式下g的值,求得平均值为
(3)由于A、B、C、D处于0~255之间,故 Gk∈ [1,131071],而 F=(f1,…,fk,…,f131071)为构建的131071维密文文件特征向量,其中分量fk=|{i|Gi=k,i∈ [1,N]}|;
(4)对其他密文文件按照以上步骤分别得到密文特征向量。
1.2 识别模型构建
本文将继续沿用之前文献[1]中的识别模型。进一步地,通过Adaboost算法[5]对采用的分类器进行改进,得到对原始分类器进行加权的强分类器后替换原有分类器。
2 序列密码识别结果及分析
对RC4、A5/1和Trivium这几种常用序列密码进行识别。RC4算法按照密钥长度40 bit、64 bit和 128 bit分为3种,记作RC4_40、RC4_64和RC4_128。A5/1算法按照使用全密钥流、下行密钥流和上行密钥流加密分为3种,记作A5/1、A5/1_down和A5/1_up。对应各算法,分别在100个明文文件下加密得到对应的100个密文样本,且明文均为可读的文本数据。其中,80个密文样本用于训练,20个样本用于识别测试。
2.1 密钥一致情形
当训练和测试密文样本对应密钥一致时,识别结果见图1。
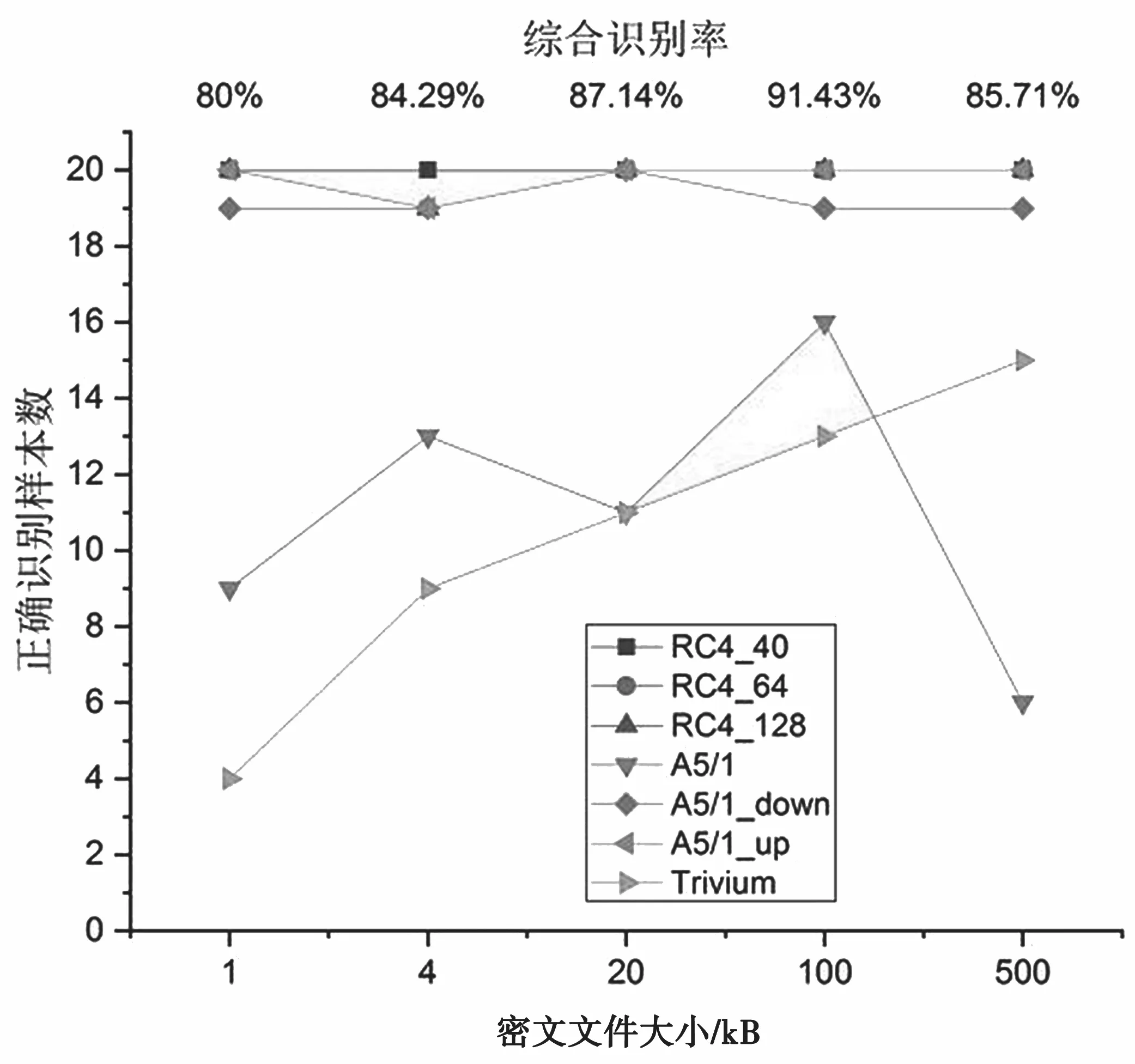
图1 密钥一致时识别结果
从图1可以看出,在训练和测试密文样本密钥一致时,RC4_40、RC4_64、RC4_128、A5/1_down和A5/1_up几乎都正确识别出了各自对应的20个样本,A5/1和Trivium识别率较低。另外,在密文文件为100 kB时,7类密文样本的综合识别率达到了最高值91.43%。
2.2 密钥不一致情形
当训练和测试密文样本对应密钥不一致时,识别结果见图2。
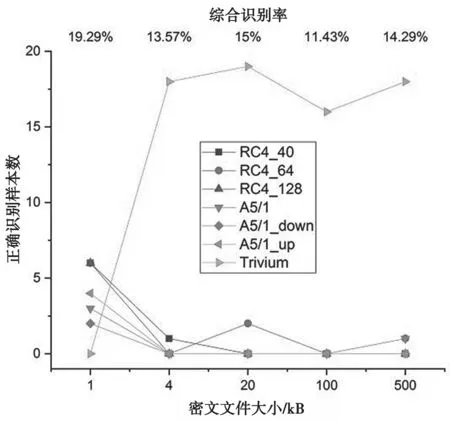
图2 密钥不一致时识别结果
由图2可见,综合识别率处于1/7位置附近,即随机猜测概率,远远低于密钥一致情形的识别率。分别单独对RC4系(RC4_40、RC4_64和RC4_128)和A5/1系(A5/1、A5/1_down和 A5/1_up)加密数据进行识别,结果见图3和图4。
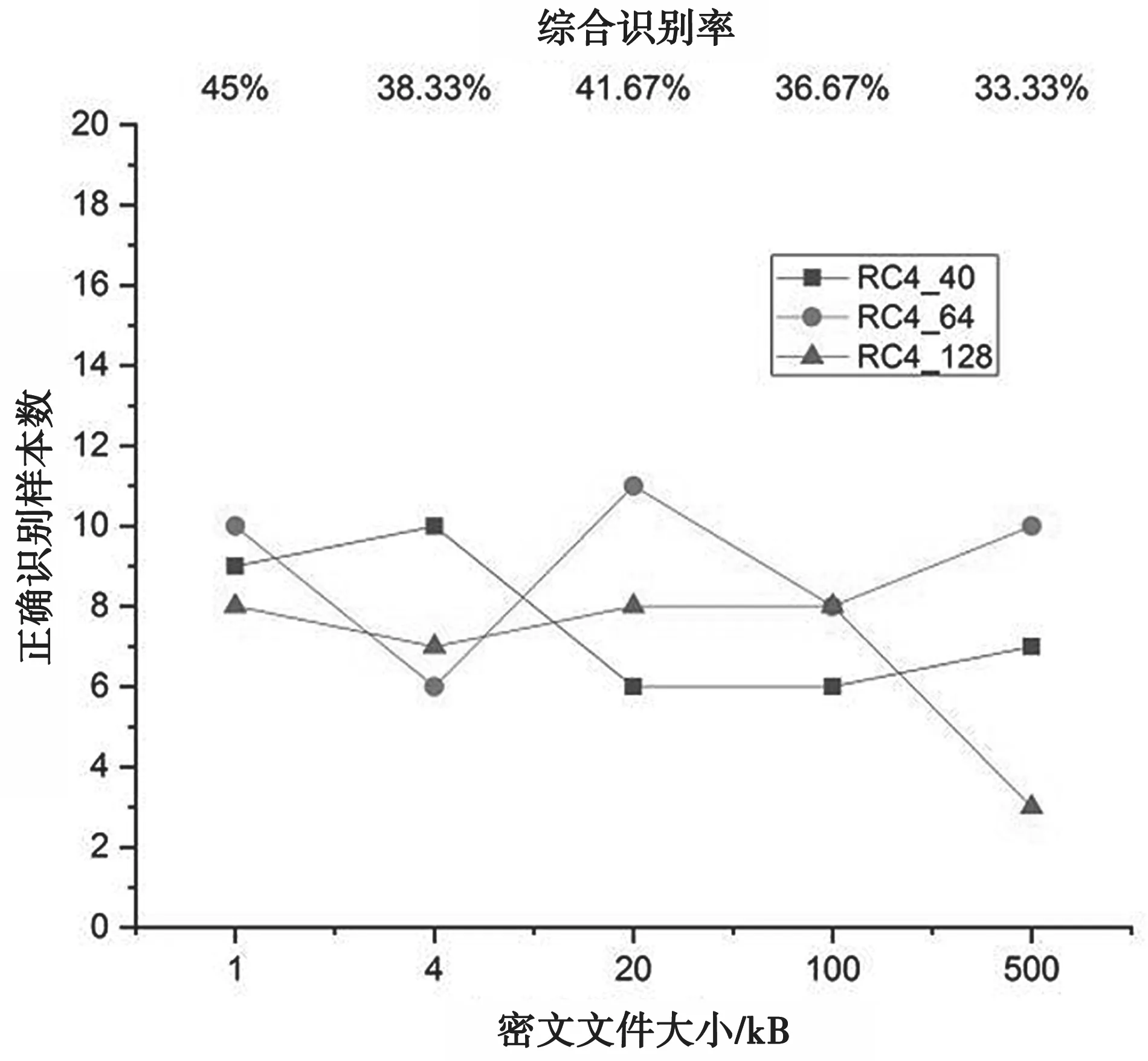
图3 密钥不一致时RC4系加密数据识别结果
比较图3和图4,RC4系加密数据整体比A5/1系加密数据识别率稍高,比随机猜测概率1/3也稍高。可见,训练和测试密文样本对应密钥不一致情况下,多分类识别率较低。
考虑RC4_128、A5/1和Trivium之间的两两识别,即二分类识别,识别结果见图5。

图4 密钥不一致时A5/1系加密数据识别结果
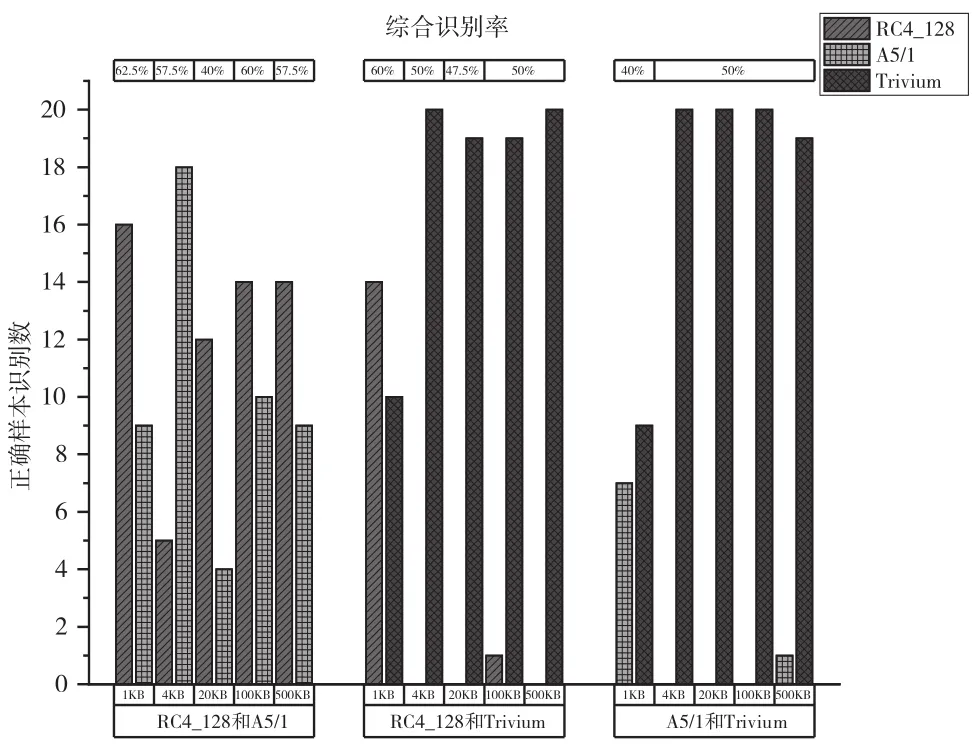
图5 密钥不一致两两识别结果
图5中识别率对应下方两种类型算法的40个样本。由图5可见,RC4_128和A5/1间的识别率整体稍高,RC4_128和Trivium以及A5/1和Trivium两种情形下的识别基本呈现一边倒现象,即全部样本识别为同一种加密类型。
3 序列密码和分组密码混合识别
由第2节可知,序列密码在密钥不一致时识别比较困难。真实环境下,一般待识别的密文数据加密密钥一般是未知的,因此后面章节仅考虑训练和测试密文样本对应密钥不一致的情形。
这节针对序列密码和分组密码进行混合识别,分组密码选择AES、3DES和Blowfish算法,序列密码选择RC4_128、A5/1和Trivium算法。
3.1 序列密码和AES混合识别
AES是目前最常用的商用密码算法,序列密码和AES混合识别的结果见图6。

图6 序列密码和AES混合识别结果
从图6可以看出,RC4_128、A5/1和Trivium与AES混合识别的综合识别率均只有50%。当密文文件100 kB和500 kB时,识别结果出现了一边倒现象。
3.2 序列密码和3DES混合识别
3DES是DES算法的一种强化变形,和RC4_128、A5/1和Trivium混合识别的结果见图7。

图7 序列密码和3DES混合识别结果
从图7可以看出,当密文文件20 kB以上时,识别率达到了100%;当密文文件为4 kB以上时,3种情形下的混合识别率分别达到了97.5%、95%和85%以上;当密文文件为1 kB时,出现了一边倒现象。
3.3 序列密码和Blowfish混合识别
Blowfish与AES、3DES一样,也属于较常见的分组密码算法,其对应的混合识别结果见图8。

图8 序列密码和Blowfish混合识别结果
对比图7和图8,呈现的识别结果基本上差不多,表明当密文样本文件足够大时,序列密码与某些分组密码密文差异性比较明显,可以进行混合识别。
4 基于短密钥流的序列密码识别
所有密文样本都是基于单次初始化生成的密钥流进行加密产生,密钥流较长,因此导致在训练和测试密文样本密钥不一致的情形下难以识别。对于待加密数据量较小情形,仅需产生较短的密钥流用于加密。
这节对应每种算法分别产生60个测试样本。考虑16 Byte、32 Byte和64 Byte这3种长度的密钥流,继续针对RC4_128、A5/1和Trivium算法进行识别,识别结果见图9、图10和图11。
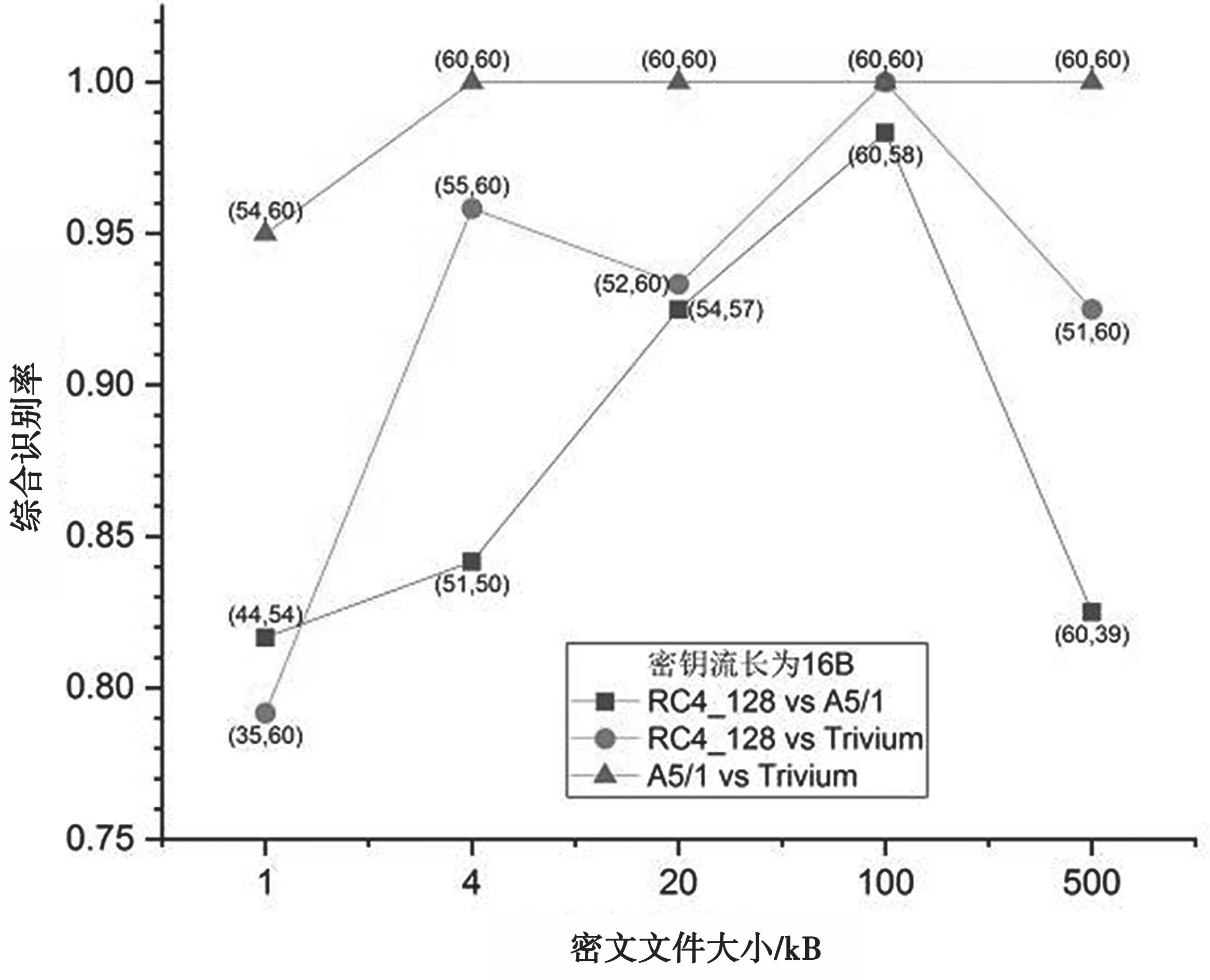
图9 密钥流长16 Byte时的识别结果
图9、图10和图11中,括号内两个数值分别表示对应两种密码算法类型正确识别的密文样本数。可以看出,A5/1和Trivium间的识别率要比其他两种情形更高。此外,RC4_128和Trivium之间的识别率整体上优于RC4_128和A5/1。
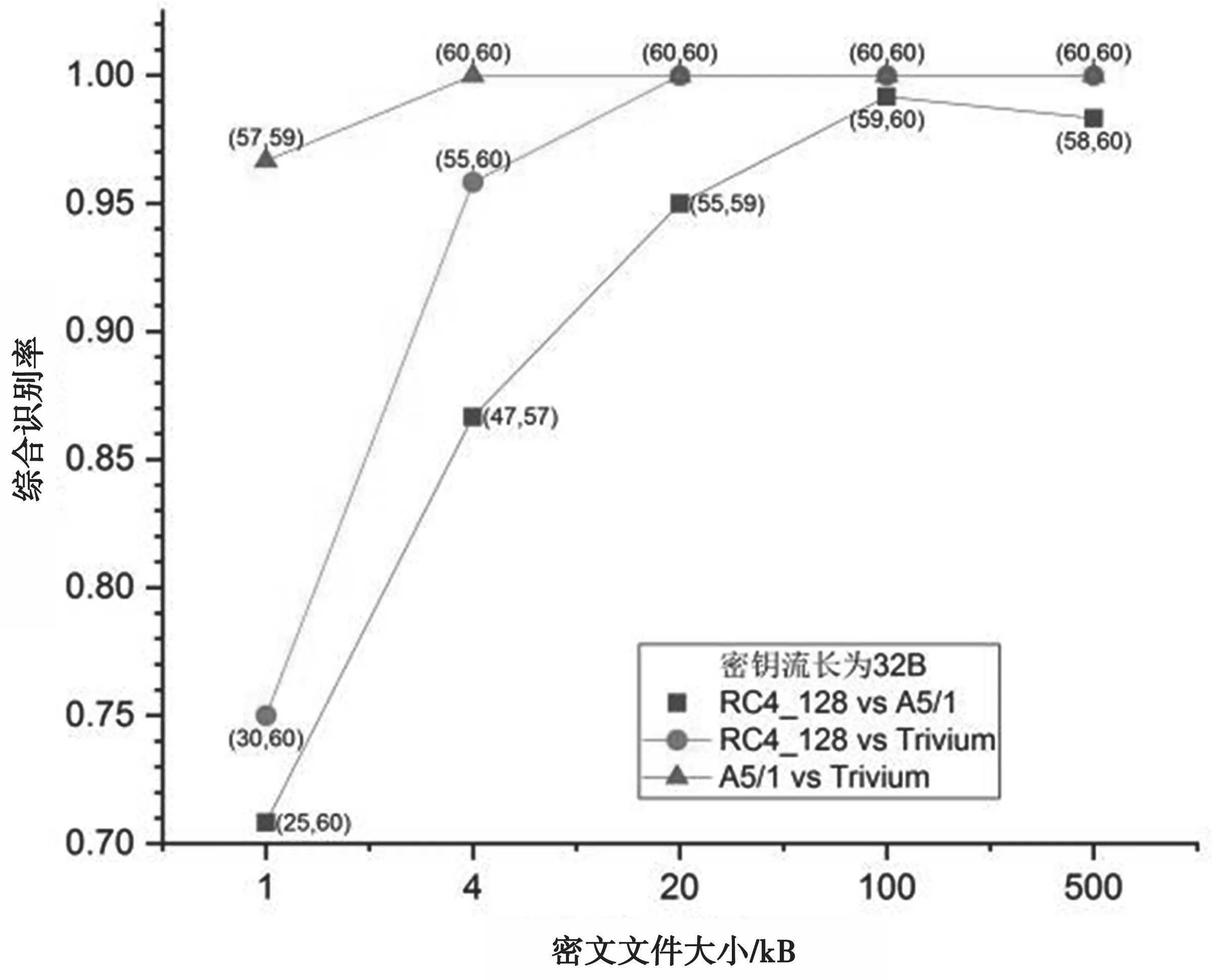
图10 密钥流长32 Byte时的识别结果

图11 密钥流长64 Byte时的识别结果
当密钥流长32 Byte时,整体识别率稍高于密钥流长16 Byte的情形。在这两种情形下,所有识别率在密文文件为100 kB时达到最大值,在1 kB时达到最小值,RC4_128和A5/1间识别率处于70.83%~99.17%,RC4_128和Trivium间识别率处于75%~100%,A5/1和Trivium间识别率处于95%~100%。当密钥流为64 Byte时,整体识别率最低。在该情形下,RC4_128和A5/1间识别率以及RC4_128和Trivium间识别率急剧下降,出现了一边倒情形,而A5/1和Trivium间识别率下降不是很明显。只要密文样本文件在4 kB以上,识别率就能达到90%以上;当密文样本文件在20 kB以上时,识别率达到了100%。
5 结 语
针对基于唯密文数据的序列密码识别难题,以RC4、A5/1以及Trivium等序列密码为研究对象,提出了一种有效的序列密码识别方法。研究发现,密文文件大小和识别对象均会对识别结果产生一定影响。在训练和测试密文样本对应密钥不一致时,虽然识别结果不是很理想,但是在短密钥流情形下能够达到较高的识别率。在密文样本文件大小为4 kB以上时,尤其是A5/1和Trivium之间的识别率基本上能达到90%以上。此外,与3DES、Blowfish分组密码间的混合识别也能够达到较好的识别结果。在密文样本文件为4 kB以上时,识别率均能达到85%以上。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
计算机仿真(2021年10期)2021-11-19
北京电子科技学院学报(2020年2期)2020-11-20
网络安全技术与应用(2020年11期)2020-11-14
沈阳工业大学学报(2020年2期)2020-04-11
中国听力语言康复科学杂志(2019年3期)2019-06-24
小型微型计算机系统(2018年9期)2018-10-26
中国高新技术企业(2017年5期)2017-05-05
