
粒子群优化三维模型相似性评价
2020-03-28 12:26孙静懿韩文军
机械设计与制造 2020年1期
闫 洁 ,孙静懿 ,韩文军 ,2
(1.长春金融高等专科学校,吉林 长春 130028;2.电子科技大学中山学院,广东 中山 528400)
1 引言
随着CAD/CAM等数字化技术的发展,设计资源的重用在产品的创新设计中正变得越来越重要,日益增多的三维CAD模型为产品设计带来了大量的可重用资源。CAD模型成果的累积成为核心竞争力的重要智力资源。研究和统计表明,产品的工艺结构及其功能等方面存在较强的继承特性,在产品设计过程中,约40%是重用过去的部件设计,约40%是对已有设计部件的微小修改,而只有约20%是完全新的设计[1],因此,如何从海量产品的模型库中有效挖掘典型结构并合理重用,是提高开发效率的重要保障,基于三维模型检索的设计重用技术近年来成为研究热点之一。如何从海量产品模型中快速、有效地查找适合设计重用的局部结构已成为产品开发各环节的一个迫切需求[2]。
目前,基于实例推理[3]、基于模块化[4]和基于检索[5]等多种设计重用算法已被广泛使用,可有效提高产品设计效率和质量,文献[3]将设计知识融入到基于实例的推理中,实现知识的辅助决策。提高典型模具的设计效率和重用率;文献[4]提出了基于模糊关联分析与求解的复杂产品的模块化设计,对产品设计中出现的不确定信息进行转化与传递。文献[5]通过求解面属性邻接图的顶点和边的相容矩阵,实现对相似模型的检索,提出基于模糊集的三维CAD模型相似性评价。由于机械产品CAD模型包含较多几何及拓扑信息,基于实例推理和基于模块化的设计重用方法可靠性不高,同时由于在现代设计中三维CAD模型设计信息的复杂化,传统的基于检索的数字化设计重用方法不再适用,基于内容的模型典型结构检索方法提供了全新的技术方式,已成为近年研究热点,其主要通过设计一套有效的匹配算法,在三维CAD模型库中搜索含有与需求结构具有最优相似度的模型用以设计重用。文献[7]基于模拟退火算法提出的相似模型检索方法,利用属性邻接图建立设计所需结构与已有模型之间的关联图,通过模拟退火算法检索关联图中的最大主团完成相关所需结构的挖掘和相似评价;文献[8]使用蚁群算法搜索源模型与目标模型之间的最优面匹配序列,以最优面匹配序列为基础来计算两个模型之间的相似性文献[8]以自由草图进行建模,对模型进行形状分布比较来提高模型的形状检索精度;文献[9]提出的基于形状分布算法的检索方法,通过比较模型随机点之间距离(D2)统计特征的形状分布曲线实现模型的相似性评价;文献[10]基于遗传算法对模型相似度计算时的权重进行优化,提出基于多特征加权融合的典型结构检索算法;文献[11]通过构造CAD模型属性邻接图,借助神经网络进行CAD模型的自动聚类;
三维CAD模型的相似性评价对模型重用至关重要,直接关系到模型中典型结构检索的效率和可靠性[12],为此,在前人研究基础上,文中利用模型面组成边数差异,以此构建模型的面相似性评价矩阵,然后以粒子群算法来搜索矩阵中的的最优面匹配序列,通过最段匹配序列实现对源模型和目标模型的相似性进行评价,为三维CAD模型中主模型结构的智能化检索和有效重用提供依据。
2 模型相似矩阵构建
三维CAD模型通常由面元素组成,面元素形状的差异,形成了模型的千差万别,在CAD模型检索过程中,面的邻接相似程度直接影响了模型检索的精确性。因此通过累积两个模型间的面相似情况,可以得到重用前模型的相似情况。如果组成两个面的边的数目相差较小,则两模型存在较高的相似度;反之,则相似度较低。描述模型的面相似性使用的模型示例,图中模型A包含u1,u2,…,u7七个面,模型 B 由 v1,v2,…,v7七个面组成,如图 1 所示。
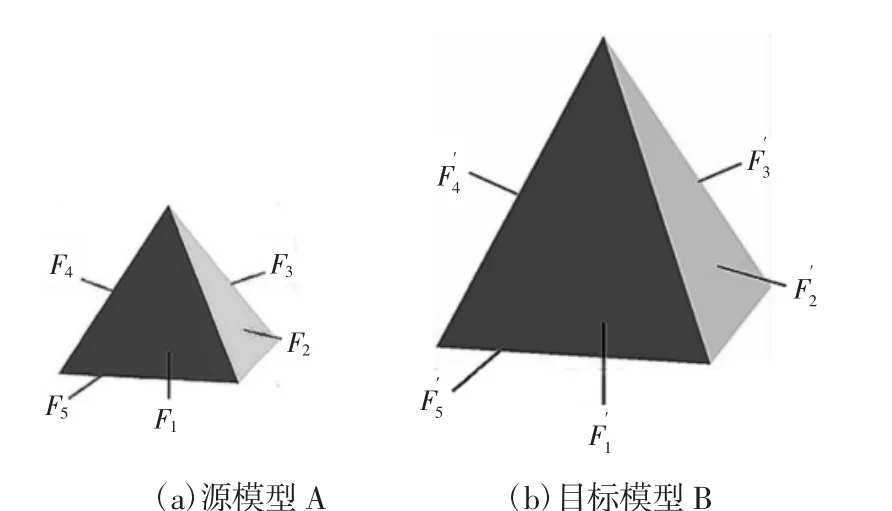
图1 模型面相似计算示例Fig.1 Example of Similarity Calculation for Faces of Models
用A[x,y]表示面x与面y的邻接关系,其计算过程为:

则图1中两个示例模型的相似度可以通过式(2)来计算
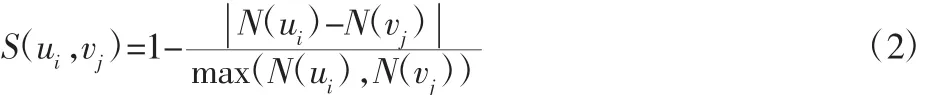
式中:N(u)—某模型的面含有的组成边数;max(·)—取最大值。
式(1)说明当S(ui,vj)值越大,说明两个面的边数N(ui)与N(vj)差异越小,两个面的形状越相似,使用S(ui,vj)可以构造待评价两模型的面相似度评价矩阵SAB,两模型的面序列分别为矩阵的行和列。
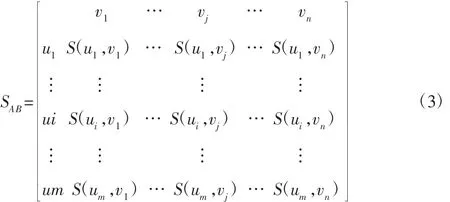
式中:m和n—待评价的两模型的面数,为便于后续相似性分析,如果两模型面数不一致,则当m>n时,将SAB进行转置处理。
组成两模型的面的相似度影响着两个模型的相似性,两模型间的面相似度越高,两模型之间的相似性越高[6]。而对于两个待相似性评的模型,其对应的组成面存在着不同的对应方案,为此文中以面相似矩阵为参数,通过粒子群算法来匹配两模型之间的面最优匹序列,在此基础上评价两模型整体的相似情况。基于粒子群算法的最优面匹配方法实现了局部典型结构的的空间位置变换,使空间中处于不同位置和方向的典型模型结构能够重合。
3 改进粒子群优化模型相似评价
3.1 改进粒子群算法最优面匹配
粒子群算法以种群个体间的学习为核心,在搜索空间中粒子通过学习机制向最优解区域飞行,调节参数少且收敛速度快,在很多领域得到了应用。设d维空间种群规模为p,xt为粒子t所在的位置,其表示由粒子群算法得到的序列号向量,vt为粒子t的飞行速度表示算法经过 k 次迭代后全局和粒子个体的最优位置,相应的适应度函数分别表示为fGbest和fPbest。算法在实现过程中通过不断迭代更新现最优匹配序列的搜索,其过程为[8]:
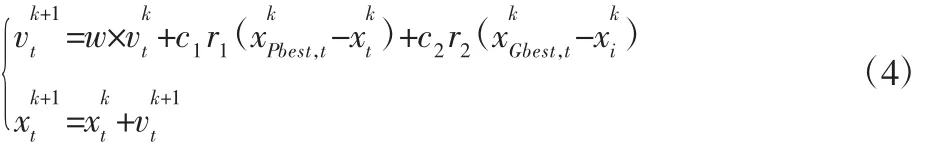
式中:k—当前迭代数;w—惯性因子;c1和c2—算法优化的学习因子;r1和r2在迭代过程中在[0,1]内随机取值。
针对经典粒子群算法在面匹配方面的不足,文中先采用基因表达式对粒子进行编码,并设计相应飞行方法,同时通过环状拓扑和突变算子,提高算法搜索效率和避开局部最优。
将语法树节点自上而下、从左到右罗列,得到基因表达式的编码区,并其追加非编码区以消除叶节点出现运算符,表达式首段由各种函数、运算符以及终止符等构成,而尾段仅有终止符号,基于基因表达式的粒子编码,如表1所示。

表1 改进算法粒子编码Tab.1 Improved Algorithm Particle Coding
为使模型在预设精度达到最优的简洁性,约束表1中编码的有效长度,当实际编码超过约束长度L时,设置罚因子对粒子进行评价。
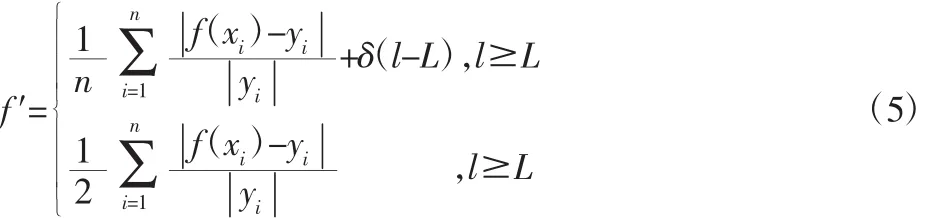
式中:f′—增加罚因子后的适应度值;δ—罚因子;l≥1—实际长度,适应度值会随着编码实际长度的增加而增大,使超长部分的粒子的适应度变差,并在迭代中淘汰。
粒子向最优个体学习即为向学习目标飞行,当前粒子为t,当t向xkGbest,t学习时,先随机选择xkGbest,t的节点,然后以选中节点替代t节点,t向 xkPbest,t的学习方式与向 xkGbest,t相同,仅目标不同。如图 2所示为采用的R-邻域环状拓扑结构,图中为种群规模,将粒子顺序排列并首尾连接,每个粒子维护一个其自身与相邻的2R个粒子共同组成的感知邻域,粒子在飞行学习过程中会以其感知邻域最佳粒子(rbest)进行最优信息传递,而当与邻域外粒子交互信息时,则以至少一个节点粒子为媒介,而此时媒介粒子可将自身的部分结构信息融入优化过程,从而增强粒子迭代学习的鲁棒性。
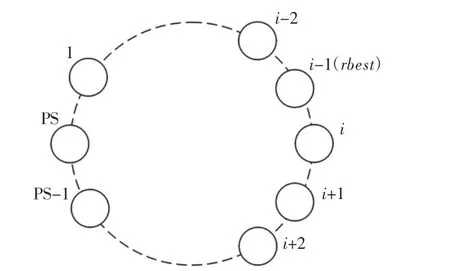
图2 R-邻域环状拓扑结构Fig.2 R-Neighbor Ring Topology
为避免协同搜索产生的局部最优,根据变异思想先产生一个不大于编码有效长度的随机数作为待突变节点的个数,然后随机生成编码区内突变位置,并对其节点进行突变,当随机突变位于编码首段,则从运算、终止符等随机选择替换,而当位于尾段,以终止符随机替换。为缓解种群趋同影响,当某位置出现多个相同粒子时,仅保留一个而其余粒子通过突变驱散原位置。相同粒子的检测方法为先判断适应度值,适应值不相等则编码结构必然不同;适应度值相等时,再进一步进行编码结构判断,当两粒子节点不同进,则判定粒子编码结构不同。
根据以上描述,基于改进粒子群优化的模型最优匹配面匹配过程哪图3所示。图中:PM—突变概率;MI—最大迭代次数;rand—(0~1)之间的随机数。
3.2 基于最优匹配面的模型相似评价
通过粒子群算法可以搜索得到两个模型间的最优位置xt=(j(1),j(2),…,j(m)),从而得到两个模型之间的最优面匹配序列(1,j(1)),(2,j(2)),…,(m,j(m)),根据最优匹配序列提取SAB中元素,通过相似性累积可以得到两个模型的整体最终相似性评价,即:
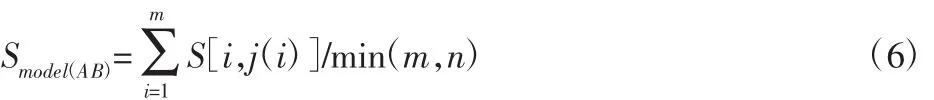
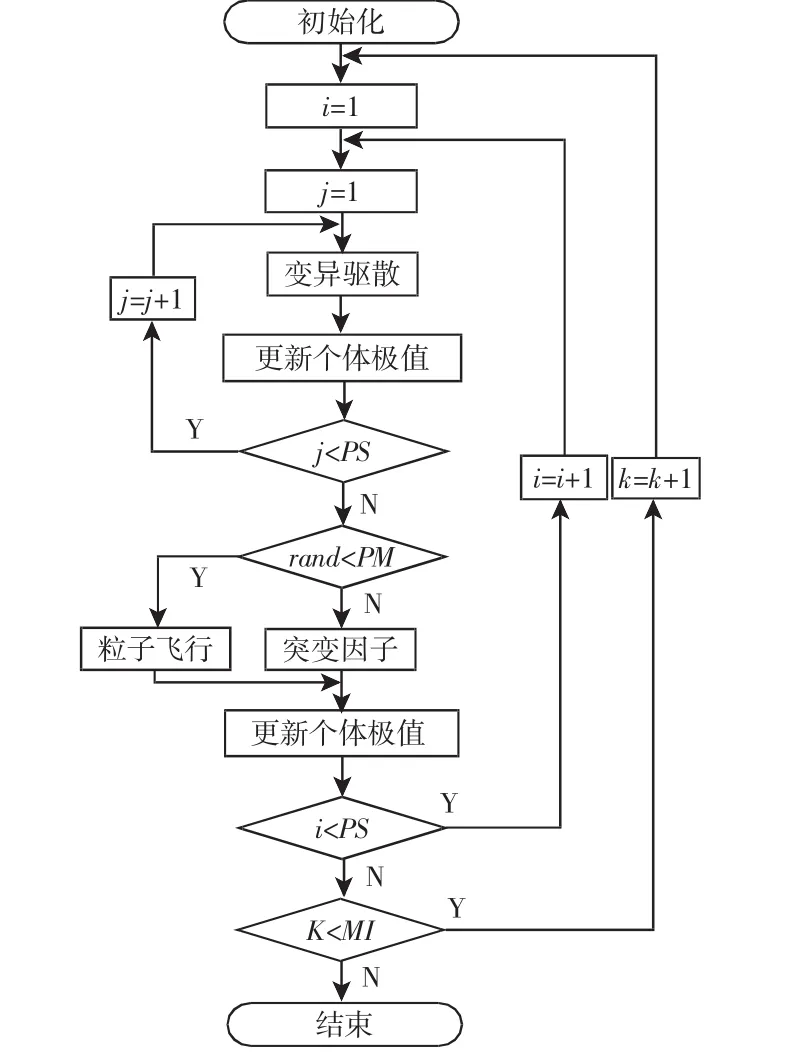
图3 改进粒子群优化的最优面匹配算法Fig.3 Improved Optimal Surface Matching Algorithm
4 实验验证分析
为验证提出算法的有效性,以Open CASCADE为平台构造几何模型,选取普渡大学ESB模型库[12]中的部分模型,在Inte(R)CoreTMi7-7700HQ CPU,16G内存的计算机硬件下进行实验。
4.1 算法有效性实验
从模型中选取红色标记的典型结构对其进行挖掘,并在模型库中得到的返回模型,如表2所示。可以发现,所提算法可以将带有该局部结构的模型从模型库中全部检索出来,去掉了一些基本相同的模型,选取了16个具有代表性的模型进行了显示。从返回模型中可以看出,典型相关结构往往隐藏在外形各不相同的三维CAD模型中,而所提算法可以有效地将隐含典型结构的CAD模型进行推送。

表2 算法有效性实验结果Tab.2 Experiment Result of Proposed Algorithm
4.2 算法性能比较实验
为充分验证文中算法的模型相似性评介性能,选取20个经典重用模型结构,以70%的相似度为评价阈值,以通用ESB模型库中搜索存在经典结构的模型,每个经典结构进行50次重复实验,取平均值,然后20个经典结构的实验结果再进行平均,得到每个算法的平均查全率和平均查准率,获得PR曲线。所提算法与基于模拟退火算法(Wol-Sim)[10]和基于蚁群算法(Acs-Sim)[11]的模型相似性评价算法在ESB模型库中进行相似性模型搜索得到的PR曲线,如图4所示。PR曲线的理想结果为查准率等于的恒定直线,对于实验结果,曲线位置越靠近理想曲线,说明算法的相似性评价性能越好,对模型的检索精度越高,从图4曲线结果看出,所提算法的重用结构检索性能优于Acs-Sim和Wol-Sim算法。
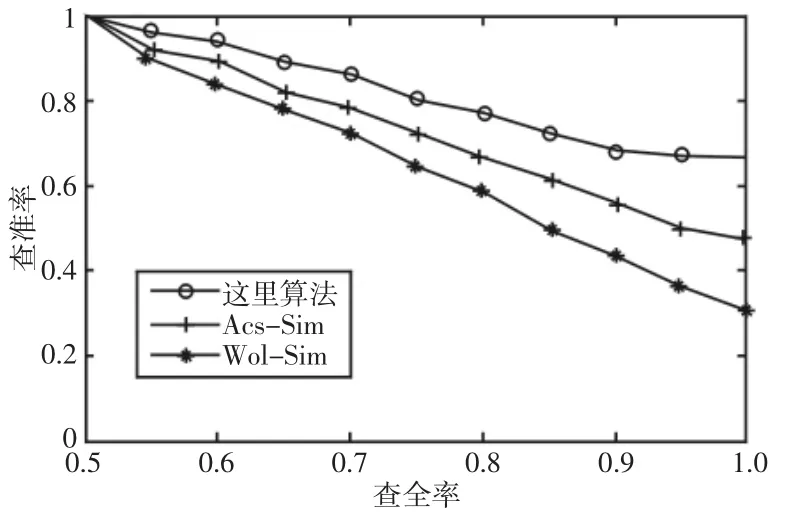
图4 实验结果平均PR曲线Fig.4 Average PR Curve of Experimental Results
5 结束语
为实现典型模型结构的高效重用,提出了基于粒子群算法优化的CAD模型典型结构相似性评价算法,算法首先由组成模型各面的边的数目构造相似性评价矩阵,然后以此为描述体,通过粒子群算法搜索两模型的面最优匹配序列,最后根据搜索到的面最优序列提取并计算面相似度,进而对模型整体的相似度进行计算。通用ESB模型库实验结果表明,与已有算法相比,所提算法可以更准确地描述三维模型的典型结构相似性,有助于典型结构的准确挖掘和设计重用。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
中原商报·科教研究(2021年4期)2021-03-03
河北画报(2020年8期)2020-10-27
中国科技纵横(2017年1期)2017-03-10
浙江大学学报(工学版)(2016年2期)2016-06-05
专利代理(2016年1期)2016-05-17
湘潭大学学报(哲学社会科学版)(2015年5期)2015-11-25
会计之友(2014年28期)2014-10-13
俄罗斯问题研究(2013年1期)2013-03-11
质量与标准化(2010年5期)2010-05-03
