
结合SUR与因子效应原则的多响应质量设计①
2020-04-01 09:59汪建均屠雅楠马义中
管理科学学报 2020年12期
汪建均, 屠雅楠, 马义中
(南京理工大学经济管理学院, 南京 210094)
0 引 言
产品质量不仅是企业的生命线,更是在全球市场上赢得顾客的关键,因此连续性质量改进已经成为世界各大企业永恒追求的目标.现代质量工程的主流观点认为:波动是导致产品产生质量问题的根本原因.因此,为了改进和提高产品质量,必须最大限度地减小和控制围绕设计目标值的波动.如何减小或控制产品实现过程中的波动,已经成为连续质量改进活动的核心内容[1].质量设计应用于产品形成的早期阶段,能够从源头上查找导致产品产生缺陷的原因,因此通常认为在产品设计阶段实施质量改进活动是最具有生产效率和成本效益的生产管理方法[2].近年来,产品设计趋于复杂化,顾客需求层次也呈现多样化,在产品的质量设计过程中往往需要同时考虑多个质量特性[3],因此考虑多质量特性的优化设计在连续质量改进活动中显示出越来越重要的作用与地位[4].
响应曲面方法涉及统计试验与数据分析、模型构建方法以及数值优化技术等一系列的连续质量改进方法或技术[5].响应曲面方法(response surface methodology, RSM)已经广泛地应用到产品或过程的连续质量改进活动中,成为了工业试验的核心[6].因此,基于RSM的多质量特性优化设计方法已引起众多研究者的关注,并取得了一系列新的研究成果[4].通常来说,以质量设计为基础的连续质量改进活动主要由变量筛选、响应建模和参数优化三个阶段所构成[7].在变量筛选阶段,研究者旨在通过科学的试验设计,筛选出响应曲面模型的显著性变量,从而为后续的响应曲面模型构建奠定坚实的基础.著名统计学家Wu和Hamada[8]在其经典著作《试验计划、分析与参数设计优化》中指出“因子效应原则(效应稀疏原则、效应排序原则以及效应遗传原则)能够评判因子设计结构的合理性,是否考虑了因子效应原则是区分一般回归问题与试验设计问题的关键,因此考虑因子效应原则的变量筛选对提高产品或过程的设计质量具有重要的意义”.在响应建模阶段,研究者旨在通过响应曲面模型反映试验因子与多质量特性之间的函数关系.然而,正如著名统计学家Box等[9]所言 “所有的模型都是错误的,但是有些模型是有用的”.传统的响应曲面建模方法往往忽略模型参数[10]或模型结构的不确定性[11]以及响应预测值的波动问题[12],不仅可能导致得到不科学的研究结果,而且将极大地降低了试验结果的可重复性.在参数优化阶段,研究者旨在通过构建稳健可靠的目标函数和高效的优化算法,寻求一组最佳的参数设计值,使得多个质量特性同时满足设定的目标值.多优化目标之间的冲突、多响应过程的稳健性度量以及优化结果的可靠性已成为该阶段需要重点考虑的研究问题.上述三个阶段的质量设计问题往往相互叠加、相互影响,通常会造成响应预测值与设计目标值之间存在较大的波动.然而,以往的研究往往关注于其中某个阶段的问题,未能从连续质量改进的视角全面地系统考虑上述多质量特性的质量设计问题.为此,本文将在SUR响应曲面的贝叶斯建模与优化框架下,首先,结合因子效应原则筛选出显著性的模型变量;然后,在此基础上运用贝叶斯抽样技术构建多变量过程能力指数;最后运用混合遗传算法对所构建的贝叶斯多变量过程能力指数进行参数优化,从而获得产品或过程的最佳参数设计值.
1 国内外研究现状及分析
近年来,随着以质量设计为基础的连续质量改进活动在企业中广泛应用和推广,以响应曲面建模为主的质量设计问题引起一些研究者的广泛关注和重视.在响应曲面模型变量的筛选阶段,一些学者提出了一系列新颖的研究方法.例如,Beattie[13]针对超饱和试验设计,在随机搜索的基础上,结合贝叶斯因子方法提出了一种两阶段的因子筛选方法.Song等[14]针对因子数远大于试验次数的超高维试验设计,提出一种基于随机近似蒙特卡洛(stochastic approximate Monte Carlo,SAMC)算法的两阶段贝叶斯变量选择方法.该方法首先将高维数据切割成许多子集,从每个子集中筛选因子,然后将筛选出的因子进行汇总,从中识别出显著性因子.针对非正态响应的部分因子试验,当筛选试验所涉及的因子数目较大时,汪建均和马义中[15]提出基于广义线性模型(generalized linear models,GLM)的贝叶斯变量选择与模型选择方法.该方法通过经验贝叶斯先验考虑了模型参数不确定性的影响,然后在广义线性模型的线性预测器中对每个变量设置一个二元变量指示器,在此基础上建立起变量指示器与模型指示器之间的转换关系,然后利用变量指示器与模型指示器的后验概率来识别显著性因子与选择最佳模型.上述方法虽然都筛选出了模型的显著性变量,但是在因子筛选或变量选择过程中忽略了因子效应原则的影响.因此,上述研究结果往往只是统计意义上的显著,所获得研究结果可能并不符合试验设计的因子效应原则.为此,一些学者在进行响应曲面建模时考虑因子效应原则以便筛选出更加符合实际的显著性变量.例如,针对含有复杂别名的试验设计问题,Chipman等[16]在一般回归模型基础上考虑因子效应原则,并运用贝叶斯变量随机搜索方法来识别显著性因子,提出了一种新的贝叶斯变量选择方法.针对两水平的部分因子试验设计问题,Bergquist等[17]在响应曲面建模过程中依次考虑效应稀疏原则、效应层次原则和效应遗传原则,提出了一种新的贝叶斯变量选择方法.针对含有复杂别名结构的非正态响应部分因子试验,汪建均等[18]在广义线性模型的框架下将因子效应原则融入到了模型参数的先验信息之中,提出了一种多阶段的贝叶斯变量选择方法.Noguchi等[19]提出了一种改进的贝叶斯LASSO (least absolute shrinkage and selection operator, LASSO)方法.该方法将效应遗传原则和效应层次原则加入LASSO模型,并利用马尔科夫蒙特卡罗(Markov chain Monte Carlo, MCMC)方法计算了各因子和模型结构的后验概率.Taylorrodriguez等[20]提出考虑因子效应遗传原则的贝叶斯变量选择方法.该方法为模型空间设定不同的先验,并利用MH算法搜索符合遗传效应原则的模型.针对单个质量特性的稳健参数设计问题,欧阳林寒等[21]考虑了模型参数以及模型结构不确定性的影响,结合贝叶斯模型平均方法考虑了因子效应原则,从而获得更加符合实际、更为精确的响应曲面模型.上述研究往往只涉及到单响应情形下的变量筛选问题,很少涉及到多响应的变量筛选以及后续的响应曲面建模与参数优化问题.
在响应曲面模型构建过程中,模型参数和模型结构的不确定性以及响应预测值的波动问题引起一些研究者广泛的兴趣和普遍的关注.针对模型参数和模型结构不确定性,研究人员通常运用置信区间或贝叶斯方法开展相关的研究.例如,针对多响应优化中模型的不确定性问题,He等[11]通过拟合响应曲面模型的置信水平考虑了模型不确定性对优化结果的影响,从而构建出了一种解决多响应曲面优化问题的稳健理想函数.该方法由于考虑模型预测结果的不确定性,因此能够在实践中获得比传统理想函数更为可靠的优化结果.针对多响应优化设计的问题,Ouyang等[22]运用多响应的预测区间考虑了模型不确定性的影响,提出了一种新的质量损失函数.该方法不仅克服了传统质量损失函数忽视模型不确定性对研究结果的影响,而且所提的优化策略能够适应不同的特殊情形(如不考虑模型不确定性的最佳策略以及考虑模型不确定性的稳健性保守策略).He等[23]通过置信区间考虑模型的不确定性影响,并运用稳健的模糊规划方法同时考虑了多响应曲面优化过程所涉及到的位置效应、散度效应以及模型不确定性等问题,从而确保了研究结果的稳健性.针对多响应优化问题,Ouyang等[24]考虑模型参数的不确定性以及实施误差(即参数设计值难以在实际操作中准确无误地实施),提出一种新的质量损失函数.针对多响应的优化问题,张旭涛和何桢[25]考虑考虑响应间相关性和可控因子波动的影响,提出了一种基于似无关回归的多元稳健损失函数方法.该方法不仅利用似不相关回归模型考虑响应间的相关性,而且利用给定点的梯度信息估计了可控因子波动对过程稳健性的影响.针对作用关系复杂且多极值的制造过程,崔庆安[26]考虑了模型结构的不确定性对优化结果的影响,运用支持向量机作为复杂作用关系过程的近似模型,提出了基于支持向量聚类与序列二次规划的参数全局性优化方法.在多响应优化设计中,模型参数的不确定性以及生产过程的噪声因子不可避免地会导致预测响应值出现较大的波动.针对上述的问题,汪建均和屠雅楠[27]结合贝叶斯抽样技术、帕累托优化策略以及灰色关联分析方法提出了一种多响应优化设计方法.Chapman等[28]提出一种利用置信区间度量预测响应值波动的方法,该方法利用随机抽样法得到响应预测值的置信区间,将该区间端点的最优值作为响应预测值,同时利用图形显示响应预测值波动对优化结果的影响.由于贝叶斯方法能够在建模过程中有效地利用相关的先验信息和专家知识,而且能够在后续的建模过程中对以往的先验信息进行不断地更新和修正,因此贝叶斯方法在不确定性质量设计(模型参数、模型结构以及响应分布等不确定性)的建模过程中也得到了广泛地应用.例如,针对多响应优化问题,Peterson[29]提出了一种贝叶斯的后验预测方法.该方法在贝叶斯建模与优化过程中考虑了试验数据之间的相关结构、过程分布的变化以及模型参数的不确定性,然后利用多响应的后验概率分布计算响应预测值满足所设定质量条件的概率.Miro-Quesada等[30]扩展了Peterson[29]的研究工作,在多响应的后验概率密度函数中考虑了噪声因子的影响.此外,Peterson等[31]考察了多响应之间存在不同协方差的问题,结合多变量似不相关回归模型进一步改进以往的研究工作.上述方法过分关注响应预测值落在规格限内的概率,却忽视了多元过程的稳健性[32].事实上,在很多情况下仅仅考虑优化结果的可靠性所获得的参数设计值,其可靠性结果往往令人满意,然而其质量损失却相当大[7].为此,汪建均等[4]在贝叶斯多元回归模型的统一框架下,结合多元质量损失函数与贝叶斯后验概率方法提出一种新的多响应优化方法.该方法能够在优化过程中较好地兼顾多元过程的稳健性和优化结果的可靠性,从而为实现多响应稳健参数设计提供了各方面(如多元过程的稳健性、优化结果的可靠性)均较满意的优化结果.此外,Vanli等[33]在考虑模型参数不确定性的稳健参数设计时,融入了在线可观测的噪声因子,提出了一种自适应的贝叶斯稳健参数设计方法.该方法旨在通过在线观察噪声因子的水平,从而不断调节最佳的输入参数水平.
此外,在参数优化过程中,优化指标的选择对研究结果的影响至关重要.针对多响应曲面优化设计,研究者通常采用维度缩减技术构建一个简化的综合性能指标,从而将多响应曲面优化问题转换为单目标优化问题.在多响应曲面优化设计中,常见的综合性能指标主要有:理想函数[11, 34, 35]、质量损失函数[10, 36, 37]、马氏距离函数、后验概率函数[7, 29, 31]以及多变量过程能力指数[38-40].多变量过程能力指数不仅考虑过程是否满足规格要求,而且还考虑过程与目标值之间的偏差与波动,因此在多响应优化设计中选择多变量过程能力作为综合性能度量指标能够较好地权衡产品的符合性与质量损失二者之间的关系.因此,一些研究开始尝试运用多变量过程能力指数来优化多响应优化设计问题.例如,Amir等[38]利用多变量过程能力指数解决非正态响应的优化问题.Awad等[39]将多变量过程能力指数作为目标函数,输入变量的限制条件作为约束,提出一种基于多变量过程能力指数的多响应优化设计方法.Ouyang等[24]利用多变量过程能力指数来评价不同方法的优化效果.
本文拟在SUR模型的框架下,结合贝叶斯建模与优化方法,从变量筛选、响应曲面建模以及参数优化三个阶段开展连续质量改进.首先,为SUR模型中的各个变量设置二元变量指示器,在此基础上构建符合因子效应原则的混合二元变量指示器;然后利用MCMC方法计算混合二元变量指示器和模型结构的后验概率,从而确定模型中的显著性变量;最后,优化多变量过程能力指数获得最佳的参数设计值.
2 似不相关回归模型的贝叶斯分析
在多响应优化设计中,假设有m个响应,各个响应包含n个观测值和q个因子效应,则一般多响应回归模型(SMR)为
(1)
其中Yj为n×1的响应矩阵;βj为q×1的回归系数矩阵;Xj为n×q的因子效应矩阵;ej为n×1的随机误差矩阵,服从均值向量为0、方差-协方差矩阵为H的正态分布,而且H为对角阵.式(1)中随机误差项的方差-协方差矩阵为对角阵,其非对角线元素均为0,表明该式中的m个响应是相互独立的.但是在实际生产中,需要解决大量相关多响应的优化问题.Zellner[41]在1962年首次提出SUR模型,该模型与SMR模型最大的区别在于:该模型中的每个响应包含的随机误差项是相关的,即响应之间是相互联系的.假设需要考虑m个响应模型,每个响应有n个观测值和mj个解释变量,则SUR模型的结构如下
(2)
其中Yj为n×1的响应矩阵;Xj为n×mj的因子效应矩阵;βj为mj×1的回归系数矩阵;εj为n×1的随机误差矩阵.由于式(2)中的随机误差项εj不独立,因此满足以下性质
(3)
还可将式(2)改写为矩阵形式
Y=Xβ+ε,ε~N(0,Σ⊗I)
(4)
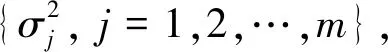
根据式(2)~式(4),可计算出关于Y的似然函数为
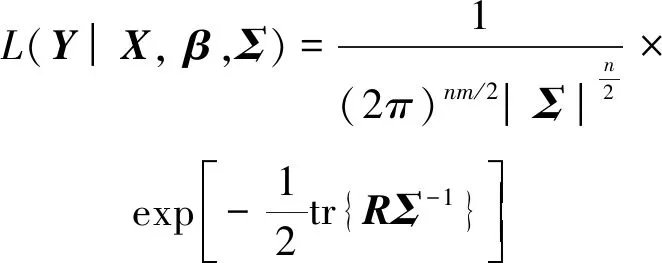
(5)
其中|Σ|表示矩阵Σ的行列式;tr表示矩阵的迹(主对角线元素之和);R为m×m的矩阵,其元素为rij=(Yi-Xiβi)T(Yj-Xjβj).在式(5)的基础上,可求得参数β和Σ的极大似然估计,比如Zellner[41]采用迭代的SUR方法获得了β和Σ的参数估计值.
由于贝叶斯方法能够在建模过程中有效地考虑先验信息或专家知识,因此被广泛地应用到复杂模型的参数估计与统计推断之中.近年来,一些学者构建了SUR模型的贝叶斯推断方法.贝叶斯的先验分布大体上可分为两类:无信息先验和共轭先验,因此SUR模型的贝叶斯参数估计与统计推断通常也是从上述两个角度展开分析.
第一类是在对参数信息缺乏了解的情况下,利用无信息先验作为参数的先验信息,此处倾向于选择Jeffrey无信息先验[42].假设参数β和Σ是相互独立的,则参数β和Σ的联合先验分布为
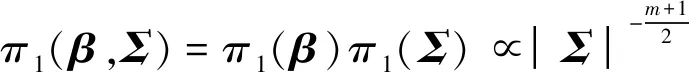
(6)
根据式(5)和式(6),可以求得参数的联合后验密度

(7)
在参数β和Σ联合后验密度的基础上,可计算参数β和Σ各自的条件后验分布为
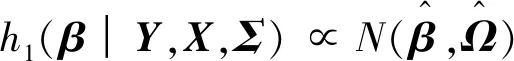
(8)
h1(Σ|Y,X,β)∝IW(R,n)
(9)
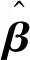

(10)
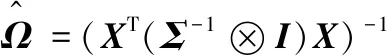
(11)
第二类是在根据过去的经验知识,假设参数的先验分布与后验分布具有相同的形式,则参数β和Σ的联合先验分布为
π2(β,Σ)=π2(β)π2(Σ)
(12)
其中
π2(β)=N(β0,A-1)
(13)
π2(Σ)=IW(Λ0,ν0)
(14)
根据式(5)和参数β和Σ的先验分布,可推断得参数β和Σ的条件后验分布为
(15)
h2(Σ|Y,X,β)∝IW(Λ0+R,n+ν0)
(16)
其中
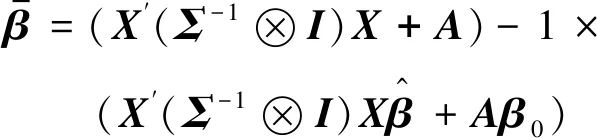
(17)
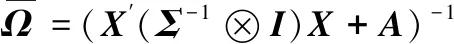
(18)
3 结合SUR模型与因子效应原则的连续质量改进
3.1 考虑因子效应原则的SUR模型
Wu和Hamada[8]指出:因子效应原则通常包括效应稀疏原则、效应排序原则以及效应遗传原则,主要用于选择模型的显著性变量.效应稀疏原则指模型包含的重要性因子是少数的,可称之为试验设计的帕累托原则.效应排序原则认为:同阶效应具有相同的重要性;低阶效应与高阶效应相比,低阶效应更可能是重要性因子.因此,当试验次数有限时,应当优先估计低阶效应.效应遗传原则指:在考虑交互项时,如果该交互项是显著的,那么它的亲本因子中应该至少有一个是显著的,即不可能出现没有亲本因子的交互项.若一个模型仅有交互项而未包含其亲本因子,则该模型违背了效应遗传原则,应该将其剔除.在筛选试验中,需要筛选出能够解释模型的显著性变量,同时需要剔除那些拟合效果很好但违反因子效应原则的模型.如果将这部分模型用于后续的质量改进阶段,可能会导致预测模型更加偏离真实模型,从而影响试验最终的优化结果.
在以往关于变量选择的研究中,大都没有考虑因子效应原则,通常都是计算各个变量指示器γyj={γ1,γ2,…}j=1,2,…,m的后验概率来判断该因子是否显著.本文借鉴文献的经验[19],通过构建混合二元变量指示器来进行因子筛选.假设共有m个响应,p个主效应,并考虑其二阶交互项和平方项,则该混合二元变量指示器如下
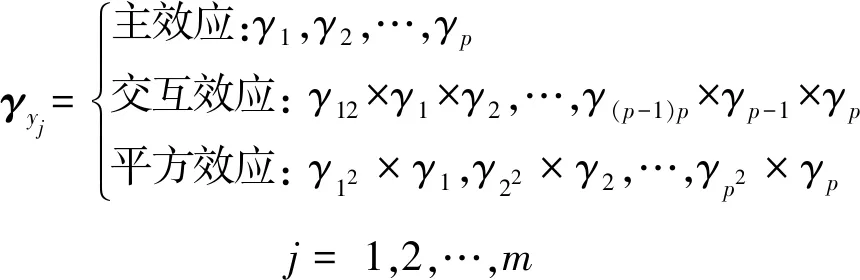
(19)
其中γyj表示第j个响应的一组混合二元变量指示器向量;γp表示第p个主效应的变量指示器;γ(p-1)p表示第p-1个主效应与第p个主效应之间的交互项对应的变量指示器;γp2表示第p个主效应的平方项对应的变量指示器.
式(19)中的模型结构表明该设定符合效应排序原则和效应遗传原则.以交互项为例,该模型利用三个变量指示器的乘积γ(p-1)p×γp-1×γp来判断该交互效应是否显著.如果该交互项的两个亲本因子中至少有一项为非显著性主效应,即γp-1和γp中至少有一个值等于0.那么该交互项的变量指示器γ(p-1)p等于1,否则γ(p-1)p×γp-1×γp的值仍然等于0,因此该交互效应将判定为非显著性因子,符合效应遗传原则的假设.此外,增加了γp-1和γp的约束后,γ(p-1)p×γp-1×γp=1的可能性要远远小于两个亲本因子的变量指示器γp-1=1和γp=1的可能性,因此低阶主效应为显著性因子的概率将远远高于高阶交互效应,这与效应排序原则的思想保持一致.
为了在SUR模型中更好地融入因子效应原则,在一般SUR模型式(4)的基础上,引入式(19)中的混合二元变量指示器,从而构建出一种结合SUR模型与因子效应原则的新模型
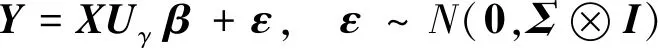
(20)
即

(21)

本文拟在上述新模型的框架下构建考虑因子效应原则的贝叶斯变量选择方法.借鉴一般SUR模型的第二类贝叶斯分析方法,拟对模型参数采用一种经验贝叶斯先验.首先,式(20)中参数β的先验形式采用多变量正态分布,即运用式(13)获得;然后,式(20)中参数Σ的先验形式采用逆Wishart分布,即运用式(14)获得.最后,针对混合二元变量指示器γym采用贝努利(Bernoulli)分布,即假设其包含的各个因子效应的变量指示器满足概率pj=P(γj=1)的0-1分布.
由于新模型中加入了混合二元变量指示器,增加了参数计算的复杂度,从而无法直接得出模型各参数的封闭后验分布.因此,本文采用MCMC方法动态模拟各参数后验分布的马尔科夫链,利用各参数的后验样本进行参数估计.结合以上先验假设,利用R和JAGS软件实现相应的MCMC过程,以两个响应为例,其先验形式如下.

从分布IW(Λ0,ν0)获取Σ的先验值从分布N(β0,A-1)获取β的先验值gamma1=(γ1,γ2,…,γ12,…,γ21,γ22,…)for j=1 to p1 do 从分布Bernoulli(gamma1[j])获取gamma1[j]的先验值end forgamma2=(γ1,γ2,…,γ12,…,γ21,γ22,…)for j=1 to p2 do 从分布Bernoulli(pgamma2[j])获取gamma2[j]的先验值end for
其中p1和p2分别代表响应y1和响应y2的候选变量个数,gamma1[j](j=1,2,…,p1)和gamma2[j](j=1,2,…,p2)分别代表两个响应候选变量所对应的变量指示器的先验值,pgamma1[j](j=1,2,…,p1)和pgamma2[j](j=1,2,…,p2) 代表相应0-1分布的先验概率值.
该方法主要通过混合变量指示器和模型的后验概率来识别显著性因子,利用每个混合变量指示器γ和模型结构M的后验样本,可以估计每个混合变量指示器γ和模型结构M的后验概率,计算公式如下
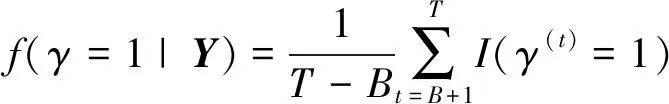
(22)
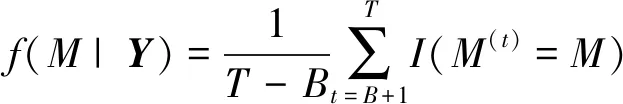
(23)
其中T为迭代总次数,B为舍弃的燃烧期次数,γ(t)为该混合变量指示器在第t次迭代的后验样本值,M(t)为第t次迭代后的模型结构.
3.2 多变量过程能力指数
工业生产中常用过程能力指数评估产品处于受控状态下的质量水平,以体现生产过程的工艺水平和产品符合性的程度.所谓过程能力指数[43],就是判断过程是否满足规格要求的一种度量方法,即评估过程能力满足产品规格要求程度的数量值.在连续质量改进过程中,计算与分析过程能力指数是至关重要的一项工作.
质量管理学家朱兰(Juran)[44]提出了第一代过程能力指数Cp,该指数假设过程输出的均值与目标值相重合,具体的定义如下
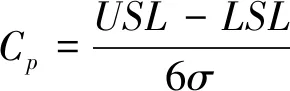
(24)
其中USL表示规格上限,LSL表示规格下限,σ表示过程特性的标准差.自从朱兰(Juran)提出第一代过程能力指数之后,相继又有学者提出了第二代和第三代过程能力指数,具体定义见文献[44].
然而,上述过程能力指数只能用来评价单个质量特性过程的质量水平.在实际生产过程中通常包含多个质量特性,并且需要考虑各响应间可能存在的相关性,衡量各个响应对产品质量影响的差异,从而全面地评价该产品的质量和可靠性水平.因此,一些研究人员将单变量过程能力指数扩展到了多变量情形.Wang等[45]将多变量过程能力指数定义为两块区域的比值,具体的表达式如下
(25)
其中v表示响应个数;R1表示工艺的规范区域面积或体积;R2表示过程区域的面积或体积.假设R1是一个椭圆形,则R1区域内(包括边界上)的点都满足以下不等式[47]
(26)
结合式(25)和式(26), Chan等[46]提出了以下多变量过程能力指数
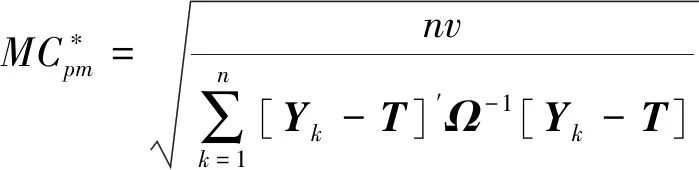
(27)
其中n表示试验样本数,其余参数与式(26)中的一致.
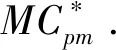
3.3 结合SUR模型和因子效应原则的连续质量改进
本文在SUR模型的框架下结合因子效应原则,运用贝叶斯统计、随机搜索技术以及混合遗传算法等方法和技术,从变量筛选、模型构建以及参数优化实现多响应的质量设计.通过结合因子效应原则筛选出符合试验设计原则的因子效应,不仅能够为后续的响应曲面设计节约试验成本,也能够构建更加精确的响应曲面模型.响应曲面模型构建和参数优化则可以视为对筛选试验分析(即显著性变量识别)工作的进一步改进与优化.通过响应曲面建模与优化工作,获得产品或过程最佳参数设计值,从而能够从产品形成的源头减少或控制设计值与目标值之间的波动,提升产品的质量与可靠性水平.首先,在SUR模型中针对每个因子设置一个二元变量指示器,然后运用贝叶斯抽样方法计算出变量指示器与不同模型结构的后验概率,从而确定显著性变量和模型结构;其次,根据所选择的模型结构,运用MCMC方法估计模型参数,获得各响应的抽样值,在此基础上考虑模型参数不确定性与预测响应值的波动,构建出新的贝叶斯多变量过程能力指数;最后,结合混合遗传算法对所构建的多变量过程能力指数进行优化,获得最佳的参数设计值.所提方法的基本流程如图1所示,具体实施步骤如下:
步骤1确定试验因子和试验响应,选择合适的试验设计开展试验,并收集试验数据;
步骤2假设各个响应的模型结构一致,确定初始的因子组合;
步骤3针对各个响应的每个因子设置一个二元变量指示器,然后根据式(19),构建混合二元变量指示器;
步骤4根据步骤3的研究结果,构建初始的SUR模型.针对模型参数设置相应的先验分布,然后利用贝叶斯方法计算出变量指示器的后验概率,确定模型的显著性变量,并选择最佳的模型结构;
步骤5根据步骤4的结果,判断各个响应的模型结构是否一致,如果模型结构一致,则采用SMR模型建模,转入步骤6,否则,采用SUR模型建模,转入步骤6;
步骤6利用MCMC方法对模型参数进行估计,获得各响应的后验抽样值;
步骤7利用步骤6所获得各响应后验抽样值,构建多变量过程能力指数;
步骤8针对所构建的多变量过程能力指数,通过混合遗传算法优化获得最佳的参数设计值.

图1 本文所提方法的基本流程图
4 实例研究
4.1 实例1
4.1.1 实例背景
实例1来源于文献[48],该试验具有两个相关的响应,即聚合物的转化效率y1和热活动放射性y2,其中转化效率为望大质量特性,取值范围为[80,100],目标值设为100;而热活动放射性为望目质量特性值,取值范围为[55,60],目标值设为57.5.影响上述响应的可控因子主要包括:反应时间(x1)、反应温度(x2)和催化剂的使用量(x3).试验者选择中心复合设计(central composite design,CDD)开展了相关的试验,其试验计划与试验结果如表1所示.

表1 实例1的试验计划与试验结果
4.1.2 变量筛选
首先,假设各响应的模型结构相同,则式(2)中的因子效应满足
其次,针对两个响应的各个因子设置变量指示器γi,i=1,2,…,10 ,在此基础上结合因子效应原则构建混合二元变量指示器,其结构如下
γy1={γ0,γ1,γ2,γ3,γ12×γ1×γ2,γ13×γ1×γ3,
γ23×γ2×γ3,γ12×γ1,γ22×γ2,γ32×γ3}
γy2={γ0,γ1,γ2,γ3,γ12×γ1×γ2,γ13×γ1×γ3,
γ23×γ2×γ3,γ12×γ1,γ22×γ2,γ32×γ3}
本例中因子效应数量较少,此处不考虑效应稀疏原则,所以假设先验信息中的向量pgamma1和pgamma2中的元素均为0.5.然后,运用MCMC方法对每个参数迭代了100 000次,舍弃了前20 000次的燃烧期样本.为了弱化各参数抽样值之间自相关性对研究结果的影响,在此对所获取的各参数后验样本每间隔4步抽样一次,共20 000个有效的参数抽样值.在此基础上对所获取的样本进行收敛性检验,并提供一些可视化的收敛性(如踪迹图等)来帮助判断参数抽样值的收敛性.考虑到篇幅限制,在此仅仅提供响应y1和响应y2的交互效应x1x2所对应的参数后验抽样值的踪迹图如图2所示.
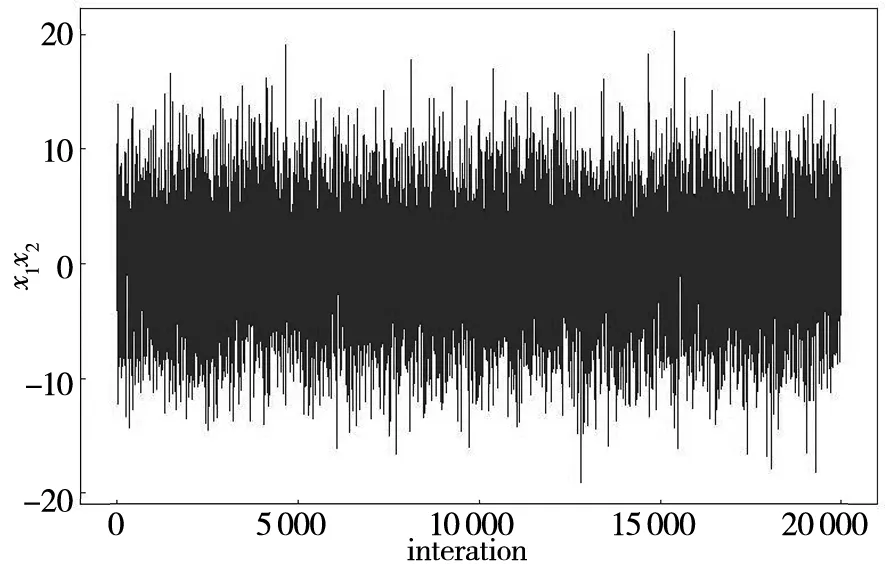
(a)响应y1的交互效应x1x2参数踪迹图
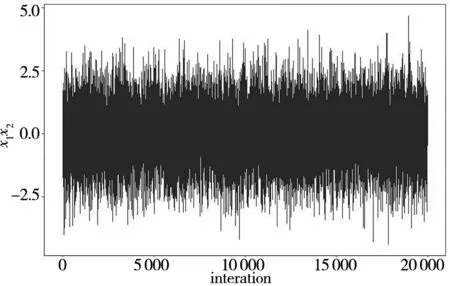
(b) 响应y2的交互效应x1x2参数踪迹图
根据图2的踪迹图观察可知:在抽样过程中,由于参数的不确定性在其抽样值会围绕着某个确定的均值呈现上下波动的趋势,且其波动幅度基本保持一致,呈现出稳态分布的特征,因此可以利用其参数的抽样值进行后续的统计推断与数据分析.在对模型参数进行收敛性诊断之后,可以计算变量指示器的后验概率,其研究结果如表2所示.
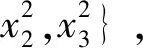
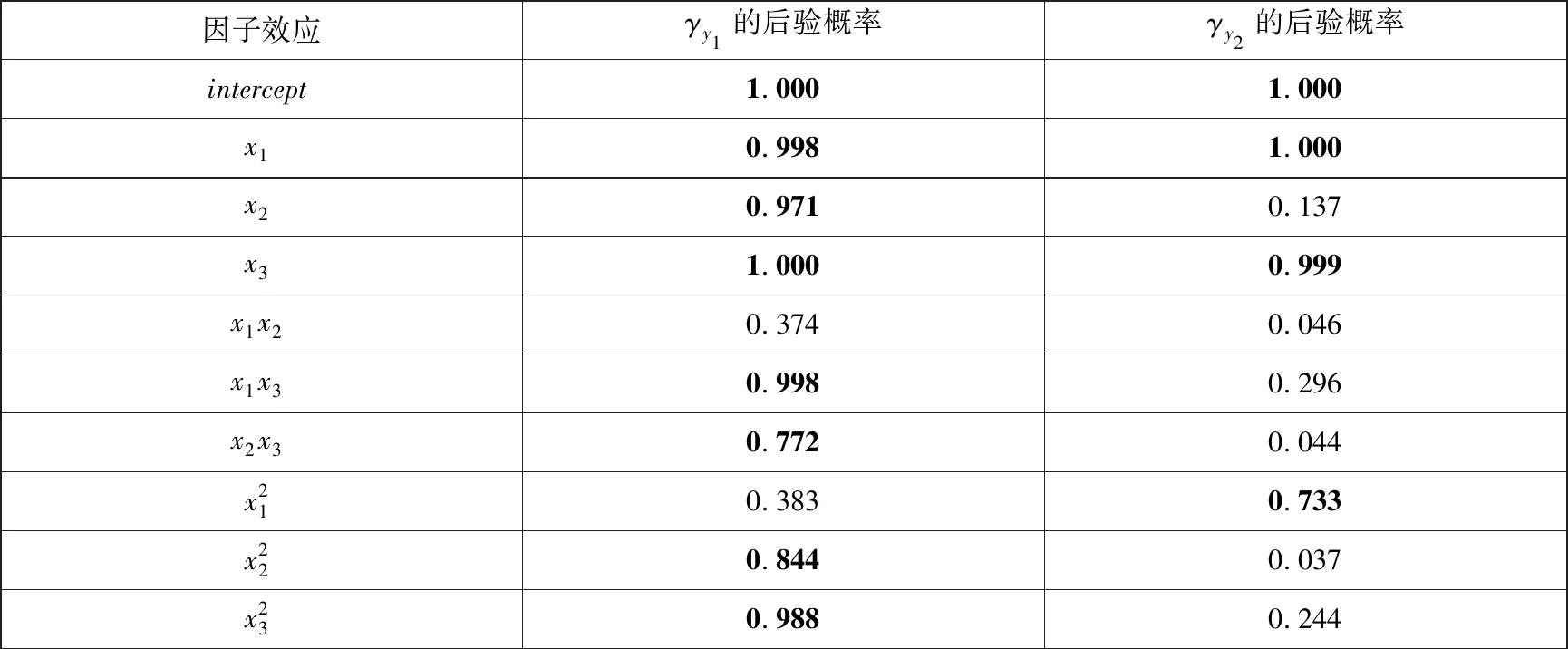
表2 混合二元变量指示器的后验概率
4.1.3 响应建模与参数优化
变量筛选的研究结果表明:在本例中,两个响应的最佳模型为不一致的模型结构,因此后续将运用SUR模型进行响应曲面建模与优化工作.因此式(2)中的因子效应向量确定为
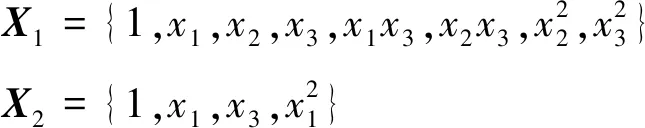
对所构建的SUR模型运用MCMC方法对模型参数进行10 000次迭代,并舍弃了前2 000次的燃烧期样本,获得了8 000个模型参数与响应的后验抽样值.在对模型参数和响应的抽样值进行收敛性诊断后,运用所获得的响应抽样值构建式(27)中的多变量过程能力指数.其中,样本数n设为8 000,响应个数v设为2,目标值向量T为[100,57.5],方差-协方差矩阵Ω利用其响应后验抽样值的样本方差计算获得.事实上,由于模型参数的不确定性以及随机误差的影响,其响应的后验抽样值也将呈现出一定的波动,因此根据其响应的后验抽样值及其方差-协方差矩阵所构建的多变量过程能力指数将呈现出高度复杂的非线性、多峰的特征.鉴于上述复杂的情形,传统的优化算法(如线性规划方法等)将难以获得理想的优化结果.为此,本文拟充分利用遗传算法的全局搜索与模式搜索的局部优化的优势,构建结合遗传算法与模式搜索技术的混合优化算法,从而有效地解决上述复杂曲面函数的优化求解问题.在本试验中,将上述多变量过程能力指数作为目标函数,运用MATLAB优化工具箱中的混合遗传算法对其进行最优化求解,其可控因子的参数设计值为(-0.552 0,1.679 9,-0.407 0),此时多变量过程能力指数等于0.937 0,优化过程见图3.在上述优化结果中,若固定可控因子x3=-0.407 0,则可以绘制出关于参数x1和x2以多变量过程能力指数为优化目标的响应曲面,其结果如图4所示.从图4观察可知:考虑响应预测值波动所构建的响应曲面往往表现出复杂的非线性、多峰等特征.
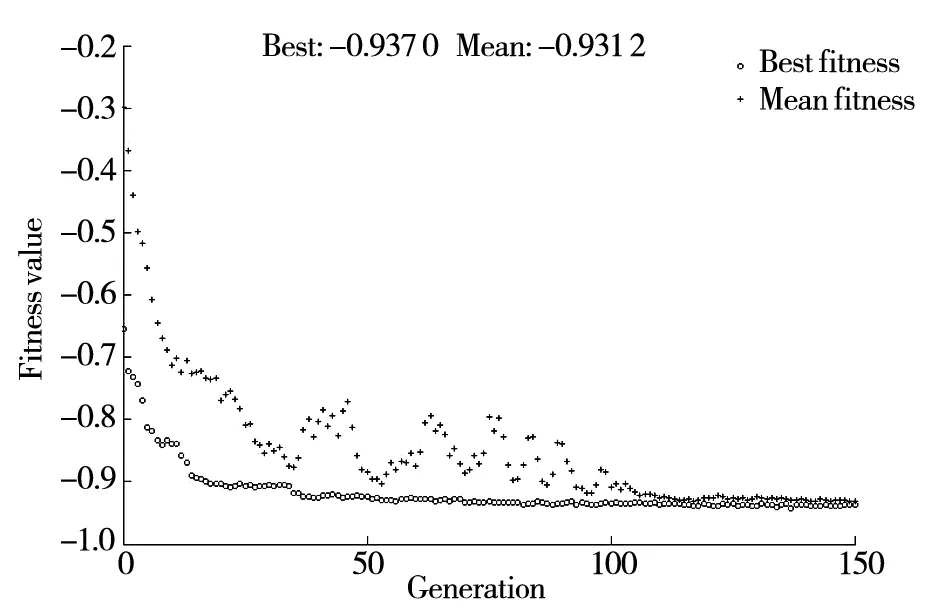
图3 混合遗传算法的优化过程
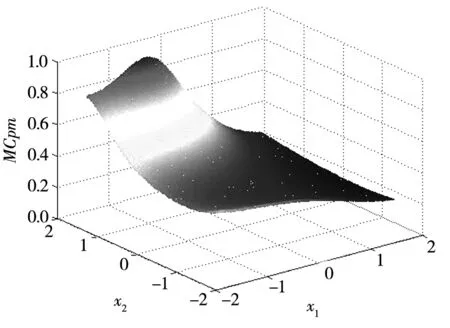
图4 多变量过程能力指数的响应曲面图
4.1.4 不同研究方法的比较与分析
实例1的试验曾被众多文献广泛应用,在此选择汪建均等[4],Ko等[37],Park等[47],Vining[48]文献的研究结果开展比较分析.将上述方法所获得参数设计值代入到本文所构建的SUR模型之中,从而能够获得不同方法响应预测值波动的情况,其结果如图5所示.
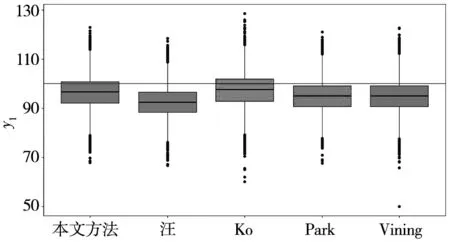
(a)响应y1的箱形图

(b)响应y2的箱形图
从图5(a)可知:针对响应y1,本文方法的抽样值波动情况与Ko方法、Park方法、Vining方法基本一致,明显优于汪方法的结果.其主要原因是汪方法采用与本文的初始模型相同的结构,未能进一步筛选显著性变量识别出最佳的模型结构,从而导致其抽样结果明显偏离目标值.从图5(b)可知:针对响应y2,除了Ko方法以外,本文方法的抽样值波动情况与其他方法比较接近,且都接近目标值.需要特别指出的是,虽然Ko方法也采用结构不一致的模型,但是由于其在试验过程中采用重复的响应数据,且需要同时考虑响应与目标值的偏差、响应的预测性能和稳健性这三方面的质量损失,无法最小化每一部分的质量损失值,所以导致其响应y2明显偏离目标值.
考虑到模型参数不确定性以及响应预测值的波动,将上述方法的最优参数设计值代入到所提的多变量过程能力指数目标函数之中,并重复上述抽样过程1 000次,其结果如表3所示.

表3 不同研究方法结
比较表3的结果可知:与其他方法比较而言,本文所提方法的多变量过程能力指数最大,且两个响应预测值都比较接近相应的目标值.尽管汪的方法考虑了模型参数不确定性和预测响应值的波动,但是一方面该方法未实施变量筛选,而是选择全因子模型来进行建模.另外该方法将质量损失函数作为目标函数,将响应位于规格限内的概率作为约束,得到的优化结果需要最大限度地满足这两个函数的优化目标.上述原因导致其模型预测结果与目标值之间存在较大的偏差.因此导致其所获得的MCpm较低.虽然Ko方法、Vining方法和Park方法针对两个响应采用了完全不同的模型结构,但是并未考虑因子效应原则,且优化函数与本文也存在差异.此外,上述三种方法在建模过程中未能考虑模型参数的不确定性和预测响应值波动的影响,因此导致上述方法的MCpm值仍然低于本文结果.本文方法不仅结合因子效应原则筛选出显著性变量,识别出更加合理的模型,从而提高了模型的预测性能,而且利用贝叶斯抽样方法,考虑了模型参数不确定性和预测响应值波动对优化结果的影响,从而获得较高的MCpm值.
4.2 实例2
4.2.1 实例背景
该实例来自文献[49],主要研究某试验中表面活性剂和乳化变量的设计问题.在该试验中,重点考察的质量特性为粒度(particle size)y1,玻璃转变温度(glass transition temperature)y2.影响上述两个关键质量特性的可控因子为普朗尼克F68的含量(x1)、聚氧乙烯40单硬脂酸酯的含量(x2)、聚氧乙烯脱水山梨糖醇脂肪酸酯NF的含量(x3).两个响应均为望目质量特性,其目标值分别为150、8;三个因子的取值范围均为0≤x1≤1.此试验的目的是希望通过试验设计确定获得可控因子的最佳参数设计.试验者采用中心复合设计开展相关试验,试验数据见表4.

表4 实例2的试验计划及其试验结果
4.2.2 筛选试验
由于上述试验的次数较少,因此不适合选择包含全因子效应的初始模型.根据Wang等[7],Peterson等[31]的相关研究,本文选择的初始模型所包含的因子效应向量为
Xj={x1,x2,x3,x1x2,x1x3,x2x3},j=1,2
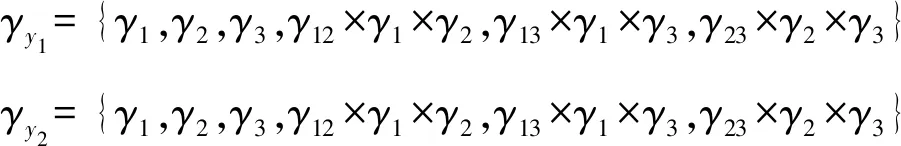
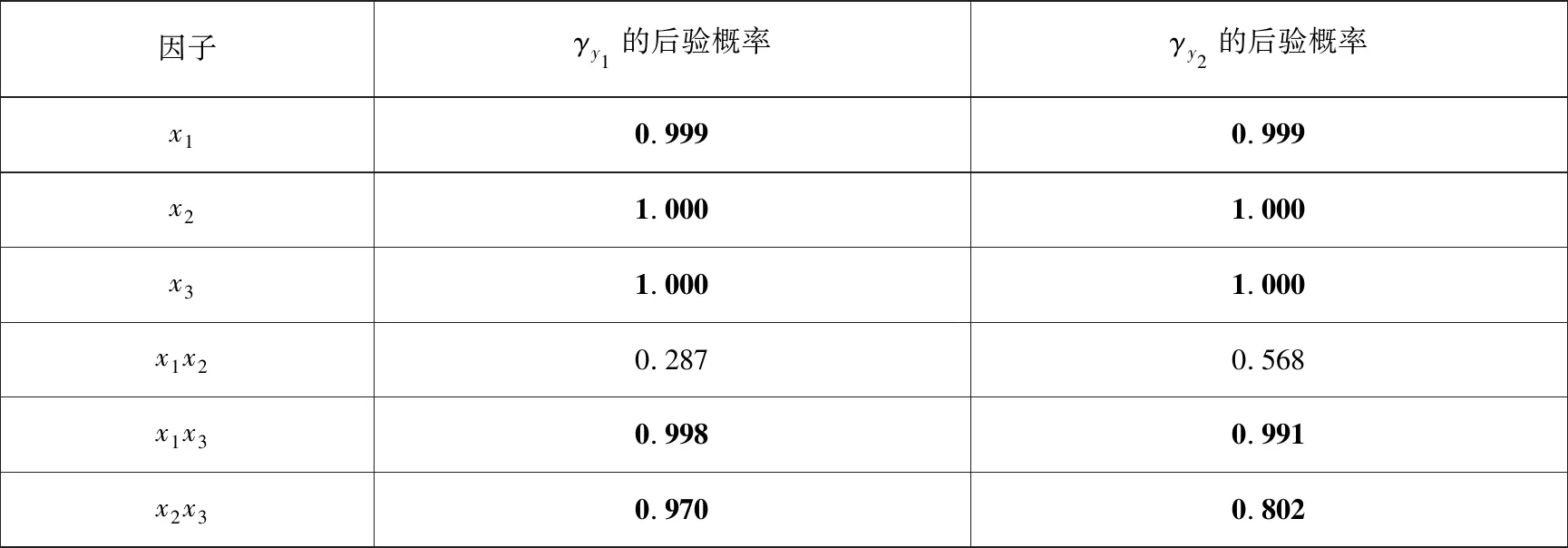
表5 混合二元变量指示器的后验概率
根据表5,比较响应y1与响应y2的显著性变量可知:响应y2模型的因子效应x1x2的后验概率较低,是否纳入到最终模型有待进一步分析.在上述试验中两个响应模型之间的差异较小,若针对两个响应采用相同模型结构对后续统计建模与抽样更为容易.为此,本文进一步比较了两种不同模型结构之间的后验概率.模型1中两个响应包含相同的因子效应{x1,x2,x3,x1x3,x2x3},其模型后验概率为0.210 2.模型2中响应y1包含的因子效应为{x1,x2,x3,x1x3,x2x3},响应y2包含的因子效应为{x1,x2,x3,x1x2,x1x3,x2x3}.模型2所包含的因子效应与运用本文所提方法所识别出模型结构一致,其模型后验概率为0.358 8.尽管模型1与模型2的后验概率存在一定差异,但是为了快速实现贝叶斯统计推断与数据分析,同时比较SUR模型和SMR模型的抽样效果,在后续的建模与优化中本文倾向选择相对简单的模型1,从而能够建立其更为简单的SMR模型.
4.2.3 响应建模和目标优化
首先,运用SMR模型开展后续的贝叶斯统计建模与优化,其中式(1)中的因子效应向量为
Xj={x1,x2,x3,x1x3,x2x3},j=1,2
然后,运用MCMC方法对SMR模型进行抽样.利用所获得的响应抽样值构建式(27)中的多变量过程能力指数.其中,样本数n设为10 000,响应个数v设为2,目标值向量T为[150, 8],方差-协方差矩阵Ω利用响应抽样值之间的样本方差代替.最后,将上述多变量过程能力指数作为目标函数,运用混合遗传算法进行最优化求解,获得最佳的参数设计值为(0.028 4, 0.499 6, 0.013 7),目标函数值等于0.999 9.将其他研究方法的优化结果代入到本文所选择的SMR模型中,则其获得的抽样结果如图6所示.
比较图6中不同方法的抽样结果可知:Peterson方法的抽样结果明显偏离了目标值.其主要原因在于Peterson方法将各个响应位于规格限内的概率作为优化函数,忽略了响应与目标值之间的偏差,从而导致该方法的后验抽样值严重偏离目标值.Wang方法采用一种有约束的目标函数进行优化.该方法将质量损失作为目标函数,将响应位于规格限内的概率作为约束.尽管该方法利用质量损失函数考虑了响应预测值与目标值之间的偏差,但是由于其决策者在选择成本矩阵以及期望的符合性概率时往往具有一定的主观性,从而导致其响应抽样值与目标值之间的偏差比本文所提方法更大.
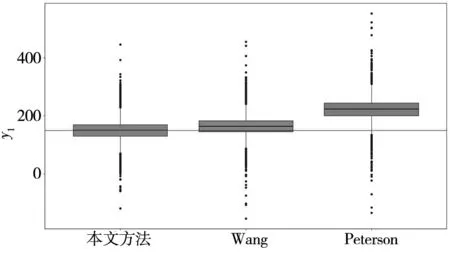
(a)y1的箱形
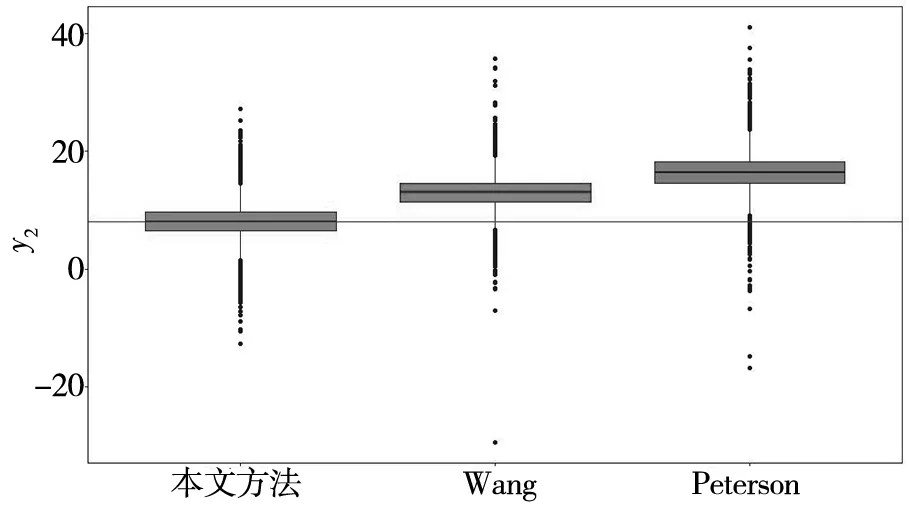
(b)y2的箱形
另外,为了减少响应预测值波动的影响,将上述方法的最优参数设计值代入到所提的多变量过程指数目标函数之中,并重复上述抽样过程1 000次,其结果如表6所示.
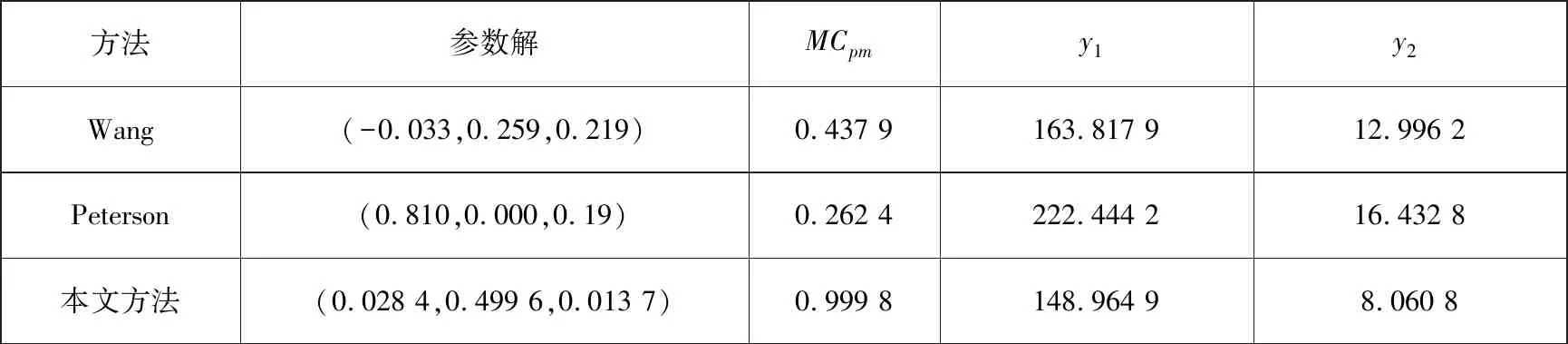
表6 不同研究方法结果
比较表6的研究结果可知:与其他两种方法比较而言,本文方法得到的MCpm值最高.上述研究结果进一步验证本文所提方法的有效性与可靠性.
5 讨论
5.1 所提方法的优势
比较而言,本文所提方在处理多响应的质量设计问题时具有一些明显的优势.首先,本文所提方法在SUR模型的框架下结合因子效应原则(即效应系数原则、 效应排序原则和效应遗传原则)筛选出显著性效应,能够快速排除不符合试验设计基本原则的因子效应组合,从而大大地缩减模型选择的空间.因此本文所提方法能够处理试验因子数目较大的质量设计问题.其次,在建模过程中充分结合贝叶斯统计的优势,因此对样本量大小没有特殊要求,即使是小样本的试验数据也能够顺利开展相关研究.例如,本文所选择案例均为三个因子、两个响应的质量设计问题,但是其试验数据的样本量差异较大.第一个案例试验运行次数为20,第二个案例试验运行次数仅为11,但是从研究结果来看,所提方法对小样本量的质量设计问题同样是有效的.最后,本文利用贝叶斯似不相关(seemingly unrelated regression, SUR)响应曲面模型,并在此基础上运用Gibbs抽样方法获得多响应的抽样值.通过上述多响应的抽样值来估计响应之间的方差-协方差矩阵能够充分地考虑由于模型参数的不确定性以及其他随机误差所引起响应波动,从而能够更好地构建符合实际生产过程的多响应优化指标,即考虑响应波动的多变量过程能力指数.这种改进的贝叶斯多变量过程能力指数,由于结合贝叶斯响应曲面建模与抽样技术,因此能够有效考虑模型参数不确定性以及其他随机误差对优化结果的影响.
5.2 所提方法的不足
本文所提方法除了具有上述的优点之外,也存在一些明显的不足之处.首先,所提方法若涉及到大量的响应优化问题(比如10个或10个以上),在运行速度方面可能会受到比较大的影响.由于本文所提方法会涉及到SUR模型的贝叶斯抽样技术,因此当响应变量为高维数据时在运行速度上将会有很大的影响.其次,当响应变量个数较多时,在优化过程中可能会出现响应之间的方差-协方差矩阵行列式接近零情况,从而无法获得理想的优化结果.最后,本文所提方法在响应曲面建模过程中通常是假设响应变量满足为正态分布.此外,本文利用贝叶斯抽样方法所构建的多变量过程指数也仅适用于正态响应的情况.因此本文所提方法无法有效地处理非正态、多类别响应(如同时包含离散的属性变量和连续性变量)的质量设计问题.
6 结束语
在连续性质量改进中,往往需要同时考虑变量筛选、响应建模和参数优化过程所涉及到的一系列问题.针对多响应的质量设计问题,本文结合SUR模型和因子效应原则,提出了一种连续性质量改进方法.该方法在SUR模型融入了因子效应原则,提出了一种新的贝叶斯变量选择方法,不仅保证了模型结构的合理性,而且提高了模型的预测性能.另外,本文还采用多变量过程能力指数来衡量过程能力满足产品规格要求的质量水平,同时在优化过程中,利用贝叶斯抽样技术考虑了模型参数的不确定性和预测响应值的波动对优化结果的影响,从而提高了优化结果的可靠性.最后,通过两个实例分别展示了SUR模型和SMR模型的抽样效果.
需要特别指出的是,本文在整个分析过程中均假设响应服从多元正态分布,如何在贝叶斯广义线性模型的框架下结合帕累托优化策略与灰色关联度分析开展相关研究解决非正态多响应的质量设计问题,将是下一步重点研究的课题之一.另外,本文所提出的方法仅研究了待测因子数小于试验次数的试验设计.然而,由于经费、试验条件等方面的限制,试验者经常会选择大幅减少试验次数,采用超饱和试验设计(待筛选因子数目大于试验次数的情形),如何选择合适的方法解决超饱和试验的质量设计问题,也是未来有待深入研究的课题之一.
猜你喜欢
核科学与工程(2021年4期)2022-01-12
法律方法(2021年4期)2021-03-16
今日农业(2020年19期)2020-12-14
工程数学学报(2020年3期)2020-07-06
统计与决策(2019年6期)2019-04-22
中学物理·高中(2016年12期)2017-04-22
雷达学报(2017年6期)2017-03-26
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
郑州大学学报(医学版)(2015年2期)2015-02-27
