
高频听力损失补偿算法的设计与实现
2020-04-01 05:58李志强林永武陈俊健
计算机与网络 2020年21期
李志强 林永武 陈俊健
摘要:在听觉生理学的内在原因和外部因素,如噪音、耳毒性药物、日益严重的老年化问题的作用下,高频听力损失已经成为如今最常见的听力障碍。针对高频听力受损的上述特点并结合听觉生理学和语音信号处理技术,提出了移频法和频谱压缩法2种高频听力补偿的方法。对这2种听力补偿方法的原理和优缺点进行了深入研究,并通过实验仿真的方式对上述方法进行了验证。结果显示,频谱压缩算法虽然系统开销比较大,但在降频效果上比移频算法的效果更好,是一种更值得推荐的高频听力损失补偿算法。
关键词:高频听力损失;补偿算法;移频;频谱压缩
中图分类号:TP391.4文献标志码:A文章编号:1008-1739(2020)21-60-4

0引言
权威听力机构研究表明,世界上听力残疾位于各类残疾之首。在最近10年中,发达国家以及一些发展中国家,国民听力病患发病率增加了3倍以上。听力损失在中度以上的患者数量已经超过世界人口的6%。中国听力障碍患者中90%的人存在中高频听力损失,耳机的过度使用和急剧恶化的老龄化问题,使得青少年和老年人中的高频听损患者比例更高[1]。
针对高频听力损失的补偿技术,很多研究人员尝试使用频率降低技术进行语音助听和培训[2]。Baer在2019年对降频补偿技术进行了全面的研究和总结,并且表示降频技术在未来将有很好的发展前途[3]。本文将对2种听力补偿方法的原理和优缺点进行深入研究,并通过实验对上述方法进行仿真验证。
1听力学的基本原理
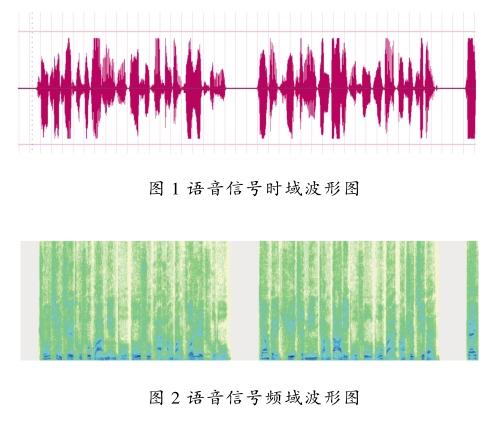
物体的振动通过媒体到达人类的耳朵,被人类的耳朵接收,就是所谓的声音。20 Hz~20 kHz是人耳所能感知的声音频率范围,不到20 Hz频率的声音叫做次声波,超过20 kHz的声音称为超声波。平常所听到的声音主要是各种不同频率的声音叠加复合声一起而形成的,能量集中频带不同声音的性质也有所不同。通常高音调声音能量主要集中在高频部分,低音调的声音能量主要集中在低频部分[4]。人类的语音频率范围主要集中在200 Hz~8 kHz。按照频率的高低,通常将超过1 kHz的叫做高频区域,500 Hz~1 kHz区域称为中频区域,不到500 Hz的区域称为低频区域。图1和图2所示的是一段时域和频域上关于语音信号的波形图。
2高频听力损失补偿算法
高频听力损失在现代社会中是非常普遍的疾病,然而人们不太重视,甚至大部分人不知道它的存在。实际上大部分的听力下降都与高频听力受损密切相关,高频听力损失补偿算法在弥补高频听力受损方面有至关重要的作用。目前有多通道声码器压缩[6]、频率转移[7]及频率压缩[8]等几种常见算法。
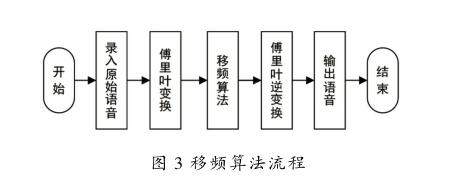
频率转移是目前比较先进的一种算法,主要原理是对用傅里葉变换过的频谱信息按照一定的移频量进行移频。算法首先需要确定原始语音的声学特性,然后选择必须降低频率的声音,并将其移向低频区,而不需要降低频率的声音则保持不变。总的来说,就是将临界的高频语音信息转移到尚具有较好残余听力的低频区中。同传统的助听算法相比较,在进行了高频转移之后比较有效地保留了原有的语音信息。在将高频信息移动到低频部分的同时,人耳对处理后声音的识别没有明显下降。移频算法流程如图3所示,流程为:①对原始语音信号进行傅里叶变换;②将高频信息移动至低频;③对处理后语音进行傅里叶逆变换;④得到重构的语音信号。
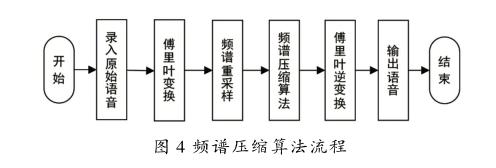
与移频算法不同,频谱压缩算法是对频谱信号进行重采样而设计的。频谱压缩算法流程如图4所示,流程为:①对原始语音信号进行傅里叶变换;②对变换后的频谱重采样;③将采样后的频谱作为低频,④高频部分补0;⑤对处理后的语音进行傅里叶逆变换;⑥得到重构的语音信号。
重采样技术就是将原来的采样频率转换为新的采样频率,从而适应不同采样率的要求。在对声音信号进行重采样时,如果满足Nyquest定理(采样频率大于等于语音信号最高频率的2倍),可通过一个插值函数比较完整地还原语音,重采样算法采用线性插值法。
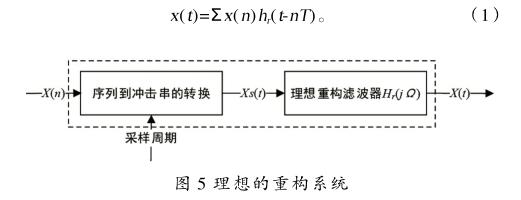
图5所示的是一个理想的重构系统,图中( )是由( )形成的冲激串。
滤波器频率的响应函数(j)如图6所示。
3实验仿真结果及分析
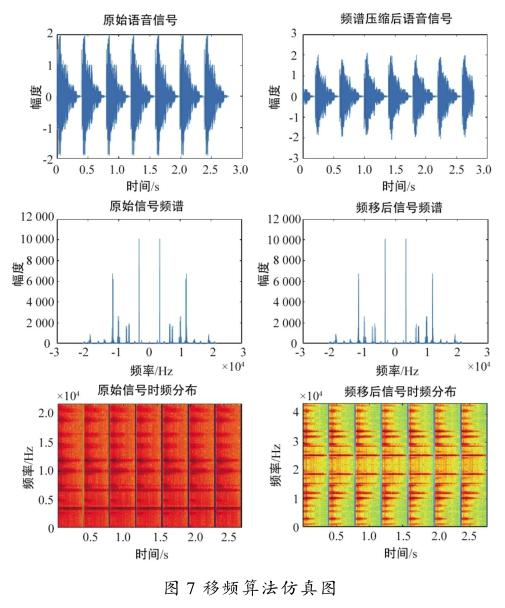
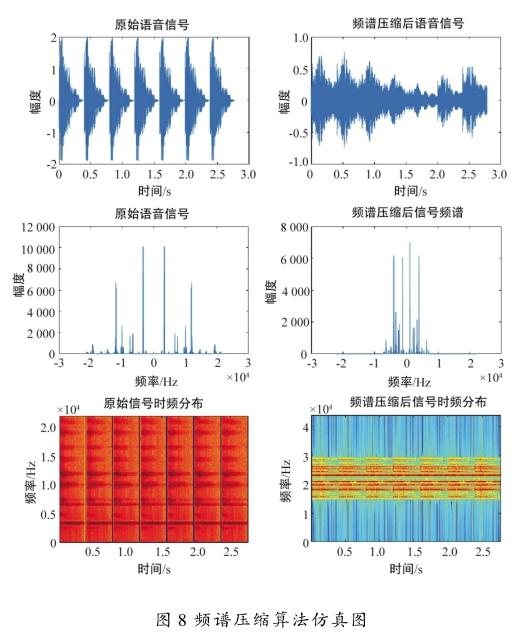
在针对高频听力损失的特点和对上述算法理论深入分析的基础上,对2种算法分别进行了仿真实验。为了模仿自然中同时具有连续的高低频的声音,仿真采用的原始语音信号是频率范围在0~20 000 Hz的一段连续蜂鸣信号。
移频算法仿真结果如图7所示。对仿真后的结果进行分析,可以发现经过移频处理后的信号与原始信号相比,声音高频部分已经被转移到了人耳可以识别的较低频部分。移频后的信号频谱图处理前后相差不大,主要原因是移频的点数很多,移频后肉眼看到的就不是很明显。而从时频分布图和处理前后语音信号图就可以看出比较明显的变化。由于技术和条件有限,移频后的语音信号听上去失真较大,没有很好地保留原始语音信号的一些特征,可能对人耳的语音理解度有所影响,造成这个结果的主要原因是此算法是通过恒定的频率进行移频的,这样就导致语言声出现不自然的变化。
频谱压缩算法的仿真结果如图8所示。从仿真图上可以看出,在降频的效果上此算法的效果要比移频算法的效果更好。语音信息超过10 000 Hz的高频部分已经完整地压缩到了0~100 00 Hz的中高频部分了。而且从语谱图可以看出,降频后声音的能量比较集中在中低频的部分,語音中信息的丢失并没有那么严重。但是从人耳直观上听到处理后的声音和原来的声音变化还是比较明显。这主要还是因为算法不够具体和完善,忽略了声音中滤波的处理和共振峰的保护等。使用语音重采样的方法对于还原原始语音的真实度上效果较好,虽然系统开销比较大,但却是一种更值得推广的方法。
4结束语
本文提出并仿真实现了移频法和频谱压缩法2种高频听力补偿方案,二者都各有优缺点,移频法更为简单、运算较少、系统的开销也比较小,能有效地把高频的信息转移到低频部分,但是声音的失真现象比较严重,可能会影响人耳对语音信息的识别。而频谱压缩法采用了音频的重采样方法,在移频的同时比较有效地保留了声音中的原始信息,运算量较大,是一种更好的方法。这2种算法也有很多的不足和待改进的地方,首先是没有考虑声音的降噪和保存声音原来的特性,只是着重表现了声音的降频这一方面。另外,2种算法均难以处理日常生活中的全部声音信号,需要其他算法的配合才能得到令人满意的助听效果。
参考文献
[1]余艳萍,于文永,杨向茹,等.中文版老年听力障碍筛查量表评分与纯音听阈测试的比较研究[J].听力学及言语疾病杂志,2020,28(3):253-256.
[2]罗丽.DSP数字助听器关键技术[J].电子技术与软件工程, 2019(12): 92.
[3] BAER T, MOORE B C J. Evaluation of A Scheme to Compensate for Reduced Frequency Selectivity in Hearing-impaired Subjects[M]. Modeling Sensorineural Hearing Loss: Routledge,2019.
[4] THIJS van de Laar,BERT de Vries[J].IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2016,24(11): 2200-2213.
[5] VROEGOP J L,HOMANS N C,VAN D S M P,et al. Comparing Two Hearing Aid Fitting Algorithms for Bimodal Cochlear Implant Users.[J]. Ear Hear,2018,40(1):1.
[6]曾珖,谢志文.基于长时共振峰分布的多通道响度补偿算法[C]//2018年全国声学大会论文集K语言声学与语音信号处理,2018-12,中国北京:出版社不详,2018:8-9.
[7]李战明,张璇.基于频率转移的数字助听器单通道响度补偿算法[J].电子设计工程,2017, 25(5): 83-87.
[8]胡杰彬.数字助听器的响度补偿和移频压缩研究[D].哈尔滨:哈尔滨工业大学,2017.
