
基于BI的报表系统的数据挖掘优化
2020-04-22 20:36程旭王萌齐新
电脑知识与技术 2020年6期
程旭 王萌 齐新
摘要:伴随着大数据的发展,各大企业都在成立自己的数据中心,目的是为了统一处理各大部门的数据信息,打造一个数据中台来提升企业的综合实力。BI系统应用而生,BI主要是通过对大数据的收集,提取,分析vx2c~,-7;.等操作,过滤之后的信息以各种图形化的方式展示出来,帮助领导以及企业做出正确的决断。通过对国内的大部分数据中心进行观察发现了以下问题:海量的数据不能正确的处理,复杂的图表展示,大量冗余的信息使得企业不得做出正确的决定。故该文主要针对报表系统的数据挖掘模型进行优化设计与分析。
关键词:报表系统;数据挖掘
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)06-0005-02
1背景
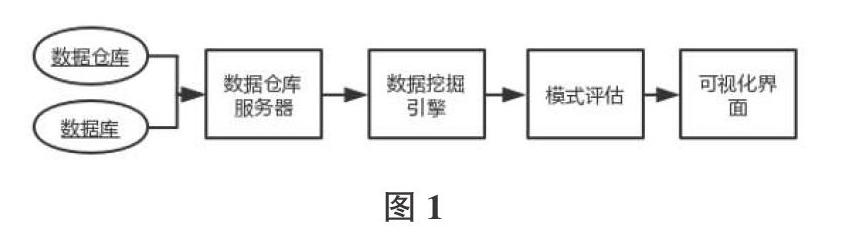
BI又被稱为商务智能,译为Business Intelligence,在1989年,Howard Dresner称为“使用基于事实的决策系统,来解决业务决策的一套理论和方法”,主要是通过数据仓库,数据挖掘以及报表系统集合来打造一个系统。将多种来源的数据整合并提取出共性数据,然后对数据进行清洗,分析以及整理,这个数据处理就叫作ETL过程,ETL过程可以完善数据的正确性。然后对数据进行分类整理呈现给决策者或者存人数据仓库。目前国内的BI系统发展迅速,大部分企业的数据分析技术也很强,但是大家对于BI的认知不同导致设计系统的侧重点也是不同的,在此仅针对BI系统部分的数据挖掘进行优化。
2数据挖掘模型
2.1数据挖掘
数据挖掘是对数据进行抽取,分析,处理之后形成的数据仓库,之后再对数据仓库中的数据进一步挖掘的过程。
2.2数据模型之决策树
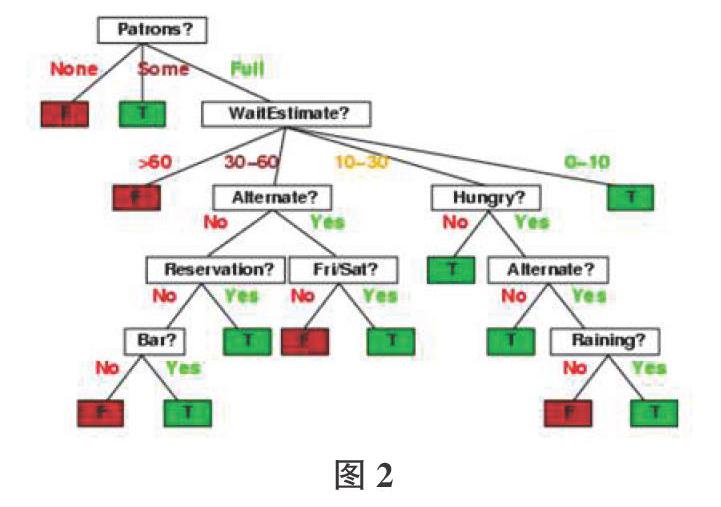
决策树结构如图2所示。
决策树是树形结构,每个节点是一个简单的线性决策器,节点属性依据取值的不同划分为不同的种类,其中决策树的任意一个非叶子节点有两个特点:一个训练子集和一个分割属性,每个节点的训练子集互不相交。
决策树的构造:
在初始时刻构建树根节点,且树根节点拥有所有的训练数据,任一节点Ni,选择数据的某一个属性A,以A的不同值,把节点Ni拥有的数据Di划分为全部没有交集的集合,每个集合变成Ni的一个子节点,当某个节点的所有训练数据都属于同一个类时,该节点的划分过程结束,生成叶节点只有一个属性,它的父节点拥有的数据集所属的类标号。
ID3算法:
决策树的重点在于如何最有效的去划分子节点,也就是选择划分的属性使得从数据集中找到最重要的数据,我们可以用数据的不纯性来描述数据分割的能力,“纯”代表着分割之后的子集异类数目越少越好,因此衍生出了ID3算法,采取信息增益这个量来作为纯度的度量,
算法流程:
1)计算信息熵,对于给定的变量拥有的概率分布向量(p1,p2,p3……),我们可以计算出信息熵是概率分布向量的对数期望值:H=-f(x)=-∑npn logpn,主要是来衡量随机变量的不确定性;
2)计算熵不纯度:对决策数的节点N定义熵不纯度为i(N)=H(N);
3)对于节点的不同取值,都进行子节点的信息增益计算:IG(N/Ai)=H(N)-∑I Ni/NH(Ni)=H(N)-H(N/Ai),可选取信息增益最大的属性作为当前划分属性,之后再从第一步开始循环,直到叶子节点。
以信息的增益为例,我们一般会选取属性相同多的属性,这样做的后果是会造成对取值数目的属性和个数有所偏好,为了减少这种偏好取值所带来的影响,我们可以采用C4.5算法来消除这种影响,使用属性增益率来划分最适合属性,对最适合的信息增益属性取权值再求熵,作为最后的增益率划分属性。
C4.5算法:
与ID3算法不同的是,C4.5算法划分重点转移到信息增益率上,信息增益率可以表示为:IGR=IG(N/Ai)/H(N/Ai),息增益除以分割后的信息熵,它通过信息增益率的选择分裂属性可以解决ID3算法中通过信息增益倾向拥有多个属性值的属性进行分割的不足,同时也可以将连续性的属性进行离散化的处理,属性离散化处理流程:将属性A的N个属性按照一定的规则排序,然后将属性A的所有量化属性通过二分法划分为两个部分,可以计算出共有N-1种划分的方法,划分的值取相近的属性取平均值,计算出每一种划分方式的信息增益值,然后对比信息增益的结果,将信息增益值最大的划分方式的阈值作为属性A的二分阈值。也就是当前节点的划分方式。
算法流程:
1)将当前节点上的属性A的值作为所有样本的数据,然后将数据进行排序,得到属性A的排列属性(xA1,..xAN)。
2)对于属性A的排序(xA1,...xAN)中共有N-1种划分方法,总计可以产生N-1个划分阈值。假设针对第i种划分方式,取其二分阈值为θi=(xAi+xAi)/2。可以将该节点上的原始数据集划分为2个子数据集(xA1,...,xAi)(xAi+1,...,xAN)。然后计算该划分方法下的信息增益。
3)统计N-1种划分结果下的信息增益值,选取信息增益值最优的方式作为对属性A的划分方式。
2.3决策树算法优化
为了提高决策树的性能,避免决策树的分支太多造成泛化的能力太差,可以在构建决策树时采用剪枝的方式:停止树的构建,不在分割某个节点,直接构建叶子节点,叶节点的标号为父节点的占优类或者类分布,比如设置信息增益的阈值,分割时不能超过阈值则分割停止。或者我们在构建决策树之后在进行剪枝。达到优化性能的目的。C4.5算法使用PEP剪枝法,是一种自上而下的剪枝法,这里就不再细述。
伴随着数据集的规模越来越大,可能会出现再一次内存中无法存放所有的训练集,这时我们可以采用随机读人数据放入内存中进行训练数据子集,在获取的子集上构造决策树,同时可以重复采样,获取多棵决策树,最后再用集成学习的方式综合多棵决策树的结果获取最终的分割属性。
3结束语
针对数据挖掘模型做出优化,可以极大地改善数据提取的效率和精准度,对于大型企业的冗余信息提取具有重大的意义,同时由于BI系统依赖大数据的特性,数据挖掘算法也成为BI系统中很重要的一步,可以为后续的BI系统信息展示提供良好的支撑作用。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
电力与能源(2017年6期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
郑州大学学报(医学版)(2015年1期)2015-02-27
电子设计工程(2014年18期)2014-02-27
