
排名聚合算法在少量长列表聚合中的性能比较分析*
2020-04-27 08:19陈玟宇朱章黔王晓蒙贾韬
物理学报 2020年8期
陈玟宇 朱章黔 王晓蒙 贾韬†
1)(西南大学计算机与信息科学学院 软件学院,重庆 400715)
2)(中国人民解放军陆军勤务学院国防经济系,重庆 500106)
排名聚合将多个排名列表聚合成一个综合排名列表,可应用于推荐系统、链路预测、元搜索、提案评选等.当前已有工作从不同角度对不同排名聚合算法进行了综述、比较,但存在算法种类较少、数据统计特性不清晰、评价指标不够合理等局限性.不同排名聚合算法在提出时均声称优于已有算法,但是用于比较的方法不同,测试的数据不同,应用的场景不同,因此何种算法最能适应某一任务在很多情况下仍不甚清楚.本文基于Mallows模型,提出一套生成统计特性可控的不同类型的排名列表的算法,使用一个可应用于不同类型排名列表的通用评价指标,介绍9种排名聚合算法以及它们在聚合少量长列表时的表现.结果发现启发式方法虽然简单,但是在排名列表相似度较高、列表相对简单的情况下,能够接近甚至超过一些优化类方法的结果;列表中平局数量的增长会降低聚合排名的一致性并增加波动;列表数量的增加对聚合效果的影响呈现非单调性.整体而言,基于距离优化的分支定界方法(FAST)优于其他各类算法,在不同类型的排名列表中表现非常稳定,能够很好地完成少量长列表的排名聚合.
1 引 言
排序是在复杂系统的研究中经常使用的方法,例如通过节点中心性对重要节点排序[1,2],链路预测中对可能存在的边排序[3,4].在很多场景中,我们会面对基于不同参数,采用不同机制所得到的不同排名,如不同人群对候选者给出的投票排名,不同推荐系统给出的推荐排名,不同算法给出的链路预测排名.将多个排名列表聚合成一个综合排名列表,就是排名聚合(rank aggregation,RA)要解决的问题.排名聚合也称为Kemeny排名聚合[5]、偏好聚合[6]、共识排名问题[7],可以应用于推荐系统、元搜索、期刊排名、提案评选、复杂网络等领域[2,3,8-20].作为一个研究主题,排名聚合已有超过两百多年的研究历史,最早可追溯至1781年法国数学家Borda[21]解决的法国科学院选举问题.基于“总体大于各部分之和”的基本思想[22],不同研究领域提出了大量排名聚合方法,大致可分为启发式方法和优化类方法.启发式方法基于某种直观经验或规则将多个排名综合为一个排名,具有简单、快速的特点.优化类方法通过优化某一目标函数,得到一个与已有排名之间存在某种优化量的排名.虽然优化类方法在理论上更加完备,但是因为其对应的优化问题是NP(non-deterministic polynomial)难的,难以保证得到最优解.对不同排名聚合方法进行对比分析,能帮助在不同应用场景和数据条件下选择最合适的聚合方法,提高效率和可信度,具有非常重要的意义.
少量长列表的排名聚合是很多实际场景中需要解决的问题,这些排名列表相互不等长,且可能包含平局,例如不同机构给出的大学排名、基于不同基因数据库的靶点预测排名、不同搜索引擎对相关主题给出的推荐排名.选择何种算法能最好地处理少量长列表的排名聚合尚没有明确的答案.虽然当前已有综述类工作[23,24]对不同聚合算法进行了列举和介绍,但是一般缺少不同方法之间的性能比较.一些工作[25-30]虽然涉及了一部分排名聚合算法的性能比较,但是用于比较的聚合算法较少,使用的排序列表类型不够丰富,评价指标也有不够合理之处.同时,当前的绝大多数算法对比工作均是基于少量实证数据,由于数据的统计特征缺失,难以区分算法优劣是源自特定数据集,还是基于一系列数据集的共同统计特征,算法性能的泛化能力难以估测.最后,不同的聚合方法在提出时,均会声称优于已有的算法,但是用于比较基础算法不尽相同,用于测试的数据也往往大相径庭,使得我们往往无法真实知晓在具体应用场景下何种算法性能最佳.
针对这些局限性,本文基于Mallows模型提出一套用于生成统计特性可控的不同类型的排名列表的算法,使用一个可应用于不同类型排名列表的通用评价指标,介绍9种排名聚合算法,比较它们在少量长列表排名聚合下的表现.结果发现启发式方法虽然简单,但是在排名列表相似度较高、列表相对简单的情况下,能够接近甚至超过一些优化类方法的结果;列表中平局数量的增长会降低聚合排名的一致性并增加波动;列表数量的增加对各聚合结果的影响呈现非单调性.整体而言,基于距离优化的分支定界方法(FAST)优于其他各类算法,在不同类型的排名列表中表现非常稳定,能够很好地完成少量长列表的排名聚合.
2 基本概念
给定包含|S|个对象的集合S,一个块序列(bucket order)是一种可传递二元关系≺,存在块集合B1,···,Bt(1≤t≤|S|)分割S,即块数量为t.如果x∈Bi,称Bi是x的块.如果i<j,则称块Bi位于Bj之前.对象x≺y当且仅当对于i<j有x∈Bi且y∈Bj.如果一个给定块中包含多个对象,则形成一个平局,即块内的对象具有相同的位置.直观上看,一个块序列就是一个可能包含平局的严格线性序列,块中对象x的位置定义为即采用“1224”列表类型来表达对象的排名偏好信息,而非采用块中对象的平均位置[31].“1224”列表类型表示为第2和第3个对象具有相同的位置,形成一平局.本工作主要针对少量长列表的聚合,根据相关应用场景,主要针对如下3种类别的列表[32].
完全列表(full list,FL): 块序列中所有块大小均为1且 t=|S|,即包含S中所有对象且不含平局;
平局列表(full list with ties,TL): 块序列中至少有一个块的大小大于1且 1 ≤t≤|S|,即包含S中所有对象且存在平局;
不完全列表(incomplete list,IL): 由S中部分对象形成的块序列,可能包含平局.
例如,假设S包含A,B,C和D四个对象,现有如下5个块序列:
块序列1: [A],[B],[C],[D];
块序列2: [A],[B,C],[D];
块序列3: [A],[C];
块序列4: [A],[B],[D];
块序列5: [B],[C,A],
其中,一个“[ ]”代表一个块,即一个位置.块序列1包含S中所有对象,并且块数量等于S中对象数,因此是FL类型.块序列2包含S中所有对象,但B与C都在块2中,即B与C形成一平局,是TL类型.块序列3—5都只包含S中部分对象,均为IL类型.
3 相关研究
Ali和Meila[25]重点探讨了不同排名聚合方法在搜索时间与结果表现之间的均衡性,发现决定均衡的重要因素是数据集的一致程度(degree of consensus).Schalekamp和Zuylen[26]也针对相似问题开展了工作,并且将平局情况引入比较过程,给出多个聚合方法表现的下界,但是在计算过程中一些方法没有考虑打破平局的代价.上述两个工作均使用真实数据集测试不同算法,但是所使用数据量较小.Brancotte等[27]针对平局比较了一系列排名聚合方法,标注了不同方法是否适用于TL数据,研究了平局等数据集特征对所讨论方法的影响.但是以上几个工作都没有考虑更为复杂的IL数据.
Cohen-boulakia等[29]基于广义肯德尔距离,提出了一个新的启发式排名聚合算法,此方法可适用于所有列表类型,但是算法验证和对比仅仅基于一个小型生物医学数据集和人工数据(4—8个对象).Lin[24]从排名聚合方法在生物信息学中的应用角度,综述和对比了多个聚合算法,但是该工作使用的数据较小并且对IL数据的情况考虑不充分.Sculley[33]比较了不同算法在大量短列表聚合下表现,但是其比较的方法较少,且均为启发式算法;Xiao等[30]基于其提出的数据生成模型对四种排名聚合算法进行了比较,并通过一个预设的真实排名(ground truth ranking)比较不同算法结果的质量.由于该数据生成模型对于平局数量、IL数据生成过程不可控,同时真实排名在现实场景中难以获得,其算法质量评估在真实场景中的应用具有局限性.
在评价指标的选择上,大多数工作使用斯皮尔曼等级相关系数或肯德尔 τ 距离.这两个经典量只适用于排名列表包含所有对象的情况,不能应用在IL数据中,同时它们也没有考虑不同排名位置的不同权重.在真实场景中,靠前的排名应比靠后的排名具有更高的权重,例如第1名和第2名、第50名与51名之间均只相差1个排位,但前者的排名差距权重比后者更大.
综上所述,当前很多排名聚合算法比较工作存在数据量小、评估指标不够合理、数据统计特征缺失或列表类型单一等问题.针对以上问题,本文提出一个数据生成模型,生成列表类型、列表长度(即对象数量)、列表数量、一致程度等特征可控数据用于算法比较.本文同时采用更为合理的评价指标,更好地处理平局、排序权重等之前工作中未能充分考虑的问题,从而更合理地比较不同算法在不同情况下的表现.
4 排名聚合方法及其分类
排名聚合方法可根据相关特征从不同角度进行分类[23,24,27,31,34].文献[23]是最早对排名聚合方法进行分类的排名聚合公理派综述文章,将排名聚合方法分为启发式方法和优化类方法两类.文献[24]将所有排名聚合方法分为基于分布的方法、启发式方法和随机搜索方法三类.文献[27]从能否处理平局的角度分为基于广义肯德尔距离的方法、基于传统肯德尔距离的方法和位置类方法三类.文献[31]按是否需要训练数据分为监督类方法[35,36]和非监督类方法两类.本文采用第一种分类标准.
4.1 启发式方法
4.1.1 KwikSort
KwikSort[37]是一种分治算法,其核心思路是给定一组对象,随机选择一个对象作为中心点,并将其他所有对象按照一定规则置于该中心点前后的两个块中,从而使每一个对象与该中心点的违例数最少(为与下文排名聚合方法MVR中违例数相区分,此处违例数定义为对于两个对象,如果其在两个列表中的相对位置不一致,则形成一个违例).van Zuylen和Williamson[38]提出了 KwikSort去随机化版本.事实上,对象有一定概率与中心点形成平局.Brancotte等[27]通过这种策略对KwikSort进行了改进使其可以处理平局.
4.1.2 FaginSmall
Fagin等[31]针对平局提出几种指标并利用动态规划方法提出一种新的近似算法.Cohenboulakia等[29]对上述方法做了修改得到FaginLarge和FaginSmall,前者得到的结果包含平局,而后者不包含平局,因此,本文选用FaginSmall.
4.1.3 BioConsert
给定M个对象和N个排名列表Rμ1,···,RμN(μ1,···,μN是每个列表对应的排名机制),通用目标函数为
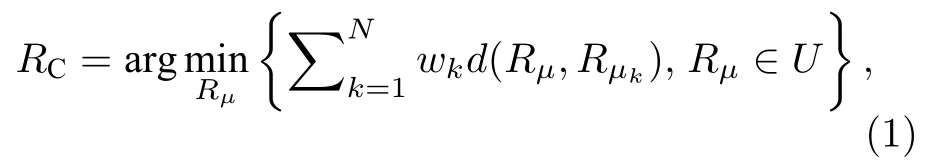
其中w是权重向量,用于指定有关排名列表相对重要性或可靠性的先验信息.本文取为元素全为1的向量,以表征所有排名列表一样重要,此时该问题也称为Kemeny排名聚合问题.本文不考虑最终得到的聚合排名中包含平局的情况,所以U表示由这M个对象组成的所有FL集合,则|U|=M!.d是某种距离函数,如肯德尔τ距离[39]、斯皮尔曼简捷距离[40]、KS距离[23]以及Hausdorff距离[41]等.RC在本文中叫聚合排名,而在社会选择和离散数学文献中叫共识排名(consensus ranking),在统计学文献中称为中值排名(median ranking).
BioConsert[29]的主要思路是从一个初始排名列表R开始,通过不断迭代选择执行两类操作以减少上述通用目标函数值.当任何操作均不能再减少目标函数值时,则将此时的排名列表作为最终的聚合排名.这两类操作是: 1)将一个对象从原来的块中取出放入另一个块中;2)将一个对象从原来的块中取出并在另一个新的位置新建单对象块.如果执行上述某一操作后目标函数变小,则执行该操作;反之,则不执行.不同初始排名列表R会产生不同的聚合排名结果,极大影响算法的表现[27].本文选用波达计数法的聚合排名RC作为初始排名列表.
4.1.4 波达计数法(BordaCount)
波达计数法[21]是最简单直观的排名聚合方法:在每个排名列表中,根据排名顺序对每个对象赋值一个分数,将每个列表中该对象分数相加并对每个对象总分数进行排序就得到了最终的聚合排名.同一对象在不同排名列表中的总分数除使用简单相加以外,也可使用其他聚合函数,例如中值函数、几何平均函数、p范数等[24].本文采用最简单的波达计数法,即某一列表中对象分数为该对象所击败的对象数量(例如在长度为M的排列中,第1名的分数为M-1,而第M名的分数为0),并采用求和的方法计算各对象总分数.
4.1.5 MedRank
MedRank[42]的核心思路是给定阈值q∈[0,1],逐一并行读取所有N个排名列表,一旦有对象出现次数首次超过N×q,则根据对象出现的先后顺序依次添加至最终排名列表,直至达到指定列表长度.本文将阈值q取为0.5.
4.1.6 马尔科夫链方法(MC3)
Dwork等[11]使用成对比较信息,基于马尔科夫链提出了一系列的排名聚合方法,其核心思路是将所有对象当作状态,构建一各态历经的马尔科夫链转移矩阵,从而其稳态分布会给予排在前面的状态更高的概率,对象转移概率的不同赋值方法取决于我们的目标.Lin[24]对上述方法进行改进以使其可以适用于不同类型列表.本文采用文献[24]中的MC3方法,给定M个对象和N个排名列表Rμ1,···,RμN(μ1,···,μN是每个列表对应的排名机制),对于u,v属于M,且u不等于v,则u→v的概率为
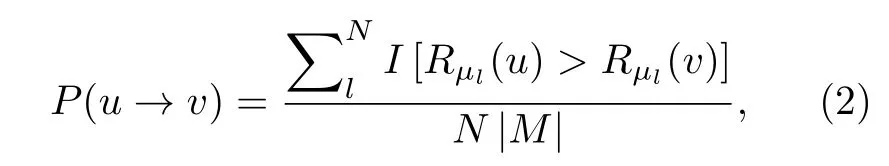
其中当I(·)所包含的条件满足时,I(·)=1,否则I(·)=0.此时,定义同时,对象转移概率与将待转向对象排在当前对象前面的列表数量成正比.根据(2)式建立相应的状态之间的概率转移矩阵,同时建立以状态为节点,状态间转移概率作为边权重的加权有向图 G(V,E),V为状态集合,E为边集合,此时,将问题转变为寻找最大的有向非循环连通子图.
4.1.7 PageRank
依据经典PageRank算法[43]的排名聚合算法PageRank[44]的主要思想是给定排名列表构造图G(V,E),V为节点集合,E为边集合,将每个对象看作图G中一个节点,对于每一个排名,如果对象u排名高于对象v,则建立一条加权有向边e(v,u),其权重为所有给定排名列表的差值.此外,对所有权重进行归一化处理,以便每个节点的出度边权重总和为1.对每个节点u构建Pg(u)值作为排名得分,Pg(u)定义为
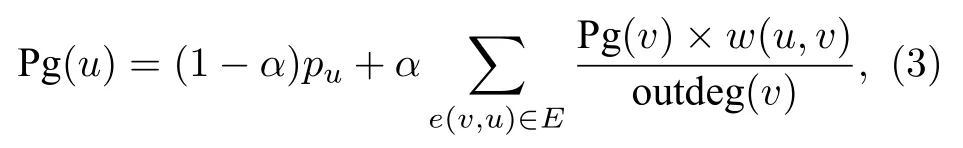
4.2 优化类方法
上述启发式方法尽管在运算速度上有优势,但是并不能在理论上保证最终排名的性能最优性.针对这一不足,一些学者提出了优化类方法,通过优化基于某一性能指标的目标函数,获得聚合排名.在衡量两个排名之间一致性情况下,采用不同的性能指标(如距离函数、等级相关系数和违例数等)会得到不同的优化方法[7,12,13,45-47].不同性能指标之间有时可相互转化,比如在FL情况下,KS距离和肯德尔 τ 距离完全等价[48];此外,KS距离函数和τx等级相关系数是等价的,具有线性变换关系[45].
4.2.1 分支定界方法(FAST)
肯德尔提出了 τa和τb等级相关系数[39],前者适用于FL,而后者还适用于TL.因为 τb在处理平局方面存在问题,Emond和Mason[45]基于 τb提出τx等级相关系数.在一个包含M个对象的列表中,定义分数矩阵A为一个方阵,对于任意两个对象u和v,如果u排在v前面或者与v形成平局,则auv=1;如果 u排在 v后面,则 auv=-1;如果u和v相等,则 auv=0,即A对角线上元素始终为0.因此,τb在处理平局时将其分数矩阵对应元素置为0,而 τx置为1,故而分数矩阵中除对角线以外的0元素表征无比较信息.给定两个列表Rμ1和等级相关系数定义为
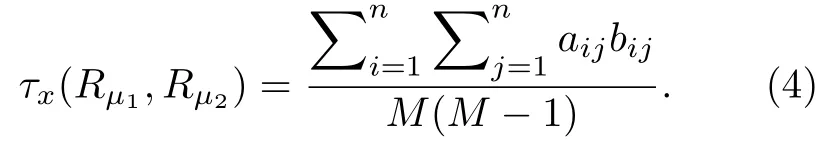
Emond和Mason[45]基于 τx提出一个分支定界算法来寻找聚合排名,即寻找一个聚合排名RC使平均加权 τx等级相关系数最大(或平均加权KS距离最小),其目标函数为
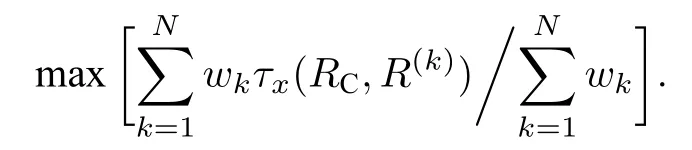
注意: 此处的目标函数与通用目标函数(1)式是一致的,因为 τx与KS距离具有线性变换关系.本文所有基础排名列表的权重都取1,以表征所有基础排名列表一样重要.上述目标函数化简为
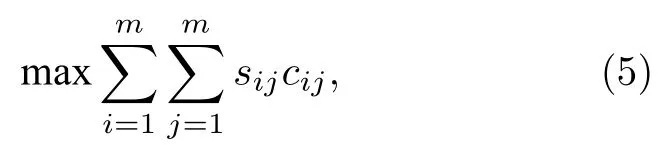
4.2.2 最少违例数方法(MVR)
在给定对象两两比较信息情况下,Pendings等[49]利用0—1线性整数规划来寻找一个聚合排名以使对象不一致数量最少.如果一个方阵每一行从左到右元素依次增大,每一列从上至下依次减小,那么该方阵就称为坡型矩阵.对于一个方阵,违反坡型结构的元素对数就是违例数(注意:此处违例数与KwikSort违例数[27]定义不一样).MVR旨在尽可能寻找这样一个坡型结构,从而使违例数最少.MVR目标函数为
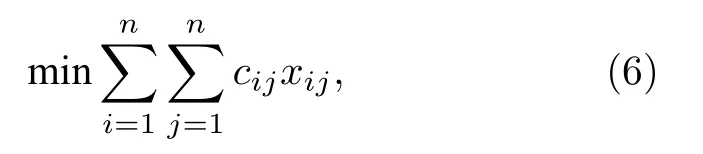
其中方阵X是决策矩阵,其值xij=1表示将mi置于mj前面,否则置于后面,并且需满足三个条件:1)xij∈{0,1};2)xij+xji=1;3)xij+xjk+xki≤2.方阵C用于计算与坡型矩阵的违例数.对任意i和j,cij=#{k|dik<djk}+#{k|dki>dkj},其中前面的列表数量与将mj排在mi前面的列表数量的差值,以衡量输入排名列表之间的一致程度.值得注意的是,MVR采用对象成对比较方式来表达偏好信息,其最原始的应用场景是各类循环赛,但在排名聚合背景下,可将基础排名列表转换为两两比较信息.如果出现平局或比较的两个对象至少有一个并未参与某一排名,则不计算这两个对象在该排名中的得分,因为未参与该排名,故而无法得知孰强孰弱.
4.3 算法比较
本文主要基于Mallows模型生成的完全列表、包含平局的列表和不完全列表,利用相似性指标来考察不同类型的列表数据对算法的影响.从算法自身设计角度来说,除少数算法以外,多数都可以直接处理不同类型的列表.例如,除了Bio Count,Med Rank和MVR方法需要对列表作稍微调整外,其余方法均可以处理包含平局的列表;除Bio Consert,Borda Count和Med Rank需要对列表作稍微调整外,其余方法均能处理IL数据.
以上Kwik Sort,Fagin Small,Bio Consert,Borda Count和Med Rank聚合算法使用文献[27]所提供的在线平台进行相关实验,MC3,Page Rank,FAST和MVR使用相关程序进行本地运算.
5 评价指标
为对比不同的排名聚合方法在不同列表类型上的表现,需要一个通用评价指标来表征各排名之间的相似性.一个合理的相似性度量指标需要能够处理对象未同时出现在排名中的情况,即列表不等长;赋予高排名对象比低排名对象更多的权重;同时相似度取值随着排名列表长度的增长而最终收敛.在排名聚合领域,有大量指标可用于计算列表之间相似性[50-54],但是很多都不能同时满足以上三个要求.比如,经常用于排名相似度计算的斯皮尔曼等级相关系数只能处理完全列表,当列表不等长或列表元素存在不同时不再适用;肯德尔τ距离以及广义肯德尔距离都可计算将一个排名转换为另一个排名所需的相邻对象交换次数,但是却不能给排在前面的对象更高权重,同时取值随着列表长度的增加而发散.Webber等[55]基于简单概率用户模型实现了一个满足上述三个条件的指标—有偏等级重叠(rank-biased overlap,RBO).RBO通过在给定评估深度下计算一个基本分数(下界)和一个最大分数(上界)来提供单调性.需要点估计时,也可以计算出一个介于上下界之间的分数.RBO∈[0,1],0表示两个列表中对象完全不同,1表示两个列表包含相同对象且相对顺序一致.RBO中包含一个参数p,其决定对象被加权的程度,决定权重下降陡峭程度,p越小,指标对前面的对象加权越大.本文根据文献[55],选取参数p=0.9.
为考察聚合算法的效能,本文根据不同的列表类型,使用2种指标.对于FL数据,由于列表生成模型基于一个中心排名均匀的产生随机样本,因此可以认为中心排名即为最佳的聚合排名.聚合排名与中心排名的差异性则体现出算法效能:
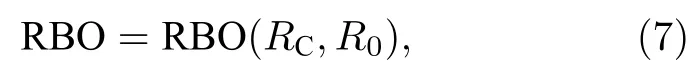
其中RC为聚合排名,R0为中心排名.
对于TL和IL数据,由于在添加平局和构造不等长列表的过程中,不可避免地使得列表不再基于中心排名列表随机分布,(7)式不再适用.因此我们使用聚合排名与原排名的平均相似度来度量聚合效果:
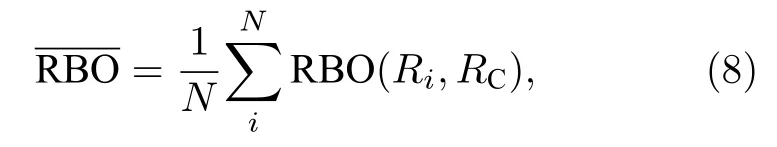
其中RBO(Ri,RC)代表原排名列表Ri与聚合排名列表RC的相似度.这一度量也同样适用于FL数据类型.
对于算法搜索时间比较方面,由于各方法使用不同的平台、语言和优化工具,本文不做比较.
6 数据生成模型
为评估和比较各种排名聚合方法,首先需要生成具有不同统计特征的数据集,包含多个相似但不相同的排名列表.TL和IL数据都可作为FL数据的变体,因此首先介绍FL数据的生成模型.当前已有多种FL类型数据生成模型[56-62],本文选用理论和应用研究中应用广泛的Mallows模型[56,57],以更好地分析数据一致程度对排名聚合方法表现的影响.Mallows模型是一个基于排名列表之间距离的指数模型,包含两个参数: 中心排名 R0和离差散布参数θ .Mallows模型会给每一个排列赋予一个概率值
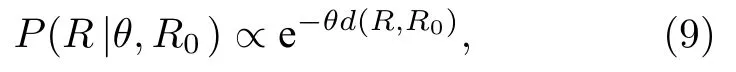
其中d代表某种距离函数,如肯德尔τ距离、海明距离、Cayley距离和Ulam距离等[58].本文使用肯德尔τ距离.θ控制生成的排名与中心排名的距离.当θ=0时,生成的排名R与R0无关;θ越大,概率衰减越快,生成的排名R越集中于R0附近.
(9)式虽然理论上非常简洁,但是在实际操作中却存在难度,一方面归一化常数的解析解难以获得,另一方面也很难直接通过距离随机地生成一个排名.因此在生成随机排名样本的过程中,我们具体使用公式
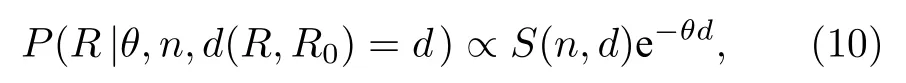
其中S(n,d)为中心列表长度为n时,所有与其距离为d的列表的数量.在样本生成过程中,首先基于中心排名,穷举出所有相关的排名列表组合,获得S(n,d)(这一步骤通常为O(n3)的复杂度).根据(10)式随机生成距离d,再从所有与中心排名距离为d的排名列表中随机选择一个排名.由于(10)式中的S(n,d)随d增长,e-θd随d下降,因此最终获得的随机样本,与中心排名的距离应该满足一钟型分布,即概率存在一个峰值,并在峰值距离两端迅速下降.
由于在Mallows模型中使用肯德尔τ距离生成排名序列,而在聚合效果的度量中使用RBO相似度,为验证生成的排名序列在RBO度量下也具有同样的统计特性,基于不同的参数θ生成3组序列,计算其与中心排名的相似度RBO(图1),获得了预期中的钟形分布,随着参数θ的增长,生成的随机排名与中心排名相似度逐渐增加.
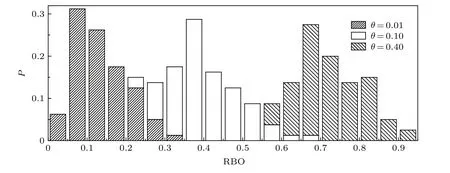
图1 Mallows模型在RBO度量下的表现Fig.1.The Mallows model under the RBO metric.
图2 FL2 TL示意图Fig.2.An illustration of FL2TL.
基于Mallows模型生成的FL数据,本文提出两种方法将其转换为TL和IL类型数据.
1)FL2TL(rt)
由(10)式获得长度为M的FL后,生成一随机变量T~U[0,rt*M],作为列表中的平局总量,其中rt定义为平局比例,取值范围为[0,1].令T′=T,在2至T′之间生成一随机数t,将一平局子块的长度设为min(t,T′-t).令T′=max(t,T′-t),重复以上步骤,直到T′≤3.假设总共获得了n个和为T的随机数,代表着对总长度为T的平局块的随机划分.将n个随机数由小到大排序,获得平局子块长度序列{T1,T2,T3,···,Tn}.在排序列表中随机选择n个对象,按照排名先后获得对象序列{P1,P2,P3,···,Pn}.结合序列Ti与Pi,将序列中排在Pi到Pi+Ti-1范围内的对象设置为平局,若两个平局之间存在相同的对象,则合并这两个平局为一大平局.整个过程如图2所示.
此方法在FL数据中加入了位置随机、长度随机的平局块,并且兼顾了经验规律: 排名位置靠后的对象更容易形成包含对象数量较多的平局.同时此方法只有一个参数,便于进行相关分析.为验证模型的可行性,我们基于不同的参数 θ和rt生成100个排序,计算了平均平局对(平均的总个数)和平局块(平局集中出现在多少分块中)的数量(图3),发现通过控制 rt可以很好地控制平局对与平均块的数量.作为验证,我们也使用了一些多参数的复杂模型,控制平局块长度和位置,发现不同的算法并不改变本文所获得的聚合算法性能的整体结论.
2)TL2IL(rk,Δk)
考虑到真实数据中,不同排名列表对靠前的排名个体差异并不大,因此使用前端截取的方法生成不完全列表.由1)中获得长度为M的TL数据后,可以从列表前端截取一个长度为L的列表获得IL数据,其中随机变量L~U[rk×M-Δk,rk×M+Δk],rk∈[0,1]定义为列表长度比例.参数rk控制IL数据的平均长度,参数Δk控制列表长度的波动区间.
7 实验与讨论
本文主要讨论少量不等长列表的聚合情况,如无特殊说明,则使用列表长度M=100,列表数量N=20,初始数据一致程度θ=0.7,rt=0.2,rk=0.8和Δk=0.2为参数.本文对数据生成过程、聚合排名算法实现以及评价指标重复进行10次实验,以确保结果更稳定.由于Xiao等[30]探究了在不同 rk值下,列表长度不等长对排名聚合方法表现的影响,故本文不再考察 rk和Δ k 组合对聚合方法的影响.对于个别不能直接处理IL数据的算法,我们将IL数据进行了规范化(unification)处理,将其变换为算法可以处理的数据类型,再将结果与其他算法结果对比.在7.4节中将具体讨论规范化处理对结果的影响.
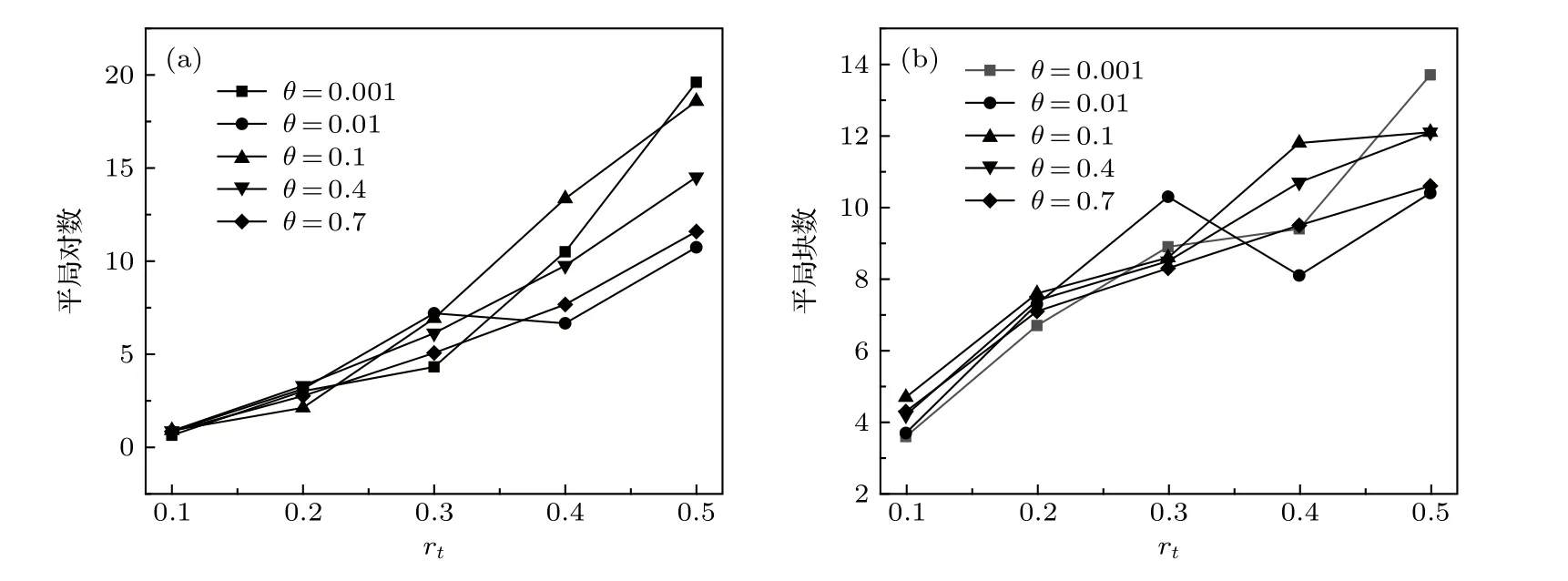
图3 (a)rt与平局对数量的关系;(b)rt与平局块数量的关系Fig.3.(a)The relationship between rt and the number of ties;(b)the relationship between rt and the block number of ties.
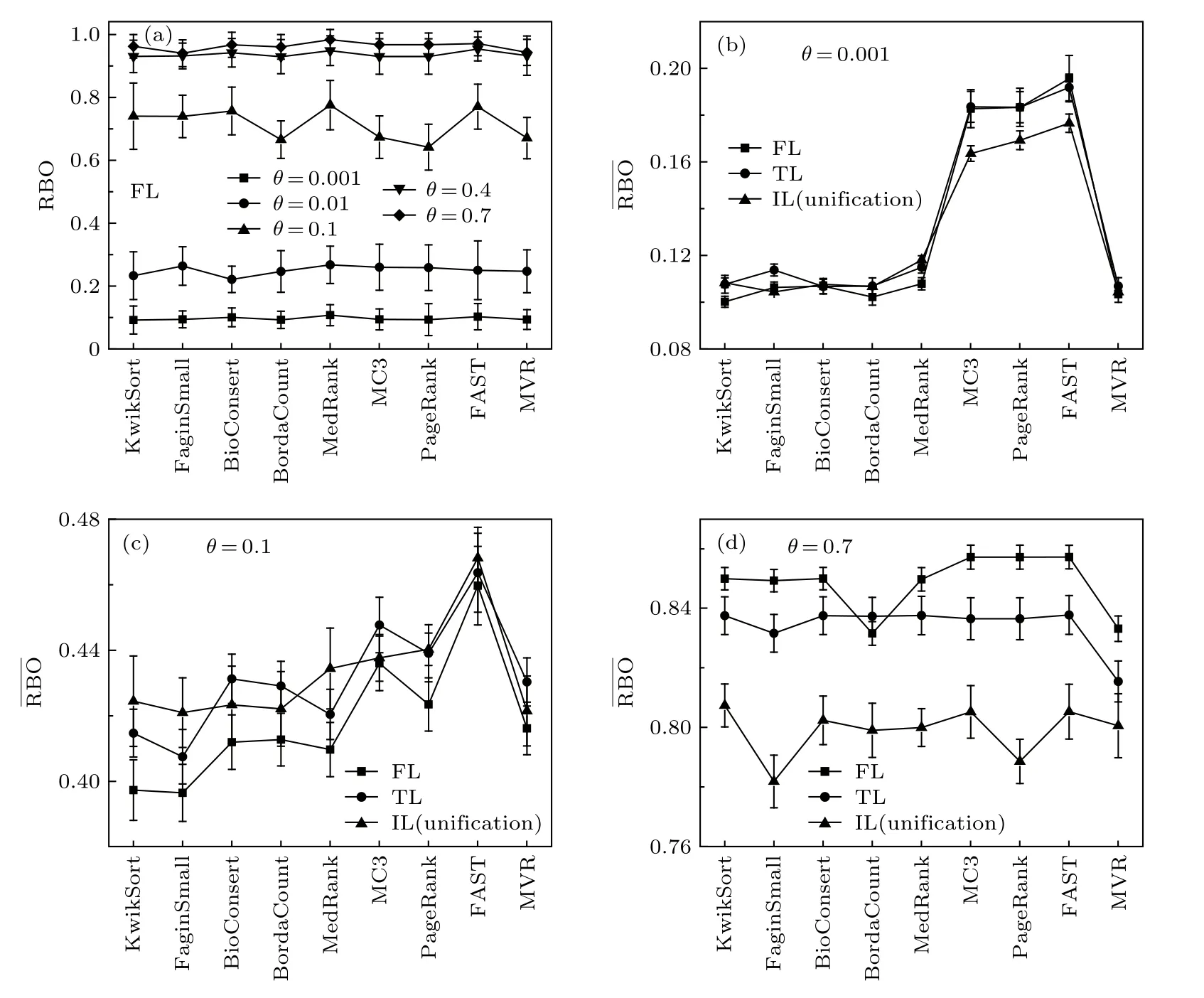
图4 θ 值对算法表现的影响Fig.4.Impact of the degree of consistency θ on the algorithm performance.
7.1 θ值对各方法表现的影响
整体而言,算法的表现主要由数据的发散程度决定.初始数据一致程度越高(θ 越大),列表的发散程度越低,最终的聚合效果也越好(图4).对于FL数据类型,如以聚合排名与中心排名的距离作为衡量标准(图4(a)),各算法之间的表现差异较大,即使在排名列表一致性较高的情况下,启发式算法也有可能不能给出与中心排名相似的结果.优化类算法MVR更适用于例如循环比赛成绩综合等列表长度短、数量多的场景,在少数长列表的情况下,表现较差,往往还不及启发式算法.当 θ 过小时,列表非常发散,任何算法均无法获得与中心排名相似的聚合排名.如以聚合排名与其他排名的平均距离作为衡量标准(图4(b)—图4(d)),在排名列表发散程度较低的情况下,平局的引入(由FL到TL)一定程度上减少了但是在发散程度较高的情况下,平局对于的影响较小.同时,对于TL和IL数据,考察聚合排名与中心排名的RBO值时,发现在不同的一致性程度下,得到了与类似的结论,这里只显示了的结果.整体而言,优化类方法FAST在不同参数 θ 下,其表现均优于其他算法.
7.2 N值对各方法表现的影响
为探究数据一致程度相同的情况下,列表数量N对聚合效果的影响,我们固定列表特征参数(M=100,θ=0.7,rt=0.2,rk=0.8,Δk=0.2),改变列表数量N,结果如图5所示.
对于FL数据,聚合排名与中心排名的相似度基本随列表数量的增加而增加.这与我们的直观感知一致,数据量越大,则生成的排名列表越均匀,得到的综合排名也越接近于中心排名.但也存在少数情况,如波达计数法(BordaCount)与MVR表现随列表数量增加呈现不规则变化.对于TL和IL数据,聚合排名与中心排名的相似度与列表数量的关系与FL数据的结果类似,不能较好地体现聚合算法的差异,因此在考察N值对算法表现的影响时,主要考虑聚合排名与其他排名的平均相似度的变化情况.
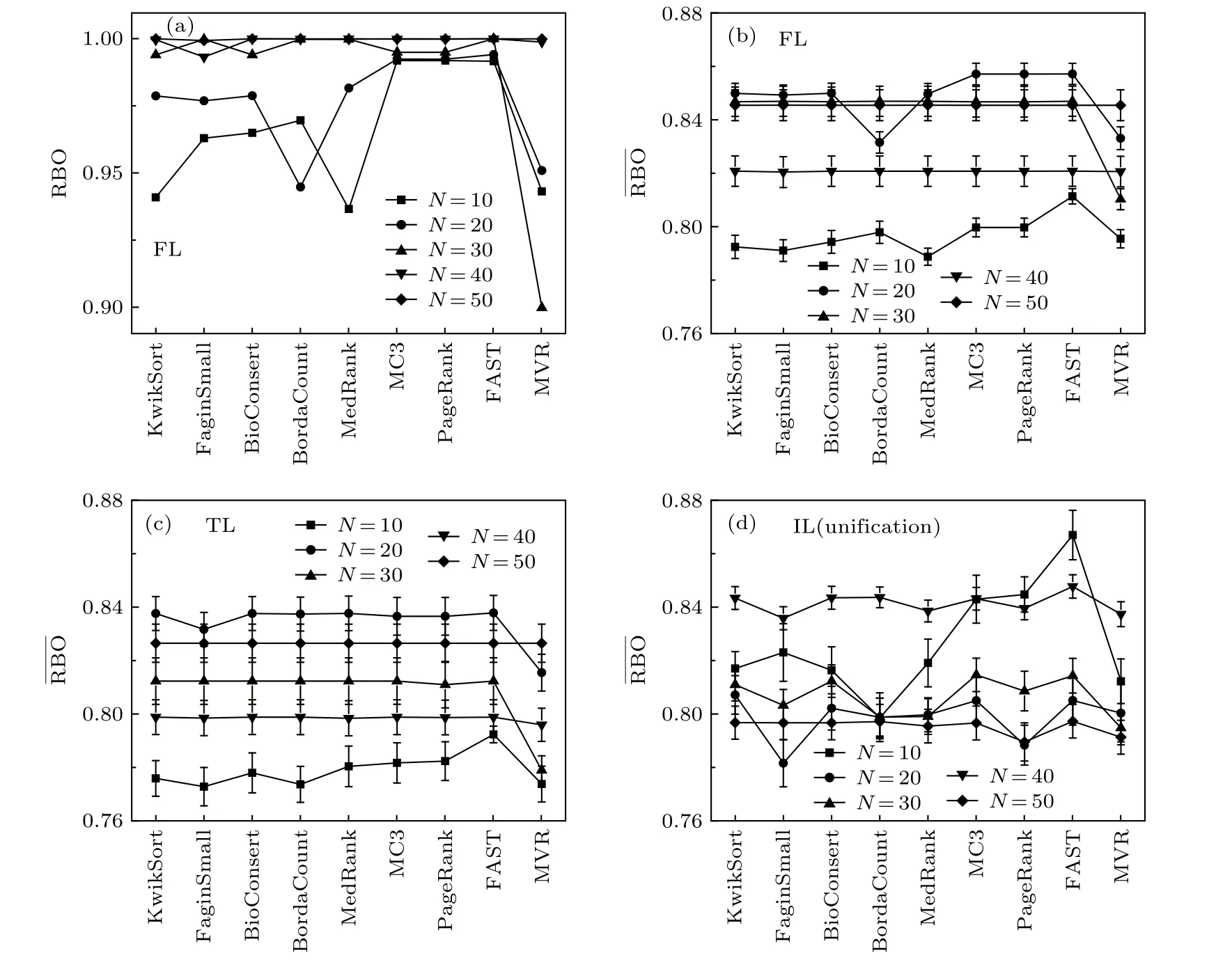
图5 N值对算法表现的影响Fig.5.Impact of the number of rank lists on the algorithm performance.
同时,对于所有列表类型,随着列表数量的增加,各聚合算法之间的相对差异也逐渐减少.整体上优化类方法FAST表现也都较为稳定,R BO 与表现普遍更好.
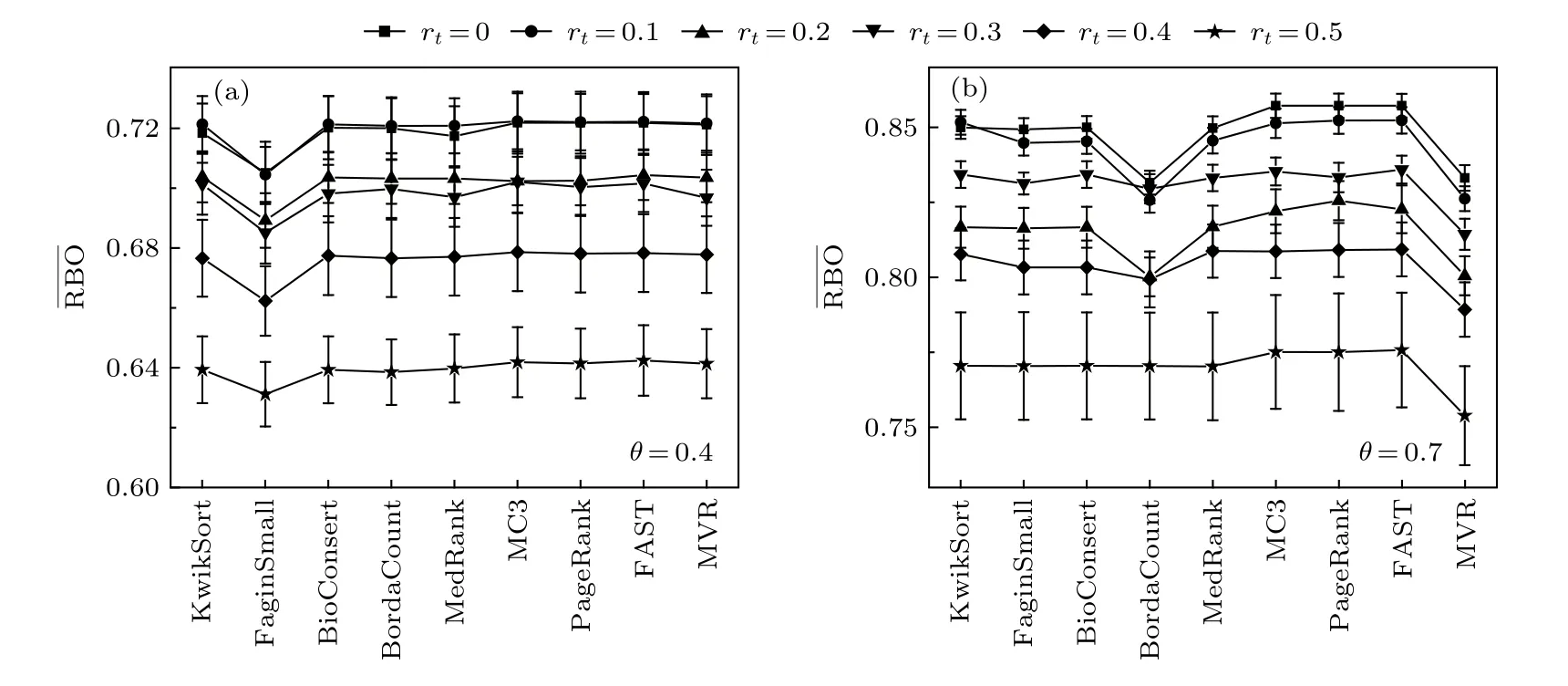
图6 rt 值对算法表现的影响Fig.6.Impact of the parameter rt on algorithm performance.
7.3 平局数量对各方法表现的影响
FL数据和TL数据的区别在于TL包含平局.在实际问题中,TL比FL更常见.我们调节参数rt以分析平局数量对聚合效果的影响,结果如图6所示.
图6(a)和图6(b)分别表示在 θ=0.4和0.7下各聚合方法的最终结果.当 rt=0 时,对应数据类型是完全列表,随着 rt逐渐增大,平局块大小及其数量都在增加,聚合排名与其他排名的平均相似度逐渐下降,且波动性增加(方差增大).不同算法对平局情况的处理结果存在一定差异,例如FaginSmall方法受整体序列一致性程度影响较大,而波达计数法(BordaCount)在序列整体一致性较高但存在平局时的表现较弱,考虑到波达计数法被广泛运用于简单的投票统计,这也一定程度上说明为何一般投票中均没有平局.
7.4 Unification规范化对算法表现的影响
对于一些不能直接处理IL类型数据的排名聚合算法,如 MedRank,BordaCount,BioConsert等,可以通过对数据的规范化处理,将IL数据变为TL数据,使得这些算法可以发挥作用.一般而言有两种规范化处理方法: Projection和unification.Projection只考虑同时出现在所有列表中的对象,将未同时出现在所有给定列表中的对象从每个列表中删除.Unification将未出现在本列表中的对象全部放到一个块中,置于该列表底部,形成一个多对象平局.例如2节示例中的块序列3—5经过unification处理后变为:
块序列3: [A],[C],
块序列3(unification): [A],[C],[B,D];
块序列4: [A],[B],[D],
块序列4(unification): [A],[B],[D],[C];
块序列5: [B],[C,A],
块序列5(unification): [B],[C,A],[D].
在7.1节与7.2节的性能比较中,为了使所有算法均可以参与比较,我们对排名列表进行了unification处理,将不同算法应用到unification后的数据进行比较.对于不能处理IL数据的算法,利用unification处理数据是合理且必须的,但是对于可以处理IL数据的算法,unification可能会带来算法性能的高估或低估.从另一个角度来看,初始数据决定着可用信息量,而经过规范化或简单推理以后,实际上增加了一些人为规则信息,必然会影响最终的聚合排名结果.为探究unification规范化过程对算法表现的影响,我们选用可以处理IL数据的优化类方法FAST和启发式方法PageRank,分析在处理前和处理后的算法性能变化.
为消除列表不等长对结果的影响,令 Δ k=0,改变参数 rk,比较PageRank和FAST不执行规范化和执行规范化的结果(图7).结果发现,聚合排名与其他排名的RBO均值随列表长度呈不规则变化,同时,不执行规范化的结果总是优于执行规范化的结果,这也说明7.1节和7.2节中的结果,一定程度上低估了如FAST这类可以直接处理IL数据的算法,进一步说明了FAST算法在整体表现上的优越性.与此同时,尽管是否进行unification所带来的值差异不大,但是对于需要更精细结果的应用而言,谨慎处理初始数据和规范化也非常重要.
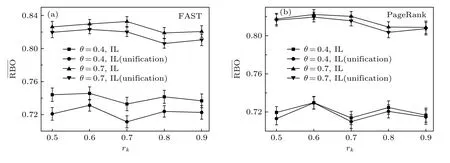
图7 Unification对算法表现的影响Fig.7.Impact of unification on algorithm performance.
8 结 论
使用Mallows模型生成FL排名数据,并提出一套TL和IL数据生成机制以生成人工可控的排名数据,同时,结合有偏等级重叠指标来探究数据特征对不同排名聚合方法的影响.通过本文提出的数据生成机制,可以生成具有不同统计特征的可控数据集.实验结果表明,启发式方法虽然简单,但是在排序列表相似度较高、列表相对简单的情况下,能够接近甚至超过一些优化类方法的结果,例如在完全列表情况下,波达计数法简单可行,最终结果也基本可以接受.整体而言,基于距离优化的分支定界方法(FAST)优于其他各类算法,在不同类型的排序列表中表现非常稳定,能够很好地完成少量长列表的排名聚合.
猜你喜欢
廉政瞭望·下半月(2021年5期)2021-07-20
小学生学习指导(中年级)(2021年4期)2021-04-27
时尚北京(2021年4期)2021-04-12
中学生数理化·中考版(2020年10期)2020-11-27
中学生数理化·高三版(2020年8期)2020-07-24
课堂内外(初中版)(2020年5期)2020-06-19
读者·校园版(2019年16期)2019-07-31
意林(2018年3期)2018-03-02
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中学生数理化·中考版(2015年10期)2015-09-10
