
基于Spark大数据平台的老年病风险预警模型
2020-05-11 11:44谈笑
微型电脑应用 2020年2期
关键词:决策树

摘 要: 针对我国社会老龄化进程加快背景下老年病风险预测的需求,设计基于数据挖掘思想的患病风险预警模型。采用决策树模型,根据居民的年龄、性别、BMI指数、家族病史等多项数据进行树结构的构建与修剪,同时引入Bagging、Boosting和Rotation Forest等方法进行树的训练。最后,使用Spark中的SQL和MLlib实现并行化的决策模型。仿真结果表明,风险预警的准确率可以达到98.07%。此外,集成学习规模对于模型预测的精度影响较小,决策树的剪枝可在不损失预测精度的前提下降低模型的复杂度。
关键词: 决策树; 集成学习; Spark; 疾病预测
中图分类号: TP311 文献标志码: A
Risk Early Warning Model of Geriatric Disease Based on
Spark Big Data Platform
TAN Xiao
(School of Economics and Management, Shanxi Institute of Technology, Xi'an 710300)
Abstract: Aiming at the demand of risk prediction of geriatric diseases, this paper proposes a disease risk early warning model based on data mining. Firstly, a decision tree model is used to construct and prune tree structure based on age, gender, BMI index, family history and other data of residents. At the same time, some methods such as Bagging, Boosting and Rotation Forest are used to train the tree. Finally, the parallel decision model is realized by using SQL and MLlib in Spark. The simulation results show that the accuracy of risk early warning can reach 98.07%. In addition, the scale of ensemble learning has little influence on the accuracy of model prediction. The pruning of decision tree can reduce the complexity of model without loss of prediction accuracy.
Key words: Decision tree; Ensemble learning; Spark; Disease prediction
0 引言
随着我国老龄化速度的加快,老年人的健康状况得到了更多的关注。心血管疾病、糖尿病等老年病,成为危害老年人身体健康的主要杀手。以糖尿病为例,最新研究表明,我国的糖尿病患者人数已超过1亿人。对于老年病,及早的预警可帮助老年人及时改善生活、作息习惯,避免病情的产生和恶化。近年来,由于医疗信息化程度的加深,积累了大量的临床医疗诊断、身体指标等医学数据,医学的发展也进入大数据时代。在此背景下,如何挖掘医疗数据中的有用价值成为了重要的研究课题之一[1-3]。
针对老年病的预警,本文结合机器学习领域的决策树算法,根据居民的年龄、性别、BMI指数、家族病史等多项数据进行老年人糖尿病发病概率的预测,使用Spark大数据处理平台构建了老年病风险预警模型[4-5]。该模型中,引入集成学习的Bagging、Boosting和Rotation Forest等方法,提高了模型训练的效率、模型预测的准确度,证实数据挖掘在医疗大数据背景下的可行性。
1 模型概述
1.1 模型结构
本文使用的模型结构流程图如图1所示。
从图1中可看出,模型包括数据采集、数据预处理、建立决策树模型、集成学习等几个步骤[6-7]。
在数据处理部分,需要对获取的数据进行清洗和数据格式的转换,同时,设计一定的规范进行数据表达和存储。本文重点介绍的是系统使用的决策树模型,并在简单的决策树模型上引入时下流行的Bagging、Boosting和Rotation Forest等集成学习方法,提升决策树的分类性能,增加老年病风险识别的能力。
在传统机器学习领域,通常采用單一模型进行分类[8]。随着计算机的计算能力快速增长和数据量集日趋复杂,集成学习成为提升单一模型性能的重要手段之一,其思路在于使用多个分类器来判断同一个问题[9-13]。在医疗诊断和预测中,使用集成学习方法,可综合多个分类器的预测结果,得到更可靠的判断[12-14]。
1.2 决策树模型
决策树模型是数据挖掘和机器学习领域中常用的算法之一,具有结构简单、易于解释的优点[15-16]。本文在进行老年病风险发现时,将其视作一个分类问题。应用决策树模型,作为基础算法进行分类。在决策树模型中,树结构的建立与树的修剪是最核心的两个流程。
本文使用的算法在决策树结构建立时,基于信息增益率作为分组变量。对于信息源的信息量U,信宿接收到的信息量为V。此时,有条件概率P(U|V)矩阵表示信息传输的概率:P(U|V)=P(u1|v1)P(u2|v1)LP(ur|v1)
P(u1|v2)P(u2|v2)LP(ur|v2)
P(u1|vq)P(u2|vq)LP(ur|vq)
(1) 此时,根据概率学理论,可得到ui的信息量I(ui)信源的信息熵Ent(U)I(ui)=log21P(ui)=-log2P(ui)
Ent(U)=-∑iP(ui)log2P(ui)
(2) 根据信息熵的计算方法,可得到信宿接收信息后的信息熵Ent(U|V)=∑jP(vj)(-∑iP(ui|vj)log2P(uivj))
(3) 信源和信宿之间信息熵的差异称为信息增益GainsGains(U,V)=Ent(U)-Ent(U|V)
(4) 在决策树中,使用式(4)的信息增益进行筛选。当信息增益率最大时,选作最佳的分组变量。
使用式(4)作为标准可得到完整的决策树,但会造成过拟合现象。因此,还需要基于一定的原则对决策树进行剪枝。剪枝的方法为ei=h+zα/2hi(1-hi)Mi
∑ki=1piei>e
(5)1.3 Bagging
Bagging方法的流程图,如图2所示。
其思想在于,首先将整个训练集分为D1,D2,…Dt个子集和弱分类器。然后使用t个训练集分别进行训练弱分类器,获得分类器M1,M2,…Mt。当对x进行分类时,使用类器M1,M2,…Mt共同决策,得到分类结果。
1.4 Boosting
Boosting方法进行训练和表决的流程图,如图3所示。
首选创建k个弱分类器和k个训练子集,然后用第一个弱分类器与对应的分类子集进行训练;在训练第二个弱分类器时,除了其本身对应的训练子集外,加入第一个分类器分类错误影响的相关子集;依次按照此方法,训练所有弱分类器,最终结果由所有分类器投票得到。
1.5 Rotation Forest
Rotation Forest的方法流程图,如图4所示。
在Rotation Forest中,需要借助PCA(主成分分析)算法去除原始数据中的关联项,获得新的训练集,进而可得到更高精度的模型。
2 系统实现
2.1 数据概述
本文设计的模型主要用于老年病风险的预测,因此选取陕西省西安市某三级甲等医院的糖尿病患者的健康档案,同时加入部分健康人群的病患档案。模型使用的训练样本和测试样本的具体情况,如表1所示。
数据项的结构,如图5所示。
2.2 Sprark生态系统
Spark是由Scala语言开发的分布式并行处理框架,整个Spark生态的相关组件。系统中涉及的主要组件是Spark SQL DataFrame和MLlib。如图6所示。
Spark SQL支持标准数据库查询语言和Hive,DataFrame结构更适用于结构化的数据计算;MLlib中包含了大量的机器学习算法,本文使用的决策树算法也包含在MLlib库中。Spark的运行机理,如图7所示。
对于一个Spark应用程序,其至少包含两个部分:SprakContext和Excutor。其中,SparkContext负责程序的驱动,Excutor负责程序的运行。从图7可以看出,首先SprakContext进行初始化,创建一个任务调度模块和作业调度模块。通过集群管理服务Cluster Magnage调度代码运行节点Worker Node,每个运行节点上均有自己的进行Excutor来执行具体的Task。
在进行具体的Spark API调用时,本文使用的是Java语音。
2.3 模型效果仿真
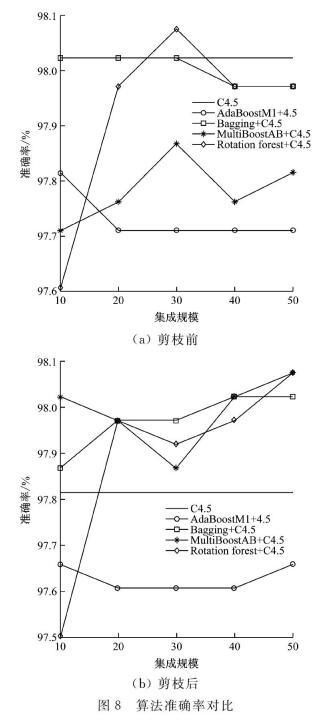
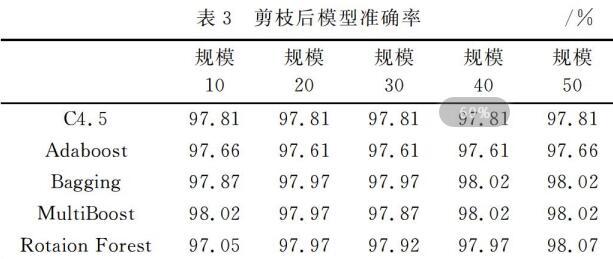
使用Sprak的MLlib库搭建决策树模型,使用Sprak SQL进行数据的读取和存储操作[16]。在评估模型效果时,为衡量集成学习规模对模型的影响,设置不同的集成学习规模:10,20,30,40;为衡量决策树剪枝前后的预测准确率,在决策树剪枝前和剪枝后分别进行模型训练与精度计算;为评估不同集成学习方法对结果的影响,本文选择了AdaBoosst、Bagging、MultiBoost和Rotation Forest这4种方法。剪枝前后每个方法在不同的学习规模下具体结果,如图8(a)、(b)和表2及表3所示。
从模型的仿真结果可看出不同规模下,模型精度变化不明显,集成学习的规模对于模型精度影响较小,这可能是由于模型训练集所使用数据量不够大造成的;修剪后决策树在准确率从98.02%变为97.81%,从数值上看并未降低,精度损失极小,但模型的复杂度有较大的改善;在引入集成学习方法后,决策树修剪前后模型训练的效率和精度均有一定程度的改善。
3 总结
本文对机器学习领域决策树模型在老年病發病率预测上的可行性进行验证,设计针对糖尿病的风险预警模型。模型部署在Spark大数据平台,借助Spark SQL和MLlib库,同时引入集成学习Bagging、Boosting和Rotation Forest等方法。仿真结果表明,预测精度可达到98.07%以上。充分证明,决策树模型和集成学习方法在老年病风险预测上具有可行性。
参考文献
[1] 李季,丁凤一,李翔宇.基于电子病历数据挖掘的疾病危重度动态预测研究[J].信息资源管理学报,2017(4):40-45.
[2] 费海波,童玲,李智.关联规则及关键特征挖掘在临床透析时机选择中的应用[J].软件导刊,2017,16(3):118-121.
[3] 霍东雪,刘辉,尚振宏,等.一种异构集成学习的儿科疾病诊断方法研究[J].计算机应用与软件,2018,35(6):60-63.
[4] 陈霆,蒋伏松,朱兴敏,等.基于随机森林法的2型糖尿病合并非酒精性脂肪肝预测模型[J].中国数字医学,2018,13(11):66-68.
[5] 简艺恒,余啸.基于数据过采样和集成学习的软件缺陷数目预测方法[J].计算机应用,2018(9):2637-2643.
[6] 房乐楠,何腾鹏,刘宇红.一种改进型PSO算法在SVM参数寻优中的应用[J].电子科技,2018,31(6):21-23.
[7] 李娜,侯义斌,黄樟钦,等.基于三轴加速度信号的实时人体状态识别算法[J].北京工业大学学报,2012,38(11):1689-1693.
[8] 林海波,李扬,张毅,等.基于时序分析的人体运动模式的识别及应用[J].计算机应用与软件,2014(12):225-228.
[9] 梅雪,胡石,许松松,等.基于多尺度特征的双层隐马尔可夫模型及其在行为识别中的应用[J].智能系统学报,2012,7(6):512-517.
[10] 朱红蕾,朱昶胜,徐志刚.人体行为识别数据集研究进展[J].自动化学报,2018,44(6):20-46.
[11] 赵仲恺.基于组合分类器的神经网络算法[J].电子科技,2017(12):43-46,51.
[12] 艾新龑,毛文涛,田梅.基于机器学习技术的在线疾病诊疗方案倾向性识别研究[J].中华医学图书情报杂志,2018,27(7):1-5.
[13] 赵家英.面向健康评估的机器学习方法研究与应用[D].成都:电子科技大学,2016.
[14] 劉宇晨.基于多尺度ICA方法与多模态皮层结构特征的无先兆偏头痛患者的脑机制研究[D].西安:西安电子科技大学,2018.
[15] 徐旭冉,涂娟娟.基于决策树算法的空气质量预测系统[J].电子设计工程,2019, 27(9):39-42.
[16] 黄成兵.一种多层次分布式数据挖掘方法的改进研究[J].现代电子技术,2017, 40(9):78-80.
(收稿日期: 2019.08.06)
基金项目:陕西省职业技术教育学会项目(SZJZX-1821)
作者简介:谈笑(1988-),女,天津人,硕士,讲师。研究方向:老年服务与管理,医院信息管理。文章编号:1007-757X(2020)02-0071-04
猜你喜欢
科学与信息化(2019年28期)2019-10-21
河北工业大学学报(2019年6期)2019-09-10
科学与财富(2016年32期)2017-03-04
无线互联科技(2016年14期)2017-02-06
软件导刊(2016年12期)2017-01-21
求知导刊(2016年28期)2016-11-28
科技视界(2016年7期)2016-04-01
科教导刊·电子版(2016年3期)2016-03-14
智富时代(2015年3期)2015-05-22
智富时代(2015年3期)2015-05-22
