
始发保优的序列比对
2020-05-14 07:43陆成刚
小型微型计算机系统 2020年5期
陆 成 刚
(浙江工业大学 理学院,杭州 310023)
E-mail:luchenggang168@gmail.com
1 引 言
序列比对是矢量聚类或模式分类的基础,它的核心功能是计算模式之间的相似(异)性的程度.无论哪一种聚类分类方法,本质上都要基于某种内置的距离运算.常规的欧几里德距离可以看作是一种静态的序列比对,而经典的DTW距离(DTW英文全称Dynamic Time Warping即动态时间规整)则以动态对齐模式的距离计算而闻名[1-3].数学上可以证明,DTW距离并不符合距离公理的三角形法则(但满足非负性、对称性法则),所以它并不支持使用算术平均来计算多个矢量的质心(距离满足三角形法则是使用算术平均计算该距离意义下质心的必要条件),也因此在k均值聚类、模糊c均值聚类等领域应用受到限制[4,5].事实上,在DTW对齐模式下求两个矢量的算术平均是可以得到它们的(基于DTW距离意义下的)质心的,只是对于三个以上的矢量求它们的动态对齐方式是比较困难的,这就是所谓的动态规划算法的“维数灾难”问题[6-8].在两个序列之间使用DTW计算距离具有一些不可多得的优势,如能适应序列在时间轴上的伸缩变异,又能适应参与比较的两个序列长度不一致的情况.在层次聚类、kNN近邻法、PCA聚类、谱聚类和DBSCAN聚类法中只涉及计算两两之间的序列距离[9-13],因而都可以使用DTW距离作为内置.
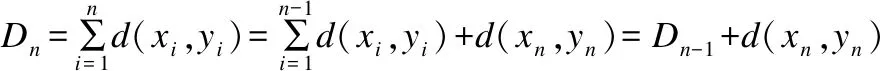
2 DTW的重新理解
2.1 DTW距离
DTW是使用动态规划方法搜寻序列间足标的一种最佳对应使它们具有最小的距离.DTW距离主要使用在评估两个数据序列之间的相似性上.特别是基于DTW距离的kNN匹配分类法一度是近十几年间序列分类识别应用领域的经典标配[16-18].如图1示例了常规欧几里德距离的静态对应和DTW距离的动态对应之间的差异:前者具有平行平均的对应间隔、后者完全是不规则对应的.
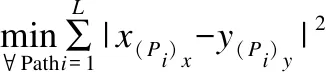
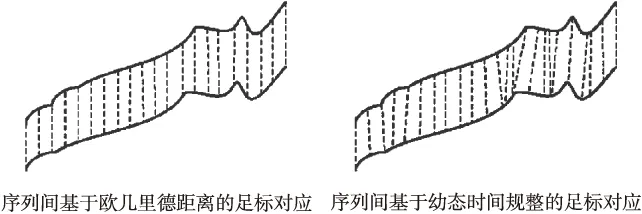
图1 DTW动态时间规整具有捕捉序列时长动态差异的特性
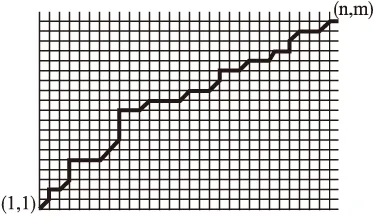
图2 坐标轴点阵的路径
传统的DTW距离算法是基于动态规划原理进行的,引入状态变量D(i,j)表示由P1=(1,1)到点(i,j)的最小距离,于是D(n,m)就是所求的DTW距离.状态变量D(i,j)有递推式D(i,j)=min{D(i-1,j-1),D(i-1,j),D(i,j-1)}+d(i,j)其中d(i,j)=|xi-yj|2或d(i,j)=|xi-yj|.根据递推公式生成状态矩阵(D(i,j))m×n,其中首行首列通过其唯一前邻点来生成,取得最小值的最优路径由终点(n,m)逆溯到起点(1,1)而得到.取得路径的逆溯过程的伪码如下.
1) Path=NULL,(n,m)→Path;
2)i=n,j=m;
while(i>1 or j>1)
{
if(i==1) j=j-1;
else if(j==1) i=i-1;
else i, j get value from
min{D(i-1,j-1),D(i,j-1),D(i-1,j)};//将最小者对应的足标赋给i、j
(i,j)→Path;
}
3) Inverse(Path);//将Path中各点倒序;
2.2 DTW更新解读
DTW距离求解法是基于状态变量的递推方程施行的,而递推方程成立是利用了平方距离或曼哈顿距离的累计可加性.利用距离形式的累计可加性可以得出达到最优值的路径也具有保持最优性的可加性(简称可加保优性),这就是定理1.
首先介绍路径全分割:如图3中路径Path={P1,P2,…,PL}分割成多个片段,每个片段称谓子路径(Subpath),前后相邻的子路径共享一端点,所有子路径的依次串接(共享的端点只计一点)恢复为原路径.
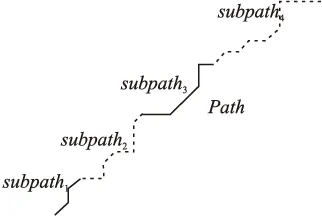
图3 路径的全分割示意图:路径Path被分割为4段子路径Subpath,且第一条子路径的起点P1,第4条子路径的终点PL
定理1.设Path={P1,P2,…,PL}是DTW距离的(最优)路径,则对该路径的任何一个全分割,每条子路径都是其自身起点到其自身终点的最优路径.反之,Path={P1,P2,…,PL}的任意一个全分割的每条子路径都是其起点到其终点的最优路径,则Path={P1,P2,…,PL}是DTW距离的(最优)路径.
证明:先证前面的结论,使用反证法,假设{Pi,Pi+1,…,Pj}⊂{P1,P2,…,PL}是一条子路径,并且{Pi,Pi+1,…,Pj}不是序列(x(Pi)x,x(Pi)x+1,…,x(Pj)x)和(y(Pi)y,y(Pi)y+1,…,y(Pj)y)间DTW距离对应的最优路径.求得它们的DTW距离对应的路径不妨设为{Pi′,Pi′+1,…,Pj′}其中Pi′=Pi且Pj′=Pj,则{P1,P2,…,Pi-1,Pi′,Pi′+1,…,Pj′,Pj+1,…,PL}对应的距离数值应小于Path={P1,P2,…,PL} 对应的距离数值,这与Path={P1,P2,…,PL}是DTW距离对应的(最优)路径矛盾.再证后面的结论,反之,Path={P1,P2,…,PL}本身也是它自己的一个全分割,它是最优路径,所以它是DTW距离的(最优)路径.证毕.
引入始发路径的概念:以端点(1,1)为起点的路径称为始发路径.如果对路径上任意点作终点的始发路径都是从(1,1)到该点的最优路径,则称该路径具有始发保优性.DTW距离路径即具始发保优性,此为推论1.
推论1.设Path={P1,P2,…,PL}是DTW距离的(最优)路径,则以该路径上任意点作终点的始发路径都是从(1,1)到该点的最优路径.反之,如果Path={P1,P2,…,PL}满足这样的性质:以该路径上任意点作终点的始发路径都是从(1,1)到该点的最优路径,则Path={P1,P2,…,PL}是DTW距离的(最优)路径.
证明:在Path={P1,P2,…,PL}任取一点作始发路径的终点,则该始发路径与以该点作起点、(n,m)为终点的子路径构成原路径的全分割,根据定理1,该始发路径为最优路径.反之是显然的.证毕.
图4示意了始发最优特性,一条最优路径上任意点作终点的框内部分(路径)都是最优的.

图4 始发最优示意
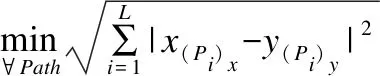
3 DTW距离的缺陷
传统的DTW距离隐含着一种缺陷,例如考虑使用DTW距离计算以下三段直流信号的匹配情况:A=(0.1,0.1)、B=(0.25,0.25,0.25,0.25)、C=(0.28,0.28,0.28),信号A与B的DTW距离为0.6,其最优匹配路径的长度为4;而信号C与A的DTW距离0.54,最优匹配路径的长度为3.从我们直觉判断信号B比信号C更接近A,但从DTW距离决定的相异性来看,反而是C比B更接近A.造成这个反直觉的效果是由于我们仅仅考虑了距离,而忽视了路径长度,假如以DTW距离相对路径长度的平均值而言,B比C更接近A.传统DTW的缺陷是没有考虑路径长度平均的距离,从而可能导致两个同类序列的距离大于两个异类序列的距离.这就违背了“距离大小决定相异程度”的准则.定理2从理论上揭示了这种可能性.
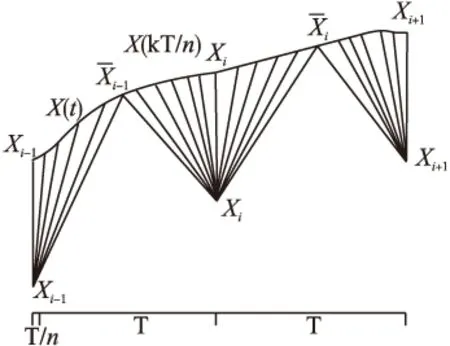
图5 信号重构采样后的DTW匹配
定理2.设对于序列S1其采样周期为T,先将S1使用sinc插值恢复成模拟信号,再使用T/n的采样周期离散化形成序列S2,S2长度n倍于S1、但两者仍属同类序列,可证S1和S2的DTW距离随着n的增加而无限制增加,势必将大于S1与任一确定的其它类序列H的DTW距离.
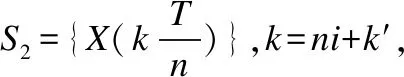
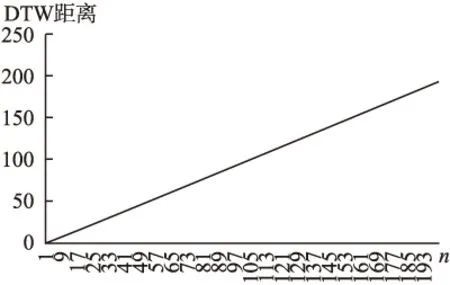
图6 同类序列DTW距离随着长度差异变大而变大
可见考虑路径长度平均意义下的DTW距离是必要的,而这又牵涉到对于不满足累计可加特性的距离形式的处理.
4 基于始发保优的延拓
对序列X=(x1,x2,…,xn)与Y=(y1,y2,…,ym),定义满足端点条件、连续性和单调性的足标对应的路径Path={P1,P2,…,PL},提出三个组合优化问题
(1)
(2)
(3)

显然平均距离、Pearson相关系数和Tanimoto系数不满足累计可加性,组合优化问题式(1-3)的最优解没有保优可加性结构.由于始发保优特性易于算法实施,受此启发,提出修正的最优路径问题.考虑任意的终点为(μ,υ)的始发路径,记作Path(μ,υ),由此对应的三个组合优化问题衍生为三族问题,即
(4)
(5)
(6)
式(4-6)是三族优化问题,每族都考虑为μ=1,2,…,n;υ=1,2,…,m遍历整个点阵时的一系列组合优化问题,由此开发的算法称为始发保优的序列比对.当只考虑(μ,υ)=(n,m)时式(4-6)蜕化为式(1-3),可以理解为式(4-6)的解路径是式(1-3)的解路径附加满足始发保优性质的解路径.
由式(4-6)求得的系数不妨称作动态平均距离、动态Pearson系数和动态Tanimoto系数,照例它们满足距离公理的非负性法则和对称性法则,且序列X=Y时动态平均距离为0,而动态Pearson系数和动态Tanimoto系数均为1.
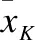
lij:表示(x1,x2,…,xi)与(y1,y2,…,yj)依始发最优特性计算绝对值最大Pearson相关系数时得到的对应路径的长度;
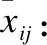
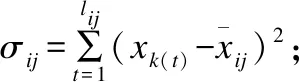
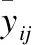
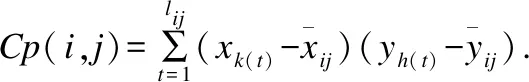
再引入这些统计量的累计计算公式,设(i′,j′)是当前点(i,j)的一个后继,即(i′,j′)=(i+1,j)或者(i′,j′)=(i,j+1) 或者(i′,j′)=(i+1,j+1),则
li′j′=lij+1
(7)
(8)
(9)
(10)
(11)
(12)
以上诸公式中式(7)是显然的,式(8、10)是均值累计计算原理的应用;式(9、11)本质上也是均值的累计计算,只是在应用式(8、10)结果基础上再进行累计计算;式(12)是内积的累计计算,可以通过内积的定义直接验证.由此得到(i′,j′)的绝对值Pearson相关系数
(13)
下面给出以式(5)作例子的动态Pearson系数算法,其它两族问题的算法类推可得.
动态Pearson系数算法
2.令k=1,h=2,3,…,m;l1h=l1h-1+1,
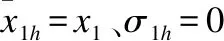
c1h=0
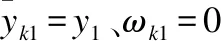
ck1=0
4.令k=2,3,…,n,h=2,3,…,m;

当(u,v)遍历{(k-1,h-1),(k-1,h),(k,h-1)}得到三个|ctemp|中取最大的一个(在计算动态平均距离时取最小的一个,而动态Tanimoto系数也是取最大),此时(u,v)=(u0,v0)为{(k-1,h-1),(k-1,h),(k,h-1)}里的具体的一个格点.因而利用式(7-13)更新矩阵元素如下
lkh=lu0v0+1
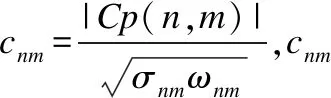
6.对其它两族优化问题可以施行同样的算法,这类算法可以总结为如图7的四个模块:首先是初始化,如以上算法的步骤1;其次对涉及到的统计量构成的矩阵更新其首行首列,如以上步骤2、3;然后依据式(7)-式(13)的累计计算原理更新矩阵的其余部分,如以上步骤4;最后是输出结果如以上步骤5.

图7 动态系数算法框架
Fig.7 Algorithm framework for dynamic mode
图8-图10示例了DTW距离与动态平均距离、Pearson系数与动态Pearson系数、以及Tanimoto系数和动态Tanimoto系数的执行效果的比较:
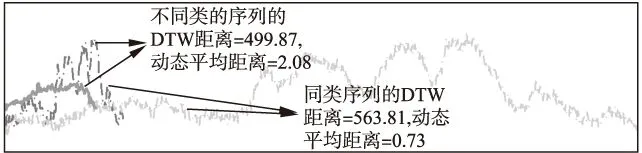
图8 DTW距离与动态平均距离的比较
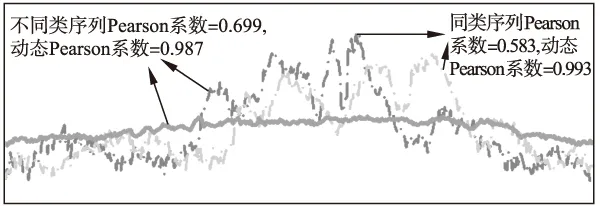
图9 Pearson系数与动态Pearson系数的比较
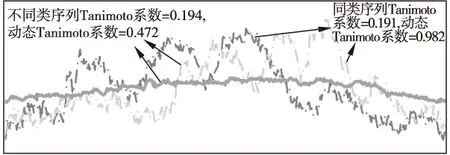
图10 Tanimoto系数与动态Tanimoto系数的比较
在图8-图10中点划线示例的是同一类序列,粗实线代表另外一类.图8的DTW距离和动态平均距离的示例显示相同类别的序列距离反而比不同类别的序列的距离远,而动态平均距离则能正常地显示同类距离近、异类远.造成DTW距离度量失效的原因是DTW距离对序列长度分布的不均匀程度比较敏感,从而引入了路径长度对距离数值的干扰.主要表现在同类的序列、但长度相差较大时,DTW距离的数值较大,“掩盖”了它们本该相似的属性.在算法测试部分,更多的序列测试证实了动态平均距离优于DTW距离.图9、图10使用长度相同的序列作比较,常规Pearson系数和Tanimoto系数均在同类序列显示值为小、而异类序列值为大,动态计算的Pearson系数和Tanimoto系数能有效地“纠正”这个反常现象.
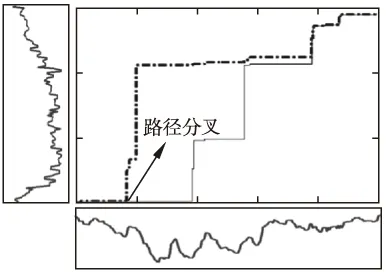
图11 动态平均距离的最优路径不满足可加保优性
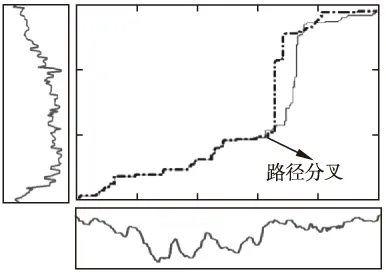
图12 动态Pearson系数的最优路径不满足可加保优性
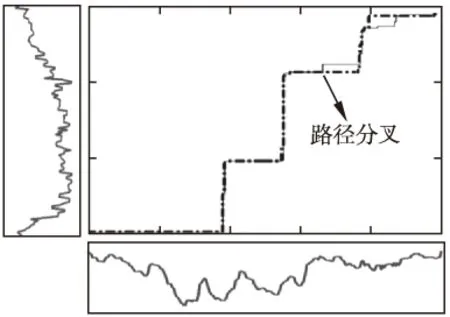
图13 动态Tanimoto系数的最优路径不满足可加保优性
式(4-6)是始发保优原则衍生的三族优化问题,但解路径依旧没有传统DTW路径的可加保优特性.假如在依式(4-6)的最优模式中获得的全局最优路径上任意取定一点,以此为界,构造一个分割,那么从始发点到该点的最优路径与全局最优路径的前部分重合,而由该点到终点的最优路径与全局最优路径的后部分不一致,产生分叉.图11-图13分别示例了这个由分割点产生路径分叉的现象.它证实了基于式(4-6)的序列比对法满足始发保优,但不满足可加保优特性.
最后对DTW距离、动态平均距离、动态Pearson系数、和动态Tanimoto系数进行算法复杂度分析,主要考虑算法框架中涉及到的矩阵变量的数目,因为它既关联到缓存占用大小,又关联到更新矩阵元素的计算量.这里不考虑临时变量、辅助变量、以及编程时各种数据类型占用内存的差异.由于输入序列段长分别是m和n,所以一个矩阵变量的资源数目就是mn,它既是缓存开销的大小,也是计算量级.表1显示了四类方法的计算资源的消耗量级.易知,DTW只需更新距离矩阵,所以是1个mn单位,而动态平均距离除了距离矩阵外,还需要更新路径长度矩阵,所以是2个mn单位;动态Pearson方法包含路径长度矩阵、序列X和Y的均值以及方差的矩阵、内积矩阵和Pearson系数矩阵共7个mn单位,类似可得动态Tanimoto系数方法的复杂度是3个mn单位.
表1 四类比对方法的计算复杂度比较
Table 1 Computation complexity comparing for 4 alignment methods

比对方法DTW动态平均距离动态Pearson动态Tanimoto内存消耗mn2mn7mn3mn计算量级mn2mn7mn3mn
5 动态平均距离的算法测试
相对来说动态平均距离具有最接近原始DTW方法的计算资源占用效率,而且两者皆是距离属性,可比度强,在算法测试阶段专门以动态平均距离作代表与DTW作算法效果比较.实验数据来源于国家环保部设立在浙江省环保厅的全国电离辐射测量监测中心.测试集是包含4298例环境电离辐射时间序列的波峰样本,它们已经被人工标注为4类.序列集的平均长度为237.94点,根差为96.78,可见数据长度的分布有较大的不均匀性.这原因其一是由于波峰段检测提取技术的限制,造成波峰前后带有较多或较少的平缓部分;其二是电离辐射剂量波峰本身由于环境因素如持续时长不一的降水会导致波峰长短不一的现象.我们采用层次聚类法分别以DTW距离和动态平均距离作内置进行聚类,层次由底层向上层演进,聚类循环的停机阈值为类数4.

图14 序列聚类算法的计数统计矩阵

如图14(a)所示DTW距离内置的聚类结果统计,计数矩阵的非对角元数目较大,这表示算法的漏检率、虚警率都较高;而图14(b)显示动态平均距离作内置的层次聚类执行效果较好,计数矩阵的非对角元数目较小.由表2统计DTW距离的平均F值仅为61.1%,而动态平均距离可达到的平均F值为96.9%,平均F值比前者竟高达35.8%.通过对于4298例已标注数据的算法测试,相对于DTW距离,就平均F值来说动态平均距离对算法性能的提升在35个百分点以上.
表2 对4298例序列进行层次聚类的定量分析
Table 2 Quantity analysis based on hierarchy clustering for 4298 samples
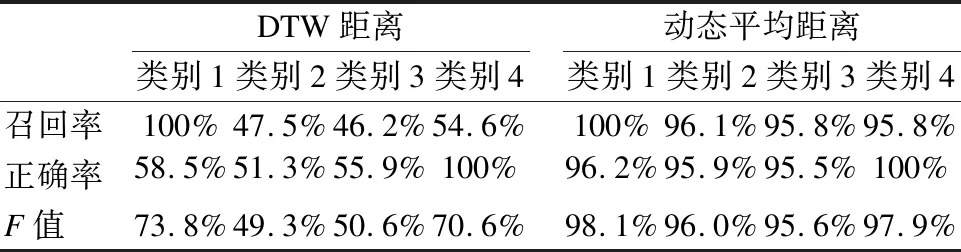
DTW距离类别1类别2类别3类别4动态平均距离类别1类别2类别3类别4召回率100%47.5%46.2%54.6%100%96.1%95.8%95.8%正确率58.5%51.3%55.9%100%96.2%95.9%95.5%100%F值73.8%49.3%50.6%70.6%98.1%96.0%95.6% 97.9%
另使用6182例4类别波峰段的标注数据集进行kNN最近邻法分类测试,该数据集段长平均为180.7、根差为168.9.且与前面4298例数据集不同的是每条测试数据均含有外点成份,如图15所示.电离辐射检测仪器故障自动重启、分布式监测网络数据传输中断等设备异常会造成电离辐射时间序列夹杂一定的随机外点或噪声.作为kNN法模板库的样本采用当前全部被测数据集合之外的波峰段、且经人工挑选而一律不含随机外点成份.


图15 6182例4种含外点的波峰段类型示例,其中3个外点是突降型,另外一个突升型
从表3看出在6182例数据集所含具有较悬殊的信号长度差别的动态特性下,将DTW距离和动态平均距离用于kNN模式分类时,后者的识别精度显著地优于前者.
表3 对6182例数据集进行kNN近邻法分类的定量分析
Table 3 Quantitative analysis of k nearest neighbor classification for 6182-samples set

类别DTW距离类别1类别2类别3类别4动态平均距离类别1类别2类别3类别4F值96.4%94.4%95.3%94.1%99.7%99.8%99.7%99.8%
表4 对杭州50年降雨数据进行kNN近邻法的丰涝旱适分类
Table 4 Classification of the drought and waterlogging in the 50-year rainfall data of Hangzhou using the kNN

类别DTW距离涝丰适少动态平均距离涝丰适少F值98.6%99.2%97.8%96.4%99.8%99.4%99.6%99.2%
电离辐射波峰跟降雨及降雨持续时间有关,另考虑杭州近50年各年份日降雨量序列数据集,对部分整月数据进行雨涝、丰水、适中和少雨等四个类型标注,并对其余整月数据进行kNN近邻法分类,然后对分类结果进行人工核验,所得F值分析为表4,显然动态平均距离内置的分类器更优.
6 总 结
数据序列的比对是模式聚类和识别的基础,而遍历数据的方式又是序列比对的基础.以DTW距离为代表的数据动态对齐方式是一类行之有效的数据遍历方式,它突破了传统静态距离计算的局限,不仅能适应时长不一致的序列比对,更能捕捉到数据时长伸缩的差异.如何将动态比对下的距离计算拓展到非一般距离,如平均距离、Pearson相关系数、和Tanimoto相似系数等,是一个有趣而实用的课题.我们的研究工作围绕着距离形式失去累计可加性时,如何使用类似DTW算法的结构去计算动态平均距离、动态Pearson系数和动态Tanimoto系数,提出了始发保优的概念,并将其施行于算法的设计,创建了一系列的序列比对方法.并以算法复杂度最低的动态平均距离作代表进行大量标注数据集的层次聚类测试,算法执行效果较DTW内置的聚类法整体性能提升了35个百分点以上.且在使用kNN进行序列匹配分类测试时内置动态平均距离较DTW距离仍能取得更高的精度.将来如何将动态平均距离内置到k均值聚类是一个更值得期待的工作.文献[4,5]使用类似最大期望法进行基于DTW距离的k均值聚类中心的生成,这个方法同样适用于基于动态平均距离的k均值聚类.我们计划实现这种聚类方法,并且基于动态平均距离比DTW距离更吻合“距离大小决定相异程度”的原则,从而期待证明动态平均距离在无监督聚类上比DTW距离具有更优越的表现.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
小学生学习指导(低年级)(2020年10期)2020-11-26
少儿画王(3-6岁)(2020年4期)2020-09-13
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
东方教育(2018年20期)2018-08-22
作文大王·低年级(2017年11期)2017-12-05
学苑创造·A版(2017年1期)2017-01-19
西南学林(2013年2期)2013-11-12
