
一种面向密码SoC的高性能全双工DMA设计
2020-05-18 11:07吕广秋南龙梅
计算机工程 2020年5期
吕广秋,李 伟,陈 韬,南龙梅
(信息工程大学 信息安全重点实验室,郑州 450001)
0 概述
在密码片上系统(System of Chip,SoC)内集成专用协处理器以加速密码运算,已成为目前高性能SoC设计的重要方法。密码SoC的性能受主处理器、协处理器以及数据调度控制的影响[1-2],其中,直接内存存取(Direct Memory Access,DMA)设计尤为重要。DMA的外围设备能直接访问内存,使其在内存数据拷贝[3-5]、实时数据采集[6-8]等数据密集型应用中得到广泛应用。
密码SoC等数据密集型应用对数据传输带宽的需求较高,因此,DMA传输的总线带宽利用率直接影响密码SoC的整体性能。文献[9]中的SoC多层总线通信架构对IP在总线中的挂载分布提出更高要求,因此,其难以显著提高传输性能,且存在总线带宽利用率低、资源占用和功耗较大的缺点。文献[10-11]中更高性能的总线虽然具有更大带宽,但其在密码应用中总线带宽利用率以及重复任务和多任务传输效率均较低的问题仍未得到解决。
文献[12]提出一种支持链表和多通道传输的DMA,其支持多个顺序固定的DMA传输,但具有密码协处理器利用率不高、重复任务和多任务传输效率低等不足。文献[13-15]提出基于双总线的全双工DMA,虽然其实现了并行读写数据的功能,但总线闲置率过高且未提高同一总线上IP的DMA传输速度。文献[16]提出专用轻量级DMA,其通过专用接口实现并行访问,但该DMA传输范围局限在固定IP与其他IP之间,难以支持任意2个IP之间的DMA传输。文献[17]使用多个DMA引擎实现数据预取,但其对无延迟的数据访问未取得优化效果。
本文借鉴已有研究根据特定应用优化DMA设计的思想[18-20],同时结合密码SoC数据流的特点,设计一种面向密码SoC的高性能全双工DMA。针对总线带宽不足的问题,通过流水线技术对特定模块的DMA传输开辟专用通道以实现并行读写,无需更改总线结构,仅在特定模块接口和DMA读写控制器中进行少量更改便可大幅提高特定模块的DMA传输速度。针对DMA传输的控制、配置等时间过长的问题,本文DMA加入循环传输模式,实现DMA自主控制重复任务的循环执行,减少CPU启动、配置和返回等重复操作,提高传输效率和带宽利用率并降低CPU占用空间。针对协处理器利用率不高的问题,通过动态优先级技术完成各通道面向服务质量(Quality of Service,QoS)的自适应传输,进一步提高系统的传输效率和质量。
1 密码SoC性能分析
1.1 密码SoC内数据流特征分析
通用密码SoC包含通用主处理器CPU、片上存储器、随机存储器RAM、高速接口、DMA和协处理器等部分,其结构如图1所示。通过分析密码服务特点可知,当密码SoC提供密码服务时,数据流向归总为4路DMA通道传输,如图1中虚线箭头所示:
①大量待处理数据由高速接口进入片内RAM。
②片内RAM的数据进入协处理器并被处理。
③数据处理完成后返回RAM。
④片内RAM中的数据传回高速接口完成一次密码服务。

图1 密码SoC中数据流特征
1.2 密码SoC性能瓶颈分析
密码SoC的数据处理速度VP主要由数据传输速度VT、协处理器利用率α和数据处理最大速度VCo决定,即:
max(VP)=min(VT,α·VCo)
(1)
协处理器的最大速度VCo由本身硬件设计决定,本文不做讨论。数据传输速度VT过低将会产生2种降低密码SoC性能的情况:
1)当协处理器数据传入速度VDataIn<α·VCo时,将会出现数据断流,即协处理器必须等待数据输入。
2)当协处理器数据传出速度VDataOut<α·VCo时,将会导致数据阻塞,即协处理器必须等待数据传出。
总线带宽利用率β定义如下:
(2)
其中,tD为数据传输周期数,tT为总线被DMA设备占用的时钟数。在理想情况下,传输1个数据最少花费1个时钟周期,即β最大为100%。
数据传输速度VT等于整个密码服务期间DMA通道的数据平均传输速度VDMA_ave。当前密码SoC数据传输可用带宽B为:
(3)
其中,Bmax为系统总线的最大带宽,VDMA_i_ave为DMA多个通道共用总线时第i个DMA通道的数据传输平均速度(本文中n=4),B其他为总线上其他操作占用的带宽。当B其他=0时,DMA通道传输速度达到最大,由对称密码应用中各个DMA通道数据传输量相同得到:
VDMA_i_ave≤Bmax×β/n
(4)
DMA传输是密码SoC最主要的数据传输方式,其直接决定带宽利用率β的大小。DMA传输流程分为4步:
1)配置DMA传输。
2)DMA将源地址数据读取至FIFO。
3)DMA将FIFO数据写入目的地址。
4)完成传输,挂起中断或等待CPU轮询。
由此可知,DMA的传输速度为:
(5)
其中,VDMA_i为DMA启动传输到结束传输的平均速度,LB为DMA传输的数据长度,TConfig为配置时间,TStart和TDMA返回为传输启动和完成反馈的时间,TDMA读+TDMA写为DMA读写耗费时间。
在式(5)中,DMA传输效率受定长时间的配置、启动和返回等操作影响,同时受由DMA读写方式决定的DMA读写耗费时间的影响。目前,学术界和工业界将DMA的读写方式分为三类,如表1所示。

表1 3种DMA读写方式的带宽利用率对比
设T1为TConfig+TStart+TDMA返回的值,不同DMA读写方式下的DMA传输速度为:
(6)
式(6)表明,传输数据长度LB越大,则DMA传输速率VDMA_i越高。本文中LB的单位为字(Word)且T的单位为时钟节拍数(Clock),此时有β=VDMA_i。当LB足够大时有VDMA_i=β≈1/m。
联合式(1)、式(4)和式(6)可知,密码SoC的数据处理速度VP可表示为:
(7)
由式(7)可知,密码SoC的最大数据处理速度VP无法大于总线可用带宽的1/n或α·VCo。
密码SoC中的Bmax、VCo和LB分别由总线类型、协处理器硬件设计和密码SoC数据处理分组长度决定,参数固定。为使得密码SoC性能最大化,本文将在影响因子m、n、T1、α方面对DMA进行优化。
2 面向密码SoC的DMA分析
为提高密码SoC的性能,本文从3个方面对DMA设计进行优化:使用专用接口进行全双工的DMA读写传输,降低DMA重复配置与启动的时间,改变传输通道优先级的自适应传输。
由式(7)可知,密码SoC的性能由协处理器利用率决定,而协处理器利用率又受数据传输速度影响,因此,得到密码SoC性能最大化的必要条件和充分条件如下:
1)必要条件:数据传输速度VT足够大,不会限制协处理器利用率α和密码SoC性能。
2)充分条件:协处理器利用率α达到最大,此时密码SoC性能最大。
当密码SoC性能最大化的必要条件未满足时,设V′P为密码SoC的最大数据处理速度,由式(7)可知:
(8)
其中,影响因子m、n和T1对V′P的影响关系和取值范围如下:
(9)
式(9)表明,为使得SoC性能最大化的必要条件未满足时V′P最大,应最小化m、n和T1。
本文在特定模块中开辟专用接口以实现并行读写的全双工DMA传输。由表1可知,此时m为最小值1,且AHB总线上执行的DMA传输通道个数n由4降为2。本文DMA专用接口占用硬件资源极小,在未改变系统总线结构的前提下实现了数据的全双工读写,极大地提高了数据传输速度并降低了总线传输负载。

(10)
(11)
由式(10)、式(11)可知,本文DMA的循环工作模式使得总线带宽利用率和传输效率接近总线传输的理论上限值,从而最大化DMA的传输速度。当密码SoC性能最大化的必要条件满足后,密码SoC的性能受限于协处理器利用率α,即:
V′P=α·VCo
(12)
为使协处理器利用率α最大,本文DMA采用多通道的动态优先级技术,实现了优先保证协处理器输入FIFO非空、输出FIFO非满,使得当SoC性能最大化的必要条件满足时协处理器利用率α接近100%且密码SoC的性能最大,最终实现密码SoC中数据的自适应传输。
将通用DMA、链式DMA和本文DMA应用于密码SoC后,其协处理器利用率变化如图2所示。其中:
①为通用DMA等待LB大小的数据处理完毕后再进行数据搬移时发生数据断流,协处理器处于空闲。
②为链式DMA提前传输FIFO中处理完毕的数据,数据断流得到缓解。
③为DMA传输优先保证协处理器输入FIFO非空、输出FIFO非满,消除数据断流和阻塞,最大化协处理器利用率α,从而极大地提高了密码SoC性能。

图2 3种DMA传输方式下的协处理器利用率变化
Fig.2 Varying utilization rate of coprocessor in three transmission modes of DMA
3 面向密码SoC的DMA设计
3.1 DMA硬件结构
相较于传统DMA,本文DMA具有支持全双工数据读写、循环工作模式和自适应传输功能,其硬件结构如图3所示。其中,①完成全双式数据读写,②中的读写状态机采用循环工作模式,③具备自适应传输功能,④为DMA各通道的配置参数。

图3 DMA硬件结构
在图3中,由并行读写仲裁电路决定是否进行全双工读写,其控制电路如图4所示。
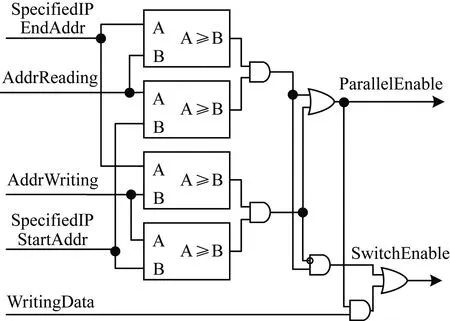
图4 并行读写仲裁控制电路
当ParallelEnable为高电平有效时,本文DMA处于全双工并行读写状态,此时由ParallelEnable和SwitchEnable信号共同决定读写引擎对片上IP和RAM的控制通路。本文DMA的循环工作模式由图3中的部分②完成。一旦通道传输完毕,读写状态机检测到该通道工作在循环模式时,会将该通道的配置寄存器AddrReading和AddrWriting重新赋值为StartAddrRead和StartAddrWrite,并且不会对通道完成标志信号Finish置位,即该通道重新配置为传输初始状态,减轻CPU对重复任务的控制负担。
自适应传输由图3中的部分③完成。由通道优先级请求电路和优先级仲裁电路共同完成通道优先级的动态调整,最终实现协处理器输入FIFO非空、输出FIFO非满。为实现该目标,本文DMA使用通道优先级请求电路生成通道的提权请求信号Priority_Higher。同时,为了保证循环模式下的数据一致性,该模块生成了通道的挂起请求信号Priority_Suspend,例如,当发生数据覆盖或读取未准备好的数据时,当前通道传输应当挂起。通道优先级请求信号生成关系如表2所示。优先级仲裁电路会根据通道的挂起、提权信号选定每个通道当前优先级,通过仲裁实时得到优先级最高的通道,并通知读写状态机将总线授权给该通道以进行读写。

表2 各通道的动态优先级
3.2 DMA工作流程
本文DMA工作流程如图5所示。

图5 DMA工作流程
在DMA传输配置阶段需要对使用专用接口的特定模块地址范围、各个通道的传输参数以及工作模式进行配置。在DMA传输开始后,首先检测当前传输通道的源或目的地址是否包含在专用接口的地址范围内,如果是,则使用AHB总线和专用通道并行读写数据,高效实现数据搬移,此时m=1;否则,DMA将定长大小的数据块读入FIFO后写至目的地址,流水执行数据的读取和返回,此时m=2。优先级仲裁器接收到通道传输状态反馈后进行通道优先级动态调整,实现面向QoS的自适应传输:当通道提权信号有效时,通道提升到预配置的高优先级;当挂起信号有效时,当前通道传输挂起,由次优先级通道进行传输或进入等待状态;通道的提权和挂起信号均无效时则优先级不变。
图6所示为面向QoS的自适应传输示例。自适应传输允许优先级较高的通道挂起优先级较低的通道传输(如Task1~Task3),而传统DMA不允许通道传输被打断,导致当前传输通道优先级可能不是最高。同时,本文DMA自适应传输优先在当前最高优先级通道中准备完毕的通道中进行传输(如Task3挂起,执行Task4),并且自适应传输允许通道优先级动态变化(如Task5),从而提高传输服务质量。当工作在循环模式时,DMA通道在完成传输后自动重置传输参数,节省CPU对DMA配置、启动等的时间,高效执行重复的DMA传输任务。在不启用循环模式时,DMA完成一次传输后,通常由中断模块向CPU发起中断报告传输完成情况。
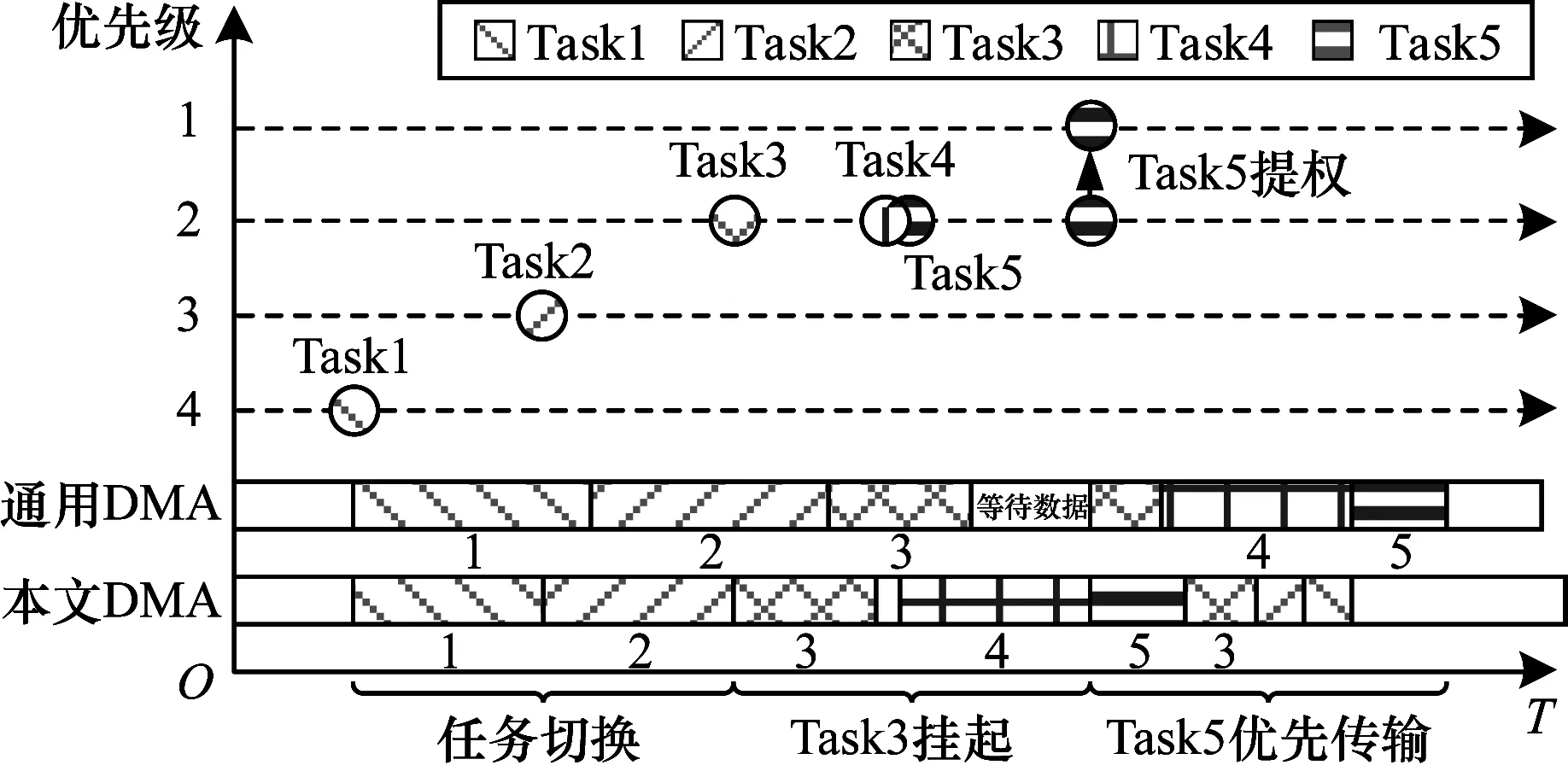
图6 面向QoS的自适应传输示例
图7所示为DMA在2种模式下的传输效率对比,单实线为通用DMA与本文DMA共同操作,双虚线为通用DMA完成一次通道传输后返回和重新配置操作。从图7可以看出,DMA工作在循环模式时无需CPU参与,提高了总线带宽利用率β和SoC应用的灵活性。

图7 循环模式传输效率优化效果
Fig.7 Effect of transmission efficiency optimization in the cyclic mode
4 实验评估
为对本文DMA进行有效评估,将其与文献[12-14]中的DMA以及由Design Ware2018生成的DMA进行对比分析,结果如表3所示。
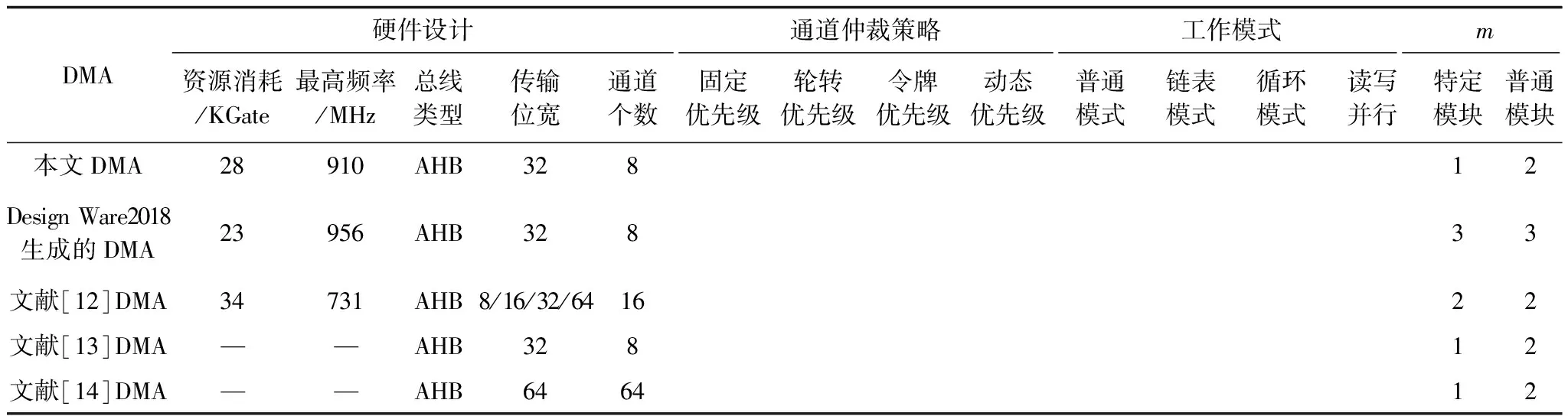
表3 DMA的性能对比分析
在表3中,本文DMA采用Verilog HDL硬件语言实现,并基于55 nm工艺对设计进行逻辑综合。最高频率是指将DMA设计的频率从原工艺等效至55 nm下所得到的大致工作频率,表示支持该功能,—表示文中未给出。由表3可知,本文DMA消耗资源适中,频率较高,在通道个数、传输位宽上相对文献[12]与文献[14]DMA较少。虽然本文DMA相对Design Ware2018生成的DMA仲裁策略不足,但其在工作模式和读写并行上功能完善,对密码应用的支持性更好。
当对外提供密码服务且时钟频率为400 MHz时,传输分片长度LB对通用DMA与本文DMA的数据传输速度及总线带宽利用率β的影响如图8所示。其中,通用DMA带宽利用率变化曲线与式(6)吻合,而本文DMA因后续通道传输没有配置、启动等时间,导致传输效率几乎不随LB变化。本文DMA使用专用接口进行并发读写源、目的地址,VDMA_i可达11.6 Gb/s,而通用DMA只能进行数据的逐个读取写入,VDMA_i仅为3.4 Gb/s。

图8 400 MHz下DMA传输效率随LB的变化情况
Fig.8 DMA transmission efficiency changing withLBat 400 MHz
表4所示为本文DMA对对称密码服务的性能优化情况。从表4可以看出,相对通用DMA,应用本文DMA后带宽利用率平均值由28%上升至91%,协处理器利用率平均值由25%上升至54%,密码算法ZUC、SNOW、SM3、SM4和AES的性能分别提升了216%、222%、123%、69%和221%。

表4 DMA传输下对称密码算法实验结果
5 结束语
本文对密码SoC中基于AHB总线的DMA传输进行优化,为特定模块开辟专用接口实现并行读写,使用循环模式和动态优先级技术完成DMA通道的高效传输,从而解决通用DMA使用AHB总线时带宽利用率低的问题,提高密码SoC的整体性能。实验结果表明,相对通用DMA,本文DMA的协处理器利用率与带宽利用率均较高。然而本文DMA还存在不支持描述符配置和仅支持AHB总线接口等不足,探究并解决该问题将是下一步的研究方向。
猜你喜欢
中国煤炭(2020年2期)2020-01-21
电脑报(2019年11期)2019-09-10
中国化肥信息(2019年6期)2019-01-19
消费导刊(2017年24期)2018-01-31
中兴通讯技术(2016年3期)2016-06-22
中国学术期刊文摘(2016年3期)2016-02-14
印制电路信息(2015年6期)2015-12-30
移动通信(2015年15期)2015-12-26
科技与创新(2014年4期)2014-05-19
现代电子技术(2014年7期)2014-04-18
