
基于GPU的LDPC增强准最大似然译码器并行实现
2020-05-18 11:07孔飞跃蒋学芹万雪芬陈思井
计算机工程 2020年5期
孔飞跃,蒋学芹,万雪芬,陈思井,崔 剑,杨 义
(1.东华大学 信息科学与技术学院,上海 201620; 2.华北科技学院 a.河北省物联网监控工程技术研究中心; b.计算机学院,河北 廊坊 065201; 3.武汉船舶通信研究所,武汉 430205; 4.北京航空航天大学 网络空间安全学院,北京 100083)
0 概述
低密度奇偶校验(Low Density Parity Check,LDPC)码是一种线性分组码,其纠错能力可以接近香农极限。LDPC码校验矩阵构造灵活、时延小,低密度性使其译码复杂度低,且译码方式可用并行操作实现。在许多工业协议中都采用了LDPC码,如DVB-S2、DVB-T2、WiFi(802.11n)、WiMAX(802.16e)和5G移动通信系统。
由于5G移动通信系统标准中要求更高的吞吐量,因此针对LDPC译码器提出专用集成电路(Application Specific Integrated Circuit,ASIC)[1]和现场可编程门阵列(Field Programmable Gate Array,FPGA)实现方案[2-3],但是,这些方案的设计成本较高且功能单一。近年来,GPU因高计算能力得到广泛应用,如文献[4-5]将GPU分别用在H-Storm平台和视频加速解码上,因为其可以同时执行多个线程,峰值达到每秒万亿次浮点运算的处理能力。与ASIC和FPGA方案相比,基于GPU的解决方案更便捷,可扩展性和灵活性也更好。基于GPU的LDPC译码器实现已经取得较大进展。文献[6-7]在GPU平台上采用压缩基矩阵的方式,设计一种大规模并行译码方案。文献[8-9]在GPU上实现了LDPC卷积码译码器。文献[10-11]提出压缩奇偶校验矩阵,并充分利用共享内存提高译码速度。文献[12-13]在GPU上实现了收敛速度更快的分层调度LDPC码译码算法。文献[14]根据规则LDPC码Tanner图中的边,提出一种边并行译码方案,以最大化利用GPU内的线程。文献[15]在GPU上实现了连续变量的量子秘钥分发方案。文献[16]在GPU上实现了非二进制LDPC码的译码器。
为降低译码器的误帧率(Frame Error Rate,FER),一些研究者提出在传统置信传播(Belief Propagation,BP)译码算法译码失败后引入再处理过程,按照相关规则对输入的码字选出一些点进行饱和处理,对饱和处理后的码字序列重新进行BP译码,这样能大幅提高译码器的纠错性能[17-19]。文献[19]提出增强准最大似然(Enhanced Quasi-Maximum Likelihood,EQML)LDPC译码器,利用更准确的节点选择方法和合理的译码停止规则提高了纠错性能,但其译码速度却大幅下降。
针对译码器译码速度下降的问题,本文基于GPU平台,利用LDPC奇偶校验矩阵压缩存储、核函数BP算法译码重排、再处理过程多码字并行译码、内存访问优化及流并行译码方案,设计针对EQML译码器的并行化实现方案,在保持译码器的纠错性能的同时提高译码速度。
1 基于LDPC码的EQML译码算法
当LDPC码长较长时,若校验矩阵中没有短环,则BP译码算法中节点输出的消息可以成功收敛。然而,当码长较短时,校验矩阵存在大量的短环,短环中的各节点在迭代过程中具有相关性,消息在迭代过程中变得不可靠,所以短环的存在会造成译码性能的急剧下降。为解决短环导致的性能损失,文献[17]提出一种准最大似然(Quasi-Maximum Likelihood,QML)译码器。文献[19]提出的EQML译码器能够在0.3 dB的FER范围内达到接近最大似然(Maximum Likelihood,ML)的译码性能。
基于LDPC的QML译码器的译码过程具体为:1)对输入的码字进行BP迭代译码,如果译码成功,则继续下一个码字,反之执行再处理过程;2)对译码失败的码字进行节点选择,选出最不可靠的节点进行饱和处理,对饱和处理后的码字序列再次进行BP迭代译码,直至到达最大阶段数,最终选出最优码字输出,QML译码器的整体流程如图1所示。
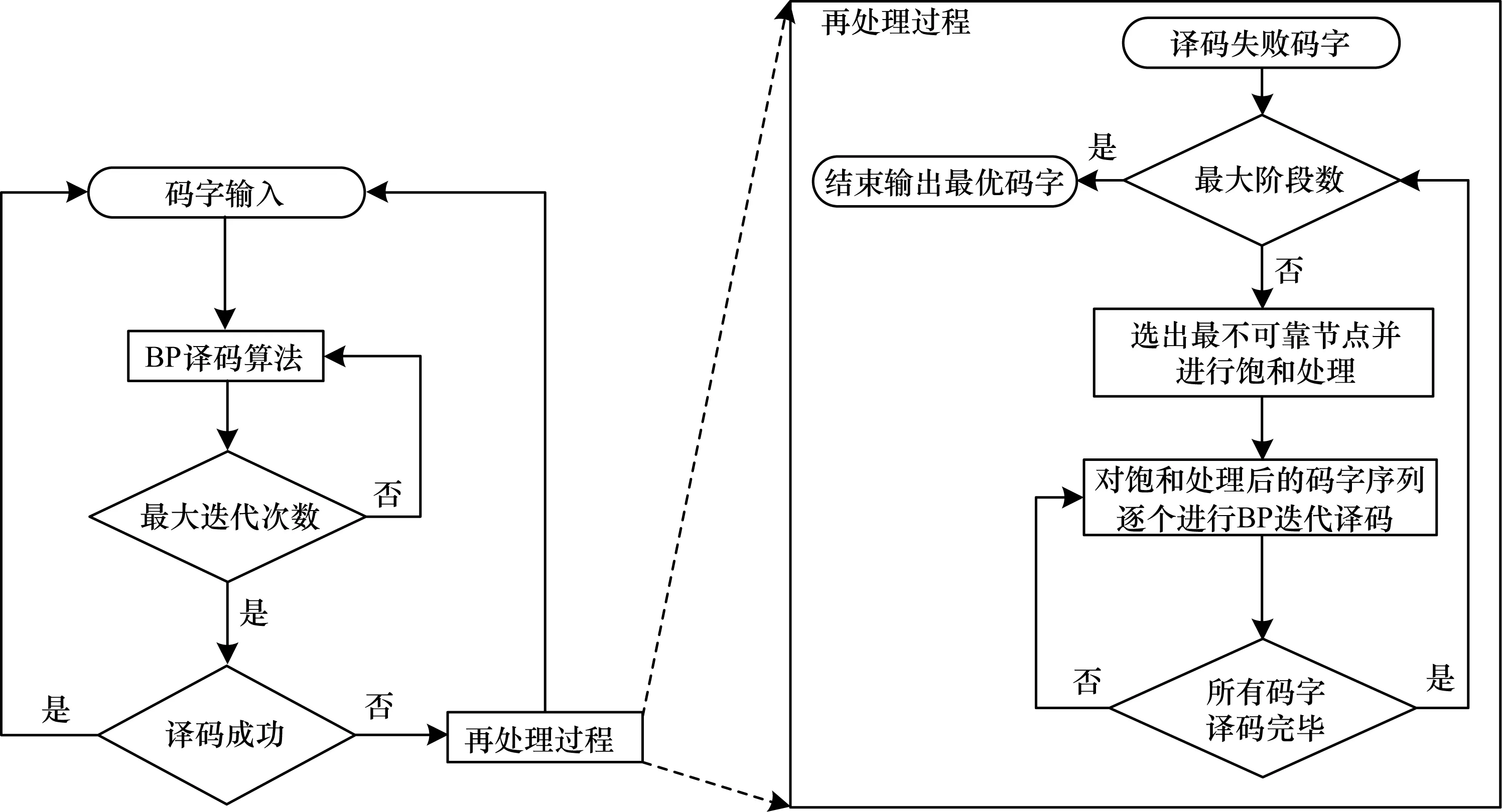
图1 QML译码器的整体流程
判断QML译码器是否具有较好的译码性能的关键在于提出的节点选择算法能否选择出最不可靠的节点。文献[19]的创新在于提出一种更加准确的变量节点选择算法,即边选择(Edge-Wise Selection,EWS)算法,同时为降低译码延迟,利用部分剪枝停止(Partial Pruning Stopping,PPS)算法在译码延迟和误码率性能之间取得了较好的平衡。
1.1 基于LDPC码的BP译码算法
BP译码算法在对数似然比域上进行运算,其中,变量节点用VN表示,校验节点用CN表示。BP译码算法的具体步骤如下:
1)初始化。计算信道传递给VN的初始概率似然比信息r(vi)(i=1,2,…,n),对于VNi及其相邻的CNj∈Ci,经过二进制相移键控(Binary Phase Shift Keying,BPSK)调制后在高斯白噪声(Additive White Gaussian Noise,AWGN)信道中得到VN传递给CN的初始信息为:
(1)
2)CN信息更新。对所有的CNj及其相邻的VNi∈Rj,CN信息的计算公式为:
(2)
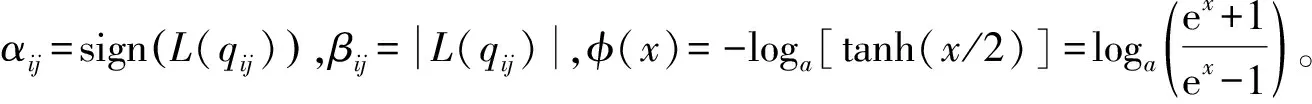
3)VN信息更新。对所有的VNi及其相邻的CNj∈Ci,VN信息的计算公式为:
(3)
4)判决译码。对所有的VN计算判决信息:
(4)
(5)
for t1=0:M do
for t2=0:rowdegree[t1]-1 do
tm p=0
for t3=0:rowdegree[t1]-1 do
if t2=t3then
continue
end if
tmp=tmp+φ(t3)
end for
end for
end for
分步计算译码方案时间复杂度的伪代码具体如下:
for t1=0:M do
tm p=0
for t2=0:rowdegree[t1]-1 do
tmp=tmp+φ(t2)
end for
end for
for t1=0:M do
for t2=0:rowdegree[t1]-1 do
tmp=tmp+φ(t2)
end for
end for
1.2 再处理过程
1.2.1 EWS算法
EWS算法的基本思想是计算Tanner图上每条边上VN传给CN的信息正负号变换次数,最后将与每个VN相连的CN信息变换次数相加,从所有VN中选出信息变换次数最大的VN组成集合,从集合中选出所对应r(vi)绝对值为最小值的点,利用一个预设的饱和值±α代替原有信息,重新进行译码。
使用wl,i表示VNi传递到与其相连的第l个CN的消息的正负号翻转次数;d(vi)表示VNi的度,即校验矩阵第i列非零元素的个数;w(vi)表示VNi的消息正负号翻转总次数,计算如下:
(6)
EWS算法伪代码如下:
For each VNi,compute w(vi) according to equation(6)
if vs∉∅ then
Select the VN with the smallest a posterior probability among vs
end if
1.2.2 部分剪枝停止算法
文献[19]在不影响FER的情况下,提出一种PPS规则有效终止再处理过程。TA表示第TA个译码的码字,x(TA)表示第TA个码字的判决输出,χ表示收敛码字集合;TF表示剩余要进行译码的码字,jmax表示再处理过程的最大阶段数,jc表示当前再处理阶段,初始化TF=2jmax+1-2。PPS算法伪代码如下:
if converge after TAtests then
Save valid codeword x(TA)in χ//存储收敛的码字
TF=TF-2jmax+1
Terminate the decoding on sub-branches thereafter//剪枝操作
else
Continue the decoding on non-convergent sub-branches
end if
if jc=jmaxor TF=0 then//当预设最大阶段或所有的分支//都收敛时停止译码
Terminate reprocessing procedure
end if
再处理过程的树形流程如图2所示,输入译码失败后的码字进行EWS,并对选出的节点进行饱和处理,重新进行译码。当TA=1时,即第一个饱和后需进行译码的码字,译码成功进行PPS操作;当TA=2时,饱和后的码字译码不成功,再次进行EWS,重复以上步骤,直至到达预设的阶段数或所有的码字都收敛。
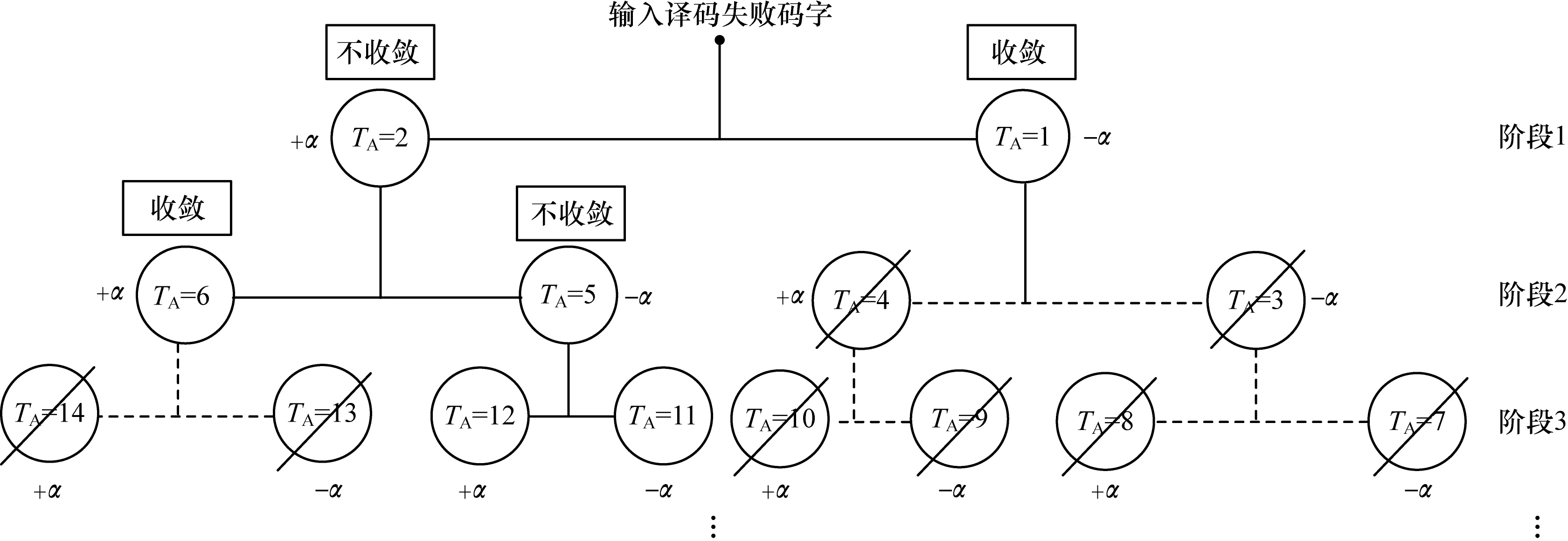
图2 再处理过程的树形流程
2 基于GPU的EQML译码器并行化计算
LDPC码的校验矩阵是一种稀疏矩阵,含有大量的“0”元素和少量的“1”元素,针对“0”元素无用问题,本文提出一种压缩存储LDPC码的校验方案,对提高译码速度非常重要。CN更新过程存在计算复杂度过高的问题,根据GPU并行特性提出一种BP算法重排方案,即使用大量线程并行、中间值计算和访存合并相结合的译码方案来提高译码速度。根据再处理过程中每个阶段都有大量码字需要译码的问题,在GPU上采用多码字并行译码方案。利用GPU内不同储存器访问速度不同的特性,采用带宽更大的储存器及流并行机制来提高访存速度。
2.1 适用于GPU的奇偶校验矩阵压缩存储方法
文献[15]提出利用链表储存奇偶校验矩阵,需要建立大量的表结构,较复杂且占用内存。文献[6-7]提出的存储基矩阵方法,需解决算法映射问题,实现较复杂。文献[10]仅给出了规则LDPC码的校验矩阵存储方案。本文在文献[10]基础上,给出一种不规则LDPC码的校验矩阵存储方案,通过7个一维数组表示校验矩阵:rowdegree,coldegree,rowsum,colsum,colnum,V2C,C2V。存储7个一维数组的方式如图3所示。rowdegree、coldegree分别储存CN的行度和VN的列度。colnum、rowsum和colsum分别代表校验矩阵中每个非零元素按列顺序排列所在的列,按行顺序排列到本行时所有非零元素的总数和按列顺序排列到本列时所有非零元素的总数,V2C和C2V分别代表按顺序储存校验节点的边及其与VN相连的CN编号。

图3 Tanner图上稀疏矩阵转化为一维数组的过程
2.2 EQML译码算法的GPU实现
2.2.1 GPU Kernel内线程排布
Tanner图中CN和VN之间高度不规则的连接结构,使得在GPU上实现EQML译码器时不能同时在内存中对连续数据进行读写操作。因为执行无序的内存读或写操作需要处理多个事务,所以此时所有Kernel内的线程都必须停止等待。相反地,对连续内存位置的访问可以在单个事务中执行并允许并发线程执行,从而减少Kernel的运行时间。此外,对无序的内存进行写操作比对无序的内存进行读操作需要更多的执行时间[20]。因此,本文对BP译码算法重新排序以避免未合并的内存写操作,并使用最大数量的线程级并行计算。

图4 BP译码算法的GPU实现
基于GPU的BP迭代译码并行化算法具体如下:
1)初始化。通过式(7)进行初始化,上标0代表迭代次数,L(Qi)和r(vi)为一个长度为N的数组,用于储存译码判决消息和初始概率似然比信息。
L(Qi)0=r(vi)=2yi/σ2
(7)
2)Kernel 1 VN更新。L(rji)是一个长度为T的数组,用来储存初始化为0的CN更新消息。在Kernel 1中,通过式(8)计算VN更新消息:
L(qij)k=L(Q[colnum[Idx]])k-1-L(rji)k-1
(8)
其中,k=1→Imax,Imax为BP译码的最大迭代次数,L(qij)为一个长度为T的数组,用于储存VN更新信息,Idx为Kernel中的线程索引,Kernel 1中Idx=0→T-1。
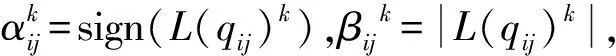
通过式(9)对比前后两次信息计算EWS算法中的wl,i,Tsign为一个长度为T的数组用于存储wl,i的数值。
(9)
3)Kernel 2中间值更新。通过式(10)计算CN更新的中间值:
devM[Idx]=devM[Idx]+
φ(V2C[rowsum[Idx]+t])
(10)
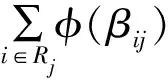
4)Kernel 3 CN更新。通过式(11)计算CN更新,Kernel 3中Idx=0→T-1。
L(rji)k=φ(devM[C2V[Idx]]-φ(Idx))
(11)
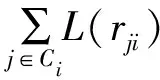
devN[Idx]=devN[Idx]+
L(r[colsum[Idx]+t)k
(12)
L(Qi)k=r(vi)+devN[Idx]
(13)
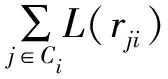
在达到最大迭代次数时通过式(14)计算出w(vi),Nsign是一个长度为N的数组,用于储存w(vi)的值。
Nsign[Idx]=Nsign[Idx]+Tsign[colsum[Idx]+t]
(14)
通过Kernel 4计算出L(Qi)及w(vi),在到达最大迭代次数后将w(vi)及判决结果从GPU读到CPU内存中cudaMemcpy(h_Nsign,Nsign,N×sizeof(int),cudaMemcpyDeviceToHost)。
2.2.2 再处理过程中的多码字并行译码
为提高Kernel中线程的利用率并充分利用再处理过程的可并行译码特性,采用多码字并行译码方案,即将每个阶段生成的码字序列同时译码。假设需要Kernel提供N个线程来译码单个码字,如果有Ncodeword个码字需要进行译码,将Ncodeword个码字合并,采用N×Ncodeword个线程对这些码字进行并行译码。译码器阶段与阶段之间采用串行方式,阶段内的所有码字采用并行译码,具体方案如图5所示。
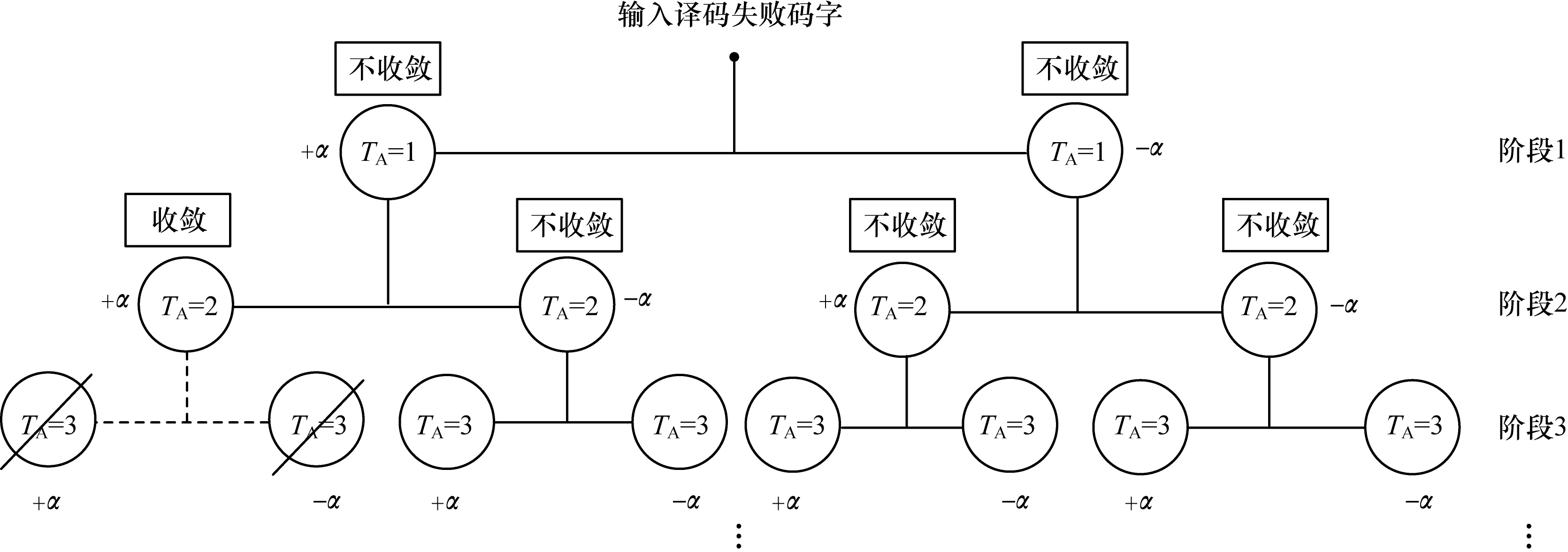
图5 再处理阶段中的多码字并行译码方案
在图5中,每个TA代表一个需要译码的码字,TA=1的码字有两个,代表第一阶段要并行译码的码字有两个。同理,第二阶段有4个,第三阶段有6个。与CPU相比,其通过并行方式对单个码字进行译码,节省了大量译码时间。
2.3 GPU内存访问数据优化
由于warp是GPU中调度和运行的基本单元,因此每个warp包含32个线程。当对常量内存进行读取时,GPU将单次读操作广播到每个半线程束(half-warp),即线程束中线程数量的一半。如果在半线程束中的每个线程从常量内存的相同地址上读取数据,那么GPU只会产生一次读取请求并在之后将数据广播到每个线程,该方式的理论速度可达到使用全局内存时的16倍。共享内存是GPU内位于每个流处理器中的高速内存空间,主要作用是存放线程块中所有线程均会频繁访问的数据。GPU上储存器的带宽参数如表1[21]所示。

表1 GPU储存器带宽
为提高译码速度,将频繁读写的局部变量使用高带宽的共享内存存储,使代表校验矩阵的7个一维数组存储在只读存储器常量内存中,因为这几个数组中储存的数据只需进行读操作,无需对数组中的数据进行修改,可以有效减少存储器事务的处理时间。共享内存和常量内存的具体使用方法如下:
__shared__double RCache[];//申请使用共享内存存储//Kernel中重复访问的局部变量
__device__ __constant__ int V2C[T];//申请常量内存用//于存储V2C数组
cudaMemcpyToSymbol(V2C,h_V2C,T*sizeof(int));//使用内置函数将数组从CPU内存拷贝到GPU常量内存中
2.4 GPU流并行机制
EQML译码器在GPU平台上运行所消耗的时间中,除去核函数执行时间外,其余大部分时间是用于CPU与GPU之间通过PCI-E总线传输码字信息和硬判决输出信息。因此,可以引入CUDA流机制,在提升Kernel自身执行效率的同时,优化数据传输和译码内核函数之间的调度机制。通过CUDA流可以实现多帧译码数据传输和执行Kernel函数之间的交叠执行,如图6所示,其中H2D和D2H分别表示码字信息数据从CPU传输到GPU和判决信息从GPU传输到CPU的传输过程,能够降低在PCI-E总线数据传输时的空闲等待时间。流并行的具体算法如下:
cudaStream_t stream;
cudaStreamCreate(& stream);//流初始化
cudaHostAlloc((void**)& lratio,N * sizeof(double),cudaHostAllocDefault);//对流使用的页锁定内存进行分配
cudaMemcpyAsync(dev_lratio,lratio,N * sizeof(double),cudaMemcpyHostToDevice,stream);//将数据复制到GPU上

图6 流并行机制
3 实验结果与分析
EQML译码器的运行环境为GTX 1060 GPU,在英伟达CUDA 8工具包下进行编译,编译环境是Visual Studio2017,Windows10 64位操作系统。实验选取的LDPC码为802.16e标准码率为0.5、码长为2 304与576的LDPC码。
为比较EQML译码器在GPU上实现的FER性能,应用码长为576的LDPC码在jmax分别为1、2、3、4和5时进行译码仿真,同时对传统BP译码器及文献[16]提出的ABP译码器进行仿真,仿真结果如图7所示。可以看出,EQML译码器能够提供比BP译码器和ABP译码器更好的纠错能力,其与5G移动通信系统安全性、可靠性、稳定性的要求相一致,所以通过EQML译码器进行并行化提升译码速度非常必要。

图7 EQML译码器与BP译码器和ABP译码器的FER性能对比
Fig.7 Comparison of FER performance of EQML decoder,BP decoder and ABP decoder
文献[5]提出一种常见的压缩基矩阵存储方案,因为作者在其github上公布了源码,所以本文将压缩基矩阵与压缩奇偶校验矩阵的实现方案进行仿真。仿真条件为信噪比1.0 dB,固定迭代30次。为使仿真结果更公平,防止因计算平台造成误差影响实验结果,这两种方案都是在GTX1060 GPU上应用码长为2 304的LDPC码进行仿真。由于文献[6]中使用MSA译码算法,为方便对比本文也采用MSA算法,结果如表2所示。由此可知,采用压缩奇偶校验矩阵比采用压缩基矩阵的存储方案具有更快的译码速度。压缩奇偶校验矩阵存储方案能提高1.45倍的译码速度。
表2 校验矩阵存储方案的译码时间比较
Table 2 Comparison of decoding time of check matrix storage schemes s

方案译码时间CPU存储方案784.54压缩基矩阵存储方案20.29压缩奇偶校验矩阵存储方案13.92
为对比本文提出的BP算法重排方案的加速效果,对传统BP译码与重排后的BP译码方案在码长为2 304的LDPC码下进行对比。通过表3中数据可知,重排后译码速度比传统BP译码算法提升了1.68倍,证明了BP算法重排后的译码优势。
表3 BP重排译码方案与传统BP译码方案的译码时间比较
Table 3 Comparison of decoding time of BP rearrangement decoding scheme and traditional BP decoding scheme s

方案译码时间CPU译码方案845.35传统BP译码方案39.39BP重排译码方案23.41
EQML译码器采用经BP算法重排后的译码方案。为对比不同jmax下基于GPU与CPU实现的EQML译码器所需的译码时间,对码长为576的LDPC码进行仿真,仿真结果如表4所示。
表4 不同jmax下的译码时间比较
Table 4 Comparison of decoding time at differentjmaxs

Jmax值译码时间CPUGPU1380.7119.952788.9130.2631508.7541.0342870.9660.1656481.63100.46
图8表示不同jmax下基于GPU实现的EQML译码器的加速倍数,由此可知,EQML译码器随着jmax的增加,加速倍数也在增加,所以基于GPU译码方案的优势在jmax取较大值时加速效果将更加明显。当jmax取5时,速度提升了约64倍,显示了基于GPU的译码方案的性能优势。
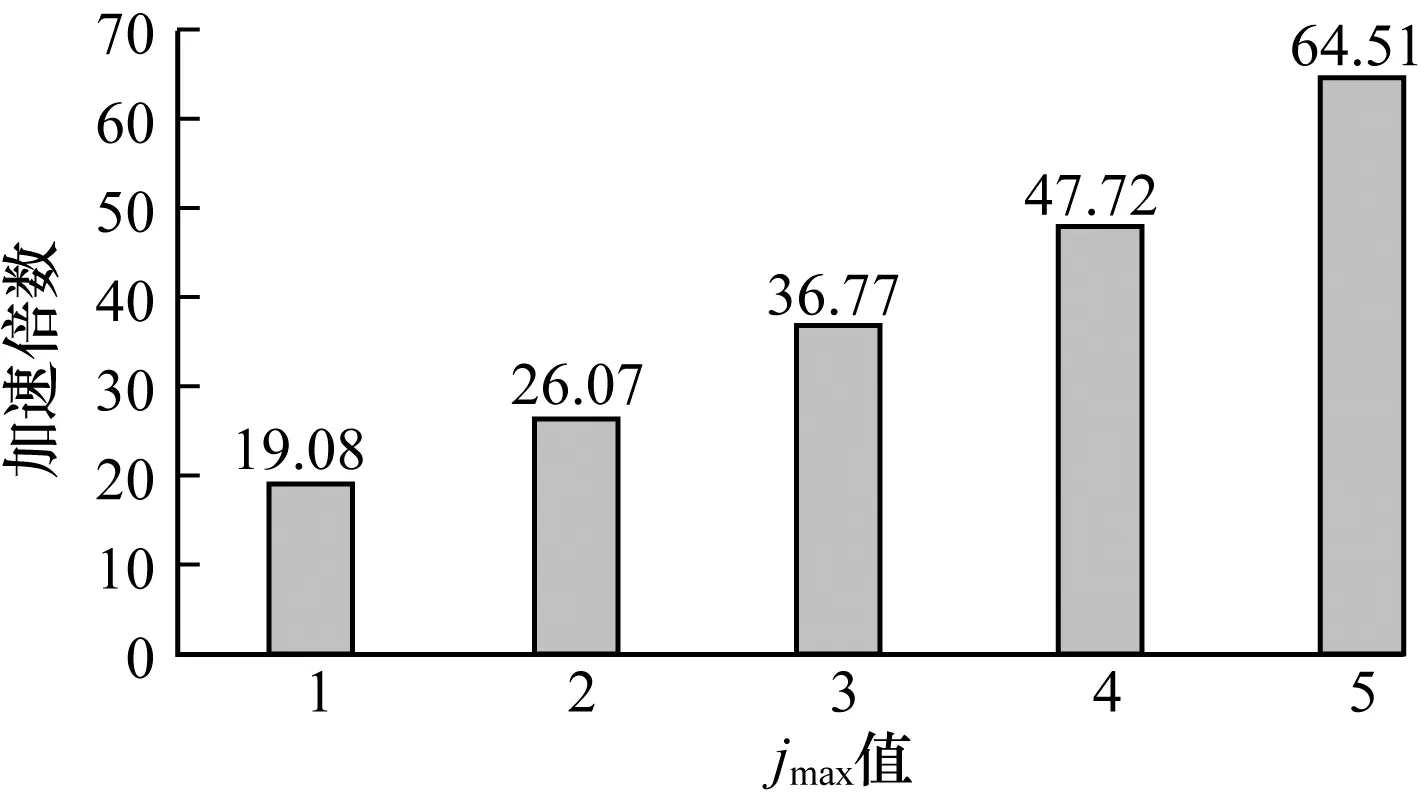
图8 基于GPU的EQML译码器在不同jmax下的加速倍数
Fig.8 Speedup of GPU-based EQML decoder at differentjmax
为比较译码器在不同信噪比下的译码速度,以码长为576的LDPC码为研究对象,设置jmax为3,分别在不同信噪比下对EQML译码器在CPU和GPU上所需的译码时间进行仿真,仿真结果如表5所示。
表5 不同信噪比下的译码时间比较1
Table 5 Comparison of decoding time at different signal to noise ratio 1 s
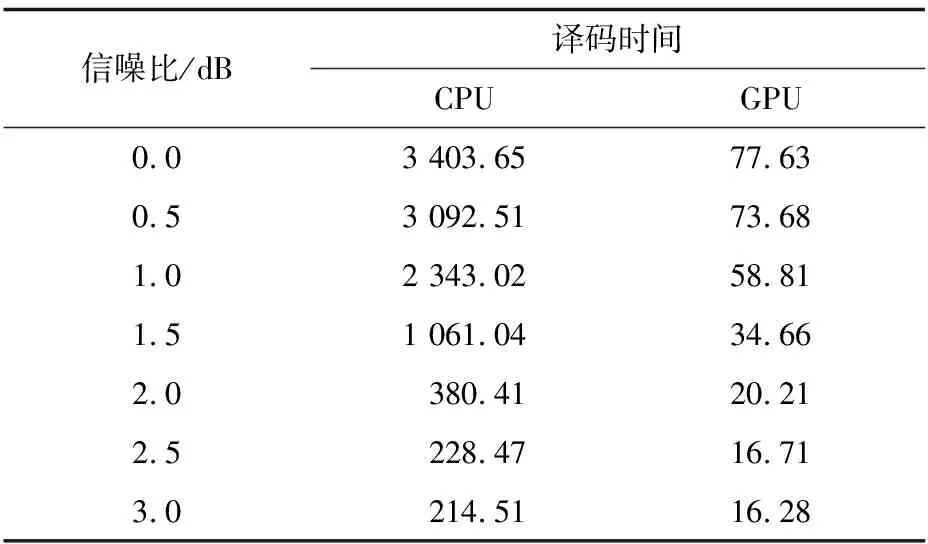
信噪比/dB译码时间CPUGPU0.03403.6577.630.53092.5173.681.02343.0258.811.51061.0434.662.0380.4120.212.5228.4716.713.0214.5116.28
图9表示在不同信噪比下的加速倍数,由此可知在信噪比较低的情况下加速倍数较高,因为EQML译码器在信噪比低时译码成功率低,再处理过程启动频繁,所以译码时间增加。在信噪比较高的情况下,译码成功率高,再处理过程启动次数、译码时间、加速倍数均降低。

图9 基于GPU的EQML译码器在不同信噪比下的加速倍数1
Fig.9 Speedup of GPU-based EQML decoder at different signal to noise ratio 1
为对比不同码长对基于GPU的译码器的影响,在相同情况下对码长为2 304的LDPC码进行仿真,仿真结果如表6所示。
表6 不同信噪比下的译码时间比较2
Table 6 Comparison of decoding time at different signal to noise ratio 2 s
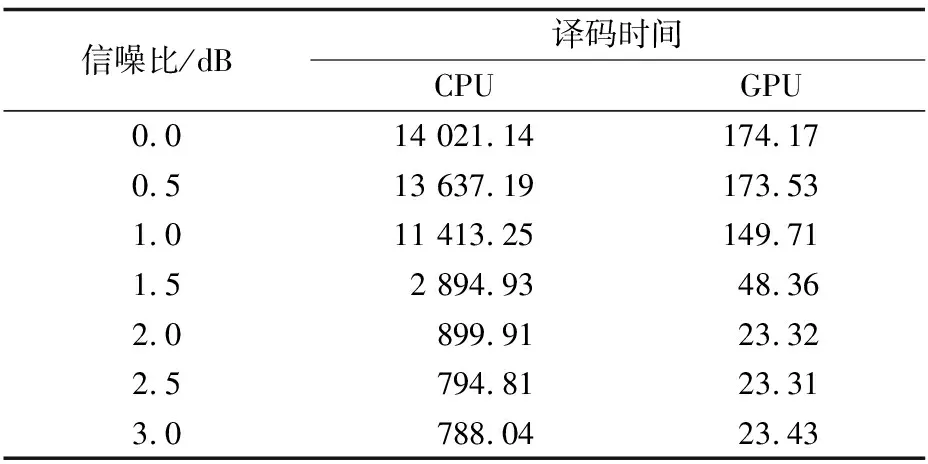
信噪比/dB译码时间CPUGPU0.014021.14174.170.513637.19173.531.011413.25149.711.52894.9348.362.0899.9123.322.5794.8123.313.0788.0423.43
图10表示码长为2 304时不同信噪比下的GPU译码方案的加速倍数,当信噪比为0时加速倍数达到80倍,大幅节省了译码时间。与图9相比可知,码字越长获得的加速倍数越大,因为当码字较长时GPU可以利用Kernel内的线程优势,使用更大量的线程译码提高译码速度,所以当码字很长时,采用GPU译码方案的优势将会更加明显。
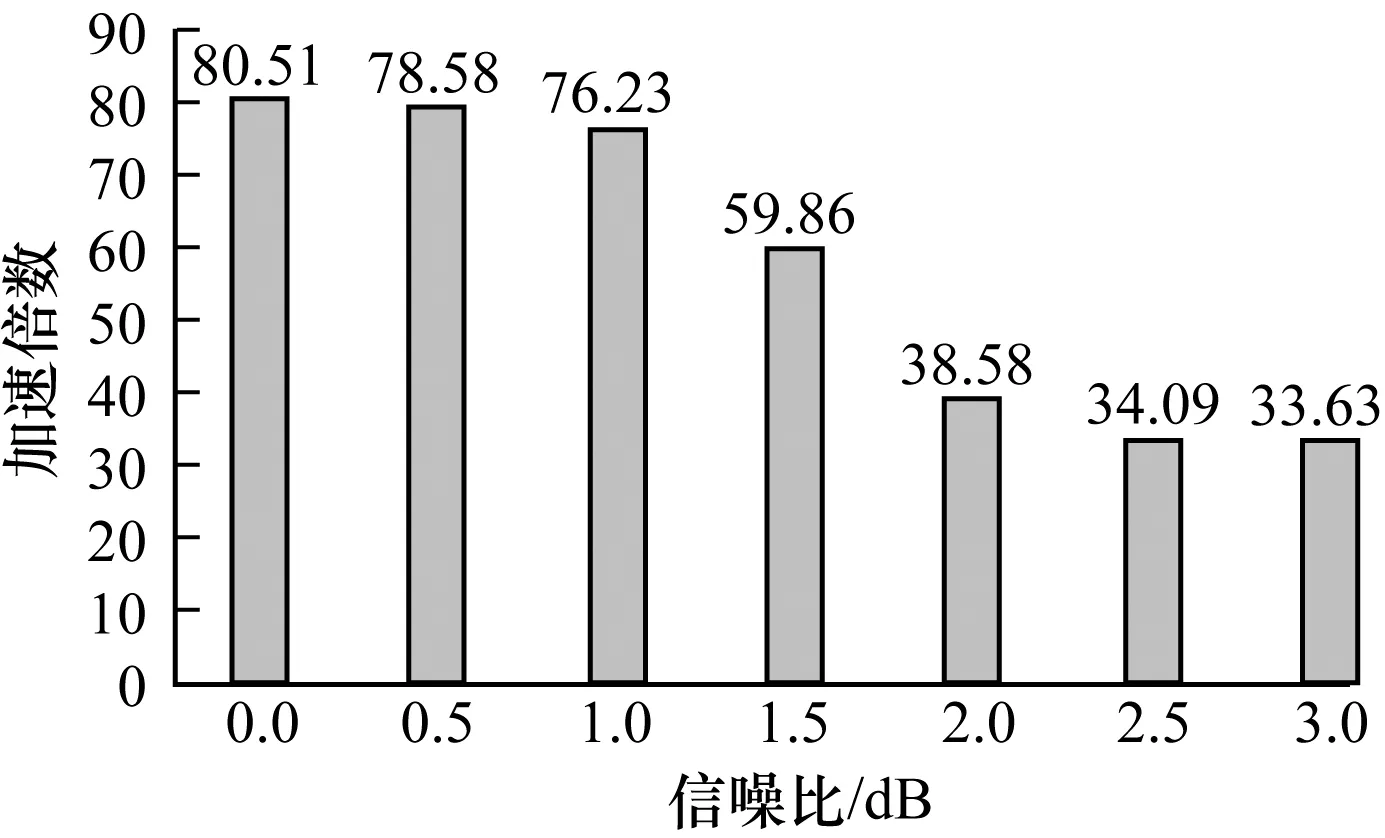
图10 基于GPU的EQML译码器在不同信噪比下的加速倍数2
Fig.10 Speedup of GPU-based EQML decoder at different signal to noise ratio 2
4 结束语
5G移动通信系统要求在确保低成本及传输安全性、可靠性、稳定性的前提下,能够提供更高的数据传输速率、更多的服务连接数和更好的用户体验。EQML译码器可以消除大量导致BP译码器不收敛的伪码字,实现更加可靠的通信,但是EQML译码器是以牺牲译码速度来换取译码性能,因此本文设计一种基于GPU的EQML译码器来提升EQML译码器的译码速度。针对不规则LDPC码,提出压缩校验矩阵存储方案,使用共享内存和常量内存分别储存频繁访问的局部变量和只读数据,在Kernel中对BP译码算法进行重新排序,并采用每阶段多码字并行译码方案,提高EQML译码器再处理过程的可并行性。实验以802.16e WiMax LDPC码为例对基于GPU的EQML译码器性能进行验证,结果表明EQML译码器在GPU上的并行实现较在CPU上的串行实现译码速度有了较大提升,当码长为2 304码字且信噪比较低时的最大加速倍数可达80倍,证明了GPU技术在并行译码中的可行性和有效性。
猜你喜欢
沈阳工业大学学报(2021年6期)2021-11-29
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
西北工业大学学报(2019年2期)2019-05-15
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
扬子江(2018年1期)2018-01-26
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
遥测遥控(2015年2期)2015-04-23
