
基于姿态引导对齐网络的局部行人再识别
2020-05-18 11:08赵杰煜
计算机工程 2020年5期
郑 烨,赵杰煜,王 翀,张 毅
(宁波大学 信息科学与工程学院,浙江 宁波 315000)
0 概述
目标行人从一个相机视域离开,然后在另一个不重叠的相机视域中再次被识别,这一过程在计算机视觉领域称为行人再识别(Re-ID),其是实现多摄像头跟踪的前提条件,在现实生活中得到广泛应用。目前,对于行人再识别的研究主要集中于整体图像的研究,但在现实场景中,由于遮挡等原因拍摄到的图像不都是完整的图像,也可能存在只有部分身体的局部图像,因此需对局部行人再识别作进一步研究。
深度卷积神经网络(Deep Convolutional Neural Network,DCNN)模型通常会将图像缩放到固定大小作为输入,而尺寸相同的局部图像与整体图像会存在严重的不匹配问题并对特征匹配产生影响。相比而言,预对齐的局部行人图像更适合与整体图像进行匹配。本文提出姿态引导对齐网络(Pose-Guided Alignment Network,PGAN)模型,将人体先验知识引入到对齐网络中,使用空间变换生成与标准姿势对齐的行人图像,并在训练阶段利用姿势信息学习空间变换器的对齐参数。
1 相关工作
1.1 行人再识别
表征学习被应用于行人识别中以学习人的外貌特征。文献[1-2]使用卷积神经网络(Convolutional Neural Network,CNN)学习全局特征。文献[3-4]将图像分为多个部分提取可区分的局部特征,通过图像水平分割可有效提取变化较少的局部特征。图片切块是一种常见的局部特征提取方式,但其缺点在于对图像对齐的要求较高,如果两幅图像没有上下对齐,那么很可能出现头和上身不对齐的现象,反而使得模型判断错误。行人身体的不匹配问题将严重影响不同图像之间的特征匹配。为应对图像不对齐问题,研究人员将空间变换网络(Spatial Transformation Network,STN)引入到再识别模型中对行人图片进行空间变换对齐行人,还有研究人员将人体解析[5]、姿态估计方法等作为先验知识引入到Re-ID模型中对行人图像进行对齐。
1.1.1 基于空间变换的行人再识别
STN[6]是一个空间变换模块,可以引入神经网络以提供空间变换功能,包括平移、缩放、旋转等。STN是一个小型网络,可以进行标准的反向传播和端到端训练,而不会显着增加训练过程的复杂性。STN由定位网、网格生成器和采样器组成,定位网获取输入的特征图并输出变换参数,网格生成器计算每个输出像素的原始图像中的位置坐标,采样器生成采样的输出图像。
文献[7]提出一种多尺度上下文感知网络(MSCAN),通过将STN与定位损失相结合来提取可变的身体部位,从而减少背景影响并在一定程度上将行人图像对齐,但是定位损失的中心先验约束是基于图像主体完整且图像对齐的前提而提出。文献[8]提出行人对齐网络(PAN),使用STN在Re-ID深度卷积网络前对齐行人图像,但是PAN仅使用Re-ID损失对其进行训练,图像对齐效果较差。
1.1.2 基于姿态估计的行人再识别
Spindle Net[9]和GLAD[10]使用姿势估计算法预测人体关键点,然后学习每个部件的特征并组合部件级的特征以形成最终描述符,以解决姿势变化问题。姿态驱动深度卷积模型(PDC)[11]通过姿态信息裁剪身体区域,然后获得经过旋转和调整大小的身体部位用于姿势变换网络对身体部位进行归一化。文献[12]利用姿态不变特征(PIE)作为行人描述符,利用姿势估计定位关键点,将身体各部件通过仿射变化映射生成Pose Boex结构。文献[13]提出一个姿势敏感的行人Re-ID模型,将关节信息和粗略方位信息引入到卷积神经网络中学习判别特征,实验结果表明,检测到的关节位置和拍摄视角有助于学习特征。然而这些方法都将姿势估计直接嵌入到模型中,增加了计算成本和模型复杂度。
1.2 局部行人再识别
在局部行人再识别中,由于存在只有局部身体可被观测到的局部图像,局部图像与整体图像的匹配是局部行人再识别的一大难题。滑动窗口匹配(Sliding Window Matching,SWM)[14]利用与局部图像大小相同的滑动窗口来搜索每个整体图像上最相似的区域,然而局部匹配的计算代价太大。文献[15]提出一种深度空间特征重构(Deep Spatial Feature Reconstruction,DSR)方案,使用全卷积网络(Full Convolutional Network,FCN)生成具有一定大小的空间特征图,以匹配不同大小的行人图像。与SWM方案相比,DSR方案大幅减少了计算量。文献[16]提出可视性局部模型(Visibility Partial Model,VPM),通过监督学习感知区域的可见性,提取区域级特征并比较两个图像的共享区域。
2 基于PGAN的局部行人再识别
为解决遮挡和尺度变化问题,本文设计一个姿态引导对齐网络来对齐局部行人,然后学习有效的特征进行行人再识别,整体框架(如图1所示)包括以下模块:
1)姿态引导的空间变换(Pose-Guided Spatial Transformation,PST)模块,其进行训练并将整体/部分行人图像转换为对齐的行人图像。该对齐方法是基于完整或部分人体姿态,将人体骨骼作为先验知识,利用姿态估计方法提取每个行人图像的姿态信息。需要注意的是:该过程无需对每个图像进行姿态估计,而是使用一个空间变换器来学习标准姿态和给定标准姿态之间的转换参数。在无需显示姿态信息的情况下,该方法是一种非常有效的推理方法。
2)特征提取模块(ResNet)[17],其作为特征提取器的主干模块,提取行人图像的全局特征。
基于PGAN模型,局部图像可以实现与整体图像的匹配。

图1 姿态引导对齐网络框架
2.1 姿态引导的空间变换
PST模块是PGAN中的关键部分,利用姿态信息引导局部行人图像进行空间变换。具体为训练一个空间变换生成一个与目标姿态接近的对齐行人图像,根据人体骨骼关键点确定损失函数。
行人再识别通常使用二维图像作为输入,本文采用仿射变换来变换整体/部分行人图像进行对齐。在PST模块中,所有图像被转换成更接近标准姿态的图像。当原始行人图像与对应的转换图像分别表示为I、Ia,I、Ia中的像素可以进一步表示为p、pa,那么p、pa之间的仿射变换为:
pa=Rp+b
(1)
其中,R是一个与缩放、旋转相关的2×2参数矩阵,b是一个与平移相关的1×2参数向量。
由定位网络、网格生成器和采样器组成的空间转换网络[6]在PST模块中被用来进行仿射变换得到仿射变换后的图像Ia。输入为原始行人图像I,输出为θ,包含用于对齐的仿射变换参数。
(2)
其中,floc(I)表示定位网络。定位网络结构如表1所示,包括两个卷积层、两个池化层和两个全连接(FC)层,最后一个FC层生成仿射转换参数θ,用于创建网格生成器中的采样网格。

表1 定位网络结构
然后采样器从原始行人图像I中提取一组采样点,并产生采样输出Ia。从仿射图像到原始图像的逐点变换过程如下:
(3)
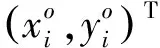
最终得到仿射变换后的图像Ia:
Ia=fSTN(I)
(4)
其中,fSTN为空间转换网络。
如果所有行人都有相同的姿势和尺度,则再识别难度会大幅下降。为获得更好的再识别性能,不同I的变换图像Ia中的行人应具有相似的姿态和尺度,但在原始的STN中,变换参数是由网络在没有任何指导的情况下进行学习得到,换言之,其不能确保转换后的图像Ia具有所需属性,例如姿态和比例。本文将关键点形式表示的标准姿态作为对齐目标,引导网络学习本文所需的变换,关键点是人体骨骼关节,如图2所示,其中包括成对对称的16个关节和单个关节,共17个关节。关键点的定义如下:
Kp={k0,k1,…,ki,…,kN}=
{(x0,y0),(x1,y1),…,(xi,yi),…,(xN,yN)}
Kvis={v0,v1,…,vi,…,vN}
(5)
其中,Kp、Kvis分别表示关键点和关键点可见性,(xi,yi)表示第i个关键点的坐标,vi表示其对应的可视分数,N表示总的关键点个数。
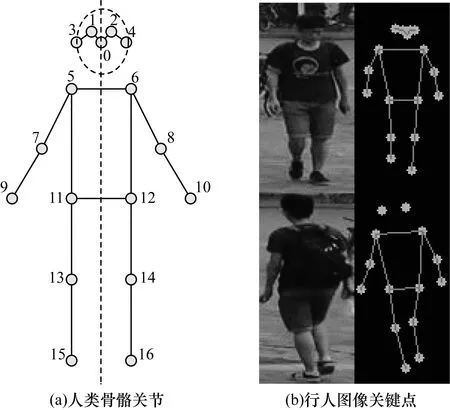
图2 行人图像骨骼关节关键点
为评价仿射变换后的图像Ia与标准图像的姿态相似性,首先通过RMPE姿态估计算法[18]提取Ia中人物的关键点P,将这些关键点P与标准姿态的目标关键点T进行匹配,得到两个姿态之间的相似性。然后将该相似性作为损失项来指导PGAN中转换参数的学习过程。需要注意的是:仿射变换在学习阶段可能会极大改变图像中人物的形状。因此,RMPE姿态估计算法可能无法检测到Ia中的关键点。此外,在模型中嵌入姿态估计会大幅增加计算复杂度,因为每个训练元中的每幅图像都需要一个姿态估计,并且该过程不能在GPU上并行执行。
由此可知,Ia的姿态信息不是直接通过姿态估计得到。实际上,变换后的图像Ia无需估计姿态关键点,可以利用输入图像I中原始关键点的坐标K和STN得到的变换参数θ计算得到,并且原始关键点只需在数据准备阶段使用一次RMPE姿态估计算法。将原始图像I及其姿态信息K作为PST模块的输入,通过方向定位和关键点计算获得Ia中关键点的转换位置P。
(6)
(7)
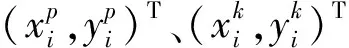
为使输入图像与标准姿态对齐,关键点匹配损失定义为两组关键点之间的L2损失之和,使Ia中每个转换后的关键点与标准姿态的关键点之间尽可能接近。对称的对齐损失函数LAli为:
(8)
其中,P和T分别表示Ia上关键点和目标关键点,kn和tn分别表示P和T的第n个关键点,vn表示第n个目标关键点的可见性分数,N表示关键点的数量。
如果输入图像是低分辨率或从侧面、背面拍摄的图像,多数姿态估计算法很难区分人体的左右部分。在这种情况下,将所有仿射变换后的关键点与标准姿态匹配可能会造成巨大损失,再加上对STN的不当指引,会进一步导致意外的空间变换。为解决上述问题,本文根据人体对称性放宽约束,只选择对称关键点的中心和距离来计算损失,而忽略其他属性。改进的对称对齐损失函数LAli计算如下:
LAli=MSE(Pm,Tm)+MSE(Pd,Td)
(9)
其中,Pm、Tm分别表示对应仿射图像的关键点P和标准姿态目标关键点T中对称关键点的中心坐标(x,y),Pd、Td分别表示P和T中对称关键点的距离,kpi、kpj和kTi、kTj分别表示P和T中对称的关键点对。
PST模块不仅可以单独用于对齐(如图3、图4所示),还可以嵌入到CNN模型中进行端到端训练。

图3 Market-1501训练集对齐示例

图4 Market-1501测试集上的对齐结果可视化
Fig.4 Visualization of alignment results on the Market-1501 testing set
2.2 特征提取
ResNet是目前使用较广泛的CNN特征提取网络,本文采用ResNet-50作为主干网络,在PST模块中提取仿射变换后图像Ia的全局特征。
F=fFE(Ia)
(10)
其中,fFE(I)是一个特征提取器。
通常用于行人再识别的softmax损失LID和三元组损失LTri都被用来训练本文模型,同时利用由全连接层和softmax函数组成的分类器来预测输入行人的身份。
PID=softmax(WTF+b)
LID=cross-entropy(PID,y)
(11)
其中,PID是M个类的预测值分布,M是身份个数,y是每个样本的身份信息,Fia、Fip、Fin分别是anchor图像、positive图像和negative图像特征,β是三元组损失的边缘,在实验中取值为0.3。
对于整个网络的训练,本文将结合LAli、LID和LTri作为最终的损失函数,如式(12)所示。通过嵌入PST模块使得PGAN可以学习对齐特征进行匹配。
L=λLAli+LID+LTri
(12)
其中,超参数λ在实验中取值为0.1。
3 实验结果与分析
3.1 数据集与测试协议
本文模型首先在Market-1501数据集上进行训练,然后在Partial-REID和Partial-iLIDS数据集上进行测试。在数据增强阶段,随机裁剪生成局部图像用于训练。
1)Market-1501[19]包含6台摄像机从不同视角拍摄的1 501个身份的行人图像32 368张。在训练集中,包含12 936张751个身份的图像。
2)Partial-REID[14]是一个局部行人图像数据集,包含60个身份的600张行人图像,每个身份有5张全身图像和5张局部图像。这些图像是在某大学校园从不同视角、背景进行拍摄,并存在不同类型的遮挡情况,每个人的所有局部图像组成Query集,而整体行人图像用作Gallery集。
3)Partial-iLIDS[20]是一个基于iLIDS的局部图像数据集。Partial-iLIDS共包含238张由多个非重叠摄像机捕获的119个身份的图像。对于被遮挡的行人,通过剪切每个身份图像的非遮挡区域生成局部图像,构建Query集,每个身份的非遮挡图像被选择用来构成Gallery集。
本文使用累积匹配曲线(Cumulative Match Characteristic,CMC)的Rank-1、Rank-3准确率作为评估指标来衡量模型性能。
3.2 PGAN实现
PGAN实现过程具体如下:
1)局部图像产生:由于局部行人再识别数据集只提供测试集,因此需要对某些整体数据集进行训练。为学习部分图像的对齐,根据给定范围随机裁剪图像生成整体图像的局部图像,同时对输入关键点做同样处理,使其与输入图像一致。为平衡训练集中整体图像和局部图像的数量,设置整体图像的裁剪概率为0.5。
2)数据增强:图像大小调整为256像素×128像素,并将原始像素值归一化至[0,1],然后分别减去0.485、0.456、0.406,再除以0.229、0.224、0.225,对RGB通道进行归一化处理。在训练阶段,在水平方向随机翻转每个图像,填充10个零值像素,再将其随机裁剪成一个256像素×128像素的图像进行数据增强。
3)网络设定:选择Re-ID中常用的ResNet-50作为骨干网络。参考文献[21]设置,使用ImageNet上预训练的参数初始化ResNet-50,并将最后一个卷积层的stride修改为1,将全连接层的连接数修改为M,M表示训练数据集中的身份数。在全连接层前使用BN bottleneck,PST中STN的参数θ初始化为[1,0,0,0,1,0]。采用Adam法对模型进行优化,共有120个训练epoch。初始学习率设定为3.5×10-4,使用Warmup方法改变学习速率,在前10个epoch时将学习速率从3.5×10-5线性增加至3.5×10-4,然后分别在第40个epoch和第70个epoch时将学习率除以10。
4)训练:本文模型分为两个训练阶段。在第一个阶段使用式(9)中的对齐损失LAli在Market-1501数据集上预训练PST模型;在第二阶段利用预训练的PST权值和ResNet-50的ImageNet上的预训练参数初始化整个PGAN模型。
3.3 PST结果可视化
为验证PST对局部图像的对齐性,在Partial-REID和Partial-iLIDS数据集上进行实验。PST可以学习对齐的空间变换,其在Partial-REID数据集上的结果如图5所示,结果表明PST不仅能对整体图像进行对齐,而且能对局部图像进行准确对齐,验证了PST模块的有效性。

图5 Partial-REID数据集上的PST结果可视化
3.4 在Partial-REID和Partial-iLIDS上的测试结果
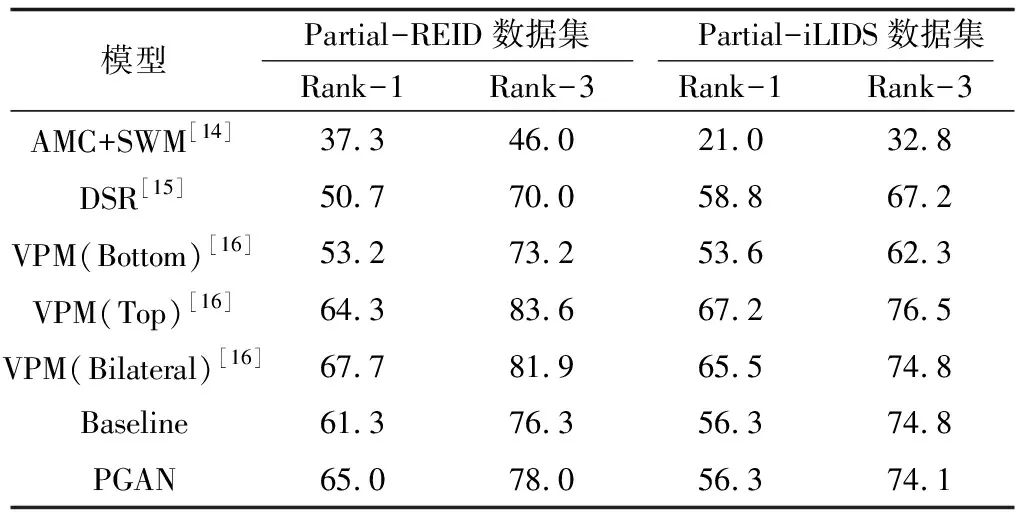
本文在Partial-REID和Partial-iLIDS数据集上进行Rank-1、Rank-3准确率实验,结果如表2所示。
表2 Partial-REID、Partial-iLIDS数据集上的Rank-1和Rank-3准确率
Table 2 Accuracy of Rank-1 and Rank-3 on Partial-REID and Partial-iLIDS datasets %
模型Partial-REID数据集 Partial-iLIDS数据集Rank-1Rank-3Rank-1Rank-3AMC+SWM[14]37.346.021.032.8DSR[15]50.770.058.867.2VPM(Bottom)[16]53.273.253.662.3VPM(Top)[16]64.383.667.276.5VPM(Bilateral)[16]67.781.965.574.8Baseline61.376.356.374.8PGAN65.078.056.374.1
为验证PST对局部Re-ID的识别效果,本文将PGAN与未使用PST的Baseline模型进行比较。对于局部Re-ID数据集,Baseline在Partial-REID、Partial-iLIDS数据集上分别得到61.3%、56.3%的Rank-1准确率,PGAN在Partial-REID数据集上的Rank-1准确率相比Baseline提高了3.7个百分点。PGAN相对于Baseline的优势在于:PST进行身体水平的对齐,以处理显著的不对齐问题,但其在Partial-iLIDS数据集上没有明显的性能提升,可能的原因为Partial-iLIDS数据集中的局部图像保留了大部分身体,其不对齐程度在CNN的处理范围内。
PGAN在两个局部数据集Partial-REID和Partial-iLIDS上与其他模型进行比较。在Partial-REID数据集上,PGAN的性能相比AMC+SWM和DSR有较大的优势,但与VPM相当。在Partial-iLIDS数据集上,PGAN的性能超越了AMC+SWM。由于PGAN模型嵌入了一个简单的PST模块进行局部图像与整体图像的对齐,从而提高局部图像的识别性能。
3.5 检索结果可视化
对于卷积神经网络,即使图像中只有行人的局部身体部位但包含一些明显特征的图像,如黄色衣服或者偏移程度较小的图像,其也可以学习高层特征实现图像区分,然而对于没有明显特征、显著不对齐的局部图像很难与整体图像进行匹配。图像行人局部图像的检索结果如图6所示。在图6(a)中,Baseline无法找到匹配图像,即匹配图像排在第5位后,而PGAN匹配图像排在第1位。在图6(b)中,对于同一输入图像,Baseline匹配图像排在第4位,而PGAN的匹配图像排在第1位。实验结果表明,局部图像对齐对局部行人再识别具有较大作用。

图6 检索结果可视化
4 结束语
本文提出一种用于局部行人再识别的姿态引导对齐网络(PGAN)。在PGAN中,PST模块通过姿态信息引导,可对部分行人图像进行有效对齐,只需在数据准备阶段通过姿态估计获取训练数据姿态信息,然后基于PST计算得到模型所需姿态信息,使得训练过程更加高效。实验结果表明,PGAN在局部行人再识别上取得了较好的识别效果,且在训练阶段和推论阶段均未产生额外的计算成本与姿态信息。后续将对结合注意力机制的局部行人再识别模型进行研究,通过抑制背景等干扰信息提高局部行人再识别的准确率。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
意林(2021年5期)2021-04-18
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
扬子江(2019年1期)2019-03-08
唐山师范学院学报(2018年6期)2018-12-25
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
新高考·高一物理(2015年5期)2015-08-18
