
基于粗糙集的影响大学生心理健康的研究
2020-05-22 13:56倪治伟
计算机技术与发展 2020年5期
徐 怡,余 浩,刘 刚,倪治伟
(1.安徽大学 计算智能与信号处理教育部重点实验室,安徽 合肥 230039;2.安徽大学 计算机科学与技术学院,安徽 合肥 230601;3.安徽大学 互联网学院,安徽 合肥 230039)
0 引 言
在如今的社会环境中,大学生在入学前承受压力大,课业繁重,部分学生存在或多或少的心理健康问题。但是心理健康的影响因素复杂,比如是否为单亲家庭,性格类型,参加课外活动的情况等等,各因素的重要程度也有差别,同时其内在联系也模糊不清,对高校的策略制定提出了严峻的挑战。因此,利用科学的方法找出影响因素,挖掘出有指导意义的依赖规则就变得十分重要。
波兰学者Z.Pawlak在1982年提出的粗糙集理论是一种能够定量分析处理不完整、不一致、不精确性信息与知识和不确定性的数学工具[1]。粗糙集理论与其他理论在处理不确定和不精确的问题的区别是,它不需要提供数据集合以外的任何先验信息处理这个问题,所以问题的不确定性的描述或处理可以更加客观[2]。基于粗糙集理论的应用研究主要集中在属性约简、规则获取等方面,基于粗糙集的理论发展为数据挖掘提供了许多有效的方法[3]。决策集的一种树结构,决策树方法具有速度快、易于转换为简单易懂的分类规则等优点。
对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
文中首先设计了高校心理健康状态调查问卷,面向本校大一到大四的学生分发调查问卷收集数据,经过离散化处理后,利用粗糙集理论中基于信息熵的属性约简算法找出影响大学生心理健康的关键因素,最后利用基于属性重要度的决策树规则提取算法挖掘出影响因素与心理健康程度的依赖关系,得到支持度、置信度高的规则集。
通过实验、评估验证了规则集的有效性。研究成果可以指导高校制定出具有针对性的改善大学生心理健康的政策,从而准确及时地帮助存在心理健康隐患的大学生。
1 粗糙集理论
为引出粗糙集的属性约简算法,下面介绍文中涉及到的粗糙集的基本概念[4-6]:
定义1:完整的信息系统S,可以用四元组表示为S={U,R,V,f},简记为S={U,R}。U={x1,x2,…,xn}是一个由有限个对象构成的论域,A=C∪D表示域属性集合,其中C={a1,a2,…,an}是条件属性,D={d}为决策属性;V表示属性值域;f是信息函数从U×R到V的信息函数,即f:U×R→V,用于表示记录x在属性a∈A上的取值。
定义2:任取非空属性子集B⊆R,如果对xi,xj∈U,∀r∈B,f(xi,r)=f(xj,r)均成立,则B为不可分辨关系,记为Ind(B)。Ind(B)即可把论域∪中分为若干个等价类,等价类的集合记为∪=Ind(B),为基本集。另外如果不存在集合X表示成某些基本集的并时,称X为B粗糙集。
定义3:任取子集X⊆U,则X关于知识R的上近似和下近似是:
R-(X)={x∈U,[x]R∩X≠∅}
R-(X)={x∈U,[x]R⊆X}
其中,[x]R表示元素x的R等价类。确定域Pos(X)表示U中在R下能确定归入集合X的元素的集合,否定域表示为Neg(X)。
定义4:在数据规约中,利用两个属性集合P,R⊆Q之间的相互依赖程度可以确定一个属性a的重要度。属性P对R的依赖程度用γR(p)表示。
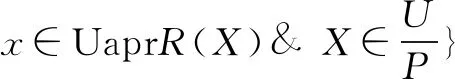
属性a加入R,对于分类U/P的重要程度定义如下:
SGF(a,R,P)=γR(p)-γR-|a|(p)
定义5:属性集合P的信息熵H(P):
定义6:设U是一个论域,P是U的一个条件属性集集合,d为决策属性,r∈P是核属性的充分必要条件为:
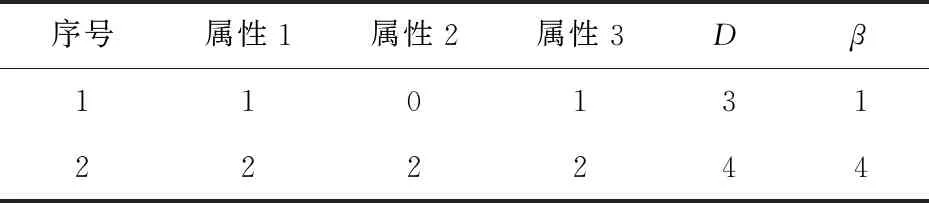
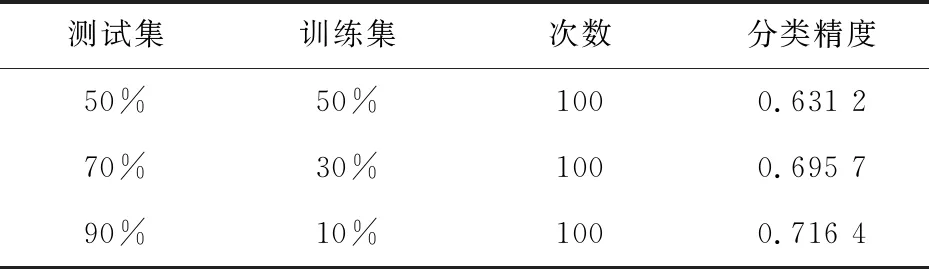
H({d}|P) 下面介绍基于信息熵的粗糙集属性约简算法。 如果一个集合有无一个属性对于它对决策表的条件信息熵的大小不造成任何改变,表明这个属性就可以被约简[7-9]。 输入:决策表DT=(U,C∪D)。 主要步骤: Step1:令决策属性集合为D,条件属性集合为C,计算D的信息熵H(D)。 Step2:计算决策表中属性集C对决策属性D的互信息量I(C,D)。 Step3:求核属性core。 (1)初始化core为空集; (2)∀a∈C,若有f(x,C-a)=f(y,C-a),a就是核属性。 Step4:令core为R,计算R对决策属性D的互信息量I(R,D)。 Step5:对∀a∈C-R,计算其对D的互信息量最大的属性,R=R∪a。 Step6:计算此属性集R对决策属性D的互信息量I。当属性集R的I和全部C的I相等时,则结束;否则转向Step5。 得到的约简集需通过规则提取才能得到有指导意义的规则集。下面介绍基于决策树的规则提取算法。 要理解好决策树,首先说明一些基本概念及其决策树的使用过程0-0。再以概念为基础介绍基于决策树的规则提取算法,支持度和置信度的概念[10-13]。 决策树是知识表示的一种形式。决策树具有树结构,树结构由多个节点和分支组成。决策树的第一个节点称为根节点,根节点是应用决策树时的唯一入口点。下面的根节点和内部节点选择一个属性组,换句话说,它们会在内部问一个问题,并将连接节点分支,和树枝将有答案的可能值,称为叶节点和终端节点决定节点用于确定预计值或对于一个给定的类别分类。 决策树的使用是通过决策树变换的分类规则来确定未知类别数据对象的分类。 首先根据所建立的决策树生成if-then格式的分类规则,然后在分类规则的前提下对所判断数据对象的属性值进行比较。如果与规则的前提一致,则该规则的分类就是数据对象的类。 以建立决策规则树为目的构造决策树算法。 Step1:在约简属性集中选择AS(attribute significance)大的属性作为节点,如果各个属性的AS相等,选择复合程度最小的属性,如果复合值再一致,则选择序号较小的属性。 Step2:依据所选的属性进行分类,然后对每个类重复上述操作,直到所有的类别中的决策属性相等,或属性集合为空,或者属性选择不能再继续分类,从而产生相应的叶子节点。选择属性后,将其从reduce属性集中删除,以确保所选属性不会重复用于每个分支。 Step3:读树。每个叶子节点是一类,就是一个规则。 Support(支持度):表示同时包含A和B的属性占所有属性的比例。如果用P(A)表示使用A属性的比例,那么Support=P(A&B)。支持度是该规则在决策表中的所占比例。 Confidence(置信度):表示使用包含A的属性中同时包含B属性的比例,即同时包含A和B的属性占包含A属性的比例。公式为:Confidence=P(A&B)/P(A)。置信度计算方法是该规则和该规则有关的全部不相容规则比例。举例如表1所示,其中β表示规则在表的个数,D为决策属性,假设决策表有100个元组。 表1 举 例 则有: (1)CD=1/(1+4+1)×100%=16.7% SD=1/100×100%=1% (2)CD=4/(1+4+1)×100%=66.7% SD=4/100×100%=25% 文中选择了通过面向本校大一到大四的学生分发问卷的形式收集数据,通过抽样调查得到的数据经过筛选后具有一定的普遍性和可靠性。 对处理后的数据使用上文所介绍的算法得到规则集,然后通过支持度和置信度的计算验证了规则集的最简性,再通过交叉测试验证分类精度的方法验证了规则集的有效性。 在进行调查问卷之前,考虑到大学生的隐私问题和后期处理的方便,对调查问卷进行了几次修改。 本次实验面向本校大一到大四的学生随机分发了300份调查问卷。剔除掉29份无效问卷后得到271份有效问卷。 首先建立大学生的心理健康特征决策表。在构建所有大学生的心理健康特征决策表时,将所有学生调查问卷视为论域U。将大学生心理健康的影响因素构成条件属性集C,心理健康总体评价作为决策属性集D,得到决策表[14]。 利用第2节描述的基于信息熵的属性约简算法对决策表进行处理,得到约简后的属性集:{a3,a5,a10,a13},分别表示性格类型、单亲家庭、课外活动、人际关系。 在属性约简的基础上,利用第3节描述的规则提取算法对约简后的决策表进行处理,可以得出以下5条规则。 (1)Ifa5=0 anda13=1,thend=0 (2)Ifa5=0 anda3=0,thend=0 (3)Ifa3=0 anda13=0,thend=0 (4)Ifa3=1 anda13=1,thend=1 (5)Ifa10=1 anda13=1,thend=1 为验证所得规则为最简规则,分别计算了5条规则的支持度和置信度,如表2所示[15]。 表2 CD和SD计算 % 由结果可知所有规则的CD即置信度均为1,即可推出不能去掉任一规则,即为最简规则。如果在5条规则中加一条,例如: Ifa10=0 anda13=1,thend=0;则规则1的CD会变化为66.7%,SD也会下降,同理对规则3和规则4也会有同样的影响。 验证了最简性后,为了验证所得5条规则的有效性,从279分数据随机抽取部分数据作为训练数据,另一部分作为测试数据,按照不同比率抽取,进行三组交叉测试,每组100次,取100次的分类精度平均值作为最终的分类精度,结果如表3所示。 表3 分类精度测试结果 从结果中可以得到分类精度在60%以上,证明了规则集的有效性。同时训练数据与分类精度正相关,进一步证明了算法的可靠性和规则集的有效性。 经过获取数据、处理数据和数据挖掘之后得到的结果中可以认识到影响大学生心理健康的主要因素为是否为单亲家庭、学习情况和人际关系,有少许影响的为性格类型。在本研究中,了解到为单亲家庭的同学更容易有心理问题。同时学习情况较差并且人际关系较差的同学也存在着心理健康风险,性格类型对大学生心理健康的影响存在但并不显著。与人们的认知相同,性格外向学习情况好的同学普遍心理健康状况好,这在收集问卷的过程中也有所体会。为了准确地挖掘出影响大学生心理健康的因素,利用粗糙集的知识构建了一种数据挖掘模型,并通过实验验证了其可靠性,可以协助高校有针对性地帮助可能存在心理健康问题的大学生,对提高大学生整体心理健康具有一定的指导价值。2 基于粗糙集理论的属性约简算法
3 基于决策树的规则提取算法
3.1 决策树概念
3.2 决策树使用过程
3.3 算 法
3.4 支持度和置信度
4 实验分析
4.1 设计问卷
4.2 处理过程及结果
4.3 规则集有效性评估

5 结束语
猜你喜欢
聊城大学学报(自然科学版)(2022年5期)2022-10-29
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
计算机应用(2022年2期)2022-03-01
计算机与生活(2021年8期)2021-08-07
计算机应用(2021年4期)2021-04-20
科学与信息化(2019年28期)2019-10-21
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
科学与财富(2016年32期)2017-03-04
海峡科技与产业(2016年11期)2016-12-26
数学学习与研究(2016年22期)2016-12-23
