
基于数据挖掘和互联网评论探索贫困地区的景点特点
2020-05-23 15:32邹冠如罗毓麟
科学导报·学术 2020年67期
邹冠如 罗毓麟


【摘 要】为了促进贫困地区旅游业的发展,本文通过网络爬虫获取到景点评论数据,通过文档向量化方法Doc2Vec生成文本向量,应用改进后的基于欧几里得距离的聚类算法K-mean将文本向量进行三个类簇的聚类,最后从三个类簇中获取到评论的大文本,采用TextRank算法,对大文本中若干个句子进行打分排序,获取到评分最高的句子,即评论大文本中最为核心的句子。
【关键词】Doc2Vec;K-mean;TextRank算法
一、前言
随着社会全面小康的时代的到来,作为人们休闲娱乐方式之一的旅游得到了飞速的发展,旅游越来越成为人们的一种时尚生活方式。而我国由于历史和自然的原因,各地区之间和地区内部的经济发展很不平衡,因此通过旅游产业带动贫困地区的经济发展是一项利于地区脱贫的一大措施。但是网上各种旅游平台的信息量太大,不利于游客迅速抓到景点的亮点,对于贫困地区的景点来说更是如此。也正是如此,阻碍了贫苦地区的游客数量的增长。而事实上,大部分的贫困地区均具有优质的环境资源和廉价实惠的农产品。因此本文以河源五大为省级重点扶贫的特贫困县之一的紫金县的御临门景区为案例,使用网络爬虫技术、数据挖掘技术和自然语言处理技术打造提炼景点特点模型,使得游客获取到更多贫困地区的旅游景点信息,为自己打造更合适、性价比更高的旅游线路,并且带动贫困地区经济的发展,助其更快脱贫。
二、相关技术
1.网络爬虫
爬虫技术是一种按照一定规则,自动抓取信息的程序或脚本[1]。我们可以在遵守网页协议的前提上爬取到携程网、美团网和大众点评等的景点、酒店评论信息,为我们的综合更全方面的评价提供了优秀的数据基础。
2.数据挖掘
数据挖掘是使用现在的算法技术从数据获取到数据的深层信息的探索过程。近年来,数据挖掘引起了各大行业的极大关注,其主要原因是存在大量去敏数据,可以广泛使用,想要通过计算机和数学将这些数据转换成有用的商业信息,产生数据的直接价值。
3.自然语言处理
自然语言处理是人工智能领域和计算机科学领域中的一个重要方向。它研究能实现计算机与人之间用自然语言进行有效通信的各种理论和方法[2]。通过特别的方法,让计算机也能听懂人类语言,这一技术在本文是至关重要的,计算依赖与计算机,而计算机则需要此项技术才能明白文本数据是在表达什么。
三、最具代表性的评论文本的自动提炼
1.基于Doc2Vec模型的句子向量化
Doc2Vec方法是一种无监督算法,能从文本(例如:句子、段落或文档)中学习得到固定长度的特征向量表示。在Doc2Vec中,每一句话和每一个词语都是唯一的向量,假设有两个矩阵,第一个矩阵X的列表示的是文本中每个句子的向量,第二个矩阵Y的列表示的是每个句子的词的向量。每次从一句话中滑动采样固定长度的词,取其中一个词作预测词,其他的作为输入词。将本句话的向量和本次采样的词向量相加求平均或者累加构成新的向量Z,Z便作为神经网络输入层的输入神经元,进而使用向量Z预测此次窗口的预测词[3]。
2.机器学习——K-mean算法
K-mean聚类算法具体过程如下:随机选择K个点作为初始聚类中心,将剩余的每个点按照距离分配给上述K个点,形成K个类簇。然后计算每个类簇的质心,并将其作为下一次迭代的聚类中心,直到满足停止训练的条件[4](例如函数收敛或达到最大迭代次数)。两点之间的距离计算方式有欧几里得距离、余弦距离、曼哈顿距离、切比雪夫距离、Jaccard相似系数等,本文采用欧几里得距离计算方法计算文本与文本之间的相似度。
其中,和是表示文本,i和j表示文本的顺序,n表示文本的向量维度。
传统K-mean算法虽然具有简单高效、可解释性强的优点,但是K-mean聚类的效果和初始聚类中心(又称重心)的选取密切相关,如果随机选择重心,容易使算法陷入局部最小值,无法收敛到全局最优。针对此项,本文做出了改进:通过多次数避免随机选择的随机性,即是选用多次随机初始化,计算每一次的成本函数,选取成本函数代价最小的初始点作为聚类结果。
3. TextRank算法概述
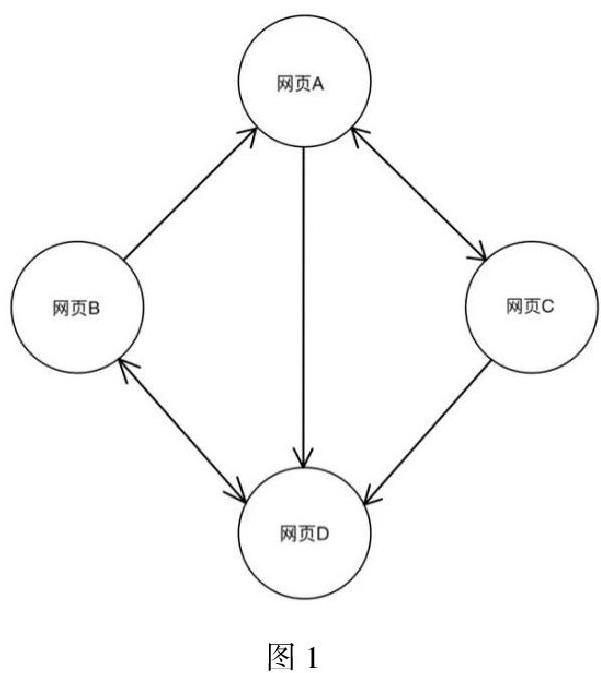
TextRank 算法是一种可以直接用来对文本进行排序的基于图的排序算法,其基本思想来源于谷歌的PageRank算法。而PageRank算法的核心思想是网页被更多的网页指向连接,则证明此网页更重要。如下图,可以看到被网页指向最多的是网页D,所以在PageRank中,网页D是比其他三个网页更加重要的。
TextRank 采用的是投票打分机制,首先对文本进行预处理,按照词项或者句子对基本单元进行分割,然后对预处理后的文本以项词或者句子为节点构建图模型,可以快速的实现对单个文本内容中的关键信息进行精确提取[5]。
TextRank 算法抽取摘要句的主要思想是通过对文本中句子进行打分排序,摘要抽取具体过程如下:
(1)预处理:将要构建的文本或文本集分割成句子=[,,...,],构建如图2-2所示的图,其中为句子集,为边集,同时对句子进行分词、去除停用词等处理,得到=[,1,,2,...,,n],其中 是保留后的候选关键词。
(2)句子相似度计算:构建图中的边集,边的构建基于兩个节点的重叠信息,给定两个句子和,根据以下公式进行相似度计算:
通过公式(1)计算得到两个句子相似度,如果相似度大于提前设定的阈值,那么j句子i和句子j就含有相同的语义信息并且一条边将两个节点连接起来,边的长度为两个节点的相似度,相似度越大边越长;
(3)句子权重计算:根据公式(a),迭代计算各句子的得分;
(4)抽取摘要句:将(b)得到的句子按照得分多少进行从高到低排序。
(5)形成摘要:按照一定的压缩比(一定的长度或者字数)对排序后的句子抽取组成摘要[6]。
四、实验过程
1.数据收集。本文爬取关于河源市景点的多个平台的景点评论信息,如美团网、携程网等,最大限度的整合同一景点的互联网上的所有评论。
2.数据预处理。对爬取下来的数据进行格式上的清洗和整理。
3.向量化文本。使用Doc2Vec技术将每一个文本转换为300维向量(参考谷歌网络设置的维度)。
4.K-mean聚类。考虑到评价主要分为三个等级,分别是好、中和差,因此本文的目标是将向量化后的文本聚类成三个类簇,并且分别提出三个类簇的评论文本,做成三个拼接后不同族的大文本,为下面TextRank算法做好数据准备。
5.提取核心评价文本。利用第四步准备好的数据,使用TextRank排序技术对每一类簇的大文本进行打分排序,输出每一个大文本的分数排名最高的评论作为三个该景点评论中最核心的三个评价。
五、实验结果与分析
1.实验结果
本文以贫困县河源市紫金县御临门温泉度假村为案例,爬取网上评论651条数据,使用python语言实现实验,可以得到在改进后的K-mean聚类的三个类簇中,每个类簇最核心的评论分别为:
“我订的是别墅、每个房间都有独立的温泉池,很方便,酒店环境很好,早餐我个人觉得很好,酒店位置有点偏,有大型停车场。”、“总的说来还是很好的,值得再去的温泉,房间很卫生,周围的环境也很好,这次唯一不好的就是安排的房间隔壁就是酒店工人的房间,还是有点吵,特别早上早早就听到服务员在外面的声音,还有早餐的种类不算多,还有待改进”、“酒店很不错,温泉的池子不少,房间设施也很好,前台服务态度很热情,早餐丰富,停车方便,就是往酒店的路比较烂”。
2.实验结果分析
从上述三个核心评价来看,我们可以明显的感受到紫金县御临门温泉度假村整体还是不错的,但是主要存在了两个核心问题:第一是早餐的种类不够多,不能满足大部分人对这个价格的需求,第二是酒店对噪音的管制仍需继续加强。
单从三个类簇中排名第一的评论观察,对K-mean算法起到的重要性不够明显,所以我们分别从三个类簇中排名前三的评论再进行分析。
第0类族排名前三的分别是:
“我订的是别墅、每个房间都有独立的温泉池,很方便,酒店环境很好,早餐我个人觉得很好,酒店位置有点偏,有大型停车场。”、“那天去到酒店已经晚上八点多了,很幸运的帮我们免费升级到别墅区,房间很大,因为是夏天,住店的人不是很多,当天晚上在房间里泡温泉还不错,第二天去公共温泉区就实在太热了,大太阳晒着水都太烫了,赞一下酒店的早餐送餐服务,按约定时间准时送到房间,而且都热热的,总体来说是很愉快的一次住店体验。”、“酒店环境,服务,设施还可以,露天温泉很干净,下次还会再来。”。
第1类族排名前三的分别是:
“总的说来还是很好的,值得再去的温泉,房间很卫生,周围的环境也很好,这次唯一不好的就是安排的房间隔壁就是酒店工人的房间,还是有点吵,特别早上早早就听到服务员在外面的声音,还有早餐的种类不算多,还有待改进。”、“酒店虽然旧了些,但环境还是不错,房价有点贵,早餐品种太少,是真温泉。”、“订的花园套房,感觉有点久,自费补差价住进了别墅房,环境很好,温泉是真的温泉,服务一般般,早餐品种不多,房间只有两瓶水,叫送多一瓶矿泉水还要收费,2000一晚的房就显得太小气了,其他都还不错。”。
第2类族排名前三的分别是:
“酒店很不错,温泉的池子不少,房间设施也很好,前台服务态度很热情,早餐丰富,停车方便,就是往酒店的路比较烂。”、“温泉度假酒店算范围大和位置好找地方,下了汕湛高速走十公里左右到了,环境舒适优美东南亚设计,有天然的温泉温眼,水质感好,房间设施齐全,早餐还算可以。”、“早餐没有吃,睡床有点硬,前台服务态度好,有问题都会帮忙解决,周边餐厅很多,八刀汤棒棒,卫生还行,就是房间灯太暗,晚上房顶也没有灯,看电视根本太暗了点,温泉个别池还可以,有一些水都不太热。”。
从上述评论中,可以明显感受到每一个类簇表达的情感不一样。
六、结束语
本文采用Dov2Vec将评论向量化,应用改进的机器学习算法K-mean进行三个类簇的聚类,最后使用TextRank算法对评论进行排序打分,得到每一个类簇最核心的评价文本,便于帮助游客从琳琅满目的互联网旅游资源获取到关键信息。通过应用数据挖掘和自然语言处理技术进行整合,更加有助于旅客根据自身需求和出行要求选择更合适的景点和线路。同时有助于对拥有优质旅游资源的贫困地区通过旅游行业带动自身经济发展,走上脱贫大道,有助于商家根据核心评价,对自己的经营模式、服务质量和硬件措施等进行改进且一步提高,从而吸引更加多的游客前往游玩。
参考文献
[1]孙建立,贾卓生. 基于Python网络爬虫的实现及内容分析研究[C]// 中国计算机用户协会网络应用分会2017年第二十一届网络新技术与应用年会论文集. 2017.
[2]王泽宇. 自然语言处理概述及应用[J]. 通讯世界,2019,26(04):309-310.
[3]徐馨韬,柴小丽,谢彬,等. 基于改进TextRank算法的中文文本摘要提取[J]. 计算机工程,2019,045(003):273-277.
[4]谭佩知. 基于K-MEAN算法的知识资源聚类研究[J]. 信息技术与信息化,2015,000(010):191-192.
[5]曹洋. 基于TextRank算法的单文档自动文摘研究[D]. 南京大学,2016.
[6]张波飞. 基于LDA和TextRank相结合的中文多文档自动摘要提取[D]. 内蒙古师范大学.
[7]于娟,刘强. 主题网络爬虫研究综述[J]. 计算机工程与科学,2015,37(2):231-237
[8]JiaweiHan,MichelineKamber,JianPei,等. 數据挖掘概念与技术[M]. 机械工业出版社,2012.
[9]张奇,黄萱菁,吴立德. 一种新的句子相似度度量及其在文本自动摘要中的应用[C]// 第一届全国信息检索与内容安全学术会议. 2004.
作者简介:
邹冠如,2000年,男,本科在读,专业:数据科学与大数据技术。
罗毓麟,2000年,男,本科在读,专业:数据科学与大数据技术。
(作者单位:北京理工大学珠海学院)
