
一种基于叠加Logistic映射分布的FWA-PSO新算法
2020-05-25 02:30孙小川刘太安魏光村王波卢昱波
软件导刊 2020年2期
孙小川 刘太安 魏光村 王波 卢昱波

摘 要:為了解决传统粒子群算法早熟收敛陷入局部最优、粒子中期震荡及收敛结果不精确的问题,提出一种基于叠加Logistic映射分布的FWA-PSO算法对其进行改进。具体方法是:叠加Logistic映射用于对粒子位置的混沌初始化,在粒子数量一定的情况下,平衡最大遍历路径与最快收敛速度;引入FWA算法,同时根据迭代次数与粒子位置标准差,基于惩罚机制非线性调整爆炸半径r、惯性权重w、个体学习因子c1和社会学习因子c2,融合高斯变异算子与循环单维度寻优策略,在维系粒子群多样性的同时,也能避免粒子越过最优解。实验结果表明:FWA-PSO算法针对单峰函数50次平均值均能达到最优解0,证明了算法的稳定性与可靠性;对于多峰函数,FWA-PSO算法也能求得最优解,证明该算法可跳出局部最优,得到全局最优解。
关键词:粒子群算法;叠加Logistic映射;FWA算法;惩罚机制;循环单维度寻优
DOI:10. 11907/rjdk. 192155 开放科学(资源服务)标识码(OSID):
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2020)002-0001-06
英标:A FWA-PSO New Algorithm Based on Superposition Logistic Map Distribution
英作:SUN Xiao-chuan1, LIU Tai-an1,2, WEI Guang-cun1,2, WANG Bo2, LU Yu-Bo2
英单:(1. College of Computer Science and Engineering, Shandong University of Science and Technology,Qingdao 266590,China;2. Department of Informaion Engineering,Shandong University of Science and Technology,Taian 271019,China)
Abstract: In order to solve the problem that the traditional particle swarm algorithm premature convergence is trapped in local optimum, the medium-term oscillator is inaccurate, and the convergence result is inaccurate, an improved algorithm is proposed, i.e., FWA-PSO (Fireworks Algorithm - Particle Swarm Optimization) algorithm based on superimposed logistic map distribution. The specific method is as follows: superimposed Logistic map is used to initialize chaotic of particle position, balance the maximum traversal path and the fastest convergence speed when the number of particles is constant; FWA algorithm is introduced, and based on the number of iterations and the standard deviation of particle position. Based on punishment the mechanism nonlinearly adjusts the blast radius r, the inertia weight w, the individual learning factor c1 and the social learning factor c2, and combines the Gaussian mutation operator with the cyclic one-dimensional optimization strategy to maintain the particle group diversity while avoiding the particles crossing the optimal solution. The experimental results show that the FWA-PSO algorithm can achieve the optimal solution for the 30-time average of the unimodal function, which proves the stability and reliability of the algorithm. For the multi-peak function, the FWA-PSO algorithm can also find the optimal. The solution proves that the algorithm can jump out of the local optimum and get the global optimal solution.
Key Words: particle swarm optimization; superimposed logistic mapping; FWA algorithm; penalty mechanism; cyclic one-dimensional optimization
0 引言
PSO(Particle Swarm Optimization)算法由Kennedy&Eberhart[1]提出,是一种基于群体智能的全局随机搜索算法,模拟了鸟群觅食的迁徙和群聚行为。与遗传算法相比,PSO算法是单向信息流,只是把信息传递给其它粒子。群体迁徙的本质是寻找全局最优解并向其靠近,在迭代过程中,不断更新每个粒子寻找到的最优解与全局最优解,并且PSO没有“交叉”和“变异”操作[2],收敛效率高、调整参数少,仅需调整惯性变量w、个体学习因子c1和社会因子c2的值,即能以较低的时间复杂度找到较为满意的解[3]。因此,相比于其它优化算法,效率更高的PSO算法成为现代优化方法领域的研究热点。
但PSO算法也存在不足之处,具体包括:在迭代过程中容易陷入局部最优,且跳不出局部陷阱;粒子收敛中后期会发生震荡,收敛速度变慢;收敛结果不精确等。针对以上问题,国内外学者提出了多种解决策略,如Shi等[4-6]提出带惯性变量w的速度更新公式,迭代时可维持上一代的趋势,增强了粒子在空间中的全局搜索能力;Liang等[7]提出一种综合学习粒子群优化算法(CLPSO),每个粒子速度更新时会参考其它粒子的全局最优解,通过综合学习策略,准确更新速度和位置;Liu等[8]利用混沌遍历思想提高局部搜索能力,使后期收敛结果更加精确;Pires等[9]将分数阶微积分引入粒子速度更新公式,使用分数阶阶次控制算法收敛速度。此外,为避免种群陷入局部最优,Dong等[10-14]引入自适应变异机制,在迭代过程中基于高斯变异[15-17]自适应调整参数。虽然学者们提出了多种解决方案,但是算法本身仍然存在缺陷。为了弥补算法的不足,本文提出一种基于叠加Logistic映射分布的FWA-PSO(Fireworks Algorithm——Particle Swarm Optimization)算法。
该算法会使粒子位置基于叠加的Logistic映射混沌序列[18-20]初始化,遵循空心规则,在满足粒子群最大遍历路径的同时,也平衡了与收敛速度的关系;重新设计惯性权重w、个体学习因子c1和社会因子c2的非线性迭代公式,该公式分为全局公式和局部公式,且有控制进化速度的参数n。n值越大,全局性或局部性越强;融入FWA算法[21-22],利用算法的爆炸性与局部覆盖性,结合高斯变异算子,为粒子赋予跳出局部最优的概率,并能找到局部最优解;同时针对高维多峰问题提出循环单维度寻优策略,利用基准函数测试后,可知该算法能显著提高全局搜索性能和收敛精度。
1 基本PSO算法
PSO算法是为了求解连续变量优化问题而提出的,其特征是模拟鸟群智能。在PSO算法中,每个优化问题的潜在解都是一个粒子,在鸟群中是搜索空间中的一只鸟。所有粒子都有一个由被优化函数决定的适值(Fitness Value),以及一个决定其飞翔方向和距离的速度,然后粒子追随当前最优粒子在解空间中进行搜索。粒子的速度和位置也在解空间中通过随机初始化产生,然后通过迭代找到最优解。每次迭代中,粒子通过跟踪两个极值更新自己。两个极值一个是粒子本身找到的最优解,称为个体极值,另一个是整个种群当前找到的最优解,称为全局极值。
假设在一个D维目标搜索空间中,由N个粒子组成一个群落,其中第i个粒子表示为一个D维向量。
第i个粒子的“飞行”速度也是一个D维向量,记为:
第i个粒子迄今为止搜索到的最优位置称为个体极值,记为:
整个粒子群迄今为止搜索到的最优位置称为全局极值,记为:
找到这两个最优值時,粒子根据式(5)、式(6)更新自己的速度和位置。
其中,c1、c2为学习因子,也称为加速常数,w为惯性因子,r1、r2为[0,1]范围内的均匀随机数。式(5)右边由3部分组成,第一部分为反映粒子运动习惯的惯性权重部分,代表粒子有维持自己先前速度的趋势;第二部分为反映粒子对自身历史经验记忆的个体学习认知部分,代表粒子有向自身历史最佳位置逼近的趋势;第三部分为反映粒子间协同合作与知识共享群体历史经验的社会学习认知部分,代表粒子有向群体或邻域历史最佳位置逼近的趋势。
2 PSO算法缺陷分析与改进策略
2.1 粒子早熟收敛分析
标准PSO算法在多峰函数下,容易早熟收敛至局部最优,本质原因包括两方面:①粒子位置及速度初始化不适合,导致后期遍历路径少,未搜索至全局范围;②公式参数设计不恰当,导致粒子在进化过程中多样性迅速消失,无法突破局部最优。针对这两种原因,提出以下解决对策:粒子从叠加Logistic映射的混沌序列中选取,增加粒子遍历路径;改进参数调整公式,更合理且更有侧重性地调整惯性权重和学习因子。
2.1.1 叠加Logistic映射的混沌粒子
粒子位置初始化一般为解空间的随机值,假设某一函数的解空间为圆c=x2+y2,x,y=[-1,1],全局最优解为pg=(0,0),粒子位置为解空间均匀分布的随机值,在x轴上的粒子平均遍历路径如式(7)所示。
若要增加遍历路径,粒子应该在解空间初始化为临边分布,使[|xi|]取最大值。在标准PSO公式下分析粒子两种分布的收敛速度,如图1所示。
横坐标x为迭代次数xi,纵坐标y为粒子位置以极值点为均值的标准差sd。图1(a)粒子初始化为均匀分布,图1(b)粒子初始化为临边分布,设置标准差值sd<0.1为迭代终止条件,测试50次取平均值。临边分布迭代次数/均匀分布迭代次数约为1.25,可知临边分布收敛速度较差。为平衡最大遍历路径与最快收敛速度,提出粒子空心分布规则。分布规律如式(8)所示。
[?(j)]代表第j区间的粒子密度,sj代表第j区间面积(一维长度,二维面积,依此类推),k代表粒子初始化由边界至中心的等分区间个数。为了使粒子分布大致遵循公式(8),提出叠加Logistic映射分布。
Logistic映射也称为Logistic迭代,其是一个时间离散的动力系统,函数如式(9)所示。
其中,zk∈[0,1], ∈[0,∞)R。当μ=3.65,3.66,3.68,4.0时,在[0,1]区间迭代生成的混沌时间序列如图2所示。
由图2可知,选取区间[0.3,0.9]的粒子可以近似满足式(8),粒子分布也近似属于空心规则。通过一定映射关系,将图2依据初始范围[-100,100]转化为二维粒子位置初始化映射序列分布图,如图3所示。
2.1.2 基于惩罚机制的自适应参数调整策略
对于公式(5),合理设置w、c1、c2也可以一定程度上突破局部最优。较大的w、c1有利于粒子进行全局搜索,较小的w、c1有利于粒子进行局部搜索。因此,很多学者对固定的w提出各种改进策略,比较经典的有线性递减策略、随机策略和非线性递减策略。非线性递减策略如式(10)所示。
为了在粒子中后期仍然保持较大的w,提升粒子搜索深度,故将w作了改进,公式如下:
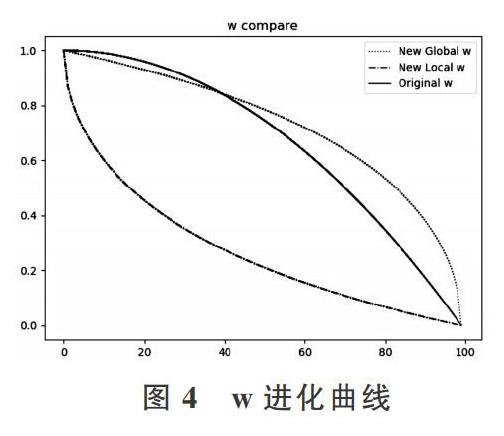
式(11)[wG]趋向于全局收敛,而式(12)[wL]则趋向于局部收敛。t为当前迭代次数,T为总迭代次数。n用来控制进化中的w值,n越大,作用越明显。[wmax]和[wmin]用于控制w的最大与最小范围。图4展示了当迭代总次数为T时,3种w进化曲线。
在搜索初期,一般采用较大的c1和較小的c2,有利于粒子群体搜索整个空间,而在搜索后期,较小的c1和较大的c2则有利于群体收敛于全局最优。基于此,粒子的个体学习因子c1可以采用非线性递减策略,而社会学习因子c2可以采用非线性递增策略,如式(13)、(14)所示。
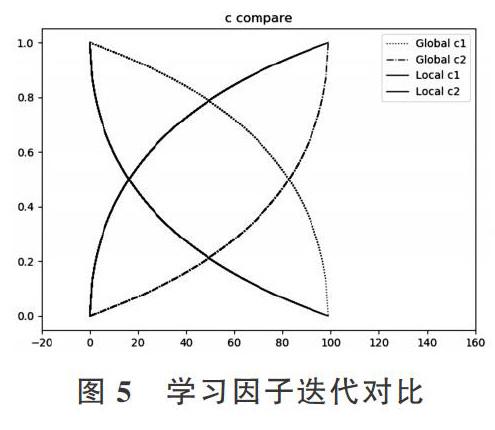
[c1G]、[c2G]学习因子偏向于全局搜索,而[c1L]、[c2L]学习因子偏向于局部搜索。[c1max]、[c1min]分别用控制个体学习因子的最大、最小范围,[c2max]、[c2min]分别用于控制社会学习因子的最大、最小范围。t为当前迭代次数,T为总迭代次数,n用来控制进化过程中学习因子c值大小。图5展示了当T=100时,4种学习因子c的进化曲线。
在粒子进化过程中,不合适的参数设置也会导致粒子在全局最优值附近产生震荡徘徊现象,大大降低了收敛速度。
如图6所示,迭代次数在120~160之间时,位置标准差sd值在5.0上下震荡,虽然粒子最终会收敛,但增加了额外运行开销。为了避免出现这种情况,本文提出基于惩罚机制的自适应参数调整策略,当位置标准差sd>1,且最近5次迭代得到[sd]的标准差小于0.1时,w、c1和c2应等于[wL]、[c1L]、[c2L],惩罚因子n增加1,达到快速收敛的效果,如式(15)所示。
[sd]代表最近5次位置标准差平均值,[sdj]是第j次位置标准差,P为最近5次[sd]值的标准差。
2.1.3 循环单维度寻优策略
粒子群在处理高维问题上有天然的弊端,这是因为在寻找全局最优解的同时,每一维度均会受到其它维度干扰,当维数增大时,扰动更为明显。为了降低多维度对粒子群算法的干扰,本文提出循环单维度寻优策略。
对于一个D维向量的Gbest,从第一维开始,将1维元素g1设置为变量,2~D维元素固定为常数,衍生出n个子向量,然后对子向量进行迭代。如图7所示,此时已将多维问题转化为一维问题。同样,下次以第2维为变量,一直持续到第n维。
每一次循环迭代,得到的结果Gbest总会比之前的最优适应度值更好,所以该循环算法的寻优轨迹是可取的,不会存在Gbest变差的情况。
2.2 FWA-PSO算法
传统粒子群算法的全局最优解经过有限次迭代后收敛精度不高,而融入FWA群体智能算法后,可以提高收敛精度。FWA算法由Tan&Zhu在2010年正式提出,当时二人受到了烟花在夜空中爆炸产生火花并照亮周围区域这一现象的启发。利用FWA算法的局部覆盖性,可以增强粒子的局部搜索能力,从而在算法运算后期更加精准地搜索最优解。
粒子在迭代搜索过程中,粒子位置会逐渐靠近,sd值会逐步递减至0,设定限值为se。当sd [ri]代表第i维的FWA爆炸半径,爆炸区域为解空间的小比例空间。λ为控制阈值数量级因子,[ximax]、[ximin]为粒子第i维的最大、最小值。 加入高斯变异算子得到式(18),对于爆炸半径r产生一个服从Gaussian分布的随机扰动项,可以在粒子爆炸时增加半径大小的不确定性,有利于粒子跳出局部最优,提高全局搜索能力。 经过变异后的半径如式(19)所示。 3 叠加Logistic映射分布的FWA-PSO算法步骤及仿真实验 3.1 算法步骤 Step1:确定粒子群规模N、初始化区间、速度上下限、最大迭代次数T、倍数η、阈值数量级因子λ等参数,并根据上文方法对粒子位置进行混沌似正态初始化。 Step2:更新粒子位置与速度。 Step3:计算粒子群局部最优值和全局最优值。 Step4:计算各粒子的适应度值,并根据迭代次数和中期震荡条件动态自适应调整惯性权重w、个体学习因子c1与社会学习因子c2。 Step5:更新各粒子个体极值与全局极值。 Step6:若达到停止条件,输出全局极值;若未达到停止条件,但达到爆炸触发条件,经高斯变异调整爆炸半径R,转向Step1;若循环次数达到设定值,执行一次循环单维度寻优算法,返回Step2;若停止条件和爆炸触发条件均未达到,返回Step2。 3.2 算法流程 算法流程如图8所示。 3.3 仿真实验 为了验证本文提出FWA-PSO算法的收敛性能,将FWA-PSO算法与文献[4]中带惯性的粒子群算法PSO-ω、文献[7]中的综合学习粒子群优化算法CLPSO以及文献[8]中的混沌粒子群算法CPSO进行比较。实验采用6个常用标准测试函数,如表1所示。这些函数中包括单峰函数和非线性高维多模态函数,往往容易使算法陷入大量局部最优点,属于优化领域中较难优化的函数。 Sphere、Matya是用来验证算法收敛速度的单峰函数,Griewank至Rosenbrock是用来验证算法跳出局部最优能力的多峰函数。惯性因子w取值区间为[0.5,0.8],初值为0.8,个体学习因子c1及社会学习c2的取值区间为[1.5,2.5],c1初值为2.5,c2初值为1.5。初始化粒子数为20,测试函数维度为30,基准函数评价次数FEs为200 000。算法所得结果均为50次运行结果的平均值。 表2中的gbset为算法在测试过程中得到的最优解,mean为50次运行结果平均值。通过表2中各算法实验结果数据对比可知,本文提出的PWA-PSO算法在各测试函数上的运行结果都表现较好。 由表2可以看出,与带惯性参数的PSO-w算法、综合学习CLPSO算法及混沌CPSO算法相比,FWAPSO算法在30维的高维复杂基准函数测试中表现更为稳定,针对单峰函数Sphere和Matyas,50次平均值均能达到最优解0,证明了算法的稳定性与可靠性。对于多峰函數Griewank、Rastrigin、Ackley,FWA-PSO算法平均值也能求得最优解,说明该算法可跳出局部最优,全局搜索能力更好。Rosenbrock是比较困难的优化函数,因为其属于高维多峰不可分函数,每一维优化均与相邻维度存在隐性关联,但在多次优化中,FWAPSO算法仍能求出最优解,多次平均值也远小于其它几种算法。因此,本文提出的FWAPASO算法具有更高的寻优精度与更强的寻优能力,更适用于解决其它算法难以解决的高维多峰函数优化问题。 4 结语 本文主要针对传统PSO算法存在的缺陷,包括容易陷入局部最优、粒子中后期震荡、收敛结果不精确几类问题进行分析,并提出一种基于叠加Logistic映射分布的FWA-PSO算法对其进行改进。粒子位置初始化由叠加的Logistic映射混沌时间序列产生,遵循空心分布原则,在保持收敛速度的同时,增加了粒子遍历路径,有利于提高全局搜索能力,避免遗漏部分解空间的搜索;通过非线性调整惯性权重、个体学习因子与社会学习因子,将参数分为偏向全局搜索与偏向局部搜索两种类型,根据不同情况选择更合适的参数公式;循环单维度算法明显提高了多维寻优效率,减少了迭代次数;融合FWA算法利用其局部覆盖性及高斯变异多样性,在不丧失全局搜索能力的同时,也能得到更为精确的局部最优值。仿真结果表明,本文提出算法相较其它算法具有更好的性能。后续工作将重点研究算法收敛性、时间复杂度及高维多峰函数各维度之间的隐性关系,以进一步提高算法性能。 参考文献: [1] KENNEDY J,EBERHART R. Particle swarm optimization[C]. Perth:Proceedings of International Conference on Neural Networks,1995. [2] MICHALEWICZ Z,JANIKOW C Z,KRAWCZYK J B. A modified genetic algorithm for optimal control problems[J]. Computers & Mathematics with Applications, 1992, 23(12):83-94. [3] REYES-SIERRA M, COELLO C C A. Multi-objective particle swarm optimizers: a survey of the state-of-the-art[J]. International Journal of Computational Intelligence Research,2006(3):287-308. [4] SHI Y H,EBERHART R C. A modified particle swarm optimizer[C]. IEEE World Congress on Computational Intelligence,1998:69-73. [5] SHI Y H,EBERHART R C. Empirical study of particle swarm optimization[C]. Congress on Evolutionary Computation,2002. [6] SHI Y,EBERHART R C. Fuzzy adaptive particle swarm optimization[C]. Proceedings of the 2001 Congress on Evolutionary Computation,2001:101-106. [7] LIANG J J,QIN A K,SUGANTHAN P N,et al. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions[J]. IEEE Transactions on Evolutionary Computation, 2006, 10(3):281-295. [8] LIU B,WANG L,JIN Y H,et al. Improved particle swarm optimization combined with chaos[J]. Chaos, Solitons and Fractals, 2005, 25(5):1261-1271. [9] PIRES E J S,MACHADO J A T,OLIVEIRA P B D M,et al. Particle swarm optimization with fractional-order velocity[J]. Nonlinear Dynamics, 2010,61:295-301. [10] PING-PING D. Improved particle swarm optimization with adaptive inertia weight[J]. Computer Simulation,2012(6):874-880. [11] ZHAN Z H,ZHANG J,LI Y,et al. Adaptive particle swarm optimization[J]. IEEE Transactions on Cybernetics,2010,39(6):1362-1381. [12] DAS S,GOSWAMI D,CHATTERJEE S,et al. Stability and chaos analysis of a novel swarm dynamics with applications to multi-agent systems[J]. Engineering Applications of Artificial Intelligence,2014, 30:189-198. [13] GONG Y J. Genetic learning particle swarm optimization[J]. IEEE Transactions on Cybernetics, 2017, 46(10):2277-2290. [14] ANGELINE P J. Evolutionary optimization versus particle swarm optimization: Philosophy and performance differences[C]. International Conference on Evolutionary Programming Springer,1998:601-610. [15] 姚凌波,戴月明,王艷. 反向自适应高斯变异的人工鱼群算法[J]. 计算机工程与应用, 2018,54(1):179-185. [16] 杜艳艳,刘升. 带有高斯变异的Lévy飞行改进蝙蝠算法[J]. 微电子学与计算机,2018, 35(3):83-87. [17] 黄海燕,彭虎,邓长寿,等. 均匀局部搜索和高斯变异的布谷鸟搜索算法[J]. 小型微型计算机系统, 2018,39(7):77-84. [18] JIANG M, SHEN Y, JIAN J, et al. Stability, bifurcation and a new chaos in the logistic differential equation with delay[J]. Physics Letters A, 2006, 350(3):221-227. [19] SHI Y, YU P. On chaos of the logistic maps[J]. Dynamics of Continuous Discrete & Impulsive Systems,2007,14(2):175-195. [20] 杨莘元,王光,谷学涛. Logistic混沌序列性能分析及应用仿真[J]. 邮电设计技术,2003(12):19-22. [21] 谭营,郑少秋. 烟花算法研究进展[J]. 智能系统学报,2014,9(5):515-528. [22] 包晓晓. 改进混沌烟花算法的多目标调度优化研究[J]. 计算机应用研究, 2016,33(9):2601-2605. (责任编辑:黄 健)
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
数学物理学报(2020年6期)2021-01-14
测控技术(2018年10期)2018-11-25
金桥(2018年4期)2018-09-26
浙江工业大学学报(2017年5期)2018-01-22
中国卫生(2014年5期)2014-11-10
物理与工程(2014年4期)2014-02-27
