
基于大数据的酒业舆情信息监测平台
2020-06-02 03:36邹佳成马远远唐伯超刘振国
酿酒科技 2020年3期
邹佳成,马远远,刘 婷,唐伯超,刘振国,高 辉
(1.电子科技大学计算机科学与工程学院,四川成都 611731;2.成都数之联科技有限公司,四川成都 610094;3.宜宾五粮液股份有限公司,四川宜宾 644000;4.中国酒业协会,北京 100831)
随着移动互联网用户的大规模增长,互联网已经成为人们生活的重要组成部分。如今社会,众多热点事件层出不穷,负面敏感信息可以在短时间内得到快速放大传播,制造严重舆情危机,给相关人员的声誉造成严重影响。相关部门和企业部门越来越关注公众舆论热点,面对汹涌的舆论,对大数据在线网络舆情的挖掘、方法和预警等方面的研究具有重要的社会价值和理论意义。无论是电视、报刊、网络、还是新媒体微博、论坛等,都在不断发布和传播各级政府的最新政策法规,全面监测这些媒体,可以及时获得自己关心的相关政策动向。同时根据自己所在部门和行业所关注的社会热点新闻,每天能够从舆情监测中获得所有的相关信息。
目前,舆情监控已引起政府部门和先进企业的重视[1],在大数据技术的支持下,相继开发了属于自己的舆情监测平台[2]。如,新浪推出了自己舆情平台“新浪舆情通”,可对某一网络事件在互联网上的整体传播情况,收集全网数据进行分析,自动生成涵盖事件简介、事件走势、网站统计、数据类型、关键词云、热门信息、热点网民、传播路径、相关词、网民观点、舆情总结等11 个维度的全网事件分析报告。政府部门也在开发各领域下的大数据舆情平台。同样,对于酒业,舆情同样影响着每一个品牌和企业。假酒事件常有出现,骗财害命也影响了品牌的形象。
酒业舆情较为庞杂,各业务部门、业务人员对于舆情的诉求各有所异,因此酒业舆情的处理不仅仅是对于酒业相关舆情的获取,更需要将酒业舆情结合酒企的业务场景,为其提供高效的分主题舆情,使得各业务主体均可通过酒业舆情快速定位业务问题,为企业相关业务的开展提供充分的外部决策数据,给业务部门提供参考与指导。本次研究的酒业舆情信息涵盖了从百度贴吧、搜狐、新浪微博、腾讯、凤凰网、网易、知乎、同花顺、微信、今日头条、人民网、宜宾零距离、央视网、新浪、东方财富网多个渠道所获取的关于五粮液、茅台、古井贡、洋河、泸州老窖、剑南春6 个相关酒企的新闻、博客和帖子。
针对此而基于大数据开发的酒业舆情信息监测平台,能够实时采集酒企及主要竞争对手在主流社交媒体上的酒业舆情信息,整理分类为“营销生产”:与白酒生产、营销、白酒价格升降相关的新闻、论坛帖子、公众号文章等内容;“金融投资”:与白酒企业股票、基金、期货、投资、并购等相关的财经类内容;“公司动态”:与白酒企业人事调动、公司高层动态、公司对外合作等相关的文章;“产品讨论”:讨论白酒产品口味、真假、售价高低、包装、物流等相关的评论文章;“社会新闻”:与白酒品牌相关的贪污受贿、清扫造假窝点、行业宣传活动等相关报道文章;“行业动态”:讨论整个白酒行业的评论性文章,白酒行业数据解读类文章以及文章评论,并分析相关网帖、事件,判断新闻情感倾向,跟踪事件发展趋势、事件热度并实时预警,从而帮助酒企全面了解自己及竞争对手在网络媒体上的舆情动态,为制定品牌形象优化策略提供指引,提前把握紧急事件。
1 基于大数据的酒业舆情信息监测平台架构
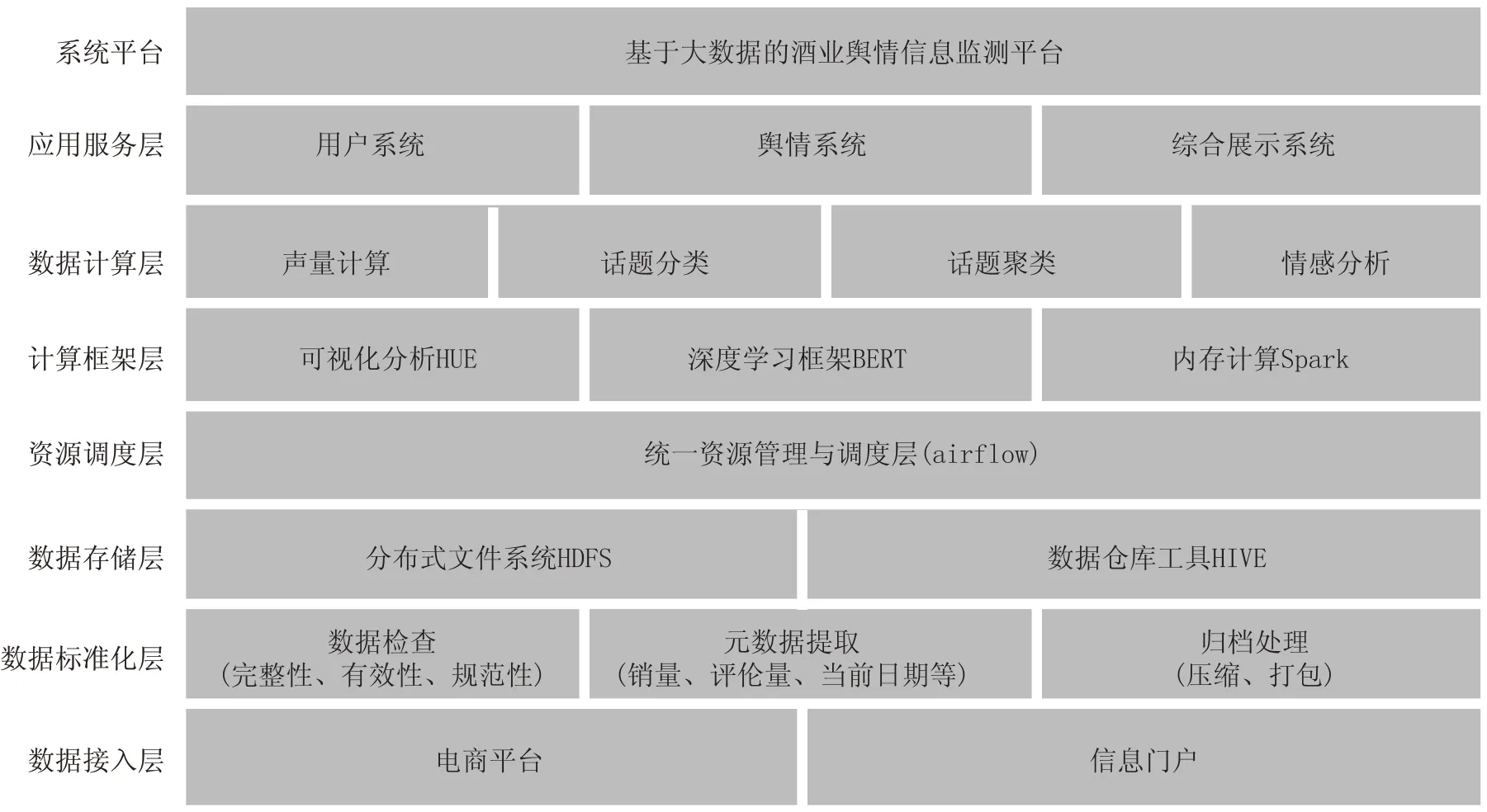
图1 平台框架图
本平台能够对五粮液及其竞争品牌的电商销售数据与舆情数据进行采集与分析,分别监控各酒类品牌的电商销售、渠道营销、用户评价以及舆情口碑情况,帮助五粮液全面地了解线上市场、竞争对手、用户偏好以及实时跟踪舆论事件发展动态,从而在线上销售策略的制定、产品的渠道投放和用户口碑建设等方面,为五粮液提供基于大数据的支撑和指引。平台共分为7个层次,框架如图1所示。
数据接入层包含酒企电商销售数据及舆情数据,采用基于Redis的增量式爬虫,接入天猫、京东、酒仙网等各大电商平台,以及微博、微信公众号、东方财经、同花顺等各大社交媒体和信息门户,每小时定时爬取数据,并将其自动导入系统。数据标准化层检查数据接入层获取数据的完整性、有效性和规范性,并对其做元数据提取等预处理操作。数据存储层利用分布式文件系统HDFS 和数据仓库工具HIVE对各类数据实现高效存储。资源调度层采用airflow,对各层内部、层与层之间,统一进行资源的管理与调度。计算框架层主要包含可视化分析、深度学习框架和大数据计算框架,为平台提供算法支撑。数据计算层根据具体需求对预处理后的数据进行分类、聚类、情感分析等。应用服务层用于建立和维护用户管理系统、舆情系统、综合展示系统,真正实现可视化舆情信息并实时告警功能。
2 主要功能模块介绍
平台每小时自动爬取网络数据,并利用数据预处理模块对原始数据进行数据清洗和特征提取,得到处理好的待分类数据,每条数据称为网帖。利用分类模块对网帖数据进行分类,将网帖分为6 个类别。在每个类别内部,利用聚类模块进行聚类,每个聚类结果称为一个事件。最后利用声量计算和情感分析模块,根据热度计算每个网帖的声量,并对其进行情感分析,确定网帖的正负情感倾向;将每个事件下所有网帖声量之和作为事件的声量,统计事件下网帖正负情感倾向,得到事件的情感正负向占比。数据处理流程如图2所示。
2.1 数据预处理
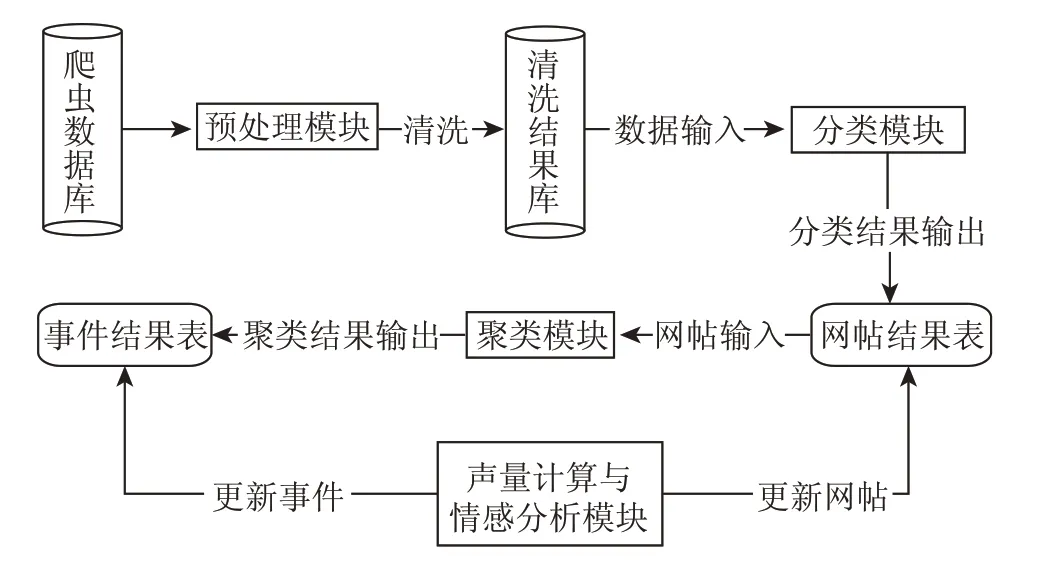
图2 数据处理流程
网帖指舆情新闻话题,由属性和文本两部分组成,其中属性包括时间、酒企标签、转发量、浏览量、声量、情感正负向等,文本包括标题和正文文本。属性用于计算声量及平台前台按条件筛选展示网帖,文本数据用于网帖分类、聚类及情感分析。平台直接从网络中获取的网络数据分散、零乱、标准不统一,需要对其进行数据清洗和元数据提取。首先,以五粮液、泸州老窖、洋河、茅台、剑南春、古井贡为正则化规则,剔除原始数据库中与六大白酒企业无关的网帖。另外,剔除微博数据中,标签大于3或者以http开头的网帖;剔除微博粉丝数少于200的微博用户发布的网帖数据;剔除标题中出现“小说”“故事”短语的网帖数据。由于网络数据中可能包含大量的CSS、HTML 等特殊字符,影响后续数据处理的准确性,所以再次利用正则匹配的方法,剔除网帖中的无关成分;对于没有标题的数据,用文本的前十位进行填充。对清洗后的数据进行元数据提取,更新网帖属性和文本对应字段。最后,将处理好的数据压缩,并存入清洗结果数据库中。
2.2 网帖分类
Bert 模型[3]是Google 公司于2018 年发布的一种新的语言编码模型,它在ELMO[4]、Word2Vec[5]等模型的基础上,采用双向语言模型进行预训练,使用Transformer[6]代替循环神经网络或卷积神经网络作为特征提取器。Bert 模型一经提出,就在11 个NLP 任务上刷新了记录,它具有非常好的效果和很强的普适性,只需要预训练和微调,就能将Bert 模型应用到不同的任务上。Bert-Base,Chinese 模型是Google 在原始Bert 模型基础上预训练的中文文本分类模型,在使用过程中,只需要再对其进行微调,就能得到非常好的结果。
经过对酒业舆情数据和舆情诉求数据的分析,得知酒企重点关注的业务领域如下:自身及竞争产品在营销生产方面的动态与市场反应、行业企业的投资并购金融近况、企业内部运营变动情况、行业突发紧急舆情、行业评论文章与网民态度。因此,本平台将酒业舆情进行主题舆情分类,并对分类结果进行聚类,以更好地为酒企提供舆情服务。根据以上需求,我们通过人工标注的方式,将10000 条网帖分为营销生产、金融投资、公司动态、产品讨论、社会新闻、行业观察六个类别,用这些标注后的样本对Bert-Base,Chinese模型进行微调,得到能够满足酒业舆情分类需求的分类模型。利用该模型,将所有输入的未分类网帖分为对应类别,并自动更新网帖属性中对应的类别字段。
由于模型以字为粒度对文本进行切分,不需要任何分词、去停用词和词嵌入操作,将清洗后的文本截取前200 个字直接送入模型,就可以得到分类结果。
在与传统的分类模型对比发现,平台使用的模型分类准确率能够提升7%。可见,我们选择的模型,不仅能够缩减分类步骤,减少分类所需时间,同时也能够提高分类准确率。
2.3 网帖聚类
使用网帖分类模块将网帖分为6 个类别后,每类别中包含的网帖可能与某一相同事件有关,将这样具有相似性的网帖聚类成相同事件,有助于更加直观的描述现实中的舆情事件。网帖包含我们将网帖文本字段分词后得到文本词语集合,利用doc2vec[7],将每条网帖数据分词后的词语集合嵌入到300 维的文档向量。使用single-pass[8]计算两个网帖向量的余弦相似度。
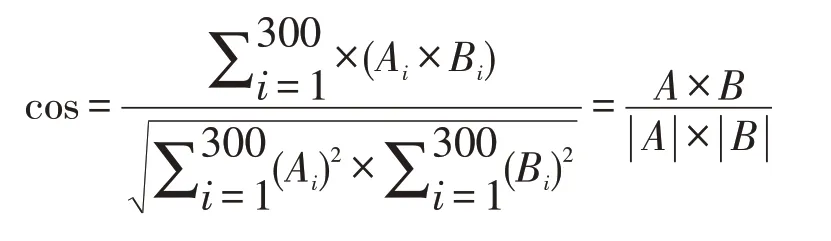
式中:A、B 表示A 网帖和B 网帖的文档向量。将余弦相似度0.75 作为阈值,当cosθ大于0.75 时,将A、B 网帖聚为一个类别。事件包含的ID、声量和正负向占比等字段。用不同ID 表示不同的事件,一个事件下的网帖有相同ID。对于已有事件,将事件中所有的网帖的文档向量取均值作为该事件的聚类中心向量。对于每天新增的网帖,将计算其与已有事件的余弦相似度。当余弦相似度大于阈值时,网帖归属于余弦相似度最大的事件下,并更新当前事件的中心向量;当余弦相似度小于阈值时,生成新事件ID,将新增网帖归为此事件,且该新事件的聚类中心为网帖的文档向量。
2.4 声量计算与情感分析
舆情平台关注媒体热度高、群众关注度高的网帖,该类网帖是非常重要的舆情信息。本平台中,用声量来衡量网帖的热度,作为舆情热度指标,以声量的变化来描述现实生活中舆情热度的变化,并为平台提供舆情监控和告警设置提供衡量标准。声量(volume)定义如下:
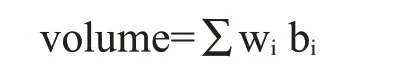
式中:bi指评论数、点击数、喜爱数、收藏数、转发数5 个网帖的相关信息,wi指bi对应的权值,分别为0.3、0.2、0.2、0.1、0.2。
通过声量公式直接计算网帖的声量,用事件中所有网帖的声量之和作为事件的声量。每次更新数据时,同时计算网帖的声量增量和事件的声量增量,并更新网帖和事件相应字段,以便于画出舆情的声量走势图。对于连续7 天内,网帖数量增量或网帖声量增量为0 的事件,将其设置为停止事件,不再对其进行关注。
此外,了解网帖的正负情感倾向,有助于了解其是正向舆情还是负向舆情,掌控舆情发展状况。故平台实现了对网帖的情感分析,并对事件中网帖的情感倾向进行统计,得到事件的正负情感倾向占比。我们将原始网帖数据分词并去停用词后,基于正负情感词词库,匹配网帖词语集合中的所有词语。网帖初始情感值设为0,匹配到正向词语时情感值做+1 操作,匹配到负向词语时情感值做-1 操作。匹配完所有网帖词语后,得到最终的网帖情感值,对其进行sigmoid 平滑处理。当处理的平滑值大于0 时,网帖情感倾向为正向,否则为负向。情感倾向示意图如图3所示。
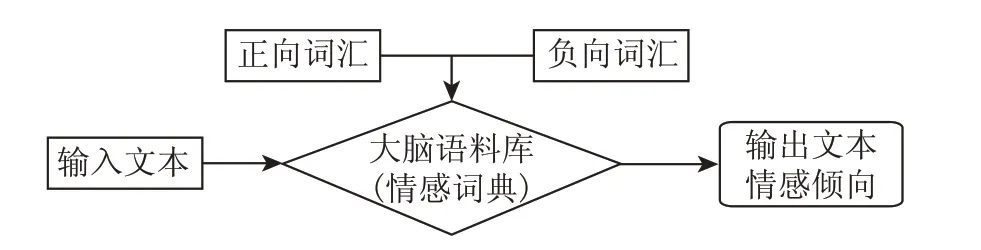
图3 情感分析流程图
事件不区分具体情感倾向,对事件中所有网帖情感倾向做统计,得到事件的正负情感倾向比例,用该比例描述事件的性质。当正向网帖占比较大时,认为该事件属于正向事件;当负向网帖占比较大时,认为该事件属于负向事件。
3 平台展示
平台能够实时采集酒企及主要竞争对手在主流社交媒体上的舆情信息,分析识别相关网帖、事件,判断新闻情感倾向,跟踪事件发展趋势、事件热度并实时预警并根据其整理出舆情统观信息。
舆情统观功能利用每日在“腾讯”“搜狐”“网易”等新闻门户网站,“百度贴吧”“今日头条”“知乎”等论坛,“同花顺”“东方财富”等财经类网站,新浪微博等社交网站渠道收集的中国酒业舆情网帖信息(图4),利用Bert 分类与情感倾向词汇统计分析并动态展现每日网帖声量走势,横向对比各渠道网帖数量及正负向情绪占比。
该功能直观的展现了酒类品牌网帖的实时声量走势,讨论热度,情绪正负向占比及热议关键词。为酒企舆情监测,突发事件公关提供详细数据指导。
平台每日监控新闻类、论坛类、微博类等社交平台及媒体渠道,实时采集“五粮液”“茅台”“泸州老窖”等中国酒业代表品牌相关的舆情网帖,统计各个网帖产生的舆情声量。声量大小体现了网帖的舆情热度,图5 展示了2019 年6 月声量靠前的部分网帖,可见“张艺兴,迪丽热巴在五粮液生产间”网帖声量大幅高于其余网帖,也体现了明星相关网帖热度往往高于一般网帖,对企业的推广有着积极的效果。
同时,对各个渠道所获取的网帖,平台会分析网帖的情感正负向,统计网帖在一天、一周、一月的时间内的数量并根据渠道来源展示其网帖的情感正负类,展示结果见图6。
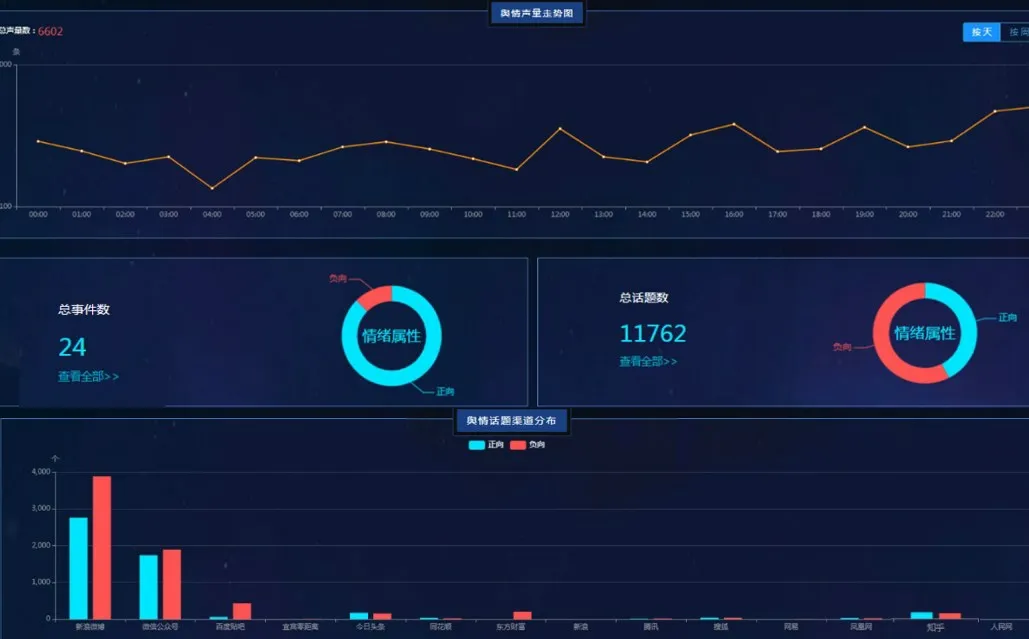
图4 中国酒业舆情网帖声量走势及渠道分布
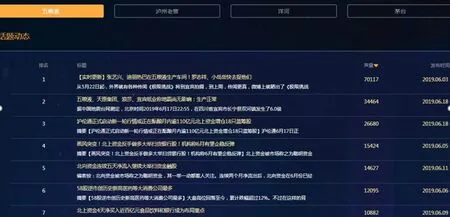
图5 当月中国酒业舆情事件及事件声量

图6 中国酒业舆情渠道及正负向网帖数量占比
对于事件与网帖,平台会利用每日的新闻数据统计与分类跟踪其声量走势,以便酒企直观的查看其对舆情造成的影响。也可查看具体网帖及其声量走势。图7 展示了根据网帖聚类后所形成的事件“一吨新酒加一勺老酒就是陈酿,企业受到起诉”的前5 网帖及其事件舆情声量近一个月的走势。可见该事件一出现便引起了社会的广泛关注,然后在一月时间内讨论热度持续下降,但仍有一定的关注度。
告警系统如图8 所示,可设置事件热度阈值和通知方式及人员,阈值以每天的网帖数量,每天的声量,每天微博大v 的博客数量来设定。对于热度超过设定值的事件,平台会向指定的相关人员以短信或邮件的方式发起告警,以及时做出处理紧急事件。
4 讨论与总结
该平台运行近一年来,在处理重大舆情事件的过程中,充分体现了快捷、高效、准确的优势。面对突发事件,舆情平台可以帮助酒企及时的获得消息,及时地做出处理,以免事件发酵,造成更大的舆论影响,网络舆情监控对于了解社情民意,缓解舆论压力具有重要作用和意义;同时,在辅助决策方面,平台提供了完整的统计信息,为酒企制定未来规划提供了参考。

图7 网帖详情与其单月内声量走势
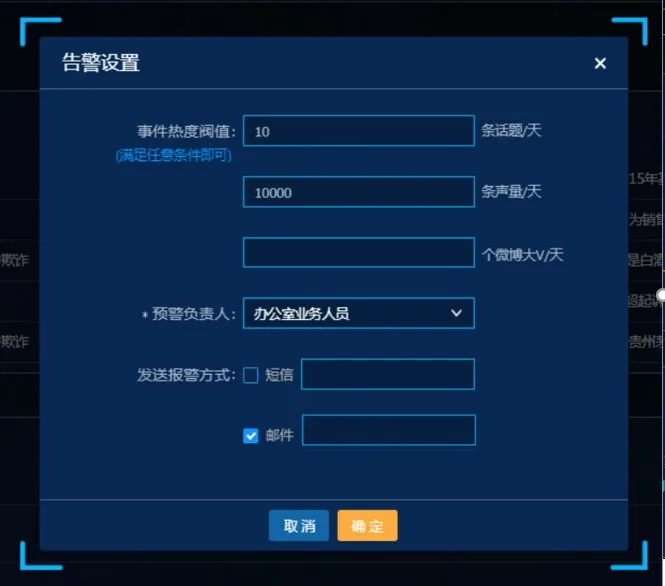
图8 事件告警系统
在平台的进一步优化方面,可以通过深化和丰富互联网舆情基础理论,不断修正模型;通过理论和实践的相互促进,提升互联网舆情监测分析基础模型的科学性,优化完善互联网舆情监测分析系统。另一方面,在对大量网络舆情事件开展测试应用,可以利用随机森林进行分析,使平台能够自动确定或推荐事件声量的合理告警阈值,加强平台的自动化性能。
猜你喜欢
今日农业(2022年15期)2022-09-20
北京航空航天大学学报(2022年8期)2022-08-31
华人时刊(2022年3期)2022-04-26
酿酒科技(2021年10期)2021-11-28
酿酒科技(2020年6期)2020-12-18
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
