
基于GA-ELM模型的我国天然气进口预测
2020-06-03 07:17李宏勋宫本璞
河南科学 2020年4期
李宏勋, 宫本璞
(中国石油大学(华东)经济管理学院,山东青岛 266580)
化石能源如煤炭、石油的大量使用给人类社会的发展带来很多问题,诸如日益严峻的环境污染、碳排量增多导致的全球变暖等. 许多国家已经意识到,转变能源消费方式建立低碳清洁的能源消费结构势在必行. 我国作为一个能源消费大国,应在世界能源结构转型进程中起到表率作用.《能源发展“十三五”规划》明确提出,建立清洁低碳、安全高效的现代能源体系,是能源发展改革的重大历史使命[1]. 而天然气作为一种清洁能源,将在能源结构转型中发挥重要的桥梁作用[2].
在天然气的储量方面,世界天然气资源丰富,但是区域分布很不均匀,中东、欧洲及欧亚大陆的天然气储量占全球总储量的73%[3],这为我国天然气进口带来了很大的压力. 同时,虽然我国的天然气储量居于世界前列,但受开采技术和成本的限制,很多天然气无法开采,再加上我国人口基数大,国内天然气的供应难以满足天然气的需求.
在天然气进口量方面,2010年我国天然气进口量为165亿m3,2018年增长到1215亿m3,是2010年的7倍多;天然气进口依存度也从2010年的15.3%增长到2018年的42.9%[4]. 国际能源署(IEA)发布的《2018天然气分析及预测报告》对未来五年全球天然气市场的发展进行了预测,预计2019年中国将成为世界最大的天然气进口国[5].
在天然气的能源消费占比方面,2018年中国天然气消费占一次能源消费的比例为7.4%,与世界平均水平(24%)相比我国天然气占一次能源消费的比例还很低,未来天然气的国内需求还有很大的增长潜力[4].综上所述,进口天然气对于满足国内天然气的需求就显得至关重要.
1 文献回顾
通过查阅现有相关文献资料,笔者从天然气预测指标、天然气预测方法和天然气进口研究现状三个方面对现有文献进行梳理.
天然气预测指标体系的构建是一个不断丰富发展的过程. 在完善的预测指标体系尚未建立时,Li等运用情景分析的方法分析了中国各部门天然气的消费现状和趋势变化情况,认为GDP和人口数量是天然气消费的主要影响因素[6],认为GDP和总人口是中国天然气消费量的核心影响因素,在对天然气消费量进行系统的分析时必须考虑这两个因素的变化. 李君臣等的研究为天然气预测指标的后续发展奠定了重要基础,后来的研究也都将经济发展水平和人口作为天然气需求的重要影响因素[7]. Zhang等认为影响中国天然气消费的因素包括GDP、城镇化率、能源效率、能源消费结构、产业结构和商品的出口贸易[8]. Chai等通过实证研究,确定了天然气消费与影响因素之间的关系,使用LMDI分解影响因素,将影响因素分为经济发展指标和清洁指标[9]. 目前为止,天然气的预测指标主要可以划分为四类:经济发展指标、人口指标、工业指标和能源消费指标.
传统的天然气预测采用的方法以灰色模型、Hubbert模型和OLS模型等方法为主[10~12]. 比如,Lifeng等使用一种新型灰色系统模型,基于不完整的信息,通过对较近的数据分配较高的权重来提升灰色系统模型的预测精度,并使用这种改进灰色模型预测了2014—2018年中国的天然气消费量[13];Zhang等认为贝叶斯模型平均法可以计算后验概率,能够解决模型的不确定性问题,且比灰色预测模型和人工神经网络等常用模型有更好的预测效果,并使用贝叶斯模型平均法预测了中国天然气的消费量[8];Shaikh等通过对数几率回归分析预测了中国天然气需求[14]. 这些传统的预测方法能够较好地解释变量与结果之间的关系,在以往的天然气预测研究中得到了广泛的应用.
传统的预测方法对变量之间以及变量和结果之间的关系具有较好的解释性,但是预测的精度较低,并且需要大量的数据样本作为支撑. 随着人工智能的兴起,越来越多的智能算法被用在天然气预测的研究中. 智能算法与传统的预测方法相比,具有预测精度高、自适应和动态学习的优点,更加适用于动态的能源需求预测. 在智能算法用于天然气预测的初期,使用的模型大多是BP神经网络模型或支持向量机模型等单一算法模型,如Szoplik等使用神经网络模型[15]、Bai等使用支持向量机[16]分别建立了天然气消费预测模型来预测短期内天然气的消费量;随着智能算法在预测领域应用的日益广泛,国内外学者们发现将不同的算法之间进行组合优化能够得到更精确的预测结果,如Deyun 等构建了基于粒子群优化算法和小波神经网络(PSO-WNN)的混合预测模型,利用PSO算法优化初始权重和小波参数,并通过更新动态学习率提高训练速度和预测准确性,并减少了WNN波动,分析了影响我国天然气消费的主要因素[17];Karadede等使用种群遗传算法和基于非线性回归的种子混合算法的模拟退火算法,以非常小的误差预测了天然气消费量[18];De等对传统的AdaBoost 算法进行改进,使用PSO 算法对ELM 模型的输入权值和阈值进行优化,并以此作为AdaBoost的弱预测器,构建AdaBoost-PSO-ELM模型,预测了未来十年我国天然气需求量[19].
在天然气进口研究方面,近几年进口天然气在我国天然气消费中占有很高的比重,目前针对我国天然气进口业务的研究大多集中在天然气进口的空间布局、价格研究以及供应安全等方面. 例如,孙聆轩等综合运用多个空间布局指标,定量分析了我国天然气进口空间格局的演进及优化情况,发现我国天然气进口空间布局的很多方面与日本、韩国还存在差距,从比较优势、治理安全的角度提出了中国天然气进口空间格局优化的方向[20]. 对于进口价格的研究有很多不同的角度,邹莉娜等建立了能综合考虑天然气储备对进口量和国内价格水平影响的模型,探讨了出口国垄断能力和进口国的供应中断风险厌恶程度对最优稳态储备规模、进口规模、国内天然气价格水平的影响[21];殷建平等通过建立静态和动态计量经济学模型,对我国液化天然气(LNG)进口价格与国际原油价格之间的关系进行实证研究,得出了“二者在长期内存在稳定均衡关系”的结论,并对我国天然气定价机制及相关进口贸易提出了一些合理的建议[22]. 除此之外,还有学者从原油价格波动、出口国偏好等角度分析对进口价格进行研究. 此外,供应安全问题也是天然气进口的一大研究热点,近年来中国天然气对外依存度快速增长,在天然气进口的过程中会面临各种风险,董秀成等以供应链为基础,构建了中国天然气进口风险指标体系,使用熵权法计算指标权重,计算了中国2011—2014年从不同国家进口天然气的风险,认为我国天然气进口风险总体呈上升趋势,应从优化进口来源、加强运输通道安全、扩大海外开发投资、培养自给能力等四个方面着手,降低进口的风险,从而保证天然气供应的持续性和稳定性[23].
不难看出,天然气预测领域的研究十分丰富. 起初,研究主要集中在探索天然气需求的影响因素,研究的重点是确定天然气需求的核心影响因素,构建起科学合理的天然气预测指标体系;后来随着研究进程的逐渐深入,研究的重点逐渐转移到对天然气需求量的预测,试图寻找到一种可以准确预测天然气需求量的方法. 然而过往的预测研究主要集中在天然气需求和消费方面,针对天然气进口量预测的研究较少. 随着我国天然气消费的逐年增长,天然气进口对外依存度逐年攀升,进口天然气在我国的天然气消费中占有很高的比重,对天然气进口量进行准确预测,对于保证我国天然气供应安全、满足国内天然气消费需求有着重要的意义.
2 模型构建
2.1 随机森林模型
随机森林是一种应用非常广泛的数据挖掘算法,随机森林算法具有评估变量特征重要性的功能,也是本文使用的一种功能. 变量的特征重要性数值越高,则表明该变量对结果的影响越显著. 用随机森林进行变量特征重要性评估的思想比较简单,主要是看每个特征在随机森林中的每棵树上做了多大的贡献,计算它们的基尼指数然后取平均值,比较不同特征之间的贡献大小. 具体步骤如下.
步骤1 计算不纯度减少量.

其中:N 表示未分离的节点;NL和NR表示分离后的左侧节点和右侧节点;Wi为样本的类权重;ni表示节点内各类样本的数量;∆i 是不纯度减少量,该值越大表明分离点的分离效果越好.
步骤2 通过计算基尼值评价各个变量的特征重要性.

得到每个变量在各个节点上的基尼值取平均值,结果可作为变量的重要性评分,然后对各个变量进行重要性排序.
2.2 ARIMA模型
ARIMA模型(Autoregressive Integrated Moving Average model),即差分整合移动平均自回归模型,又称整合移动平均自回归模型,是时间序列预测分析方法之一. ARIMA(p,d,q)中,AR是“自回归”,p为自回归项数,MA为“滑动平均”,q为滑动平均项数,d为使之成为平稳序列所做的差分次数(阶数).
ARIMA(p,d,q)模型是ARMA(p,q)模型的扩展. ARIMA(p,d,q)模型可以表示为:

其中L 是滞后算子,d ∈Z,d >0 .
使用ARIMA模型的流程如下所示.
步骤1 根据时间序列的散点图、自相关函数和偏自相关函数图识别其平稳性.
步骤2 对非平稳的时间序列数据进行平稳化处理. 直到处理后的自相关函数和偏自相关函数的数值非显著非零.
步骤3 根据所识别出来的特征建立相应的时间序列模型. 平稳化处理后,若偏自相关函数是截尾的,而自相关函数是拖尾的,则建立AR模型;若偏自相关函数是拖尾的,而自相关函数是截尾的,则建立MA模型;若偏自相关函数和自相关函数均是拖尾的,则序列适合ARMA模型.
步骤4 参数估计,检验是否具有统计意义.
步骤5 假设检验,判断(诊断)残差序列是否为白噪声序列.
步骤6 利用已通过检验的模型进行预测.
2.3 GA-ELM算法
由于我国天然气进口时间短、数据量少,使用简单的极限学习机(ELM)模型并不能取得很好的预测效果,我们使用遗传算法(GA,Genetic Algorithm)对极限学习机的隐藏层节点数、输入权值和隐藏层偏差优化,能够加快ELM模型收敛的速度,从而能够在数据样本少的情况下提高训练速度和预测精度.
使用遗传算法优化ELM的基本步骤如下.
步骤1 确定神经网络的拓扑结构,对神经网络的权值和阈值编码,得到初始种群.

式中:Qγ为种群中第γ 个个体,1 ≤γ ≤k;wij、bj在区间[-1,1]中随机取值.
步骤2 解码得到权值和阈值,将权值和阈值赋给新建的ELM网络,使用训练和测试样本训练和测试网络. 对网络设置目标函数为:

式中:n为预测时刻点的个数;yi(k)为k时刻的真实值为k时刻的预测值.
步骤3 确定适应度函数、种群规模k以及进化代数P. 适应度函数用于评价个体的优劣程度,适应度函数采用排序方式的适应度分配函数:Fitness-V=ranking(obj),其中obj为目标函数的输出.
步骤4 局部求解最优适应度函数Fitness-best. 进化代数θ 及种群个体γ 的初始值设为0,逐个求解每个个体对应的适应度函数,直到y=k 时结束循环,求得Fitness-best 值,即从中选出最优个体.
步骤5 全局求解最优适应度函数Fitness-best. 每进行一轮局部求解最优适应度函数后,利用交叉、变异对种群进行进化,并检查进化代数θ 值. 当θ 不大于P 时,将γ 值初始化为0,返回步骤4,直到θ >P 时结束运算,此时计算出的Fitness-best 即为最优适应度函数,根据其对应的参数并解码,即可得到最佳神经网络的权值和阈值,进而确定优化的ELM模型.
3 我国天然气进口预测
3.1 确定天然气进口的影响因素
到目前为止,完善的天然气进口预测指标体系尚未构建完成. 本文在借鉴了De G等构建的天然气需求预测指标体系基础上,考虑了地缘政治[24]、进口依存度[25]对天然气进口的影响,选取了GDP、城市人口数量、人均生活消费(人均每年用于各项生活消费上的支出)、能源消费结构(化石能源在能源消费中的占比)、工业结构(第二产业增加值占GDP 的比重)、家庭平均能源消费(家庭平均每年用于能源消费的支出)、对外依存度、地缘政治作为天然气进口的影响因素,其中地缘政治因素指标的确定借鉴了ECN(2004)提出的一种香农多样性指数的计算方法[26],使用随机森林算法[27]评估上述八个因素的特征重要性,指标的筛选标准是特征重要性大于0.1,图1 中前六个指标的特征重要性大于0.1,可以作为模型的自变量. 分别是地缘政治(x1)、能源消费结构(x2)、人均生活消费(x3)、对外依存度(x4)、工业结构(x5)、GDP(x6) .本文数据来源于《BP世界能源统计》和《中国能源统计年鉴》,具体数据如表1所示.

图1 天然气进口影响因素的特征重要性Fig.1 Characteristic importance of influencing factors on natural gas import
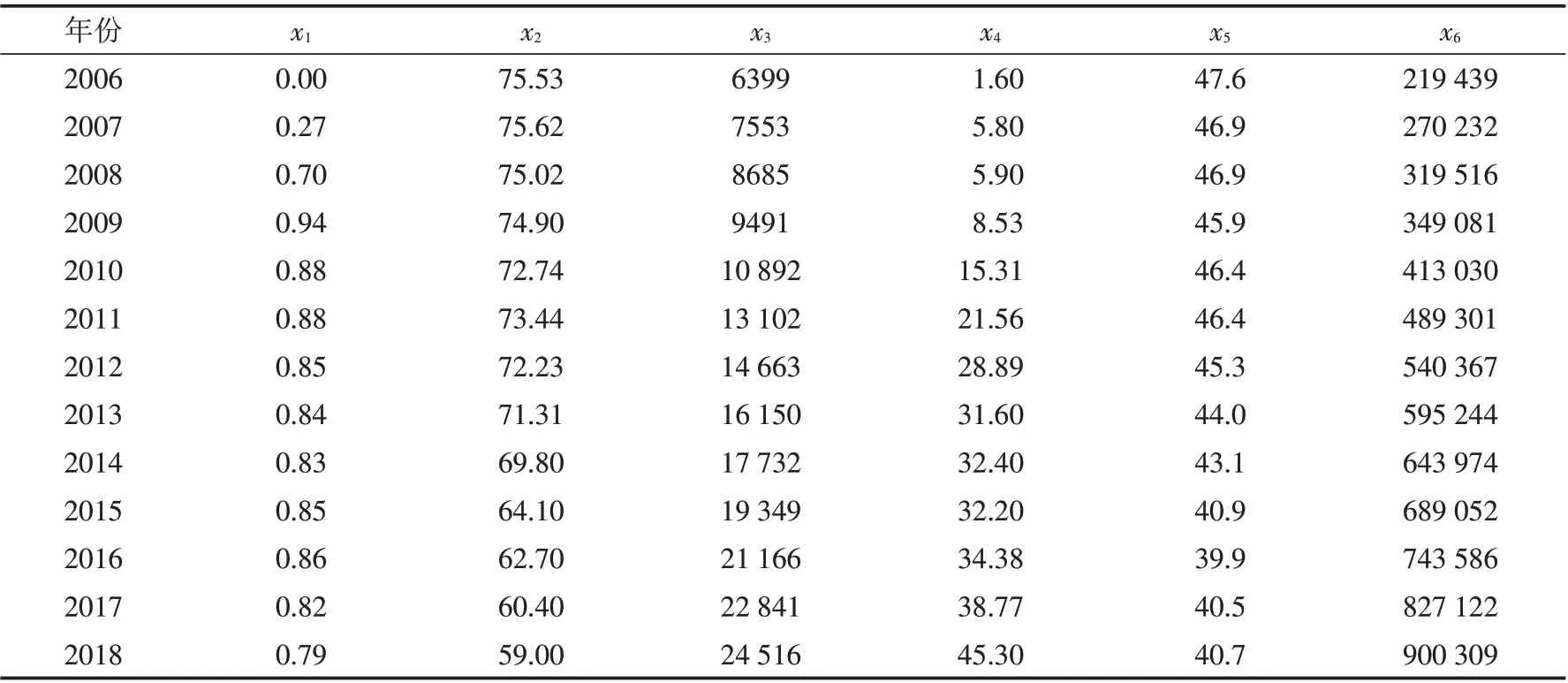
表1 2006—2018年影响因素的历史数据Tab.1 Historical data of influencing factors during 2006-2018
由于官方尚未公布2018年人均生活消费的具体数值,本文根据2016、2017年的数据对2018年的数据进行估计. 通过均值插补法计算得到2018年的人均生活消费的预测值.
3.2 自变量预测
将自变量数据代入不同的ARIMA 模型中进行拟合,选取拟合效果最好的模型对各个自变量2019—2028年的数值进行预测,结果如表2所示.
根据表2的预测结果,地缘政治因素在未来十年内呈波动上升的态势;能源消费结构逐年下降;人均生活消费逐年增加;天然气对外依存度逐年上升,预计在2020年之后天然气进口对外依存度超过50%;第二产业增加值占GDP的比重逐年减少,工业结构指标逐年下降;GDP总量预计逐年增长,但是增长速度会逐年放慢.
3.3 预测结果及分析
为了避免各参数取值范围差异较大给预测结果带来影响,本文在预测时对所有数据进行归一化处理.仿真实验在PC上进行,运行环境为:Intel(R)Core(TM)i5-4210 2.4 GHz处理器,8 GB内存,Win8 64位操作系统,运行平台为Matlab 2018b. 选取自变量2006—2015年的数据作为模型的训练集,2016—2018年的数据作为测试集. 为了增强实验结果的说服力,本文对模型训练了30次,并计算出30次对测试集预测结果的误差的平均值. 误差分析结果如表3所示.
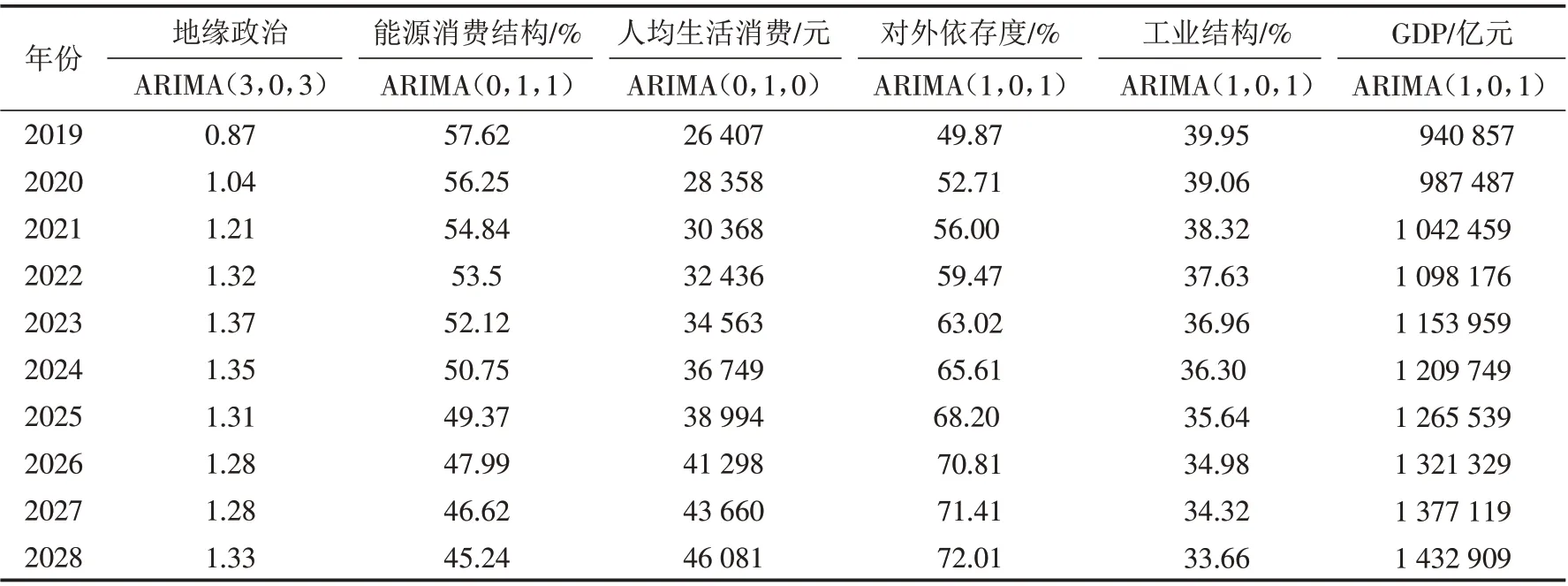
表2 2019—2028年影响因素的预测值Tab.2 Predicted values of influencing factors during 2019-2028

表3 结果误差Tab.3 Result error
不难看出,虽然受到数据样本数量的限制,但经过遗传算法优化后的极限学习机模型的样本拟合度和精确度相比单纯的极限学习机模型提高了很多,模型拟合优度R2达到0.999以上,MSE(均方误差)、MAE(平均绝对误差)、MAPE(平均绝对百分比误差)等误差指标大幅度降低,说明遗传算法对极限学习机(ELM)模型的优化效果十分明显.
将自变量的预测值代入到训练好的GA-ELM模型中后,我们得到了2019—2028年中国天然气进口量的预测值,如表4所示.

表4 未来我国天然气进口量预测值Tab.4 Predicted value of China’s natural gas import in the future
从表4预测出的我国天然气未来的进口趋势可以看出,未来十年内我国天然气进口量还将持续增长,进口量在经历了最初几年的波动之后,呈逐年上升的趋势. 天然气进口的增长速度在2019年最快,随后会逐年下降,2022年以后,天然气进口增长速度趋于平稳.
4 结论
本文提出了一种基于GA-ELM集成学习的天然气进口预测模型,该模型使用遗传算法优化了ELM隐藏层的节点数、输入权重和阈值. 使用随机森林算法提取了中国天然气进口的核心影响因素并作为预测模型的自变量,使用ARIMA模型对自变量未来的变化趋势进行预测. 得到如下结论.
1)使用随机森林算法计算各要素的特征重要性,选取特征重要性最高的六个影响因素作为预测模型中的自变量. 通过计算特征重要性,我们发现地缘政治因素对天然气进口量的影响最大,主要原因可能是天然气进口协议是在国家层面签订的,而国家之间的地缘政治关系影响着天然气进口协议的签订和履行. 其次是能源消费结构,我国能源消费总量大,能源结构向着低碳化、清洁化的方向调整,会对天然气进口需求产生相应的影响. 此外,对外依存度、工业结构和经济发展水平等因素对天然气进口量也存在显著影响.
2)使用遗传算法优化ELM模型的阈值和隐藏层权重可以加快收敛速度、减少训练样本和训练次数,可以有效提高模型的预测性能. 比较GA-ELM 和ELM 模型的R2、MSE、MAE、MAPE 值,证明了遗传算法对ELM模型的优化效果十分明显,使用GA-ELM 模型以及ARIMA 模型对2019—2028年中国天然气进口量以及核心影响因素的变化进一步预测. 结果表明,本文提出的GA-ELM集成学习模型对于天然气进口量的预测是有效的,能以较高的精度预测未来天然气进口量的变化,为后续相关研究提供参考.
3)预测结果表明未来十年内我国天然气进口量还将持续增长,天然气进口的增长速度在2019年达到顶峰,随后几年里快速下降,并在2022年之后趋于平稳.
天然气进口量的变化是复杂多样的,本文使用的预测方法并不一定能准确预测实际的天然气进口量,但有可能掌握天然气进口的增长趋势,为我国天然气进口计划以及天然气产业相关政策的制定提供参考,帮助政府提前对天然气市场中可能出现的问题进行干预,以平衡市场中可能出现的矛盾,为天然气产业的健康发展提供理论依据.
猜你喜欢
合成纤维工业(2022年3期)2023-01-02
中国化肥信息(2022年9期)2022-11-25
中国化肥信息(2022年9期)2022-11-25
今日农业(2022年14期)2022-11-10
合成纤维工业(2021年2期)2021-01-09
合成纤维工业(2021年3期)2021-01-07
小学科学(学生版)(2020年5期)2020-05-25
小学科学(学生版)(2019年11期)2019-12-09
能源(2018年10期)2018-12-08
能源(2018年8期)2018-01-15
