
基于SDN 的互联网域间路由研究*
2020-06-08 10:08何晓明刘宁芳陈文华
通信技术 2020年5期
何晓明,刘宁芳,陈文华
(中国电信股份有限公司广东研究院,广东 广州 510630)
0 引 言
边界网关协议(Border Gateway Protocol,BGP) 作为互联网基石的网间互联协议,已经把全世界所有大大小小的网络互联在一起,形成通达全球的Internet。BGP 用于在不同自治系统(Autonomous System,AS)之间交换路由信息,实现不同AS 之间IP 可达性。随着互联网流量的爆发式增长,网络扩容总是滞后于流量增长速度,网络资源捉襟见肘。网络需要为高价值业务提供更好的传输服务,在保持效率优先的同时,还能够体现出互联网服务的普惠性和公平性,而传统互联网“尽力而为”的服务模式难以兼顾两者之间的平衡。与此同时,互联网固有的流量突发性导致网络流量不均衡,表现为网络中部分链路拥塞不堪,而另一部分链路利用率低下,难以实现全网资源的最佳利用。尽管BGP可以提供灵活丰富的路由策略实现流量路径优化和负载均衡,但是由于全网设备都需要运行BGP,网络运维人员需对设备进行复杂化、个性化的配置操作,进一步增加了网络运维难度。为简化网络操作,提升网络效率,降低网络运营商的CAPEX 和OPEX,近年来SDN 技术受到网络界的追捧,全球运营商和设备提供商正积极探索利用SDN 技术实现网络运维自动化,提升网络的智能化水平,实现极简网络。
本文分析用于互联网域间路由的BGP 协议存在局限性,然后研究利用SDN 技术实现智能化域间路由,以期达到简化网络、优化全网流量、实现多出口负载均衡的目的。
1 BGP 协议的局限性分析
BGP[1-3]是运行于TCP 之上的自治系统边界网关协议,必须在交换路由更新之前协商建立TCP 连接。因此,BGP 继承了TCP 的传输可靠性和面向连接的特性。BGP 根据在BGP 邻居之间交换的路由信息建立一张自治系统图。从BGP 角度来看,整个互联网就是由自治系统组成的一张图。BGP 通告的网络层可达信息(Network Layer Reachablility Information,NLRI)可携带丰富的路径属性(Path Attribute)。其中,AS_PATH 属性包含到达该目的网络所经过的一串AS 列表,BGP 基于AS_PATH属性确保无环路的路径选择。NEXT_HOP 属性用于IP 报文转发必经的下一跳,其他如LOCAL_PREF、MULTI_EXIT_DISC、COMMUNITY 属性可由网络管理员实施BGP 路由策略,根据网间负载实际情况选择流量出、入的最佳出口,根据自治系统内部网络的链路负载情况选择最优路径等。
在一个由运营商管理的单个互联网自治系统中,网络规模庞大。例如,中国电信、中国联通和中国移动的互联网骨干网通常由成百上千台核心路由器组成,不同网络之间通过十几台自治系统边界路由器(Autonomous System Boundary Router,ASBR)进行网间互联,以实现网间流量在多出口负载均衡。充当网关设备的ASBR 之间运行EBGP协议用于交换域间路由信息,而在自治系统内部网络,路由器需要进行全网状的IBGP 连接,用于学习外部网络路由,防止产生路由黑洞。因为网内路由器数量大,全网状IBGP 连接需要消耗大量CPU处理资源,存在严重的扩展性问题,所以普遍采用路由反射器(Route Reflector,RR)[4]方式,网内路由器只跟RR 建立IBGP 连接。尽管如此,由于网内路由器需同时运行IGP、BGP 等多种路由协议,为实现全网流量工程和负载均衡,须协同IGP 和BGP 路由协议配置复杂的路由策略,使得网络的运行和维护变得十分复杂。此问,不同路由策略之间相互影响,难以达到预期的优化目标。
现以RR 优选BGP 路由为例,分析基于BGP的路径选择的局限性。
由于自治系统存在多个ASBR 出口,基于路径冗余和负载均衡考虑,对端AS 会从多个ASBR 向本AS 对应的ASBR 邻居通告相同路由信息,网内这些ASBR 邻居收到同一目的网络路由并向RR 通告。当RR 接收到属于外网同一目的地网络的多条路由时,RR 遵循标准BGP 选路原则优选唯一一条BGP路由向全网路由器反射。
这种基于RR的BGP路径优选存在以下局限性。
(1)BGP 路由选择的唯一性原则无法实现流量的多路径负载均衡。
(2)RR 基于自身到通告路由器(下一跳)的IGP 度量(Metric)值选择一条IGP 距离最近的路由,这个优选的路由与RR 所处的位置有关,并不能代表全网其他路由器到这个被选定的BGP 下一跳是最近的。RR 全网拓扑视角的缺失导致次优路由的产生。
(3)只能基于报文流目的IP 地址选路,不考虑源IP 地址或基于N元组对业务流选路。
(4)由于缺乏全局拓扑和全局流量观,无视全网资源利用情况,因此无法实现全网流量工程。
(5)RR 遵循标准BGP 选路原则,无法实现流量按照规划的路径进行疏导。
以图1 为例说明RR 选路引发次优路由问题。RR 收到来自北京ASBR 和广州ASBR 到其他运营商的同一目的Prefix 的路由,由于RR 放置位置的不同,RR 根据IGP Metric 计算自身到北京ASBR和广州ASBR 的距离,发现广州ASBR 距离自身的IGP 距离最近,于是把广州ASBR 作为该路由的下一跳向全网反射。这样带来的结果是,由北京片区的路由器转发的数据流要绕转至广州ASBR 出口,而不是最短距离的北京ASBR 出口。但是,根据实际网络拓扑,RR 应该向北京片区的路由器反射该Prefix 的路由的下一跳为北京ASBR,而向广州片区的路由器反射该Prefix 的路由的下一跳为广州ASBR。这样不仅可以实现流量的负载均衡,而且减少路径绕转,提高网络效率。
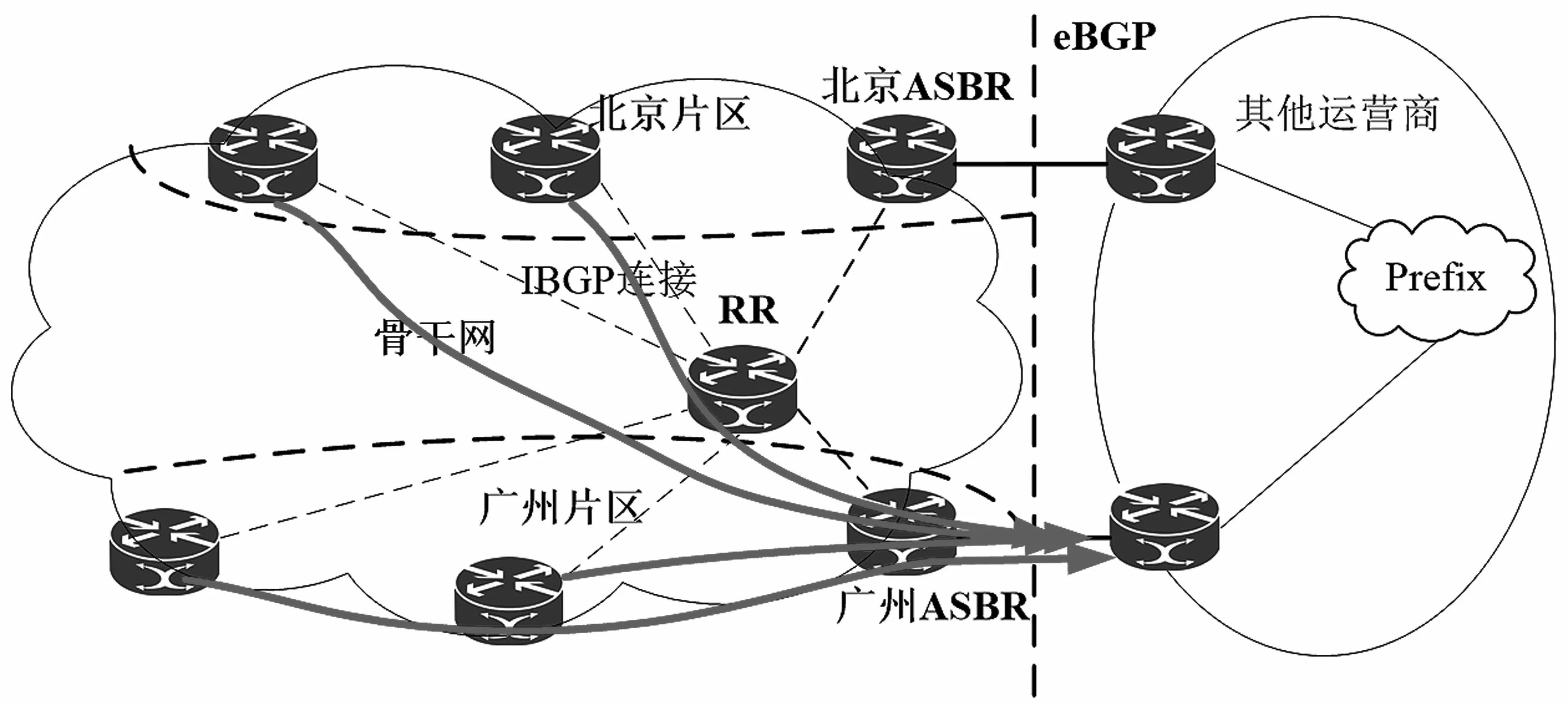
图1 RR 选路引发次优路由
2 基于SDN 的互联网域间路由
起初在制定BGP 协议标准时,主要是为了解决全球互联网跨自治域的IP 可达性及扩展性问题。随着互联网流量爆发式增长和网络规模的持续扩展,网络流量不平衡以及服务同质化现象日益突出。传统基于RR 的BGP 路径选择由于缺乏全网拓扑和全局流量观,难以实现全网流量工程,也难以为服务质量要求较高的客户提供优化路径。
SDN 具有控制和状态集中、网络控制面和数据转发面解耦以及网络可编程等特点。通过集中控制器实现全网拓扑自动发现,基于业务需求为客户提供定制化的网络服务。这种全新的网络架构带来的最大好处是集中控制器具有全局流量观和全网的资源利用视图,能实时发现各链路的带宽利用情况,因此能基于每个业务流的源、宿端位置以及QoS 需求(包括带宽、时延、丢包等),并结合各链路负载情况为不同业务流确定合适的路径。因此,SDN技术在实现流量工程和负载均衡方面具有天然优势,目前广泛部署在运营商网络和大规模云数据中心需要流量优化的场景[5-6]。
2.1 基于RR+实现互联网骨干网流量优化
针对传统RR 在BGP 路径选择存在的局限性,研究RR 实现流量调优能力,并对现有BGP 路径选择原则进行改进。借助于SDN 集中控制的思想,使改进的RR 系统(被命名为RR+)具有发现全网拓扑和实时收集全网链路流量数据的能力。同时,基于采集的Netflow 流量流向数据分析到外网的目的Prefix 所承载的流量TOP N 排名,根据网内中继链路负载情况以及域间各个出口的负载情况,在链路利用率超过阈值的流量中挑选合适的业务流,通过修改BGP 路径属性(如修改NEXT_HOP、LOCAL_PREF)等方式,把这部分流量分流到链路相对轻载的中继链路和出口,从而达到实现全网流量工程和负载均衡的目的。RR+系统如图2 所示。
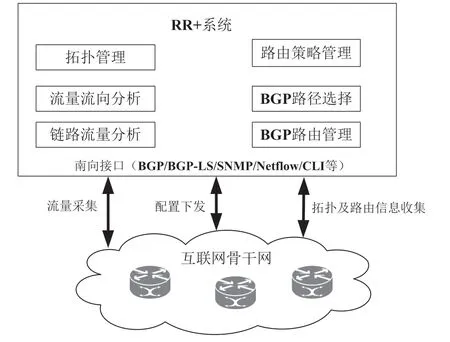
图2 RR+流量调度系统
RR+系统主要包含如下功能模块:
(1)拓扑管理。系统支持南向BGP-LS[7]接口收集全网拓扑数据,根据形成的拓扑数据库自动发现全网拓扑结构。
(2)BGP 路由管理。系统基于BGP 学习网内网外BGP 路由,包括来自多个ASBR 的相同目的网络的多路径路由[8]。
(3)链路流量分析。系统基于SNMP 收集全网链路实时流量数据,对超过链路利用率阈值的链路以及利用率低下的链路进行颜色标记。
(4)流量流向分析。系统基于Netflow 收集全网流量流向数据,生成流量流向矩阵表,并对网外目的prefix 承载流量的TOPN进行排序。
(5)BGP 路径选择。根据链路流量数据分析模块得到标记颜色的超过利用率阈值的链路、利用率低下的链路以及根据流量流向分析模块得到超过利用率阈值的链路承载外网目的prefix 流量TOPN排名,在超过利用率阈值的链路挑选相应目的prefix 的业务流分流到利用率较低的链路和出口,形成到出口的端到端优化路径。
(6)路由策略管理。根据选择的优化路径,修改相应BGP 路径属性(如NEXT_HOP、LOCAL_PREF 等)生成BGP 路由策略,向网内相关路由器通告。研发的RR+流量调优系统已部署在中国电信ChinaNet 骨干网中,实现对网内中继、网间互联出口以及IDC 出口等多场景的流量调度,达到均衡网络流量、提升服务质量的效果。
2.2 基于SDN 的互联网域间路由
尽管RR+系统丰富了互联网流量调优手段,但是全网仍需运行IGP 和BGP 等多种路由协议,配置复杂的路由策略,并未从根本上简化网络。本文提出一种基于SDN 的互联网域间路由架构,能够真正简化网络协议,降低网络运维复杂度。
在各互联网AS 内部署独立的SDN 控制器。AS域内路由器只需运行IGP 协议,无需运行iBGP 和eBGP。由各AS 域内的SDN 控制器负责域间路由信息交换,各个域内的ASBR 不再像传统方式通过eBGP 交换域间路由。SDN 控制器收集全网路由信息并相互交换各自域内的路由信息,基于收集的全网拓扑信息对域间路由进行决策控制,然后向AS内全网路由器下发域间路由的转发信息表。这样AS 内路由器对目的地址为外网的流量依据下发的域间路由转发信息表进行转发。
现以图3 为例对该域间路由架构进行描述。

图3 一种基于SDN 的互联网域间路由架构
各AS 中的SDN 控制器对收集到的网内路由进行汇总。SDN 控制器之间可以采用非常成熟的BGP 协议进行交换路由信息。图3 中AS1的控制器向AS2的控制器通告AS1的4 条汇总路由1.0.0.0/8 ~4.0.0.0/8;AS2的控制器向AS1的控制器通告AS2的4 条汇总路由5.0.0.0/8 ~8.0.0.0/8;双方通告路由时,可以选择指定下一跳信息。例如,AS1的控制器在通告的2 条汇总路由1.0.0.0/8 ~2.0.0.0/8时选择ASBR1作为下一跳,在通告的2 条汇总路由3.0.0.0/8 ~4.0.0.0/8 时选择ASBR2作为下一跳。
为实现网间流量在多个ASBR 间负载均衡,SDN 控制器根据交换得到的域间路由信息及全网拓扑视图信息,并根据监测到每条汇总域间路由承载的流量大小及多个出口域间链路的利用率情况,向全网路由器(除ASBR 外)动态下发指定下一跳的域间路由信息。
网内路由器根据IGP 最短路径把外出流量转发到一个或多个指定ASBR。网内所有路由器只需运行IGP 协议,无需运行IBGP 和eBGP 协议。同时,在所有ASBR 上配置缺省路由,出接口为网间互联接口,外出流量根据缺省路由转发到网间互联链路。假设AS1中控制器监测到AS2通告的2 条汇总路由5.0.0.0/8 ~6.0.0.0/8 承载的流量为10 Gb/s,监测到AS2通告的2 条汇总路由7.0.0.0/8 ~8.0.0.0/8 承载的流量为20 Gb/s。AS1中控制器同时也监测到ASBR1与ASBR3之间网间互联链路带宽利用率比较高,剩余带宽只能承载10 Gb/s 的流量,而监测到ASBR2与ASBR4之间网间互联链路带宽利用率较低,剩余带宽能够承载20 Gb/s 的流量。这时AS1中控制器优选ASBR1作为目的地址为5.0.0.0/8 ~6.0.0.0/8 范围内的IP 流量的出口,把域间汇总路由5.0.0.0/8 ~6.0.0.0/8向全网除ASBR 外的路由器通告(如图中R1和R2),并为5.0.0.0/8 ~6.0.0.0/8 路由指定下一跳为ASBR1。同样地,AS1中控制器优选ASBR2作为目的地址为7.0.0.0/8 ~8.0.0.0/8 范围内的IP 流量的出口,把域间汇总路由7.0.0.0/8 ~8.0.0.0/8 向全网除ASBR 外的路由器通告,并为7.0.0.0/8 ~8.0.0.0/8路由指定下一跳为ASBR2。
以上描述了SDN 控制器根据多出口链路带宽利用率情况实现外出流量在多个出口之间的负载均衡。SDN 控制器也可以根据指定路径、最短路径、最小时延等策略,为不同外网目的IP 地址的报文流指定出口路由器,无需基于BGP 路由策略这种复杂的传统技术实现多出口负载均衡。
3 结 语
互联网经历了半个世纪的发展,已成为现代社会不可或缺的关键信息基础设施,把人类文明驶向一个崭新的高度。BGP 协议把分散在全球各地的一个个孤立网络互联在一起,很好地解决了各个自治系统之间的连通性。可以毫不夸张地说,没有BGP协议就没有Internet。随着互联网流量的急剧膨胀,叠加互联网流量固有的突发性,网络流量不均衡现象日益加剧。同时,互联网上新业务和新应用层出不穷,互联网服务需要“效率优先、兼顾公平”。面对互联网新的变化趋势,传统BGP 协议也在不断完善和发展,重新焕发出新的生命力。然而,BGP不断扩展新的功能,在带给网络灵活调度的便利性同时,也增加了网络运维复杂度。SDN 技术在简化网络、实现流量工程和负载均衡方面具有天然优势,可以弥补BGP 协议的不足。针对BGP 存在的局限性,研发了基于RR+的互联网骨干网流量调度系统,并应用于ChinaNet 骨干网多个流量优化场景。更进一步,文章提出了一种基于SDN 的互联网域间路由架构,极大地简化了网络协议,并能够实现灵活的流量调度和负载均衡。后续将继续探索利用SDN技术来提升互联网的服务水平。
猜你喜欢
科教新报(2022年24期)2022-07-08
作文小学中年级(2021年10期)2021-12-26
新世纪智能(高一语文)(2021年4期)2021-07-28
科教新报(2021年23期)2021-07-21
恋爱婚姻家庭·养生版(2021年5期)2021-05-31
大众投资指南(2020年10期)2020-07-24
网络安全和信息化(2019年11期)2019-11-25
科技与创新(2018年1期)2018-12-23
电子制作(2018年14期)2018-08-21
电子制作(2017年24期)2017-02-02
