
基于CNN与SVM结合的融合特征人脸识别研究
2020-06-08 01:55梁晴晴
现代信息科技 2020年19期


摘 要:针对目前人脸识别在样本量、鲁棒性等方面所受的局限,提出一种基于CNN和SVM的人脸识别模型。通过构建CNN模型进行训练,对原始图像提取来自CNN不同深度的特征图,并将其进行加权融合。将融合后的特征作为最终特征输入SVM多分类器进行分类。实验结果显示,对于小样本数据集以及面部遮挡、光照变化数据集,特征的融合对模型精度提升明显,且与传统模型比较本方法识别精度更高。
关键词:卷积神经网络;支持向量机;特征融合;人脸识别
Abstract:In view of the limitations of face recognition in terms of sample size and robustness,a face recognition model based on CNN and SVM is proposed. By constructing CNN model for training,feature maps from different depths of CNN are extracted from the original image,and weighted fusion is performed. The fused features are input into SVM multi classifier as final features for classification. The experimental results show that for small sample data sets,face occlusion and illumination change data sets,the fusion of features can significantly improve the accuracy of the model,and the recognition accuracy of this method is higher than that of the traditional model.
Keywords:convolution neural network;support vector machine;feature fusion;face recognition
0 引 言
人脸识别通过人的脸部特征信息进行身份识别,其作为生物特征识别的一个重要方面,有着识别友好,特征易得等特点。正因为人脸识别独有的特性,使得它在刑事侦查、身份验证、视频监控等许多方面都有着广泛的应用。
国内外学者提出的人脸识别算法也颇多。李润青[1]提出一种改进的2D2DPCA与SVM相结合的人脸识别分类方法,有效减少运算量和训练时长,同时减低光照对识别的影响。张伟[2]等提出一种基于Gabor小波和LBPH算法的实时人脸识别算法,基于ARM平台实现人脸识别系统。任飞凯[3]提出了结合LBP和数据扩充的LECNN方法,有效地提高了CNN人脸识别的准确率。谷歌[4]提出基于深度神经网络的FaceNet,直接学习从原始图像到欧式距离空间的映射,将欧式空间里的距离度量與人脸相似度对应。
近年来,随着深度学习的发展,越来越多的深度学习技术[5-9],特别是CNN被更多的应用在人脸识别中。相较于传统技术,深度学习学习能力强,泛化能力好,但也存在对样本量要求大,易过拟合等问题。
因此,作者提出一种基于CNN和SVM的人脸识别算法,将CNN强大的学习能力与SVM多分类器对小样本的适用性相结合,为本校未来在人脸识别方面的应用提供参考。通过深层卷积神经网络提取人脸特征,将网络不同深度提取的特征融合,使特征在高度抽象的同时兼顾底层细节信息,增加分类特征包含的信息量。最后使用更适合小样本分类的SVM算法进行分类。
1 基于CNN和SVM的融合特征人脸识别算法框架
研究表明,大型的深层神经网络,具有较强的学习能力,对于图像分类具有较大优势。但对小样本图像数据使用深层神经网络容易出现过拟合、泛化能力弱等问题。而SVM是一类按监督学习方式对数据进行分类的广义线性分类器,有较强的泛化能力,且更适用于小样本集。为了提升对小样本人脸数据的分类精度,本文将CNN与SVM结合。CNN的不同层所包含的信息不同,低层包含细节信息,高层含有抽象的类别信息[10,11]。网络主要分为三部分,首先,构建CNN,训练网络提取图像特征。其次,将不同深度的特征融合作为最终的分类特征。最后,将分类特征输入SVM进行人脸识别。
1.1 特征提取网络
为了更好地提取人脸图像的特征,构建包含6个卷积层、3个池化层、3个全连接层的CNN。以提取ORL人脸数据集特征为例,网络结构如表1所示。
1.1.1 前向传播
对CNN进行权值的初始化,输入图像依次经过卷积层、池化层、全连接层向前传播得到最终的输出值。以ORL人脸数据集特征提取网络为例,本文定义网络的输入大小为64×64×3,卷积层C1和卷积层C2的卷积核大小为3×3,卷积步长为1,经过两层卷积得到64个64×64的人脸特征图,卷积后使用ReLU激活函数。之后进入池化层P1,使用2×2大小的滑动窗口,步长为2对特征图进行最大池化操作,对特征降维得到64个32×32的特征。经过同上相同结构的三部分后,得到256个8×8的特征图。将特征图打平成一维向量输入全连接层,向量经过三个全连接层,最终得到一个40维的特征向量。
1.1.2 反向传播
对包含N个人,共n张人脸图像的样本集使用交叉熵损失函数计算误差,其中,tki为样本k属于类别i的概率,yki为CNN对样本k预测为类别i的概率,交叉熵损失函数表达式为:
本文通过Adam优化算法对CNN参数进行更新。Adam优化算法是一种一阶优化算法,收敛速度快,训练高效,能根据数据迭代地更新神经网络参数。定义待优化参数为w,目标函数为f(w),初始学习率为α。迭代优化过程中,在第s个epoch中计算目标函数对当前参数的梯度gs=▽f(ws)。根据历史梯度计算一阶和二阶动量,一阶动量为:
1.2 特征融合
1.2.1 单层特征合并
运用1.1节中的CNN进行训练,在得到较高准确率后,保存CNN模型,利用训练好的模型学习人脸特征。本文选取池化层P2和P3层作为子特征层。其中P3是除全连接层之外的最高层,包含高度抽象的类别信息,而P2处于卷积神经网络的中间层,相较于P3属于低层,包含人脸图像的细节信息。
首先,将人脸图像输入训练好的CNN模型当中,分别获取P2层和P3层的特征。其中P2层包含128个16×16的特征图,P3层包含256个8×8的特征图。
随后分别对来自不同深度的特征进行降维。将来自P2层的维度为16×16×128的特征图进行纵向合并,转换为16×16×1的特征图FP2。将来自P3层的维度为8×8×256的特征图进行纵向合并,转换为8×8×1的特征图FP3。合并方式为:
其中,Fk为合并后的特征图,k=P2或P3。fi为第i个通道的特征图。z为通道总数,处理P2层特征时z=128,处理P3层特征时z=256。
1.2.2 P2层和P3层的特征融合
为了使合并后的P2层特征FP2和P3层特征FP3进行融合,需要将特征大小进行归一化。本文选择将P3层的特征图从8×8转换为16×16。常见的图像归一化方法包括最近邻插值法、线性插值法、区域插值法。其中,最近邻插值法效果较好且计算简便,因此本文选取最近邻插值法对特征尺寸进行归一化。
将P3层特征图FP3大小表示为Fh×FW,目标图像的大小为Th×TW,高度和宽度的缩放比例分别为hr=Fh/Th和Wr=FW/TW。目标人脸图像(X,Y)处的像素值就等于原图像中(X×Wr,Y×hr)处的值。将图像在原图基础上扩大二倍,最近邻插值法的效果如图1所示。
对合并后的P2层特征FP2和P3层特征FP3进行尺寸归一化后,FP2和FP3的尺寸都变成了16×16的一维矩阵。将来自不同深度的特征结合,保留高层高度抽象的类别信息与低层的细节信息,有助于提升分类的精度。因此将FP2和FP3进行加权融合,形成最终的特征,公式如下:
1.3 SVM分类
研究表明,SVM具有稳健性和稀疏性,分类效果好,且适用于小样本。因此在对特征进行融合后,为了提升模型对于小样本的泛化能力,取得更好的分类效果,选择用SVM分类器对特征进行分类。
SVM属于监督学习方法,其决策边界是对样本数据求解的最大边距超平面。SVM最初仅用于二分类问题,当处理多分类问题时需要构造合适的多分类器。构造SVM多分类器的方法包括一对多法和一对一法。一对多法在训练时依次将某类样本归为一类,其余样本归为一类。当有l个类别的样本时,共构造出l个SVM。分类时将未知类别信息的样本划分为具有最大分类函数值的类别。一对一法是在任意两个类别之间设计一个SVM分类器,对于l个类别的样本需要设计l(l-1)/2个SVM分类器。分类时将未知类别信息的样本划分到得票最多的类别,这里采用一对一法实现SVM多分类。
在选择适当的模型参数后,将1.2节中得到的特征F输入到SVM多分类器中进行分类,得出最终的人脸识别结果。
2 实验与结果分析
2.1 实验环境与目的
本实验环境为Intel(R) Core(TM) i5-6200U CPU @ 2.30 GHz处理器,8 GB运行内存。编程环境为Python 3.7,深度学习基于TensorFlow 2.0框架。分别在ORL人脸数据集和Cropped AR人脸数据集上验证本文方法的有效性。
ORL人脸数据集中包含40人的人脸图像,包括男性和女性,每人10张图像,共400张。图像大小为64×64。本文对ORL人脸数据集进行归一化处理,并对图像设置数字分类标签,标签范围为0至39。如图2所示,同一个人的人脸图像有表情和角度的变化。通过此数据集评估本文方法对小样本集的适应性。
Cropped AR人脸数据集中共包含1 300张人脸图像。其中有50个不同人的人脸图像,每人26张图像。包含在不同光照、不同表情、不同面部遮挡的下的图像,如图3所示,由于光照、面部表情以及面部遮挡的影响,使得Cropped AR人脸数据集的识别难度比ORL人脸数据集更大。因此,通过此数据集评估本文方法对不同光照、表情、面部遮挡的鲁棒性。
分别通过对比两个数据集在CNN模型、CNN+SVM模型、特征融合的CNN+SVM上的分类效果,探究模型融合对分类效果的影响以及特征融合对模型分类效果的影响。同时将本文模型与其他人脸识别模型对比,证实本文模型的有效性。
2.2 实验流程
2.2.1 ORL人脸数据集实验流程
将ORL人脸数据集中的400张图像按照7:3的比例分割为训练集和测试集,其中训练集280张图像,测试集120张图像。
训练阶段,将训练集人脸图像输入到本文构建的CNN模型中,设置batch size为40,epochs为100,对CNN進行训练并保存,特征提取网络的验证集准确率随epochs变化的曲线如图4所示。
利用训练好的CNN模型提取训练集图像在其不同深度的特征FP2和FP3。通过最近邻插值法将FP2和FP3的尺寸进行归一化后,将两个特征进行加权融合,作为最终的分类特征。经实验证明,当加权系数a=0.7时,特征融合效果最好。之后将训练集的最终分类特征输入SVM多分类器进行训练,将此模型用于最终分类。其中采用一对一方法实现SVM多分类,核函数为线性核函数,目标函数的惩罚系数C为0.9。
测试阶段,将测试集输入保存好的CNN中提取特征。利用与测试集相同的方法得到融合特征,输入训练好的SVM多分类器得出分类结果,并与训练集的真实标签对比得出准确率。
将训练集人脸图像输入到本文构建的CNN模型中,对CNN进行训练并保存。通过训练好的CNN提取测试集和训练集人脸图像在其不同深度的特征FP2和FP3。通过最近邻插值法将FP2和FP3的尺寸进行归一化后,将两个特征进行加权融合,作为最终的分类特征。
利用训练集得到的融合特征完成对SVM多分类器的训练,其中SVM分类器采用一对一法,核函数为线性核函数,目标函数的惩罚系数C为0.9。将测试集得到的融合特征输入SVM分类器,将预测结果与图像的真实标签对比得出最终的分类准确率。
2.2.2 Cropped AR人脸数据集实验流程
将Cropped AR数据集中的1 300张图像按照7:3的比例分割为训练集和测试集,其中训练集910张图像,测试集390张图像。
训练阶段,将人脸图像输入到构建好的特征提取网络,由于Cropped AR数据集的数据量更大,因此在每个MaxPooling层之前加上batch normalization层,加速网络训练。设置batch size为32,epochs为30,对CNN进行训练并保存,特征提取网络的验证集准确率随epochs变化的曲线如图5所示。
剩余实验流程同ORL人脸数据集实验流程。
2.3 实验结果分析
2.3.1 ORL人脸数据集实验结果分析
2.3.1.1 特征融合的有效性实验
在ORL人脸数据集上,将基础的CNN+SVM分类模型与输入融合特征的CNN+SVM分类模型作对比,探究特征融合对模型分类的提升效果,实验结果如表2所示。
从实验结果可以看到,对于ORL人脸数据集,特征融合对模型分类精度的提升显著。基础CNN+SVM模型的输入特征是未经融合的特征。从CNN中不同深度的提取出的特征具有不同的特性,深层特征更加抽象,具有更抽象的类别信息,而浅层特征更加具象,具有更多的细节信息。因此,在经过特征融合后,分类特征将包含更多有用的分类信息,有助于提升分类精度。
2.3.1.2 与其他模型的效果对比实验
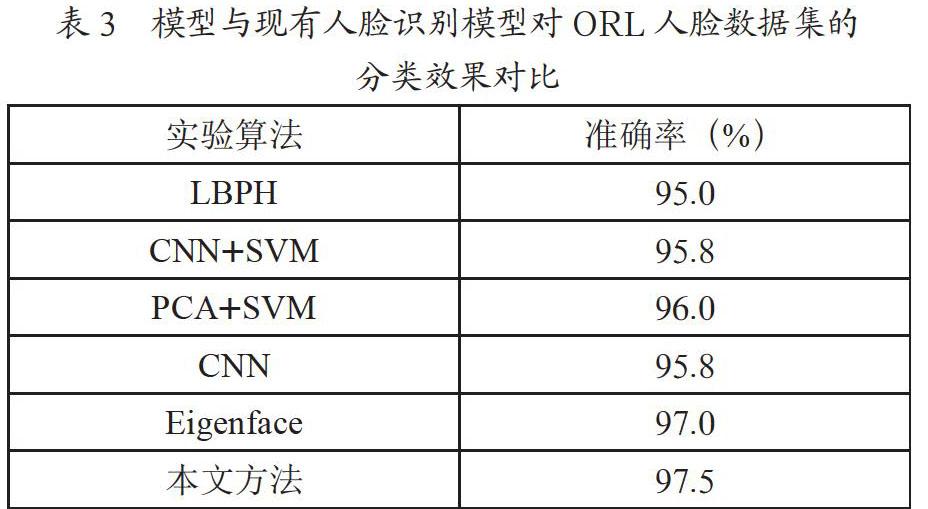
将本文模型与其他现有人脸识别方法进行对比,探究本文方法的有效性,实验结果如表3所示。
根据实验结果发现,与目前一些现有的人脸识别方法相比,本文模型在ORL人脸数据集上的识别率更高,说明分类模型建立效果良好。可见,本文模型对小样本人脸数据效果较好。
2.3.2 Cropped AR人脸数据集实验结果分析
2.3.2.1 特征融合的有效性实验
在Cropped AR人脸数据集上,分别使用CNN+SVM分类模型、输入融合特征的CNN+SVM分类,探究特征融合对分类效果的影响,实验结果如表4所示。
从实验结果可以看出,对于Cropped AR人脸数据集,特征融合对于分类效果提升显著。在对特征融合后,分类特征兼具细节信息和高度分类信息,更有利于最终的分类。
2.3.2.2 与其他模型的效果对比实验
将本文方法与其他人脸识别方法在Cropped AR人脸数据集的分类效果作对比,实验结果如表5所示。
与目前的主流人脸识别算法比较,本文的准确率更高。因此,在面对光照不同、面部姿态不同、存在面部遮挡的人脸数据集时,本文方法依然具有鲁棒性,能降低光照、姿态以及面部遮挡的影响,获得较高的准确率。
3 结 论
构建卷积神经网络模型将CNN的学习力与SVM对小样本的适用性结合。首先,使用CNN对原始人脸图像进行特征提取,将来CNN不同深度的特征进行提取并加权融合,最终使用SVM分类器进行分类。将浅层特征的细节信息与深层特征的抽象类别信息结合,提升了分类精度,证实了特征融合的有效性。通过在小样本人脸数据集以及有光照、面部表情、面部遮挡变化的人脸数据集上的实验验证模型,实验结果表明,本文方法在处理人脸图像分类问题上取得了较好的效果。
参考文献:
[1] 李润青.基于PCA改进与SVM相结合的人脸识别算法研究 [D].昆明:昆明理工大学,2018.
[2] 张伟,程刚,何刚,等.基于Gabor小波和LBPH的实时人脸识别系统 [J].计算机技术与发展,2019,29(3):47-50.
[3] 任飞凯.基于卷积神经网络人脸识别研究与实现 [D].南京:南京邮电大学,2019.
[4] SCHROFF F,KALENICHENKO D,PHILBIN J. FaceNet:A unified embedding for face recognition and clustering [C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2015:815-823.
[5] 黄振文,谢凯,文畅,等.迁移学习模型下的小样本人脸识别算法 [J].长江大学学报(自然科学版),2019,16(7):88-94.
[6] 章东平,陈思瑶,李建超,等.基于改进型加性余弦间隔损失函数的深度学习人脸识别 [J].传感技术学报,2019,32(12):1830-1835.
[7] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J].Computer Science,2014,66(11):1556-1568.
[8] JIN X,TIAN X Y.Face alignment in-the-wild:A Survey [J].Computer Vision and Image Understanding,2017(162):1-22.
[9] GLOROT X,BORDES A,BENGIO Y. Deep Sparse Rectifier Neural Networks [C]//Proceedings of the 14th International Conference on Artificial Intelligence and Statistics,2011:315-323.
[10] 尹紅,符祥,曾接贤,等.选择性卷积特征融合的花卉图像分类 [J].中国图象图形学报,2019,24(5):762-772.
[11] 翁雨辰,田野,路敦民,等.深度区域网络方法的细粒度图像分类 [J].中国图象图形学报,2017,22(11):1521-1531.
作者简介:梁晴晴(1997.10—),女,汉族,河南郑州人,硕士研究生,研究方向:调查与大数据分析。
猜你喜欢
文萃报·周五版(2021年17期)2021-05-31
中国计算机报(2020年13期)2020-04-26
通信产业报(2018年10期)2018-04-13
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科学与财富(2016年28期)2016-10-14
