
全局中心聚类算法在课程序化中的应用*
2020-06-09 06:17段桂芹邹臣嵩
计算机与数字工程 2020年3期
段桂芹 刘 松 邹臣嵩
(1.广东松山职业技术学院计算机系 韶关 512126)(2.广东松山职业技术学院机械工程系 韶关 512126)
(3.广东松山职业技术学院电气工程系 韶关 512126)
1 引言
聚类是指按照研究对象的某个特征,对其进行无监督的分类,其目的是根据研究对象自身的相似度差异,使不同簇之间的研究对象具有最小相似性,同一簇内的研究对象具有最大相似性[1]。迄今为止,研究人员已经提出了多种聚类算法,通常可以分为基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法、基于模型的方法。其中,K-means 算法是应用最为广泛的划分方法之一,但该算法对初始聚类中心和异常数据较为敏感,且不能用于发现非凸形状的簇,因此聚类结果不稳定[2]。为了解决这些问题,研究人员针对簇中心的选择与优化提出了新的计算方法[3~10],从聚类准确率、聚类耗时以及整体聚类质量等多个方面对原始K均值算法进行了优化与改进,但大多数研究都是致力于利用样本的分布信息优化初始聚类中心的选择,而在序列聚类研究领域,除了需要选择合适的初始聚类中心,还需要针对实际情况设计满足要求的相似度计算规则,在现有的各种应用中,序列数据的相似性可以分为两种:基于整体的序列相似性,常用于用户交易序列;基于局部的序列相似性,常用于生物信息序列,但课程序列与户交易序列和生物信息序列相比有诸多不同,因此,如何选择并改进现有的聚类算法,将其应用至课程序列的聚类分析中是解决课程序化问题的关键。
2 相关算法的研究现状
在聚类算法的改进方面,王实美[6]针对密度算法进行了改进,该算法使用M近邻有向图得到输入参数,克服了密度算法对输入参数难以确定的缺点,降低了参数对人工的依赖性,但是,由于该算法使用的是全局唯一密度参数,在非均匀密度数据集的聚类效果并不理想。熊忠阳[7]使用最大距离积法解决了最大最小距离法因选取初始聚类中心过于稠密而导致的聚类冲突等问题,与经典的密度聚类算法相比,该算法在密度算法基础上,从高密度点集合中选取距离乘积最大的样本作为聚类中心,但对于参数MinPts(邻域密度阈值)没有真正地实现自适应确定阈值,依然采用经验方法选取,需要人工参与。翟东海[8]使用最大距离法选取初始簇中心改进了K-mean 聚类算法,解决了K-means算法的聚类结果不稳定、总迭代次数较多等问题。段桂芹[9]选取数据对象到样本均值和当前聚类中心集合的距离乘积最大值法来确定新的初始聚类中心,克服了聚类结果对初始聚类中心的依赖性。邹臣嵩[10]通过采集样本的分布情况计算样本的密度参数,构建高密度点集合,改进了最大距离乘积法,提升了聚类算法的准确率和时间性能。
在研究以上算法[3~10]以及相关文献[11~13]的基础上,本文提出通过选取k 个“首尾相连”且距离乘积最大的数据对象作为初始聚类中心,确定样本集中数据对象的大致分布,簇中心迭代过程中,选取了与簇内样本距离之和最小的数据对象作为簇中心。实验测试表明,本文算法的聚类准确率、整体耗时、F 值等性能指标优于K-means 算法、文献[7]和文献[8]的算法。
3 全局中心聚类算法
全局中心聚类算法由距离矩阵构建、初始聚类中心选择和簇中心迭代三部分构成:在距离矩阵构建时,使用距离公式计算各数据对象间的距离;在初始聚类中心选择阶段,从距离矩阵中选取k 个首尾相连且距离乘积最大的数据对象作为初始聚类中心集合Z,Z={Z1,Z2,…,Zk};在簇中心迭代过程中,根据集合Z 完成初次聚类,选取簇内最小距离和的样本作为簇中心,生成临时簇中心集合Z'={Z1',Z2',…,Zk}',再按最小距离将各样本划分到相应簇中,重复簇中心迭代过程,直至聚类误差平方和函数收敛,完成聚类。
全局中心聚类算法中的相关定义、流程分别如下。
3.1 相关定义
设 X 为含有 n 个样本的集合,X={X1,X2,…,Xn},各样本的特征数为 p,则第 i 个样本若该集合可划分为k 个簇,每簇含样本m 个,簇中心集合为Z,则可用以下方式表示该集 合 ,既 Cluster={Cluster1,Cluster2,…,Cluster}k,Cluster∈X,Z={Z1,Z2,…,Z}k(k<n)。
定义1空间两点间的欧氏距离定义为

式中i=1,2,…,n;j=1,2,…,n;w=1,2,…,p。
定义2样本集X的空间距离矩阵X'

定义3第k簇中样本Xi的簇内距离和定义为

定义4第k簇的簇内距离和矩阵定义为

定义5将第k 簇的簇内距离和最小的样本Xi作为的中心,即

定义6聚类误差平方和E的定义为

式中 q 是样本集 X 中的某个样本,Zi是簇 Clusteri的中心。
3.2 算法描述
步骤1:根据式(1)计算样本集X中各数据对象之间的距离,得到距离矩阵X';
步骤2:根据式(2)构建样本集X的空间距离矩阵X';
步骤3:在X'中选择满足k 个首尾相连且距离乘积最大的数据对象作为初始聚类中心,即选择满足的 k 个数据对象加入簇中心集合Z 中;
步骤4:将各样本按最小距离划分至对应的簇中;
步骤5:使用式(3)、(4)计算出簇内距离和矩阵,根据式(5)从中筛选出满足条件的新簇中心存入集合Z'中;
步骤6:重复步骤5,更新各簇的中心,直到|Z'|=k,再用Z'取代Z;
步骤7:重复步骤4;
步骤8:根据式(6)计算聚类结果评价指标,判断是否收敛,如果收敛,则聚类算法结束,否则转到步骤4继续执行。
4 实验仿真与分析
实验运行环境:CPU Intel Core i3-3240 3.4GHz,硬盘1T,内存4G,操作系统Win7(64 位),仿真软件使用Matlab 2011b,实验数据集详见表1。在有效性验证方面,采用聚类总耗时、Rand 指数、Jaccard系数和聚类准确率等指标对K-means算法、文献[7]、文献[8]和本文算法进行了比较,其中K-means算法的实验结果是其运行30次的平均值。

表1 UCI数据集
4.1 聚类准确率和时间性能对比
图1~图5 是K-means算法、文献[7~8]算法和本文算法在UCI数据集的聚类准确率、初始中心选择耗时、簇中心更新耗时、迭代次数、聚类总耗时的实验对比结果。观察图1 可知,在iris 和wine 数据上,本文算法的聚类准确率明显高于K-means 算法,略高于文献[7~8]算法,在 Haberman、sonar 和soybean 数据集上的聚类准确率明显高于其他三种算法。
由图2可知,由于K-means算法随机选取初始聚类中心,无需额外计算,故耗时少,而文献[7~8]和本文优化了初始聚类中心选择过程,增加了计算开销,因此耗时较多。此外,由于本文算法先对整个样本集的距离矩阵进行了求解,并用全局中心法筛选初始聚类中心,在计算量方面开销较大,因此耗时高于文献[7~8]。
从图3 可以看出,本文算法的簇中心更新耗时小于K-means 算法和文献[7~8]算法,主要原因在于在该阶段,本文算法的簇中心与簇内样本距离之和最小,簇中心被其他样本紧密围绕,每一次更新,都会使得簇中心的位置和样本的分布情况更加清晰,进而减少了更新次数和更新耗时。
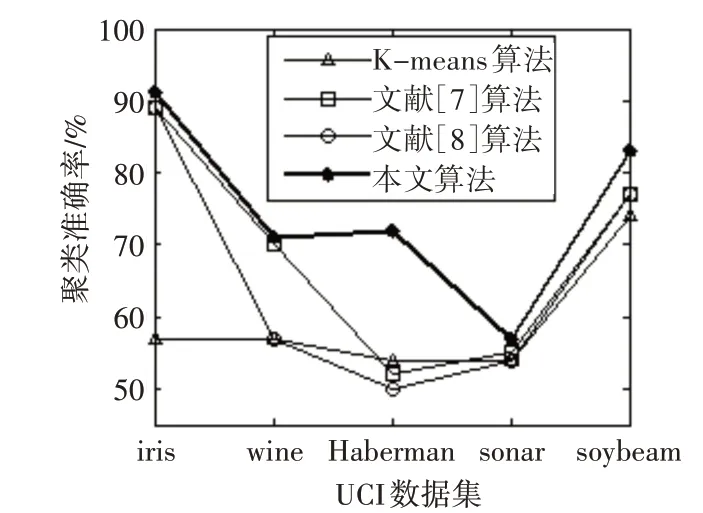
图1 聚类准确率比较

图2 初始中心选择耗时比较

图3 簇中心更新耗时比较
从图4、图5 可知,本文算法在迭代次数、总耗时方面优于其他三种算法,这是由于K-means算法的随机性导致准则函数易陷入局部极小、导致总迭代次数不稳定,此外,文献[7~8]并未对簇中心更新进行优化,依然沿用均值中心算法,未能更好地体现中心点在簇中的代表性,而本文算法在初始中心选择阶段筛选出的聚类中心相对分散,基本反映了样本的大致分布,相对而言,具有较强代表性,此外,在簇更新阶段,选取了与簇内样本距离之和最小的数据对象作为簇中心,在整体上快速得逼近了全局最优解,减少迭代次数,降低运算耗时。

图4 迭代次数比较

图5 聚类总耗时比较
4.2 其他外部评价指标对比
关于算法聚类结果的评价,除采用常用的聚类准确率、迭代次数和各阶段聚类耗时之外,还采用Rand等四个评价指标[14]对聚类结果进行了比较分析。观察表2~表5 的对比结果可知,本文算法在UCI的5个数据集上的聚类外部评价指标全部优于其他4种算法。

表2 Rand指数比较

表3 Jaccard系数比较

表4 Adjusted Rand Index参数比较
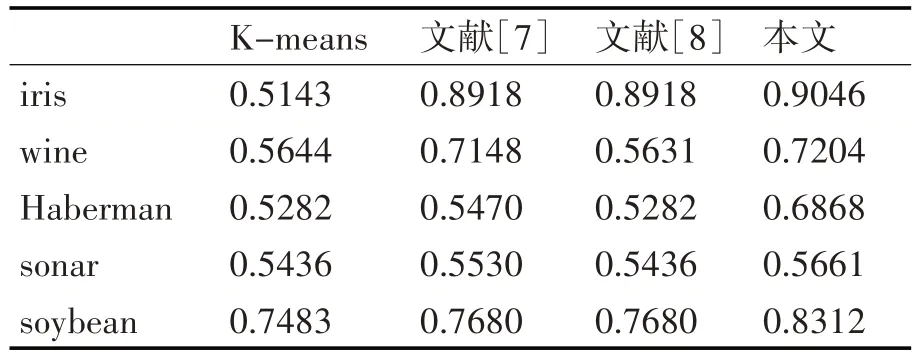
表5 F值比较
从上述UCI数据集的对比实验结果可以得出:本文算法在多种聚类结果的评价指标中展现出更佳的聚类质量、更快的收敛速度和更高的稳定性,可以应用于实际数据的聚类。
5 算法在课程序列聚类中的应用
5.1 样本数据结构
原始数据由前导课程、后续课程、开设学期三个关联关系构成,表6是26名课程专家之一填写的课程关系数据表。
在对原始样本数据预处理时,将“项目”定义为有前导后续关系的两门课程的组合,如前导课程为A,后续课程为B,则用项目“AB”表示二者关系,因此候选项目集由A 到M 的13 个元素中的两个相异元素有序排列而成,既{AB,AC,AD,…,MJ,MK,ML},共包含156个项目,每个项目都表达了两门课程的先后组合关系[15]。据此,表6 可由项目子集{GA,LA,HB,FB,BM,…,DL,IL,LA,BM,KM}表示;同理可以构建出其他25 个项目子集,共同组成新的序列样本集,预处理后的序列样本集由318 条序列事务构成。
5.2 序列间的相似性度量
序列数据的相似性可以分为两种:基于整体的序列相似性和基于局部的序列相似性,前者常用于生物信息序列,后者常用于用户交易序列[16~17]。但课程序列与户交易序列和生物信息序列相比有诸多不同:首先,一门课程在序列中是不允许重复的,即一门课只教授一次,而用户交易和生物信息序列中的元素是可以重复的;其次,在序列元素的数量上,用户交易的元素数量很大,生物信息的元素数量很少,课程序列的元素介于两者之间;再次,用户交易序列更强调时间的点,课程序列更强调先后的序;最后,生物信息序列强调空间的物理结构,课程序列更强调行为的逻辑结构。针对课程序列的特殊性以及课程体系的构建需求,序列间的相似度与距离定义如下。
定义7结构相似度。假设Xi和Xj是序列样本集中的两个样本,则Xi和Xj的结构相似度Ssim(Xi,X)j:

其中Stru(X)i、Stru(X)j分别表示Xi和Xj各自包含的元素的集合;|Stru(X)i∩Stru(X)j|表示Xi和Xj共有元素个数,|Stru(X)i∪Stru(X)j|表示Xi和Xj所包含的全部元素的个数。Ssim(Xi,X)j的取值范围是[0,1],当其值为0 时,表示二者的结构无任何相似性;当其值为1 时,表示二者的结构全部一致。
定义8内容相似度:

其中Con(tX)i、Con(tX)j表示Xi和Xj所包含的项目的集合。
定义9序列相似度由结构相似度与内容相似度共同构成,为二者均值,即:

定义10序列间的距离定义为

5.3 基于全局中心聚类算法的课程体系构建
使用式(7~10)计算序列样本集中各样本之间的距离,得到距离矩阵X',结合全局中心聚类算法,完成聚类。
需要特别指出的是:序列聚类后的每一簇序列形成一条课程路径,针对一种岗位能力的培养。由于机电设备维修与管理专业有五个入职岗位,每个岗位的核心课程约 7 门,因此对 K=3,4,5 都进行了聚类分析,且每簇选取聚类中心及距其最近的8 条序列用于课程结构的生成,聚类计算结果如表7 所示。

表7 岗位课程聚类结果
对表7 的聚类结果进行整理,删除相同聚类和元素个数大于等于8 的聚类,对剩余的6 个聚类分别计算其元素排序支持度,形成6 条链路;对孤立元素,计算其与聚类元素的排序支持度,得到1 条岗位课程排序链路,具体结果如表8。

表8 岗位课程排序结果
6 结语
本文用全局中心法对K-means 算法和最大距离乘积聚类算法进行了改进,得到了具有代表性的初始聚类中心,在簇中心迭代阶段,选取簇内距离和最小的样本作为簇中心,减少了迭代次数,提高了算法的运算速度,对比测试表明,本文算法对聚类中心的选取合理、有效。在实际应用中,使用新算法对现代学徒制的职业能力及课程体系的相关数据进行了聚类分析,解决了课程序列的有效聚类问题,为课程结构的合理设计给出了理论依据。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生导刊(2018年34期)2018-12-18
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
山东青年(2016年3期)2016-02-28
山东青年(2016年1期)2016-02-28
母子健康(2015年1期)2015-02-28
延河(下半月)(2014年3期)2014-02-28
当代修辞学(2014年3期)2014-01-21
