
基于GAN网络的面部表情识别
2020-06-11 09:26陈霖段巍刘立志
电子技术与软件工程 2020年1期
文/陈霖 段巍 刘立志
(1.中国电子科技集团公司第二十八研究所 江苏省南京市 210000 2.武警天津市总队参谋部 天津市 300000)
1 引言
面部表情识别是计算机视觉中最重要的任务之一,它在心理学、教育、数字娱乐、驾驶员监控等许多应用中起着至关重要的作用。面部表情识别旨在将给定的表情分析并分类成几种特定的情绪类型,其过程主要有两个阶段,即特征提取和表情识别。在现有的方法中,大多数表情识别只基于正面面部图像,对于任意姿态下的表情识别问题亟需解决。近年来,深度网络已广泛用于计算机视觉的各种任务,基于深度网络的面部表情识别[1]问题也得到了发展,但使用深度模型需要足够的标记数据来训练,目前人脸表情识别中大部分数据库中的数据量非常有限。因此,本文设计了一个基于生成对抗网络(GAN)的模型生成更多的图像扩充训练集,同时并将分类器嵌入到GAN 网络中实现面部表情识别。
2 基于GAN网络的面部表情识别方法
2.1 面部表情识别
现有的表情识别过程分为特征提取和表情识别两个阶段。传统的用于特征提取的方法主要包括SIFT[2]、LBP、Gabor 以及Geometry 等。本文采用卷积神经网络(CNN)方法提取特征。特征提取后,将其输入到表情的分类模型中参与训练,进行表情识别。常用的表情分类模型主要有SVM、KNN 以及随机森林等。得到相应的表情分类模型之后,即可针对一张给定的图像进行表情分类任务。与现有的方法不同,为解决任意姿态下的面部表情识别问题,本文采用GAN 网络的变体生成具有不同姿态和表情的面部图像,并将分类器嵌入到GAN 网络中训练,实现一个端到端的深度学习模型。
2.2 生成对抗网络(GAN)
GAN 网络[3]是一种深度学习模型,包括一个生成模型与一个判别模型。生成模型用于接收一个随机的噪声,通过噪声生成数据或图片。判别模型包含两类输入,一类是生成的噪声数据,另一类是从现实场景中采集到的真实数据。可以把判别模型看作一个二分类器,输出的是一个概率值,用来判别输入的样本的真假,当输出值大于0.5 说明样本为真即来自现实场景中采集到的真实数据,反之样本为假即来自生成器生成的噪声数据。生成模型与判别模型是两个独立的模型,使用交替迭代的训练方式。在训练过程中,不断优化生成模型,使得生成模型尽量生成服从真实数据分布的数据,不断优化判别模型,直到对于生成的图片判别模型不再能判别出其真假。生成模型与判别模型的目的正好是相反的,所以称之为对抗。
2.3 GAN网络与表情识别
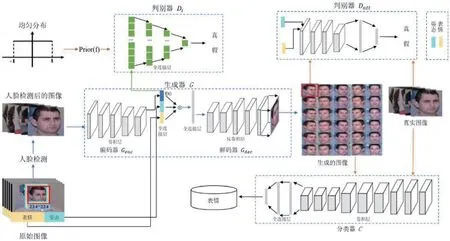
图1:模型架构图
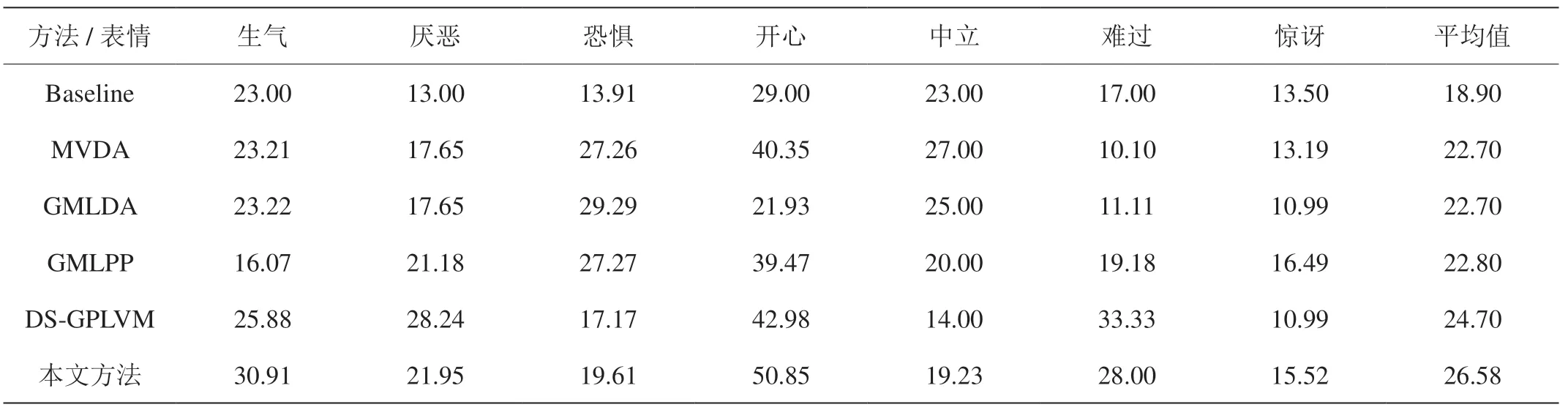
表1:本文的方法与现有的方法准确率对比
本文提出的方法模型包括一个生成器,两个判别器和一个分类器,如图1。将原始图像输入到生成器之前,先使用人脸检测算法[3]去除背景之类的冗余信息。经过预处理后,将面部图像输入到由一个编码器(Genc)和一个解码器(Gdec)构成的生成器中。经过编码器处理后,得到一个关于人脸图像特征的表示,记作f(x),然后把人脸图像特征、姿态和表情的编码输入到解码器中,生成一张新的人脸图像。之后,通过判别器(Datt)与生成器之间的对抗可以解开人脸图像特征、表情以及姿态之间的关系。将其关系解开后,加入新的姿态编码以及新的表情编码可以生成大量不同姿态以及不同表情下的人脸图像,促进表情识别任务的完成。同时,为了提高生成图像的质量,加入另外一个判别器(Di)。在这个判别器中,把从均匀采样中得到的数据当作正样本,把经过编码器处理后的人脸图像特征当作负样本,通过两者之间的对抗可以使得人脸图像特征满足均匀分布,从而提高生成图像的质量。最后,用生成的人脸图像与原始图像共同训练分类模型。
生成器G 与判别器Datt的对抗学习过程:
x 代表经过预处理后的面部图像,条件y 代表表情和姿态的编码信息,用one-hot 向量表示,G(x,y)是由生成器生成的数据。这里加入条件y 有助于生成器在生成具有不同表情和不同姿态的图像的同时保持人脸图像特征不变,扩充了数据集,解决训练集数据量不足的问题,推动当下姿态不变的面部表情识别问题的发展。真实的图像满足pd(x)分布,判别器通过图像的分布信息来判别图像的真假。通过生成器G 与判别器Datt之间的对抗训练可以得到一个用于任意姿态与任意表情下图像生成的模型,该训练过程满足式(1):
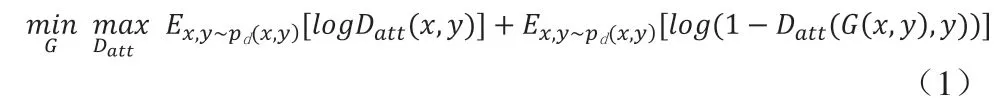
生成器G 与判别器Di的对抗学习过程:
假设prior(f)满足某种先验分布,则 f*~prior(f)表示从先验分布中随机采样的过程。将从先验分布中采样的样本当作正样本,将经过生成器中的编码器处理后的人脸图像特征f(x)当作负样本,通过生成器G与判别器Di之间的对抗训练可以得一张满足均匀分布、高质量的人脸图像,该训练过程满足式(2):
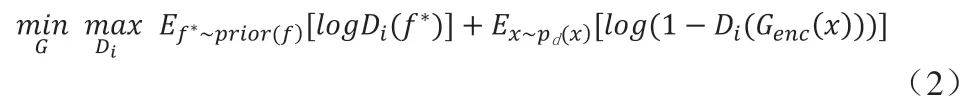
最后,将生成的图像与原始图像同时输入到分类模型C 中训练,两项交叉熵作为损失函数,前一项交叉熵用生成的图像来训练,后一项用原始图像进行训练:
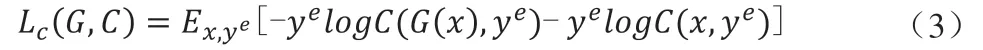
为了保障生成图像与原始图像之间的人物一致性,加入了一个l1范式进行约束:

3 实验结果
本文提出的方法在SFEW[4]数据集上得到了验证,如表1,对比现有的方法,该方法在七个基本表情上的平均识别准确率是所有方法中最高的,以此证明了该方法的有效性。
4 总结
本文提出了一个端到端的深度学习模型,在进行面部图像合成的同时解决了姿态不变的面部表情识别问题。通过解开面部图像中的人脸特征、姿态以及表情之间的关系,生成具有任意表情以及姿态的面部图像扩充训练集,以此提高模型的准确率,并在数据集SFEW 上得到了有效的验证,与现有的面部表情识别方法相比,取得了最高的准确率,为面部表情识别方法的发展做出了相应的贡献。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
学生天地(2020年3期)2020-08-25
动漫星空(2018年9期)2018-10-26
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
知识经济·中国直销(2018年8期)2018-08-23
中国老区建设(2016年1期)2016-02-28
发明与创新(2015年33期)2015-02-27
阅读(中年级)(2009年11期)2009-04-14
