
改进RetinaFace的自然场景口罩佩戴检测算法
2020-06-18 05:43牛作东李捍东陈进军
计算机工程与应用 2020年12期
牛作东,覃 涛,李捍东,陈进军
贵州大学 电气工程学院,贵阳550025
1 引言
自2019年12月以来,在我国爆发了新型冠状病毒肺炎(COVID-19)传播疫情[1],到目前为止(2020年2月27日),根据国家卫生健康委员会发布的最新消息,31个省(自治区、直辖市)和新疆建设兵团由新型冠状病毒感染的肺炎患者累计报告确诊病例78 824例,累计死亡病例2 788例,现有确诊病例39 919例。新型冠状病毒具有极强的传染性,它可以通过接触或者空气中的飞沫、气溶胶等载体进行传播,而且在适宜环境下可以存活5天[2-3]。因此勤洗手、佩戴口罩可以有效降低被病毒传染的机率。国家卫生健康委员会发布的《新型冠状病毒感染肺炎预防指南》中强调,个人外出前往公共场所、就医和乘坐公共交通工具时,佩戴医用外科口罩或N95口罩。因此在疫情期间公共场所佩戴口罩预防病毒传播是每个人的责任,这不仅需要个人自觉遵守,也需要采取一定的手段监督和管理。
虽然目前没有专门应用于人脸口罩佩戴检测的算法,但是随着深度学习在计算机视觉领域的发展[4-6],基于神经网络的目标检测算法在行人目标检测、人脸检测、遥感图像目标检测、医学图像检测和自然场景文本检测等领域都有着广泛的应用[7-10]。
本文通过研究相关的目标检测算法,发现用于人脸检测的深度学习模型可以适用于口罩佩戴的检测任务。其中文献[11]从稳健的锚点角度看待小人脸检测(Seeing Small Faces from robust anchor’s perspective,
SSF)问题,对先验框进行了比例不变性设计,提出了新的预期最大重叠(Expected Max Overlapping,EMO)值解决检测框重叠问题,并采用新的网络体系结构来减少先验框跨度、额外位移和目标随机性转移问题,该方法增强了人脸检测中对小人脸检测的能力。文献[12]提出了一种双镜头人脸检测(Dual Shot Face Detector,DSFD)方法,在该方法中使用了一种功能增强模块(Feature Enhance Module,FEM)来增强原始特征图,提出了利用计算出的渐进式锚点损失(Progressive Anchor Loss,PAL)和 改 进 的 锚 点 匹 配(Improved Anchor Matching,IAM)优化了回归网络的初始化,最终取得了不错的人脸检测效果。文献[13]提出了一种基于单次缩放感知的卷积神经网络的人脸检测器(Single-shot scale-aware network for real-time Face Detection,SFDet),该方法设计了一个具有多尺度感知的检测网络和与之相关联的先验框并在分类损失计算中引入了交并比(Intersection over Union,IoU)感知加权方案从而提高了人脸检测的效果。文献[14]提出了一种单阶段野外人脸定位算法,命名为RetinaFace,该方法采用软量级的骨干网络,可以在单个CPU上实时运行并完成多尺度的人脸检测、人脸对齐、像素级人脸分析和人脸密集关键点三维分析任务。在WIDER FACE[15]人脸数据集上的人脸检测平均精度(Average Precision,AP)对比结果如表1所示,WIDER FACE是一个人脸检测基准(Benchmark)数据集,也是世界数据规模最大的权威人脸检测平台,它根据图片中人脸检测难度分为了容易(Easy)、中等(Medium)和困难(Hard)三个等级。
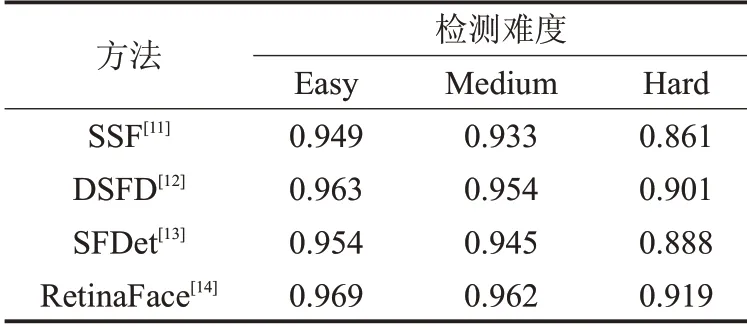
表1 人脸检测mAP值对比 %
从表1的对比结果中可以看出RetinaFace在人脸检测方面具有一定的优势,因此本文通过改进RetinaFace提出了一种自然场景下人脸口罩佩戴检测方法,主要工作有以下几点:
(1)改进了RetinaFace算法的网络结构,在人脸检测的基础上通过改进分类损失函数增加了人脸口罩配戴检测任务,并且去掉了人脸关键点三维分析等无关的检测任务,提高算法的训练速度。
(2)在RetinaFace的特征金字塔网络中引入了注意力机制,并进行了优化,增加了自注意力机制(Self-Attention),使特征提取网络提取有效的目标信息并抑制无用信息,增强特征图的表达能力和上下文描述能力。
(3)制作了新的数据集,并对数据做了大量的手工标注用于模型网络的训练和测试。
2 RetinaFace算法原理
RetinaFace是一种鲁棒的单级人脸检测算法,该算法利用多任务联合额外监督学习和自监督学习的优点,可以对不同尺度的人脸进行像素级定位。该算法的网络结构如图1所示,它融合了特征金字塔网络、上下文网络和任务联合等优秀的建模的思想。
2.1 RetinaFace特征提取网络
在RetinaFace算法的特征提取网络中采用了从P2到P6特征金字塔的五个等级,其中P2到P5是由相应的残差连接网络(Residual Network)[16]的输出特征图(C2至C6)分别自上而下和横向连接计算得到的。P6是通过C5采用Stride=2的3×3的卷积核进行卷积采样得到的。C1到C5使用了ResNet-512在ImageNet-11数据集上经过预训练的残差层[17],对于P6层使用了“Xavieer”方法[18]进行了随机初始化。
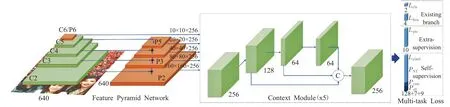
图1 RetinaFace网络结构
RetinaFace算法使用了五个独立的上下文模块,分别对应P2到P6五个特征金字塔级别,用来增加感受野的作用域和增强鲁棒的上下文语义分割能力。另外使用了可变形卷积网络(Deformable Convolutional Network,DCN)[19]代替了上下文模块中的3×3卷积层,进一步加强了非刚性的上下文建模能力。
2.2 RetinaFace多任务损失函数
对于一个训练的锚点(Anchor)框i,多任务联合损失函数定义为:

其中,Lcls是分类损失函数,pi是锚点框中包含预测目标的概率,∈(0,1)分别表示是负锚点框和正锚点框。Lbox是目标检测框回归损失函数,其中ti={tx,ty,tw,th}i表示与正锚点框相关的预测框的坐标信息,同理=表示与负锚点框相关的预测框的坐标信息。是面部标志回归损失函数,其中li=和分别表示正锚点框中预测的五个人脸标志点和标注的五个人脸标志点。Lpixel表示的是面部密集点回归损失函数。λ1、λ2和λ3表示的是损失平衡权值参数,在RetinaFace算法中分别设置为0.25、0.1和0.01,意味着在有监督的学习中再加关注检测框和面部标志点的信息。
2.3 RetinaFace锚点框
RetinaFace算法中在P2到P6不同的特征金字塔级别中使用不同的锚点框,如表2所示。其中在P2层中通过平铺尺度小的锚点框来捕捉小的面部特征,因此会花费更多的计算,并且承担更大的误报风险。对于输入图像大小为640×640,缩放步长设置为21/3,将长宽比设置为1∶1,锚点框在特征金字塔的各个级别上覆盖的尺度可以从16×16到406×406,总计产生102 300个锚点框,并且其中的75%来自特征金字塔P2层。
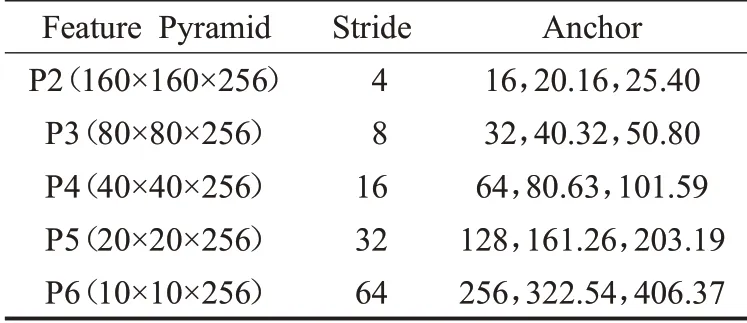
表2 锚点框尺寸
3 改进RetinaFace算法用于口罩佩戴检测
为了实现对人脸口罩佩戴进行检测,本文在RetinaFace算法的基础上进行了改进,改进后的网络结构如图2所示,整个框架分为特征金字塔网络、上下文网络和多任务联合损失三个部分。其中在特征金字塔中的主干网络为ResNet-512,用于特征提取并引入了注意力机制模块,增强特征图的表达能力。在多任务联合损失中舍去了无关的面部密集点回归损失,提高算法模型的训练速度和效率。
3.1 特征提取网络
本文使用预训练好的Resnet-512作为特征金字塔网络的主干网络,用于特征提取,除了第一层使用7×7的卷积外,其余4层均由残差连接单元组成,对于Res_N层表示包含n个残差连接单元。使用残差连接可以有效地解决深层网络训练的时候会出现梯度消失或梯度爆炸的问题,残差连接单元的内部结构如图3所示。

图3 残差单元结构
在残差连接单元中,对于输入特征向量x,输出特征向量y,通过残差连接建立的计算公式为:

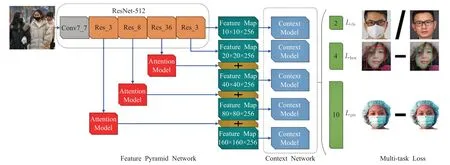
图2 本文算法的网络结构
其中,σ表示线性修正单元(Rectified Linear Unit,ReLU)激活函数,Wi表示权重参数,f(x,{Wi})表示需要学习的残差映射,对于图中三层的残差连接单元,其计算方式如公式(3)所示。相加操作通过快捷连接和逐元素进行相加,相加之后再次采用ReLU激活函数进行非线性化。
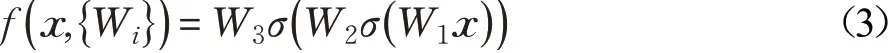
3.2 改进的自注意力机制
本文在特征金字塔网络中引入了注意力机制模块,其内部结构如图4所示,主要包括金字塔注意力机制(Pyramid Attention Mechanism,PAM)和自注意力机制(Self-Attention,SA)。金字塔注意力机制可以增强特征图的表达能力,自注意力可以更好地利用特征的上文关系,提高注意力特征图的描述能力。

图4 自注意力网络结构
在金字塔注意力机制中包括聚合操作、分布操作和描述操作。设输入的特征图包含C个通道,其中的单个通道特征可表示为xi∈RH×W×1,i=1,2,…,C,其中聚合操作利用空间池化fk生成一个k级的空间特征图描述,具体计算方式为:

空间特征图描述随着k的增长会更加详细,为了进一步满足在多任务上的不同需要求,引入敏感性m来度量描述的详细程度,对于敏感性m可以用来描述金字塔池化后的特征向量的集合:

则包含多级特征上下文的空间注意力特征图描述为:

空间特征分布的表达式为:
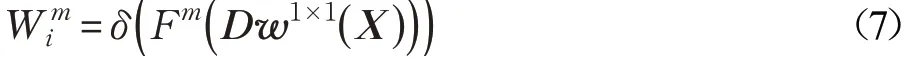
其中,X∈RH×W×C表示输入特征图,Dw1×1表示内核为1×1的深度卷积。Fm表示与聚合操作具有相同敏感性的空间池化特征的集合。δ表示用于归一化的Softmax函数。最后每个空间特征的描述可以表示为:


其中,δ表示Sigmod函数,Xd是由公式(8)获得的所有通道描述的集合。W1∈RC×C/r,W0∈RC/r×C,σ表示ReLU函数。r定义为平衡因子,在所有实验中将其设置为16,以平衡准确性和复杂性之间的关系。最后的输出特征图可表示为:

其中⊗表示逐通道乘法。
3.3 多任务联合损失
本文参考了RetinaFace算法损失函数的设计,为了提高算法的训练速度和检测效率,只保留了相关的分类损失、检测框回归损失和面部标志回归损失,并进行了优化。去掉了面部密集点回归损失。总的损失函数表示为:
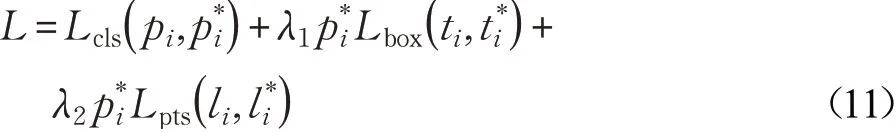
各变量定义如公式(1),其中分类损失Lcls( pi,)是由交叉熵损失函数做的二分类(完整人脸和佩戴口罩人脸),检测框回归损失Lbox( ti,)使用了Smooth-L1损失函数,面部标志回归损失Lpts( li,)同样使用了Smooth-L1损失函数对五个检测的人脸标志点做了归一化处理。另外,本文将损失平衡权值参数λ1和λ2分别设置为0.3和0.1。
4 实验分析
4.1 实验数据集
由于目前没有公开的自然场景人脸口罩佩戴数据集,本文参考WIDER FACE数据集和RetinaFace算法对数据集的处理方法,制作了人脸口罩佩戴数据集。首先从WIDER FACE人脸数据集和MAFA(Masked Faces)[21]遮挡人脸数据集中分别随机抽取1 400张人脸图片和1 600张人脸佩戴口罩图片,共包含16 344张人脸目标和3 127张口罩佩戴目标。然后对数据集进行统一的标注,标注的信息主要有目标框的中心坐标、长度、宽度、类别和五个人脸标注点,示例如图5所示,对应的标注数据如表3所示。其中80%图片用于模型训练,剩余20%的图片用于测试。
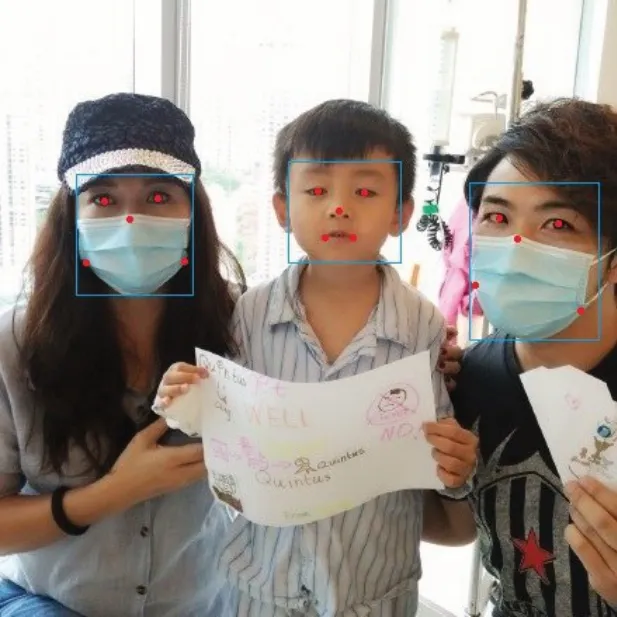
图5 数据集标注示例图片
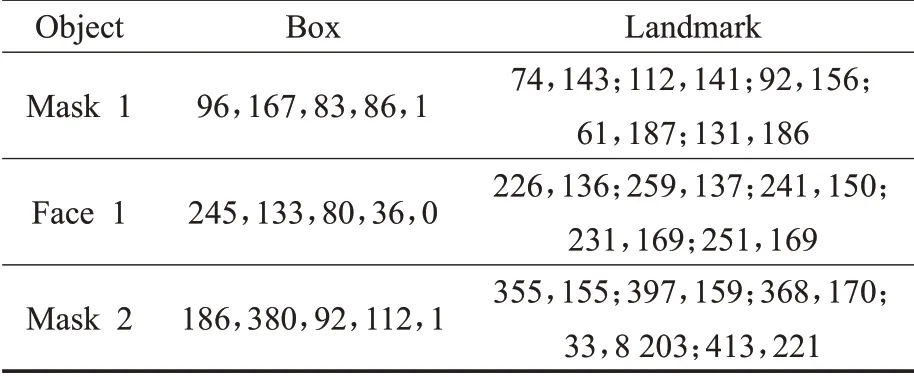
表3 示例图片标注数据
4.2 网络模型训练
本文算法在Ubuntu 18.04操作系统中编程实现,编程语言采用的是Python 3.6,深度学习框架为MXNet 1.0,另外使用GPU加速工具CUDA 8.0。硬件配置主要包括CPU为Intel®CoreTMi7-8700K@3.7 GHz,GPU为NVDIA GTX 1080Ti@11 GB,RAM为32 GB。
训练方式采用随机梯度下降(Stochastic Gradient Descent,SGD)优化模型对网络进训练,动量为0.9,权重衰减为0.000 5,批量为8×4。学习率从10-3开始,当网络更新5个轮次(epoch)后上升到10-2,然后在第34和第46个轮次除以10,整个训练过程一共进行60个轮次结束。
另外,在相同的实验环境下,使用相同的训练方式,本文训练了一个原始的RetinaFace网络模型,用于对比分析。
4.3 实验结果分析
本文将数据集中20%的图片用于实验测试分析,共600张图片,其中包含标注的3 196个人脸目标和684个佩戴口罩目标。评估指标使用目标检测领域常用的ROC曲线(Receiver Operating Characteristic curve)、平均精度AP(Average Precision)、平均精度均值mAP(Mean Average Precision)和每秒帧率FPS(Frame Per Second)来客观评价本文算法对于人脸和口罩佩戴检测的效果。其中AP的值反映单一目标的检测效果,其计算方式为:

其中,p(r)表示真正率(True Positive Rate)和召回率的映射关系,真正率p和召回率r的计算方式为:

其中TP(True Positive,真正数)表示正样本被预测为正样本的个数,FP(False Positive,假正数)表示负样本被预测为了正样本的个数,FN(False Negative,假负数)表示正样本被预测为负样本的个数。本文根据真正率和假正数的关系绘制ROC曲线用来表示对目标检测的性能,如图6所示,其中横轴表示假正数,纵轴表示真正率。总体上看本文算法和RetinaFace算法对人脸的检测效果明显优于口罩佩戴检测,原因是在数据集中人脸目标多于口罩佩戴目标,在模型训练过程中可以学到更多的人脸特征信息。当假正数到达600时,在人脸目标检测上本文算法和RetinaFace的检出率分别为0.938和0.928,在口罩佩戴目标检测上本文算法和RetinaFace的检出率分别为0.853和0.798,可以看出本文算法的检测性能相比RetinaFace算法均有所提高。
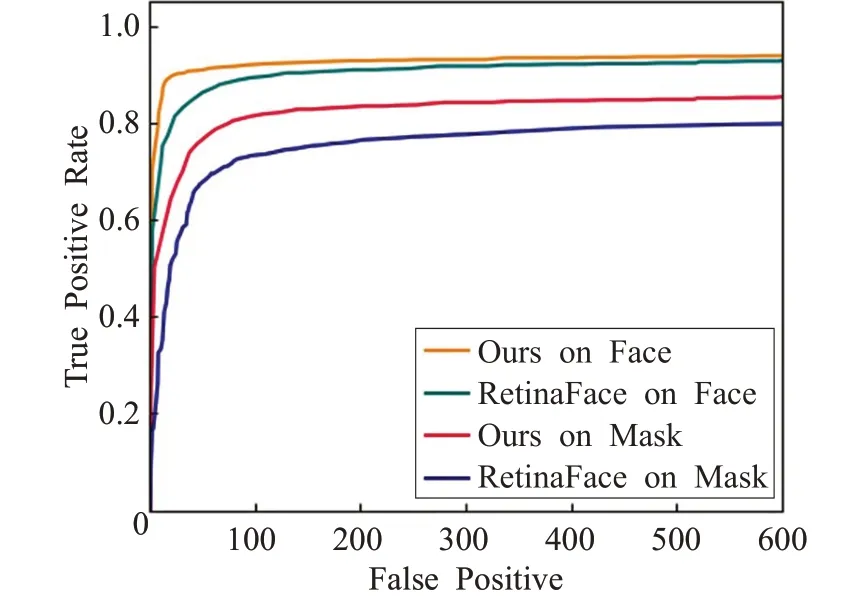
图6 ROC曲线比对数据
mAP表示所有类别平均精度的均值,反映了总体上的目标检测效果,其计算方式为:

其中,n表示类别的个数,i表示某个类别。
每秒帧率(FPS)表示每秒处理的图片数量,用来衡量算法的检测效率。本文将IoU设置为0.5时的实验结果如表4所示。可以看出,由于本文在训练好的RetinaFace网络基础上进行初始化训练,因此在人脸类别的检测上AP值分别高达90.6%和87.3%,在人脸口罩佩戴检测上的取值分别为84.7%和76.5%。总体而言,本文改进的网络模型与RetinaFace相比mAP值提高了5.8个百分点。在检测效率上,本文算法使用注意力机制增加了计算量,检测效率略低于RetinaFace算法。

表4 实验对比数据
从ROC曲线和平均精度均值两个指标上看,本文算法改进后在人脸检测和口罩佩戴检测方面RetinaFace均有一定程度的提高,具体检测示例效果如图7所示,第一行图片中的正常目标,本文算法和RetinaFace均取得了不错的检测效果,正确检测出了图片中的目标信息。对于第二行图片中当包含小尺寸目标时本文算法的检测效果相比RetinaFace提升较大,正确检测出了4个小的人脸目标。对于第三行图片中部分受到遮挡的目标,本文算法相比RetinaFace具有一定的检测能力,分别检测出了一个受遮挡的人脸目标和口罩佩戴目标。对于拍摄环境较差的第四行图片,本文算法的检测能力优于RetinaFace,可以检测出图片中清晰度低的目标。在消融实验中进一步具体分析了本文提出的改进方法对模型检测能力的影响。

图7 口罩佩戴检测效果对比示例
4.4 消融实验
消融实验是深度学习领域常用的实验方法,用来分析不同的网络分支对整个模型的影响[22]。为了进一步分析本文通过引入自注意力机制对模型进行口罩佩戴检测的影响,进行了消融实验,首先将本文算法裁剪成四组分别进行训练,然后对测试集中的检测目标进行分类,目标像素小于32×32的为小目标(Small),目标标注点小于等于3的为缺损目标(Defect),其余的为正常目标(Normal),最后测试不同实验组在不同目标类别上的mAP,实验结果如表5所示,第二组网络中增加了金字塔注意力机制,在三种类别上的mAP值相比第一组网络分别提升了4.5、2.8和8.4个百分点,提升最高的是小目标类别,这是由于在金字塔注意力机制中使用了聚合操作、分布操作和描述操作,在通道中有效保留了小目标的特征信息,增强了特征图的表达能力,提高了小目标的检测效果。
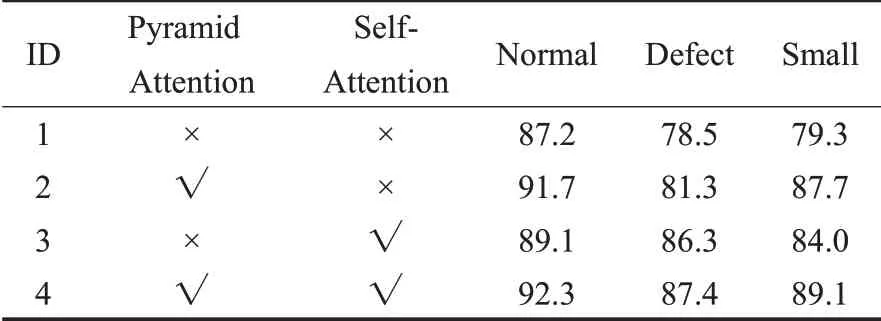
表5 消融实验中mAP值对比数据 %
第三组网络中引入了自注意力机制,在三种类别上的mAP值相比第一组分别提升了1.9、7.8和4.7个百分点,提升最高的是缺损目标,这是由于通过自注意力机制使得特征图在空间上增强特征上下文之间的联系,使用少量的特征点也能更好地描述特征图的信息。相比第二组网络,在三种类别上的mAP值分别提升了-2.6、5.0和-3.7个百分点,可以看出单独使用自注意力机制在正常目标和小目标检测上弱于单独使用金字塔注意力机制,这是由于自注意力机制无法抑制特征图通道上无用信息的干扰,使网络学习得到了无关的信息描述,从而影响了网络的检测效果。
第四组网络使用了金字塔注意力机制和自注意力机制在三种类别的目标上均取得了最优的检测结果,说明本文改进的注意力机制结构的合理性和有效性。
4.5 自然场景口罩佩戴检测实验
为了验证本文算法在自然场景下口罩佩戴检测的效果,在视频中进行了测试实验,实验结果如图8所示,该视频是从互联网中爬取,视频尺寸为450×360,帧速率为25.0帧/s,可以看出,在整体上本文算法可以有效地对视频中人脸口罩佩戴进行检测,但也有漏检的情况出现,其中图8(b)出现了一个错检测目标。另外,在视频内容进行画面切换的帧中,出现了检测失真的情况,如图8(d)所示,原因是本文算法在处理视频中口罩佩戴检测时效率不足,这也是在未来的工作中需要改进的地方。

图8 视频中口罩佩戴检测效果
5 结论
本文通过改进RetinaFace算法,提出了一种自然场景下人脸口罩佩的检测方法,该方法通过在特征金字塔网络中引入注意力机制,分别使用了金字塔注意力机制增强特征图在通道上的表达能力,并抑制无用信息,使用自注意力机制在特征图的空间上增强了上下文联系和特征描述能力,最终提高了对多尺度目标的检测效果。实验通过在本文建立的3 000张图片的数据集上进行训练的结果表示,本方法可以有效检测自然场景下佩戴口罩的人脸和没有佩戴口罩的人脸,平均精度均值达到87.7%,每秒帧率为18.3帧/s,另外在自然场景视频检测中也取得了不错的效果,证明了本文算法框架的合理性。在未来的研究中,将进一步对网络结构进行优化,使用更多的数据集对网络模型进行训练,提高人脸口罩佩戴的检测能力和检测效率。
猜你喜欢
环球时报(2022-09-19)2022-09-19
小雪花·成长指南(2022年1期)2022-04-09
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
考试与评价·七年级版(2020年4期)2020-10-23
少儿美术(快乐历史地理)(2019年2期)2019-06-12
动漫星空(2018年9期)2018-10-26
小学教学研究·新小读者(2017年9期)2017-10-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
