
渗透缓存命中率诱导的缓存区域动态分配机制研究
2020-06-19 08:45李灵枝胡九川叶笑春范东睿严龙
软件导刊 2020年4期
李灵枝 胡九川 叶笑春 范东睿 严龙

摘要:为解决计算机体系结构性能瓶颈——存储墙问题,在依赖硬件技术和体系结构创新的同时,还需优化程序算法。传统算法主要以时间和空间复杂度作为衡量指标,未考虑计算机存储结构设置。延迟避免和延迟容忍机制是解决“存储墙”问题的新途径。借助一种新型缓存结构——渗透缓存可缓解该问题。利用延迟容忍机制,通过研究渗透缓存模型在处理器片上数据调配方式,提出一种依据历史访存命中率变化情况动态调控渗透缓存容量机制(以下简称动态渗透机制)。通过改进数据在渗透缓存上的调配策略,使缓存容量动态适应程序的数据特征,经过调整得出命中率更高的缓存结构配置方案。阐述了动态渗透机制原理与仿真实验模型架构。仿真实验结果表明,在SPLASH-2的部分测试集下,与传统缓存命中率相比较,平均提高了7.629%;以动态渗透机制得出的缓存容量配置方案命中率比传统缓存平均提高31.003%。即在缓存结构改进的动态渗透机制下,访存命中率得到提高,从而缓解了“存储墙”问题。
关键词:渗透缓存;存储墙;动态缓存分区;缓存容量
DOI: 10. 11907/rjdk,192752
开放科学(资源服务)标识码(OSID):
中图分类号:TP301
文献标识码:A
文章编号:1672-7800(2020)004-0001-08
Research on Dynamic Allocation Mechanism of Cache Area Induced
by Percolation Cache Hit Ratio
LI Lingz-hil. HU Jiu-chuanl . YE Xiao-chunz . FAN Dong-ruj2 , YAN Lon2
(1.SchooL of Computer and Information Technology , Beijing Jiaotong University , Beijing 100044 , Ch.ina ;
2.State Kev Laboratory of Computer A rchitectu re,Institute of Computing Tecnolog了 ,
Clzine..se Academy of .Science.s , Beijing 100 190 . Clzina )Abstract: In order to tackle the performance bottleneck of computer architecture development-memory wall.while rely ing on the in-novation and development of hardware technology and architecture, it is necessary to optimize the program algorithm. Traditional algo-rithms mainly use time and space complexity as a measure. and do not consider the setting of computer storage structure. Delay avoid-ance and delay tolerance mechanisms are new ways to solve the memory wall problem. With the help of a new precolation cache struc-ture and delay tolerance mechanism. this paper proposes a mechanism to dy namically adjust the precolation cache capacity accordingto the change of historical hit rate by studying the allocation method of the precolation cache model on the processor chip. By improvingthe dispatch strategy of' data on the precolation cache storage structure, the capacity of the cache can dvnamically adapt to the charac-teristics of' the program and adjust the cache structure configuration scheme with a higher hit rate.Key Words : percolation cache; memory wall; dynamic cache partition; cache capacity
收稿日期:2019-12-16
基金項目:国家自然科学基金项目(61732018)
作者简介:李灵枝(1995-),女,北京交通大学计算机与信息技术学院硕士研究生,CCF会员,研究方向为计算机体系结构、软件工程;
胡九川(1965-),男,博士,CCF会员,北京交通大学计算机与信息技术学院副教授,研究方向为计算机体系结构、范畴论;叶笑春(1981-),男,博士,中国科学院计算技术研究所计算机体系结构国家重点实验室副研究员,研究方向为众核处理器设计;范东睿(1979-),男,博士,CCF会员,中国科学院计算技术研究所计算机体系结构国家重点实验室研究员,研究方向为高通量众核处理器体系结构;严龙(1988-),男,硕士,中国科学院计算技术研究所计算机体系结构国家重点实验室工程师,研究方向为计算机体系结构。
本文通讯作者:李灵枝。
O 引言
访存延迟是造成存储墙问题的重要原因之一,也是高性能、高通量计算性能提高的主要瓶颈之一[1-2]。通过预取技术可以隐藏长时间访存延迟,降低代价高昂的流水线停滞概率,以缓解存储墙问题。为保证预取的有效性和准确性,需要在预取策略中权衡不同影响因素,如在恒定步幅预取中合理设置预取步幅,在全局历史缓冲预取中合理设定要观测的历史数据范围。显然,要节省处理器资源,提高预取器的准确度,无疑会增加预取算法的复杂度和技术难度。无论采用何种预取方法,扩大预取范围都会导致数据准确度降低,不准确的预取更会污染缓存,导致处理器性能下降。
为了更好地权衡预取精度与预取范围的关系,本文将预取思想融合到渗透技术中,改变过去由缺失数据触发预取的传统模式,实现将数据源源不断的涌向处理器核周围的动态渗透机制。渗透技术是预取技术的深化,指在处理器访问某个数据之前即预测到处理器需要该数据并将其预先取到片上缓存中,从而避免较高的访存延迟。动态渗透机制通过在应用程序的访存过程中设置固定检查点,定期检测应用程序的访存命中率,据此动态调配渗透缓存容量,以达到提高访存命中率目的。
静态渗透研究[3-4]提出以泉吸和泉涌缓存作为数据载体的新型层次存储结构模型,结合该模型提出相应的静态渗透数据调配方式。由于固定统一的缓存数据调配方式不能灵活动态地对不同访存模式各程序区分处理,使得渗透缓存对处理器发来的访存请求只能机械地作出回应,导致渗透缓存存儲结构优势未充分利用。为解决上述问题,本文提出有针对性地对不同访存模式程序进行渗透处理算法,依据历史访存命中率数据动态调控渗透缓存容量,充分利用数据渗透缓存结构优势,快速分析访存踪迹,挖掘出该程序总体访存数据特征,识别当前程序的访存模式,经过多轮动态反馈机制,最后找到最适合当前程序访存特征的缓存存储结构配置方案,并通过实验仿真检验算法结果。
仿真实验结果表明,在SPLASH-2的部分测试集LU、WORDCOUNT、CHOLESKY和RANDOM下,动态调控缓存命中率比传统方式分别提高6.3482%、3.3021%、0.5124%、20.3538%.在动态渗透算法得出的缓存配置方案下,缓存命中率分别提高84.6522%、4.9791%、9.8053%、24.5741%,表明动态渗透算法能够避免访存延迟,提高处理器性能。
1 相关工作
为避免访存延迟影响计算机性能,人们不断改进缓存技术、软硬件预取、多线程和乱序执行思想以及工业集成技术。顺序预取[5]、步幅预取[6]、马尔可夫预取[7]以及全局历史缓冲预取[8]等技术不断在改进中发展,虽然预取已经取得了很好效果,但被动的、不适用于多级层次缓存结构的缓存处理方式,以及不能良好平衡预取精度和预取范围的预取技术,需要结合渗透思想作进一步改进,从而更好地缓解存储墙问题,提高处理器性能。
渗透技术最初在文献[9]中以线程渗透一词提出,旨在充分利用处理器上的硬件线程资源达到线程间相互容忍延迟的目的。由于需要软件环境支持,线程渗透目前暂未实现;文献[10]提出渗透延迟容忍模型,将存储空间划分为低延迟的核内存储空间和高延迟的核外存储空间,并允许并行访问。该文献只对特定问题进行了研究,对于求解其它非规则问题则暂未给出证明;文献[11]提出N-层渗透执行模型,旨在线程执行时就把下一线程所需数据准备好,并把前一线程所访问过的数据渗透存储到下一级缓存中;文献[12]分解了访存操作,从线程仿真层面动态决定计算操作和访存操作的时序关系,明确数据在存储层次中的移动方向。由于渗透操作需程序员人为显式指定,使技术实现较为困难;文献[3]、文献[4]从缓存结构层面深入分析渗透数据在存储层次中的移动轨迹,提出改进的渗透缓存结构和相应数据调配方式。由于对不同程序采用统一、静态的缓存调配方式,忽略了探究不同程序数据特点,仿真实验虽取得了良好效果,但对数据局部性研究空间还很大。
预取技术与渗透技术的研究重心大多集中在数据到达处理器前的阶段,即未被处理器访问过的数据。文献[13]、文献[14]指出,在研究缓存数据整体特征时,被处理器访问过的数据同样具有重要价值;文献[13]提出定向反馈预取机制,结合特定历史数据信息动态调整预取数据的存放位置。借助预取请求的准确性、及时性和由预取引起的缓存污染估计预取器的有效性;为了改善多核系统中共享缓存的分区策略,文献[15]、文献[16]提出由初始化、回滚和重分区3阶段实现的缓存分区算法,实验证明该策略可以提高多核系统的吞吐量,改善系统公平性。本文综合前人研究,提出单核处理器片上对三级渗透缓存进行动态分区的动态渗透算法,将调配数据方式从被动预取转变为主动预取,明确定义了焦点数据和渗透数据。在缓存数据到达和离开处理器的整个过程中充分利用数据的及时局部性减小访存延迟,以找到缓存结构配置的更优方案。
2研究内容
2.1动态渗透缓存结构
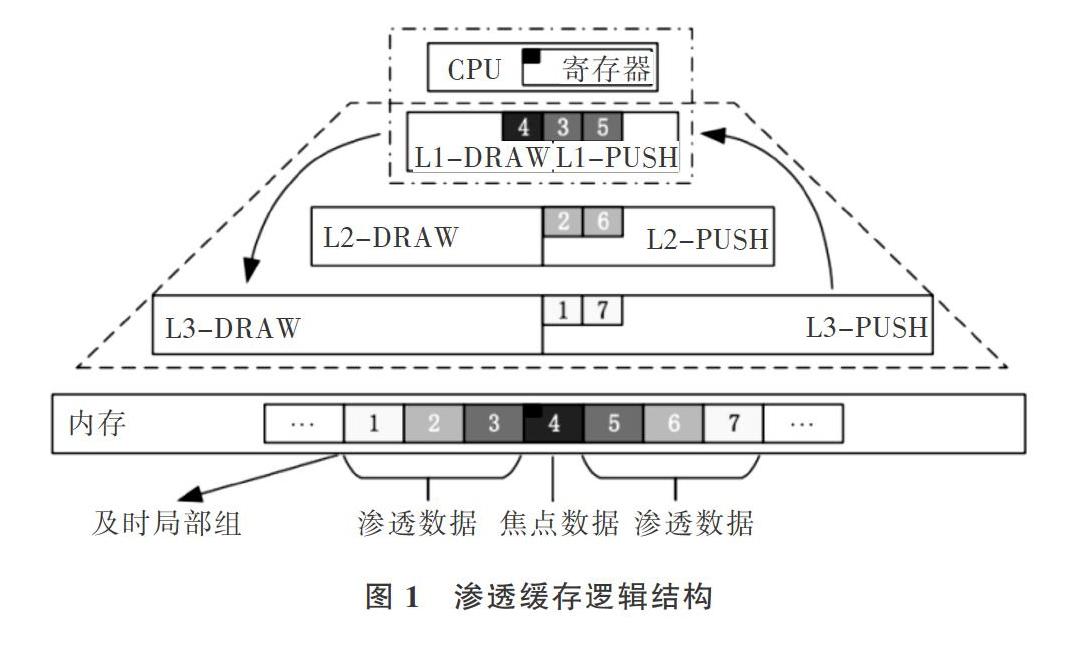
本文依据数据的及时局部性特征定义一个及时局部组,如图1所示,下面从时间和空间两方面解释缓存数据的及时局部性。在局部时间内,刚被处理器访问过的数据再次被处理器访问的概率较大;在局部空间内,刚被处理器访问过的数据前后紧邻的数据块在局部时间范围内被访问的概率也较大。不同距离间隔和时间间隔都会造成应用程序在及时局部性上的差异波动。稳定的数据及时局部性是缩小访存延迟,提高处理器性能的基本保证。图
李灵枝,胡九川,叶笑春,等:渗透缓存命中率诱导的缓存区域动态分配机制研究1中,焦点数据为处理器主动要访存的数据(红色小方块);焦点数据所在块为焦点数据块(缓存块4);与焦点数据块紧邻的缓存块1、2、3、5、6、7为渗透数据块,显然渗透数据块对于焦点数据块来说具有更好的及时局部性。
为有效保证处理器访问某数据时,该数据恰好刚刚到达处理器周围的片上存储空间中,既不过早也不过晚,本文采用兼具时间局部性和空间局部性的三级渗透缓存代替传统缓存。渗透缓存结构和传统缓存结构区别如图1所示,每级缓存都由两个性质不同的泉吸缓存( SpringDraw Cache)和泉涌缓存(Spring Push Cache)构成。SDC存储焦点数据块,即被访问过的数据,主要负责维护数据的时间局部性关系。SPC存储渗透数据块,即未被访问过的、焦点数据周边的数据,主要负责维护数据的空间局部性关系。各级渗透缓存分别赋予不同的、针对处理器内核访存行为特点的数据缓存功能。当焦点数据块被迁移到处理器中使用时,一个及时局部组中的渗透数据块,会根据与焦点数据的不同距离主动迁移到各级SPC缓存中。当处理器用完焦点数据时,焦点数据块会根据迁出处理器时间的长短,依次以优先级由高到低地按一级、二级、三级泉吸缓存顺序迁移到SDC中。
宏观上数据的流通方向如图1中红色箭头所示,渗透数据从内存迁到SPC,焦点数据从处理器迁到SDC。渗透缓存的缓存单元由有效位valid、标记tag和数据data三部分构成,多个缓存单元构成一个渗透缓存,如图2所示。在程序执行过程中,渗透数据会随着焦点数据的移动而动态改变,那些主动渗透迁移到片上的各级缓存数据汇聚在一起,随着焦点数据的流动,源源不断地流向处理器核周围,形成一种处理器被数据包围起来的态势,以提高处理器访存的命中率。
在处理器访问焦点数据时,渗透数据块会被搬运到泉涌缓存中来,按照它们与焦点数据块在内存中的距离划分重要程度,数据块越重要就放置在泉涌缓存的越高层级。随着访问继续,泉涌缓存中的数据块重要程度发生变化,更重要的数据块会搬运到更高的层级。因此,即使处理器访问泉涌缓存中的数据块在该数据块还未到达最高层级的泉涌缓存中,也可能已经在低层级的泉涌缓存中,这样就避免了过长的访存延迟。
2.2动态渗透调配原理
不同配置的缓存结构会导致缓存命中率出现明显差异。由于不同程序具有不同访存轨迹特征,所以不同容量配置的渗透缓存其命中率也会有所波动,如果将固定统一的渗透缓存结构用于迥然不同的访存程序中,很可能导致渗透缓存的性能优势不能更好利用,因此本文提出适用于非特定应用程序的、可动态改变渗透缓存容量的调配策略,以进一步挖掘渗透缓存的性能优势。
为了充分兼顾数据的时间与空间及时局部性,设置处理器访问渗透缓存的顺序为第一级缓存到第二级缓存再到第三级缓存,在每级缓存内部先访问SDC再访问SPC。渗透操作在处理器发出访存请求时展开,渗透数据的同时隐藏了处理器访问已渗透到缓存中数据的加载延迟,从而达到延迟容忍的效果。举例说明一轮渗透操作如下:每当处理器发出读写请求便触发一轮动态渗透操作,在一轮动态渗透过程中一个及时局部组中的数据块全部主动迁移到指定缓存中,其中焦点数据被迁移到处理器中直接使用,焦点数据块迁移到第一级SDC中,以当前焦点数据块为中心的一个及时局部组中的渗透数据块3和5迁移到第一级SPC中,渗透数据块2和6迁移到第二级SPC,渗透数据块l和7迁移到第三级SPC,过程如图1所示。
本文提出的动态渗透机制主要分为两个环节,第一环节先通过分析不同程序独有的数据特征,经过多轮动态调整后,得出最符合当前程序的缓存结构配置方案,仿真实验结果表明在此过程中,动态缓存的命中率比传统缓存高。前义中提出的多轮调整最多需要四轮,初始条件下SDC和SPC在第一、二、三级SDC和SPC上都是平均分配缓存容量大小;在程序运行到第一个监测点时,执行第一轮动态渗透,通过两两三组SDC和SPC的命中率大小比较可能得出两种调整方向;在选择了当前最优的调度方案后,继续渗透操作;在到达第二个监测点时开始执行第二轮调整,此时比较以第一轮调整后的缓存容量分配方案下SDC和SPC的命中率分布情况,同样有两种调整方向,选择最优的分配方案,继续后续渗透操作;在到达第三个监测点时开始执行第三轮调整,此时动态调整的方向需要分情况讨论,如果在同级缓存内第一、二轮调整是同时有利于SDC( SPC)的,此时需要选择有利于SPC(SDC)的方向进
行调整,目的是为了通过第四个监测点时,验证得出是否前者是最终渗透方案;如果在第三轮动态渗透时发现第一、二轮动态渗透是互逆的渗透操作,则直接比较第一、二轮动态调整后,同级SDC和SPC中各白的命中率表现,选择命中率较高的作为最终渗透方案,并且不再需要第四輪动态渗透了
动态渗透机制的第二环节主要为了验证第一环节得出的方案是否是更有效的,因此以第一环节得到的缓存配置方案作为初始条件再一次去仿真验证,实验结果表明渗透缓存在此基础上的命中率能被进一步提高。
2.3历史命中率诱导的渗透缓存容量动态调控算法
本文中定义(l)为渗透缓存中泉吸、泉涌的命中率表示:
其中上标j为渗透的轮数;下标Cl为第i级泉吸或泉涌缓存,d为SDC,p为SPC,i为渗透缓存级数,如d2表示第二级泉吸缓存;白变量x为渗透数据的时钟周期为缓存ci的命中次数;为访问缓存Cl的次数;为缓存ci的容量大小;表示动态调控因子;signa/:表示动态渗透调整信号,可取0,l两种情况
用式(2)表示第i轮动态调控过程中渗透缓存的总命中率。
设置t为四个动态调控的时间点如图3所示,在T0时刻到t1。时刻为第一轮渗透,第二、三、四轮渗透依次类推。t0时刻开始动态渗透,初始化操作,将各级渗透缓存平均分配给泉吸泉涌缓存;之后开始对渗透缓存进行第一、二、
三、四轮动态调控并得出结果。
算法Y:依据历史访存命中率变化动态调控渗透缓存容量算法。
输入:
输…:
tl时刻进行第一轮动态渊控
t2时刻进行第二轮动态调控
t3时刻进行第三轮动态渊控,为l时,在t4时刻进行第四轮动态渊控
结合前文提出的动态渗透机制,概述动态渗透算法调控过程如下:
t1时刻:计算各级渗透缓存中,的值,大的增加倍容量,小的减小倍容量,调整结束后发送给各
李灵枝,胡九川,叶笑春,等:渗透缓存命中率诱导的缓存区域动态分配机制研究个缓存模块调整信号,等待第二轮动态调控;
时刻:计算和,若高,则反向调整同级间SDC和SPC的大小,调整后发送给各个缓存模块调整信号,否则不调整,等待第三轮动态调控;
t3时刻:若第二轮反向调整,比较,选择值最大时缓存大小分配比例;若第二轮没反向调整,且 大于 ,则反向调整并等待第四轮动态调控,否则选择第三轮缓存大小分配比例;
t4时刻:由于只有在第二、三轮渗透参数一致的情况下,才会有第四轮比较,所以此时,直接比较 ,选择值最大时的缓存大小分配比例,即为动态渗透得出的最佳分配比例。
3仿真实验
3.1仿真平台模块设计
本文的关注焦点在于渗透缓存,所以仿真实验设计主要实现处理器、渗透缓存、内存以及动态渗透主要和缓存密切相关的模块,渗透缓存动态调控原理和功能逻辑结构如图4所示,各个模块功能依次如下:
处理器模块负责读取测试集中的访存地址,解析焦点数据和渗透数据地址;再将渗透请求信号和地址信号发送给渗透缓存模块;等待动态渗透模块发来的一轮渗透完成信号和动态渗透信号,一旦收到一轮渗透完成信号,则处理器模块开始获取下一条访存地址。一旦收到动态渗透信号,则动态调整后续渗透操作中的渗透参数。如此循环直至访存踪迹文件读完。
渗透缓存模块收到来自处理器或上级缓存发来的渗透请求信号和地址信号后,判断是否在当前缓存命中。若未命中则该请求继续发送给下级缓存或内存;若命中,则将即将被覆盖的数据迁移到下一级缓存中。每完成一个渗透数据块迁移操作,缓存模块便给动态渗透模块发送一个单次渗透完成信号。
内存模块处理来白缓存的渗透请求信号、来自泉吸缓存的替换请求信号。将在缓存中缺失的渗透数据块复制给相应的缓存。
动态渗透模块收集来自渗透缓存模块的一次渗透完成信号,一旦这些信号达到一轮渗透操作应该迁移的数据块个数,就给处理器模块发送一个一轮渗透完成信号。一旦时钟周期到达设定好的时间点,就依次开始四轮动态调控操作,一轮动态渗透完成时发送对应信号给处理器和渗透缓存模块,使得在后续的访存操作渗透缓存容量得到动态改变。
3.2渗透缓存参数设置
本文通过仿真平台实现了传统缓存模型和动态渗透缓存模型。传统缓存是目前通用处理器芯片中采用的三级缓存模式,动态渗透缓存模型为上文介绍的三级泉吸泉涌缓存,两种缓存的访存顺序分别如图5、6所示。处理器访问传统缓存时依次访问第一级、第二级、第三级缓存,若在第一级缓存发生命中,则直接对数据进行读写操作;否则,将数据所在的数据块从下级缓存或内存中取到第一级缓存中再进行读写操作。
处理器访问渗透缓存时,先根据图5中指定的访问顺序依次访问渗透缓存,如果处理器访问的数据在泉涌缓存命中,则该数据被迁移到第一级泉吸缓存,同时把及时局部组中没有迁移到泉涌缓存中的数据渗透进来;如果处理器访问的数据在泉吸缓存命中,则该数据不发生迁移,也不发生数据渗透;如果要访问的数据没有在渗透缓存中命中,则访问内存,同时出发一轮全新的渗透操作,即将处理器访问的数据发送给第一层泉吸缓存,将及时局部组中其余的渗透数据发送给各级泉涌缓存。当渗透数据到达时,若泉吸缓存已满,则渗透过来的新数据需覆盖原来的数据,同时被覆盖的数据被迁移到下级泉吸缓存或内存中。
渗透缓存只要处理器发出读写访存请求,都将触发一轮渗透数据的迁移过程,而传统缓存只迁移当前数据块到缓存中。显然,处理器访问传统缓存始终只对所访问的数据所在的那一个数据块进行操作,而处理器访问渗透缓存则需要对及时局部组中所有的数据块进行操作。
仿真实验中传统缓存和渗透缓存参数配置如表1所示,渗透缓存和传统缓存的总容量大小相等,动态渗透算法通过改变缓存的组数实现对缓存容量的动态分配。
3.3实验结果
由于渗透缓存的结构以及数据搬运数量、调配方法跟传统缓存在较大区别,若采用传统缓存的周期时间计算方法作为动态渗透缓存的性能评估指标,其准确性和有效性有待商榷。因此本文采用文献[17]中对多级缓存的耗时估算方法作为动态渗透缓存的性能评估指标,该估算方法中的關键参数为缓存命中率,一般而言,命中率越高缓存性能越高,因此渗透缓存命中率可作为现阶段评估缓存性能的主要指标。考虑到缓存是处理器的重要耗能单元,在本文提出的机制中,每次访存操作都有可能会触发相关渗透操作,即将会有更多的数据换入和换出操作,可能会导致能耗开销增加,所以本文通过在单位时间内处理相同数据所消耗的时间来衡量渗透缓存所带来的额外功耗。
本文选用的测试基准用例为斯坦福大学开发的“面向共享存储的并行应用程序( Stanfo-d Parallel Applications forShared Memorv)”第二版(SPLASH-2),测试集中的访存踪迹是由C语言和pthread编写的多线程程序生成。本文为了体现时间和空间局部性,选用了SPLASH-2测试集中Choleskv、连续LU为核心测试用例。其中Choleskv将一个稀疏矩阵表示分解为一个下三角矩阵及其转置;连续LU将一个密集矩阵分解为一个上三角矩阵和一个下三角矩阵的乘积,并允许相邻的数据被划分到同一个块中,分解时使用分块访问技术来挖掘每个独立子块中的时间局部性。此外,本文还选用普通的Wordcount程序的访存踪迹和随机生成的访存踪迹作为测试集进行仿真实验,验证动态调控算法的普适性。
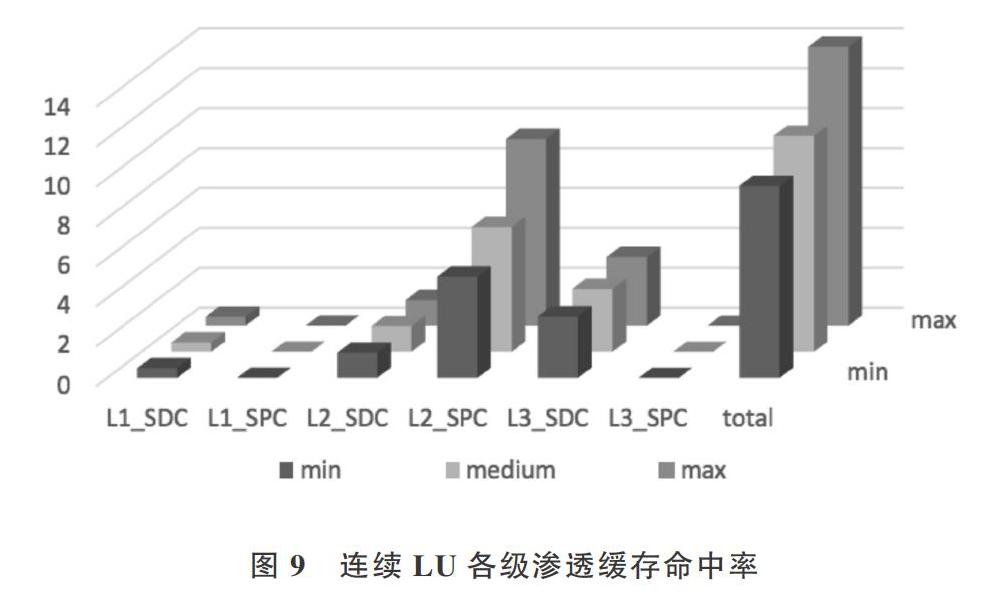
各个测试集中三级渗透泉吸、泉涌缓存的仿真结果命中率表现分别如下图7、8、9、10所示,文献[14][18]中指出过多的依赖历史数据会导致算法的效率降低,即良好的算法需要在普适性、简单性和累积参照数据之间取得平衡。因此本文设计仿真实验时,设置了不同大小的历史数据作为累积信息,用¨表示,其中min表示在一轮动态渗透的过程中参考的历史数据大小为总测试集的2.5%,mid与max分别为5%和10%。
实验结果表明在随机访存踪迹、Choleskv和Wordcount测试集下,泉吸缓存的命中率相对较高,即被访问过的数据更趋向于再次被访问,数据的时间局部性较好。而在连续LU测试集的情况下,第二级泉涌缓存和第三级泉吸缓
动态渗透算法在不同测试集下的时间消耗如下图11所示。传统表示传统的三级缓存;动态一1结果是在动态调控渗透过程中得出的结果,即动态渗透算法的第一环节;动态一2结果是以动态渗透算法得出最佳渗透缓存容量配置为初始条件时得到的结果,即动态渗透算法的第二环节;静态表示静态渗透得到的结果。存的命中率相对更高,即与焦点数据块隔一个数据块的数据和被访问过的数据更可能被访问,即及时局部性整体较好。
李靈枝,胡九川,叶笑春,等:渗透缓存命中率诱导的缓存区域动态分配机制研究
上图中,相较于传统的三级缓存而言,新型的以SDC、SPC构成的三级渗透缓存虽然在命中率上有所提高,但是在耗时上也有明显增加。可以看出,动态渗透相较于静态渗透而言,功耗依然是较小的;在LU测试集下动态渗透的两个阶段所消耗的时间有明显波动,在动态一1的渗透阶段SDC和SPC容量的动态调整过程中,缓存数据的换入换出破坏了LU连续测试集(将一个密集矩阵分解为一个上三角矩阵和一个下三角矩阵的乘积,即矩阵被分解为一个一维的数组,允许相邻的数据被划分到同一个块中,即时间局部性较好)原本良好的时间局部特性,造成读取完同样的测试数据时,所耗时间较大。
动态渗透算法在各个测试集下仿真实验结果如表2和所示图11所示。根据实验结果可以得出,在随机访存踪迹测试集下,越小渗透缓存命中率越高;在连续LU测试集下, 越大渗透缓存命中率越高,不同 的命中率相差明显;在Wordcount测试集下,渗透缓存命中率在 取5%时表现最好,过小和过大的 都会导致渗透缓存命中率都会下降。
图12表明,动态渗透算法能够充分挖掘数据的及时局部性,针对不同程序的不同访存模式给出针对性的、命中率更高的渗透缓存容量分配方案。图13展示了动态渗透算法在各测试集下带来的性能变化。
相对于传统缓存而言,在执行动态渗透的过程中渗透缓存命中率在全部测试集上都有所提高,相较传统缓存,渗透缓存命中率分别提高6.3482%、3.3021%、0.5124%、20.3538%:在动态渗透算法得出的缓存配置方案设置下,缓存命中率分别提高84.65 2%、4.979 1%、9.805 3%、24.5741%,实验结果表明动态渗透算法能够进一步避免访存延迟和提高处理器性能;动态渗透结果比静态最优配置时的命中率平均提高2.07%;在测试集Cholesky的情况下,动态渗透算法得出的缓存容量分配方案相对于传统缓存都有所提高,但是相对于静态渗透,命中率反而降低了0.0033%,原因是在动态改变渗透缓存容量由大变小时,迁移数据会导致访存延迟急剧增加,因此只能牺牲容量被调小的缓存中已有的数据;当缓存容量由小变大时,新增缓存是未迁移数据的空白空间,随着处理器后续的访存需求,数据被迁移进来。在此过程中,若访问被牺牲掉的数据会造成命中率在极小范围内有所下降。
由于传统缓存模型中主要考虑数据向处理器核聚集的过程,未考虑数据往外流动的过程,而本文提出的动态渗透机制不仅通过泉涌和泉吸两个方向的渗透操作,保证数据流人和流出的有序控制,同时泉吸机制能够更好地满足数据的时间重用性,对于时间重用步长较短的数据可以高效地再次访问到,避免了数据的频繁换出,减少了内存抖动。
4 结语
本文在静态渗透基础上提出的依据历史访存命中率的变化动态调控渗透缓存容量的算法,其性能较之传统缓存和静态渗透缓存有较大提升。由于程序访问的局部性原理,及时局部组中的数据块下次被访问的可能性较高,并且不同程序的数据特征在SDC和SPC上有不同的性能表现,因此合理、动态的配置各级渗透缓存容量的大小有利于创造更优良的数据及时局部性,以提高处理器性能。
通过仿真实验得出结论:动态渗透机制深入地挖掘了数据的时间和空间局部性,由于SDC和SPC的大小比例配置要视程序的局部性情况而定,不同的配置会使渗透缓存的性能表现各不相同。动态渗透机制通过对不同访存模式的应用,经过动态多轮调整和检验得出较为适合当前程序的渗透缓存容量配置方案。
在仿真实验中,本文为了直观的和静态渗透作出对比,采用了评估传统缓存的缓存周期时间模型(CVcle TimeModel)计算方法和单位时间耗时量作为评价动态渗透缓存性能的标准,在其他功耗方面的研究还需推出一种更合理、全面的评价指标,因此为了更加全面有效地评估动态渗透机制对处理器的性能贡献,迫切需要研究出一种适合渗透缓存的周期时间计算方法。本文从三级SDC和SPC容量的角度研究了动态调控渗透缓存容量的机制,后续研究T作中,我们将进一步讨论对前文提出的及时局部组数据的概念,是否可以通过对一轮渗透中的数据块的个数进行动态调控,进一步完善对渗透缓存动态调控机制的研究。
参考文献:
[1]胡九川,范东睿,李丹萍,等.一种支持数据渗透迁移的片上缓存模型研究[J].北京交通大学学报,2017,41(5):1-9
[2]李丹萍.单核处理器片上渗透数据调配方法研究[D].北京:北京交通大学 . 2016.
[3]HASHEMI M. KHUBAIB N. EBRAHIMI E, et al. Accelerating De-pendent Cache Misses with an Enhanced Memorv Controller[C] . Acm/ieee International Sympnsium on Computer Architecture. IEEE , 2016.
[4]GALR J, CHALDHURI M. RAMACHANDRAhr P, et al. Near-Opti-mal Ac.cess Partitinning for Memory Hierarchies with Multiple Hetero-geneous Bandwidth Sourc.es [C]. IEEE International Symposium onHigh Performance Computer Architecture. IEEE. 2017, 4-8 (2)13-24.
[5]SMITH A J. Seqential program prefetching in memory hierarchies FJl.
Computer, 1978, 11( 12) :7-21.
[6]FU J W C, PATEL J H. JANSSENS B L. Stride directed prefetchingin scalar processors [C]. International Symposium on Microarchitec-ture. ACM . 1992
[7]JOSEPH D, GRUNV'ALD D. Prefetching using markov predictors [Cl. International Symposium on Cnmputer Architecture. ACM,
1997 : 252-263.
[8]NESBIT K J, SMITH J E. Data cache prefetching using a glohal histo-ry bufferl J]. Micro IEEE , 2005 , 25( 1) : 90-97.
[9]GAO G R, THEOBALD K B. STERLING T L. et al. Programmingmodels and system software for future high-end computing systems:work-in-progress [Cl. International Parallel & Distributed Process-ing Symposium. IEEE . 2003.
[10]TAN G. SLN N, GAO G R. Improving performance of dynamic pro-gramming via parallelism and lr)cality on multicnre architectures [J] .IEEE Transactions on Parallel & Distributed Systems , 2008. 20(2) : 261-274.
[11]袁楠眾核处理器中访存延迟容忍和避免技 术的研究[D] .北京 : 中国科学院 i-l算技术研究所 . 2010.
[12]GARCIA E, OROZCO D. KHAN R, et al. A dynamic schema tn in-crease performance in many-core architectures through percolationoperations [C] . International Conference on High Performance Com-puting. IEEE Computer Society, 2013.
[13]SRINATH S, MUTLL 0, KIM H, et al. Feedhack directed prefetch-ing: improving the performance and bandwidth-efficiency of hard-ware prefetchers [C]. IEEE International Symposium on High Perfor-mance Computer Architecture. IEEE Computer Society, 2007.
[14]JAIN A. LIN C. Rethinking helady's algorithm to acc.ommodateprefetching[Cl. ISCA Fair cache sharing and paititioning in a chipmultiprocessor arc:hitecture . 2004.
[15]KIM S, CH D. SOLIHIN Y. Fair cache sharing and partitioning in achip multiprocessor architecture [C]. Partitioning in multiprocessorarchitecture .2004
[16]王磊 ,刘道福 , 陈云霁 ,等.片上多核处共享资源分配与调度策略研究综述[J] .计算机研究与发展 , 2013,50(10): 2212-2227.
[17]HENNESSY J L. PATTERSON D A. Computer architecture : a quan-titative approach[M]. Fifth Edition. San Francisco: MorganKaufmann. 2012.
[18]BELADY L A. A study of replacement algorithms for a virtual-stor-age computer[J].Imb Syst J, 1966.5(2) : 78-101.
