
搜救环境下动态物体消除方法及其在SLAM中的应用研究
2020-06-28 09:07苏卫华张世月
医疗卫生装备 2020年6期
蹇 锐,苏卫华*,张世月
(1.军事科学院国防科技创新研究院,北京 100071;2.天津(滨海)人工智能创新中心,天津 300457)
0 引言
目前,搜救机器人广泛应用于地震、煤矿和化学物品泄漏等灾害场景的搜救工作[1-2],其利用自身携带的传感器(如视觉传感器、红外传感器、激光雷达等)进行实时定位和地图构建(simultaneous localization and mapping,SLAM)来感知环境和开展搜救工作。然而,在战场、地震废墟等复杂、陌生的搜救环境[3]中进行人机协同搜救和多机协同搜救时,其他移动的机器人、搜救人员和环境中不稳定物体等动态物体会降低定位和建图的精度和准确性。目前常用的环境感知设备(如激光雷达、单目相机等)在动态物体的检测和消除方面存在各自的弊端。基于激光雷达的检测方法由于激光线束和垂直方向视场角限制,无法完成搜救环境下动态物体检测;视觉传感器在搜救环境下受到光线强弱的影响,常用的帧差法会失能,无法实现动态物体检测与消除。由此可知,单一传感器在实际应用中受限于传感器性能,无法满足复杂多变且结构不稳定的搜救环境需求,常规检测方法由于误差太大无法实现动态物体消除。
为此,结合搜救机器人应用需求,本文提出一种基于深度学习的动态物体消除方法。该方法基于激光视觉融合数据,能有效弥补单一传感器结构性能的不足;使用基于金字塔式场景理解深度学习网络进行像素级场景理解,并进行基于强鲁棒性的SURF(speeded up robust features)[4]特征匹配方法完成背景补偿和动态物体检测,充分利用图像帧的色彩信息和激光点云的几何信息来消除实时定位和地图构建过程中动态物体,实现精确定位和地图构建,为搜救机器人自主运动提供有效信息支撑。
1 动态物体检测及消除算法设计
本文利用多种传感器融合数据,采用深度学习的方法对环境进行像素级场景理解,同时结合基于动态背景的运动目标检测方法,对数据进行多层并行处理,实现动态物体消除。算法整体设计流程:将视觉传感器数据分流,进入基于金字塔式深度学习网络进行语义分割,将不同种类的物体分割出来,实现像素级场景理解,得到动态物体备选区域;同时,将同样的数据在动态物体检测线程中进行处理,得到图像中动态物体区域;结合语义分割结果和动态物体检测结果,对动态物体区域实现精准检测,利用激光雷达和相机的外参矩阵实现雷达点云和图像中运动物体消除。语义分割和动态物体消除框架图如图1所示。
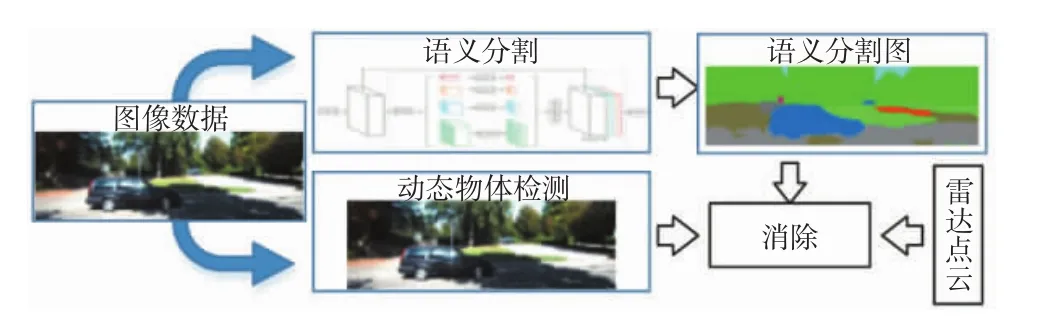
图1 语义分割和动态物体消除框架图
1.1 语义分割
为了更好地理解场景,得到动态物体备选区域,本文利用相机采集具有色彩信息的图像帧,使用金字塔式神经网络PSPNet[5]对全局场景中的各个区域进行语境聚合,使模型根据全局理解进行语义分割,解决了类似“水面汽车”的语义理解错误而产生的错误分割,其网络结构如图2所示。

图2 图像分割网络结构
如图2所示,图片输入网络后,经过卷积神经网络(convolutional neural network,CNN)[6]生成特征地图,而后进入金字塔式的池化层,该金字塔由4层组成,第1层(即红色那一层)使用全局池化生成单个输出,其余3层输入特征图分别被划分为2×2、3×3和6×6的子区域,而后对每个子区域进行池化,并将池化后的输出组合起来。由于每一层输出的特征图具有不同的尺度,在金字塔层级后用1×1的卷积核对高维特征进行降维,以保持全局特征的权重,用双线性插值的方法对低维特征图进行上采样,以恢复其特征图的尺度。对不同层级的特征图进行拼接,得到金字塔池化的全局特征,最后通过卷积层(Conv)生成预测图。
金字塔式神经网络PSPNet具有较好的准确性和实时性,且其提出者在公开数据集ADE20K、VOC 2012和Cityscapes进行了训练和测试,并公开了其网络模型和预训练参数。本文使用这些公开的预训练参数微调网络模型后,进行基于KITTI[7]数据集的模拟仿真验证,结果如图3所示。

图3 基于KITTI数据集的语义分割实验
从图3中可以看出,PSPNet语义分割算法基本能够分割出人和车的大致轮廓,其分割图在分类边界处平滑性较好,分割出的类别和原图中大致相同,但也存在错误分割,如出现将树影子和地面混淆的错误分割情况。整体效果而言,该分割算法能较好地完成对动态物体的语义分割(如汽车所在的蓝色区域),满足本文需求。
1.2 基于动态背景的动态物体检测
得到动态物体备选区域后,尚无法确定动态物体准确区域,本文采用基于背景补偿的运动物体检测算法,其算法流程如图4所示。
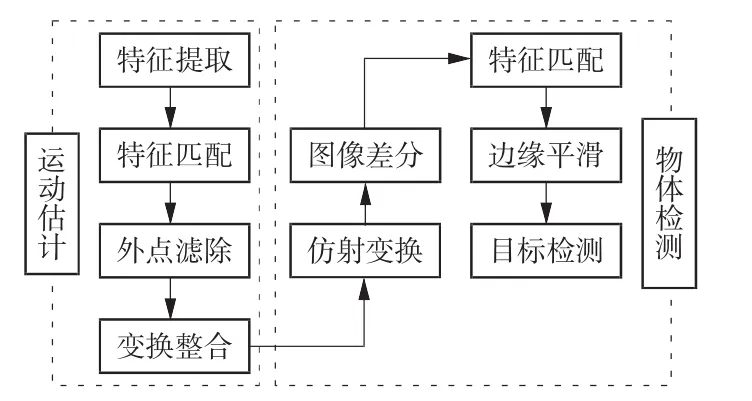
图4 动态物体检测流程图
如图4所示,该算法由运动估计和物体检测两部分组成。运动估计:首先选取SURF特征点,完成特征匹配;然后进行外点剔除,以消除待检测点对运动估计的影响;最后完成变换整合得到两帧之间的仿射变换矩阵。物体检测:利用运动估计求得的仿射变换矩阵做仿射变换,将上一帧的背景变换到当前帧,然后对变换后的图像进行差分和滤波,完成连通性分析后进行边缘平滑处理,从而检测出动态物体。基于KITTI数据集的模拟仿真验证和基于实地场景的实验结果如图5所示。

图5 基于KITTI数据集的动态物体检测图
从图5中可以看出,该算法虽然存在部分误检测,但基本可以检测出运动物体。结合语义分割和动态物体检测结果,可以实现动态物体精准确定,满足算法需求。
1.3 基于外参矩阵的动态物体消除
完成动态物体检测和语义分割后,图像数据中的动态物体可以被准确检测和消除。但在搜救环境中,光线不佳的图像数据无法实现搜救机器人准确定位,因此本文采用精度高、鲁棒性强的雷达数据实现定位、建图。为了提高精度,需要消除激光点云中的动态物体,故使用外参矩阵进行图像帧与雷达点云融合,实现动态物体消除。
本课题组使用左手坐标系法则,设定雷达坐标系为{X},其坐标原点为几何中心,X轴向前,Y轴向左,Z轴向上;相机坐标系为{Y},X轴向右,Y轴向下,Z轴向前,雷达到相机的平移矩阵为Tlidar_to_cam,旋转矩阵为Rlidar_to_cam,相机畸变校准矩阵为Trect。则雷达坐标系到相机坐标系的映射关系为

得到雷达点在图像帧中的坐标后,该雷达点对应的相机坐标系下的坐标周围存在大量标签,设定一个阈值,如果一定半径内相同标签数量大于阈值,则给该点赋予相同的标签。遍历所有雷达点后,可以检测出移动的人和车等动态物体,将该物体区域剔除后,即完成动态物体消除。其算法流程如图6所示。

图6 动态噪点剔除流程图
2 基于动态物体消除的SLAM算法
完成动态物体的消除后,使用无动态物体的数据进行实时定位和地图构建,基于经典激光SLAM算法进行改进,改进算法框架如图7所示。首先,参照激光雷达特性,将点云进行线束分类和区域划分,并将外点和噪点剔除,完成激光点云的预处理。其次,根据点云几何特性计算曲率并选取特征点,根据几何特性实现相邻两帧点云的特征匹配,构建两帧点云之间约束关系矩阵。而后使用L-M(Levenberg-Marquardt)[8-10]迭代方法解算相邻两帧点云的平移向量和旋转矩阵,实现10 Hz的高频雷达里程计。最后,在里程计基础上完成1 Hz低频地图构建,进行变换整合后输出高精度地图,并构建具有导航指导意义的八叉树地图。
3 实验与分析
完成算法改进后,基于KITTI数据集验证改进算法的有效性。为了验证改进算法的实际效能,本文结合搜救机器人任务场景(受限于客观条件,本文选取了室内和室外2个场景)对改进算法进行验证。

图7 SLAM算法框架
3.1 基于KITTI数据集的改进算法验证
完成算法改进后,使用具有真值的公开数据集KITTI进行测试。KITTI数据集是自动驾驶和移动自主机器人领域关于定位和地图构建问题使用频率最高的数据集。其数据采集平台为一辆大众汽车,车顶部装有1个64线velodyne激光雷达HDL-64E、1个彩色双目相机、1个高精度的惯性测量单元(inertial measurement unit,IMU)和全球定位系统(global positioning system,GPS),可以同时采集彩色图像信息和激光雷达点云。该数据集使用相同频率在同一时刻采集图像和雷达数据,且提供雷达到图像的变换矩阵、畸变校准矩阵等参数。数据集有11个场景具有高精度的真值,可以用于比较。使用该数据集中有高速、城市、乡村等多个具有动态物体的场景进行算法测试,同时也在多个具有较少动态物体的场景上进行测试。实验测试均在配置Intel i5处理器、970M显卡和6 GB显存、16 GB运行内存的平台上进行。本文假设在求解过程中平台的运算能力能满足需求,不存在因计算能力带来的误差。
实验结果如图8所示,其中,红色代表KITTI提供的真值,蓝色代表本文的改进算法,黑色代表原始LOAM(laser odometry and mapping)算法。从图 8中可以看出,本文的改进算法结果比原始LOAM算法的结果更加接近真值,尤其是在高速场景下。本研究使用KITTI提供的量化评价工具评价了改进算法(本文算法)和原始算法(LOAM算法)在旋转误差和平移误差的量化差异,其结果见表1。由表1可以看出,本文算法在07、09场景上平移误差和旋转误差都比原始LOAM算法低,分别降低了3.6%、4.9%和6.9%、5.6%,故本研究改进的算法在定位精度上有一定的提高。
3.2 基于室内、室外场景的实验与分析
为了进一步验证算法的有效性,本文将校准好的激光视觉模块搭载于轮式搜救机器人上,进行室内外实地实验,如图9所示。模拟信号拒止的搜救场景,在室内进行实验,该实验场景具有各种办公用品,虽然地面平整、结构性强,但具有明显动态物体,如随意移动的人。在该场景下进行实验,由于缺少真值,本文采用闭环实验,即在起点位置做好标记,终点将回到同样的位置。

图8 实验结果

表1 2种算法不同场景旋转误差和平移误差对比表%
室外场景实验在外包园一号口门前进行(为闭环实验),如图9(d)所示。本次实验存在移动的人和外卖摩托车等移动物体。实验所用数据处理平台为一台Intel i5处理器、970M显卡和6 GB显存、16 GB运行内存的便携式计算机,在实地实验过程中,假设实验平台运动速度相对恒定,减少瞬时加速度过大产生的偶然误差。
如图 9(b)、(c)、(e)、(f)所示,语义分割基本能识别主要事物,动态物体检测基本能识别移动的人等动态物体,结合语义分割结果和动态物体检测结果消除运动物体,并进行定位、建图,其结果如图10所示,蓝色代表本文算法,橙色代表原始LOAM算法。在图中对定位末端做放大处理,可以看出,虽然2种算法距离原点的误差都不小,但是本文算法比原始LOAM算法更加接近坐标原点,精度更好。从定量分析来看,在室内环境中,消除运动物体后漂移距离为0.516 8 m,原始数据漂移距离为1.069 9 m,误差减少了51.7%;在室外环境中,消除运动物体后漂移距离为1.664 9 m,原始结果漂移距离为1.827 2 m,误差减少了8.9%。无论是定性分析还是定量分析,都证明了本文提出的方法能实现动态物体消除,提高了定位、建图精度。
4 结语
本文着眼于搜救环境中动态物体问题,使用激光视觉融合数据克服激光传感器特征提取单一、色彩信息缺乏的缺点,以弥补视觉传感器对光线敏感、易产生运动模糊的不足;综合运用基于场景理解的语义分割方法和基于动态背景的目标检测方法实现动态物体检测与消除,以提高定位和建图的精度。完成算法改进后,进行基于KITTI数据集的验证和基于实际场景的验证,实验证明,本文所改进的算法能有效消除动态物体,提高定位、建图精度。
本研究不足之处在于:使用图像数据进行语义分割和基于动态背景的运动目标检测,再使用外参矩阵进行噪点剔除,数据经过多个算法处理,对计算平台的运算能力要求较高,实时性有待提高。下一步拟直接使用彩色点云进行动态物体检测与消除,减少数据处理步骤,增加算法实时性。
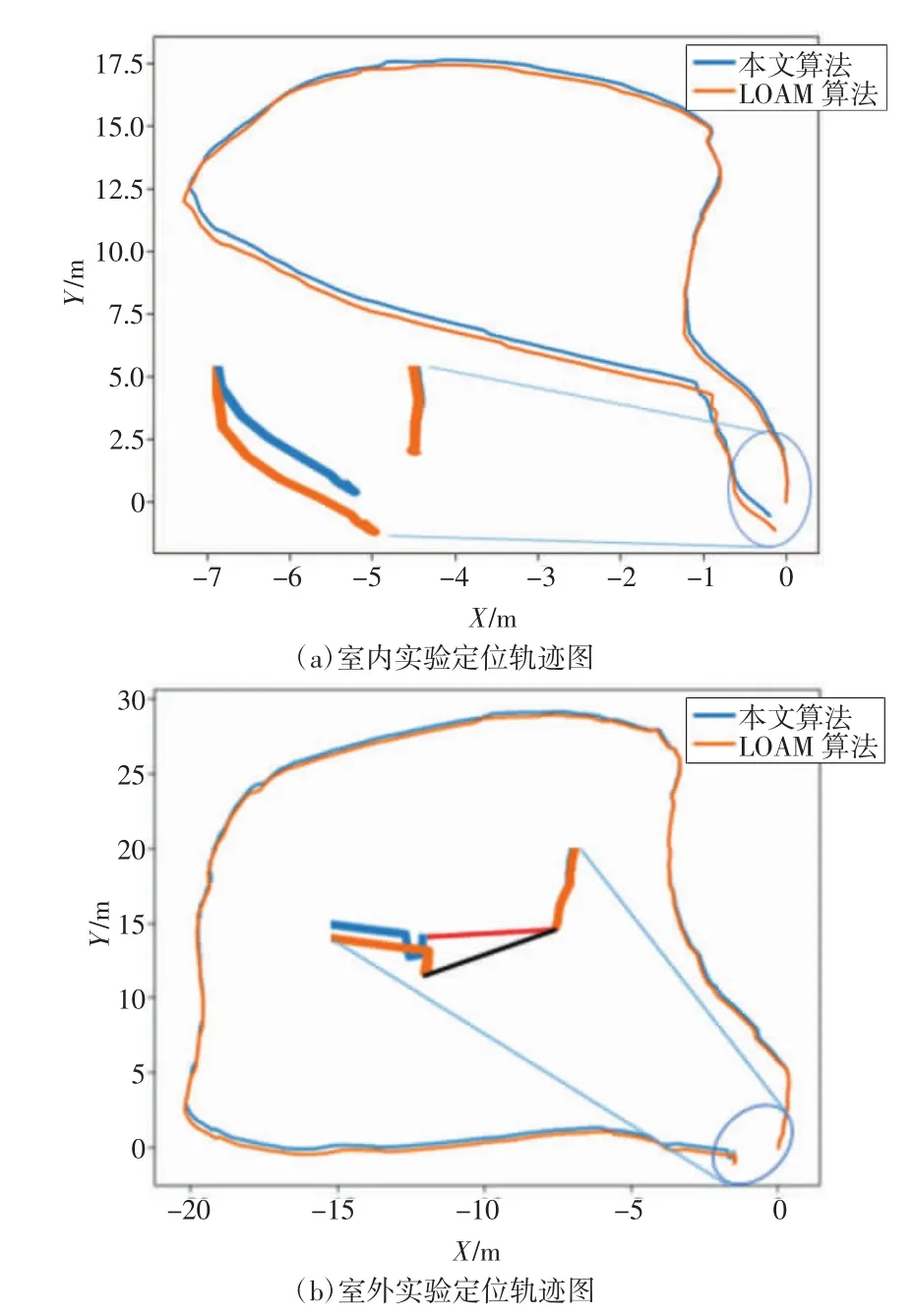
图10 室内外实地实验结果
猜你喜欢
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
开放教育研究(2020年2期)2020-03-31
中学生数理化·高一版(2020年1期)2020-02-20
环球慈善(2019年6期)2019-09-25
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
