
基于Hadoop的大数据处理系统分析与研究
2020-07-09 22:13卢爱芬
现代信息科技 2020年2期
关键词:大数据分析

摘 要:针对当前很多医院或者企业在面对庞大数据处理过程中存在能力缺乏的问题,研究提出基于Hadoop的数据分析系统,该系统能够用于医院辅助诊断以及数据比较分析,同时该系统融合多节点分布式计算技术,能够依据医院患者医检结果生成初步诊断结果,可显著改善传统医疗过程中数据信息处理效率较低的问题。
关键词:Hadoop;大数据处理系统;大数据分析
中图分类号:TP311.13 文献标识码:A 文章编号:2096-4706(2020)02-0109-03
Abstract:In view of the lack of ability of many hospitals or enterprises in the process of huge data processing,this paper proposes a data analysis system based on Hadoop,which can be used for hospital auxiliary diagnosis and data comparative analysis. At the same time,the system integrates multi node distributed computing technology,it can generate preliminary diagnosis results according to the medical examination results of the patients in the hospital,which can significantly improve the low efficiency of data information processing in the traditional medical process.
Keywords:Hadoop;big data processing system;big data analysis
0 引 言
近年來,互联网技术以及计算机技术的发展,在一定程度上改变了人们的日常生活和工作方式,使人类社会逐渐进入了大数据时代,使医疗信息化逐渐加速,根据有关部门统计数据显示,在2018年,我国医疗信息化建设共投入资金300多亿元,同时多种医疗信息数据量扩大,且呈现爆炸增长的方式,过去主要是通过数据仓库的方式进行储存,相应的医院信息系统由于受到硬件等多种因素的影响,对于一些数据量较大的非结构化数据在处理过程中很容易出现问题,无法获得良好的储存能力和计算效果。因此本研究在当前大数据背景下设计了Hadoop的数据分析系统,能够更好地帮助企业或者医院实现数据整合加工和定性分析。
1 大数据及其处理技术
最早的大数据是由全球麦肯锡公司提出的,大数据是指能够超出常规数据库或者数据处理能力,被迫采用一些非常规方式的数据集,同时大数据具备四大特点,包括较大的体量、处理速度较快、具有多种类别、具有较强的可靠性,能够通过分布式可扩展储存的方式实现数据的管理查询,目前很多研究机构虽然已经具备大量数据,然而由于缺乏高效分析手段,同时数据仓库维护过程的成本逐渐升高,因此目前很多企业广泛应用基于Hadoop结构的分布式文件系统。Hadoop是一种大规模数据处理的重要分布式系统架构,其核心为MapReduce编程以及HDFS的编程模式,其中HDFS是一种主/从式架构,具有较强的容错性。在普通的PC端大量部署,进而能够实现多数据节点对大量数据集的分块储存有效管理,除此之外,HDFS能够为系统提供一次访问,写入多次读取的模式,确保数据一致性,能够适用于当前处于大数据时代背景下高吞吐需求,而MAP和Reduce是由谷歌研发的一种重要分布式程序模型,是通过化简和映射这两个环节来实现大数据处理,首先在映射函数中不改变原有数据的前提下,能够将大文件切割形成的小文件构建独立元素实现逐步映射,并创建多种列表实现映射,将处理结果保存之后可以利用化简函数将所映射出的文件根据函数值进行合并或者缩减,将大量不同结构或不相关数据进行特征提取后,将结果保存至指定的途径中。
2 系统结构设计
针对当前医院实现数据信息化建设的情况,本研究提出的大数据分析系统框架主要由三个部分构成,分别是数据层、访问控制层和应用层,其具体的系统结构功能如下:在该结构中,根据层次结构原则,数据层是最底层,可将现有数据系统所提交的文件通过切割的方式保存至Hadoop数据节点中,进而能够有效控制文件分片管理和负载;中间层为控制访问层,主要是由命名节点命名各种文件和数据节点关系以及空间镜像之间的关系,运算中心可以通过节点调取的方式提供重要的原数据信息,能够对原数据进行映射化简处理,指导相应的文件进行读写,并将处理结果反馈到应用层中;系统最高层为应用层,可为用户提供文件界面,窗口用户通过该界面能够下达访问控制层指令,并接收系统最终提交的辅助诊断报告和分析结果。
3 系统功能设计和实现
该系统与传统的信息系统,如果两者能够实现协同运行,对现有单节点数据库储存多种数据方式及分布式储存管理,通过运算中心调用的映射化简算法,进而能够对庞大数据实现高效分析处理,以及为医生提供确切的辅助诊断信息。从数据储存功能来看,数据层是安装了一系列Linux系统,由普通PC端和现有信息化系统数据库共同构成的,由于Hadoop分布式文件系统在众多由PC端所构成的节点群中运行,所以能够对原有数据实现分布管理导入。
当前很多医院采用的信息管理系统是由电子病历系统、影像归档系统共同构成的,其中电子病历系统可用于患者基本情况检查结果、诊断结果等一些结构化数据的储存,而影像归档系统可用于多种数字影像,声音等非结构化的数据的储存。在Hadoop项目中,除了HDFS和映射化简编程模型之外,还包括非结构化数据基础所构架的hive以及非关系数据库HBase,传统数据储存仓库与HDFS之间重要的数据导入工具及Sqoop等模块。
在利用分布式处理原始医疗数据之前,首先需要进行节点命名并安装HBase以及hive,利用Sqoop工具能够将所提供的Java API与现有的数据库进行有效连接,导入多种数据之后,判断其是否属于结构化数据,如果系统判断其为结构化数据时,可以利用Sqoop工具通过接口进行hive的连接,然后判断数据查询与数据对应的列表是否存在,如果不存在则需要创建新表进行hive的储存,如果该列表已经存在,需要有系统自行判断数据量是否超过额定值,如果没有超过额定值可以直接进行储存,如果超过需要进行分区再次存入。当所储存的数据为非结构化数据时,可以利用Sqoop工具通过JDBC接口与HBase进行连接,提交插入后得到请求响应之后能够对Base表进行扫描和定位插入,同时实现时间设置,能够将数据插入特定的HBase数据库中,数据写入HBase的具体步骤为:由客户端开发库启动相应的数据节点,并向上层命名节点发起请求,命名节点会检查所创建的文件是否存在,或者具体创建人员的使用权限,一旦检查成功会为其创建文件,如果检查失败会提出异常报警信息,当RPC获得请求响应之后,由客户端开发库将所需要写入的文件切割成多种小文件,之后再向命名节点申请blocks,能够将HDFS与本地文件数据快实现映射列表,并且通过报告的方式提交命名节点,该命名节点之后能够向客户端返回数据节点的配置信息,由客户端根据节点地址IP管道的方式,按照顺序写入相应的数据块节点中,当HDFS写入全部的原始数据后,命名节点能够将所有数据信息,包括文件属性、块列表、数据结点与列表之间文件之间的关系,提交到相应的运算中心中,此时运算中心可以根据所设计的算法模式对该文件进行读写和分析。
在数据储存以及数据库设计过程中,基于Hadoop的大数据分析系统在数据储存过程中主要利用HBase数据库,同时在储存数据库时能够按照一定标准完成数据库设计,为后续实现数据库扩展奠定基础。在hive数据库中相对应的数据表能够按照内部、外部表形式储存,由于hive在内部数据表创建过程中,可将目标数据信息移动到指定路径,并删除相对应的内部数据,因此,这对于数据的错误操作保护以及安全性来说是有利的。本研究中我们按照用户信息表创建进行hive储存方式创建。具体的代码如下所示:
Create external table //创建外部数据存储表
User_info(user_id int , user_name string ,
user_password string ) //指定关键词和存储类型
Row format delimited //指定行格式限定
Fields terminated by , //指定分隔符
Stored as textfile //指定文件存储类型
Location ‘/data/report/ user_info; //指定文件存储位置
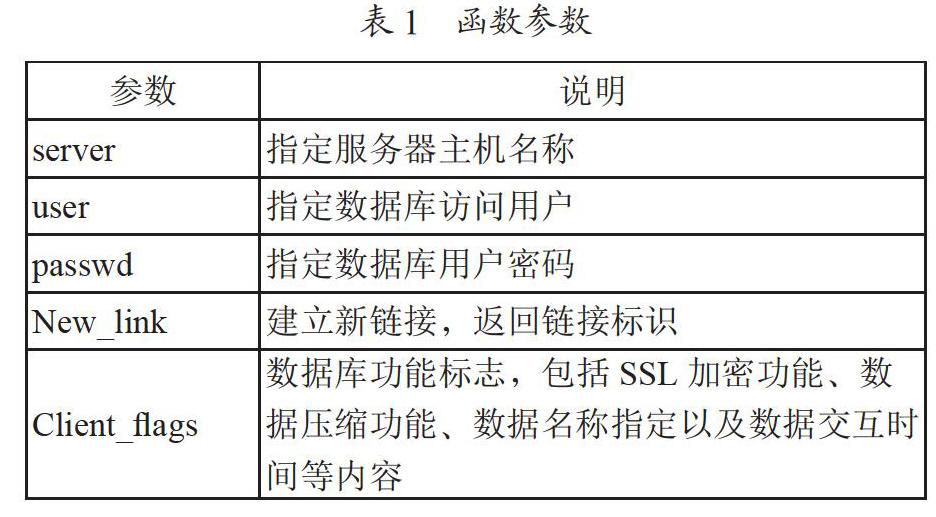
完成上述代码执行之后,需要将指定文件上传到相对应的文件夹中,然后系统能够自动生成统一路径,每一个hive储存数据表有唯一路径,在后续数据改变时只需要找到相对应的文件夹就可完成操作。在数据库部署过程中,大数据分析系统中数据库选择和充电是重要的环节,数据库是一种数据储存的重要程序,其与API是一种独立的且可用于数据的储存访问。在本研究中,我们以数据库作为数据管理系统,首先在数据库安装过程中,由于该数据系统属于开源系统,可以直接在网站下载,为便于数据库服务器的后期管理,实现用户访问控制和数据库查询,本研究,我们采用的是MySQL RPM版本完成数据库安装,需要检查其是否可正常运行,通过执行代码ps-efl grep mysql确认其安装的正确性,如果无法正常运行,则需要启动下列指令:root@host# cd/usr/bin./safe_mysqld。在数据库管理方面,为便于实现数据库管理,需要添加数据库用户,通过改指令实现数据库启动,利用Database changed开启写入功能,利用写入修改后的用户信息,包括用户种类、账户、密码等,同时需要指定用户权限,将其作为数据库的管理员,包含选择、升级等多种权限,完成用户设定之后,可以利用选择键对数据库信息进行查询。除这些方法之外也可以采用GRANT的方式实现用户设置。在数据库的链接中,可以安装MySQL利用PHP的mysql_connect()指令实现数据库链接,具体函数参数如表1所示。
当完成链接后会返回相应标志,构建数据库连接之后需要以下指令[(用户名)@host]#mysql-u root-p,实现数据库用户的指定,完成连接后会返回链接信息。用户使用结束之后可以根据指令实现终端连接或者链接关闭。
4 辅助诊断和数据功能的设计
在患者来医院就诊的过程中,通常需要开展一系列的医疗检查,由于不同患者体质不同,对于同一疾病在检查过程中也会根据患者检查中成像数据差异进行自动诊断,因此当患者接受医疗检查之后,还需要经过一段时间入院观察才能够确定最终疾病类型。具体算法顺序为:首先在映射算法上,工作人员需要打开患者的電子病历文件,并且能够确定文件是非空集,未结束则采取循环字符串读取的方式到变量str中,如果str为年龄,Then数据值为年龄值,当str为诊断结果时,value1为病症名称,我们可将(key1,value1)写入相应的中间文件中,如果str为诊断结果时,之后key2为病症名称,可以将(key2,value2)作为医疗数据,可以修改str为病症名称和所对应的医疗检查项目,value2是该项目对应的意见结果数据,能够将该病对应的一些项目分别形成key2和value2,并写入中间文件中。在化简算法中需要首先创建hash表ht,当k值为整数时,key与key1对应年龄段以及value1等于value+1,将其写入ht中,当k值为字符串类型时,此时如果value大于max,那么则有max=value,如果当key为key2时,value等于max,则此时需要将(key,value)写入hIt中,如果value低于min时,此时min等于value等于key2,value等于min,可以将ht中的每一个(key,value)写入最终结果分析文件中,由于映射算法提供的key值与value存在不同数值类型,而hash table可用于多种类型的key和value值的识别,需要创建hash表可用于最终结果处理。该系统进行统计分析过程中,首先需要判断所收到的配置是否为整数,如果是整数,需要按照数值大小依次排序并归入对应年龄中,然后对该年龄段和对应症状构成新的配置,判断该值是否储存于ht中,如果不存在则需要在ht中加入key值,如果已经存在,需要将key值对应的value值输入,当接收到key值时,如果该值为字符串类型,判断key对应的value值是否高于目前max最大值,如果是,则需要将max替换为value,如果判断key值对应value值小于min最小值时,需要将min替代为value,反复进行数据比对,可实现某一疾病不同患者医疗检查项目数据的汇总,最终能够对所有患者疾病项目数据值区间进行提取,形成一种医疗辅助检测模板。
5 系统性能测试
为了能够进一步测试该系统的运行效果,在本研究中共设置20个数据节点,随机挑取不同年龄段的电子病例,共计5万多份,实现数据统计分析,数据统计如表2所示。
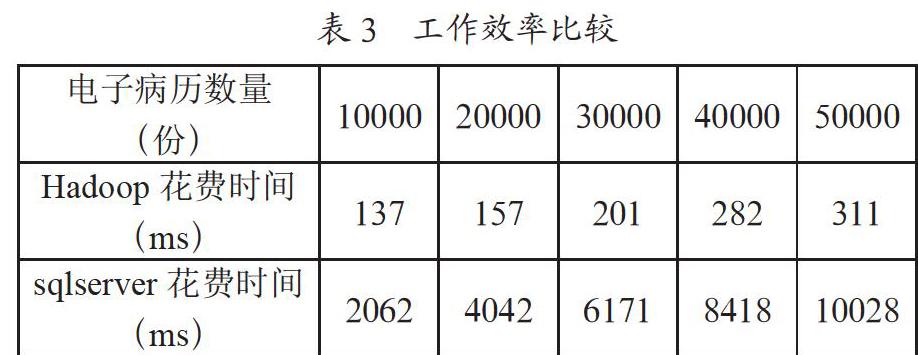
最后与医院现有的信息化数据库进行比较,将该系统与原有系统利用函数记录时间实现工作效率进行比较,在数据处理过程中两种系统比较表如表3所示。
通过实验我们可以发现,随着目前医院电子病历数量的增加,采用传统单节点数据库处理,耗时呈现线性关系,然而利用基于Hadoop的大数据分析处理系统时,在处理中采用分布式数据分析方法能够显著节约时间。
6 结 论
本研究提出了基于Hadoop的数据分析系统,能够对该系统工程进行分析设计,进而该系统运用到医疗系统时可为医疗辅助诊断提供可操作性的映射。简化上,相比原系统来说能够简化诊断流程、实现庞大数据的快速处理。最后通过实验验证的方式证明该系统相比传统单一节点数据库具有较高的运行效率。
参考文献:
[1] 陈臣.基于Hadoop的图书馆非结构化大数据分析与决策系统研究 [J].情报科学,2017,35(1):24-28.
[2] 王卫锋,杨林.基于Hadoop的邮政寄递大数据分析系统设计与实现 [J].中国科学院大学学报,2017,34(3):395-400.
[3] 王丽红,刘平,于光华.基于Hadoop的对俄贸易大数据分析系统研究 [J].电脑知识与技术,2018,14(1):20-22.
作者简介:卢爱芬(1975.09-),女,汉族,湖南郴州人,就职于软件教研室,专任教师兼教研室主任,讲师,研究生,硕士,研究方向:软件工程。
猜你喜欢
亚太教育(2016年36期)2017-01-17
山东工业技术(2016年24期)2017-01-12
中国远程教育(2016年11期)2016-12-27
中国管理信息化(2016年21期)2016-12-27
科技传播(2016年19期)2016-12-27
