
文本分类专利技术综述
2020-07-10 09:16李若晨
科学与财富 2020年13期
摘 要:随着信息快速增长,大数据时代的来临,对文本数据的分类越发重要,且海量数据意味着高度依赖文本自动分类。本文从文本自动分类技术演进路线、专利申请情况和重点申请人几个方面分析了文本自动分类技术专利情况,并结合重点专利进行技术分析。
关键词:文本分类;专利
一、引言
文本分类是指依据文本语义内容将未知类别的文本归类到已知类别体系中的过程,在众多领域中均有应用,常见的应用包括:邮件分类、网页分类、文本索引、自动文摘、信息检索、信息推送、数字图书馆以及学习系统等[1]。
二、文本分类技术演进路线
回顾文本分类的相关研究,以20世纪60年代出现贝叶斯文本分类器为界限,将文本分类分为两个阶段:20世纪60年代以前主要依靠人工筛选,之后,文本分类开始自动分类。20世纪80年代,出现采用知识工程的方法进行分类,通过建立专家知识库与字典等一系列分类规则来构建分类器,但知识工程方法需要大量领域的专家和工程师参与,势必耗费很多人力物力,当电子文档急剧增长时将无法满足需求。
此后,由于基于机器学习的自动文本分类系统几乎可以达到与人类专家相当的正确度,但是却不需要任何知识工程师或领域专家的干预,机器学习方法在文本分类领域得到了深入的研究和广泛的应用。
在20世纪末以来,出现了大量基于监督学习、半监督学习等机器学习算法在文本分类上的研究,例如朴素贝叶斯文本分类器、基于决策树的分类、K近邻聚类、SVM支持向量机等,并且,在当前研究中,对传统机器学习算法在文本分类的研究依然没有停止。
在实际应用中,考虑到数据的复杂性和多样性,往往单一的分类方法不够有效。因此学者们在多种分类方法的融合方面进行了广泛的研究.例如基于投票机制(bagging或者boosting)的多分类器研究[2]。
伴随着人工智能的飞速发展以及深度学习理论在图像和语音方面的良好表现,研究者将深度学习理论应用在文本处理中,出现了基于深度学习的文本分类研究。目前研究的热点就在于基于不同应用下文本类型的特点,将神经网络应用在文本分类中。
三、文本分类技术专利分析
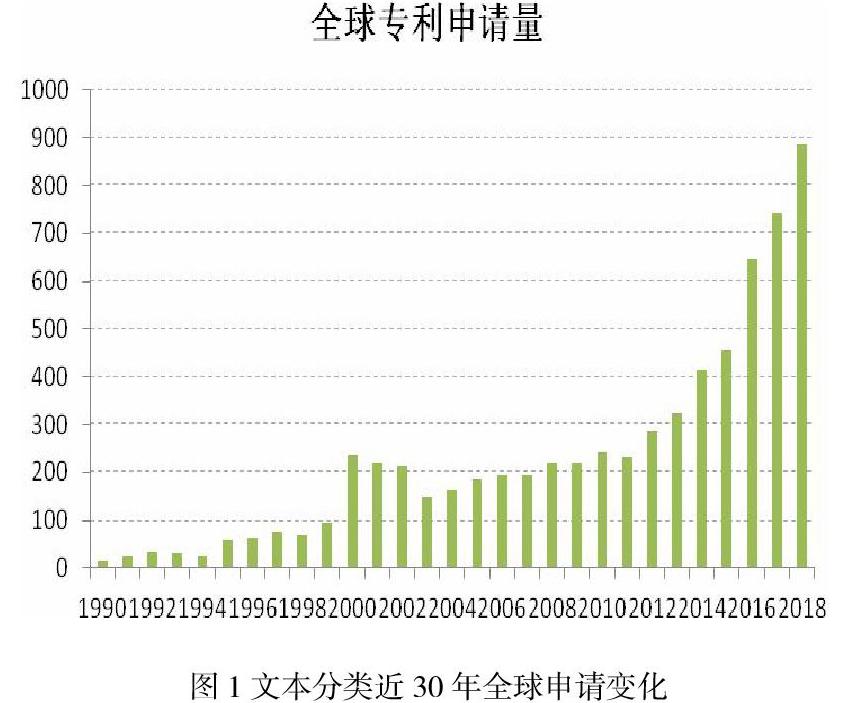
通过在标题和摘要中利用关键词“text catego+ or text classif+”进行检索,将过滤出的专利按照年限统计分析如下:
图1示出了文本分类近30年全球申请量变化情况,从图中可以看出,20世纪90年代,全球申请量较低,虽然整体上申请量在增长,但处于发展缓慢阶段。从2000年开始,申请量出现增长高潮,尤其从2003年开始,申请量呈现指数增长形式,出现该状况的原因在于互联网的飞速发展,新一代通信技术市场化的普及,使得文本分类的需求增加,从而促使在文本分类方面的研究。
四、重点专利分析
通过对专利的同族数量和被引证次数进行分析并结合文本分类技术演进,下面对该领域重点专利进行详细技术分析。
1、基于字典、语法结构、知识库等进行文本分类
在机器学习的分类算法没有广泛应用之前,基于知识库、字典等方式对文本进行分析归类是常见的方法。1988年IBM公司的专利申请EPEP0282721,提出了基于范式的形态文本分析,利用结构化知识库和字典,对文本进行分析归类。该方案用于自然语言文本分类并生成单词形式,其中涉及到的字典表示、语法分析、自动索引和同义词检索应用在多种自然语言中。
1998年,THE DIALOG公司提出公开号为WO9858344的申请,将文本按照主题进行分类,将文本语料库中的文本实体表征为相关的主题区域,包括确定所述文本实体中的所选术语和所选择的术语。该申请中依然利用到了单词字符串的匹配,并且设置了多种匹配规则,将词语出现次数这一特征纳入分类的影响因素之中,可以提高分类的准确性。
2、基于传统机器学习算法进行文本分类
机器学习算法的普遍应用逐渐替代了认为设定规则与知识库的分类方式。决策树、朴素贝叶斯分类、SVM算法等均在文本分类中各具优势。
IBM公司于1998年提出申请US6253169,请求保护一种提高基于决策树的文本分类准确率的方法。决策树分类算法作为一种有监督学习算法,需要分类标注出训练数据的类标与主题。该方法中,首先分析样本集文件中的文字以识别多个主题;然后开发多个本地词典;接着,为样本集中的每个文档生成向量,为样本集中的每个文档生成的向量是针对所述多个主题中的相应一个开发的所述多个本地词典中的相应一个中的单词;基于在所述分类步骤中执行的样本集中的文档的分类形成预测模型。
華为技术有限公司于2009年申请了专利CN101887443A,申请人发现由于现有技术提供的技术方案是根据文本中的基本特征来判断该文本的类型,其判断方式仅根据文本的基本特征来计算文本的分类,文本分类不准确,因此,在设计方案时,不仅考虑了文本的基本特征,还考虑了句式特征、重复词特征和叠置词特征中的一种或多种,增加计算的参数,使得分类准确。
3、融合分类器
面对众多机器学习分类算法,研究者认为单一分类器的效果不够准确,因此考虑将多个分类器的分类结果进行“融合”,形成了融合分类器。CHOU WU等人于2004年在专利申请US2006069678提出了这一思路。该申请在初始广义线性分类器上执行最小分类错误训练以生成训练的初始分类器,将AdaBoost算法的增强算法应用于训练的初始分类器以生成m个备选分类器,然后使用最小分类误差训练来训练m个备选分类器以生成m个训练的备选分类器,基于训练集上的分类错误率,从所述训练的初始分类器和所述m个训练的替代分类器中选择最终分类器。该方法可以良好适应各种类型的文本数据,在保证准确率的情况下有较强的适应性。
4、基于深度学习的文本分类
由于传统机器学习分类方法需要人工做特征工程(文本预处理、文本表示和特征提取等),成本很高,而深度学习可以解决大规模文本分类中文本表示,且诸如CNN/RNN等网络可以自动获取特征表达,因此,省去了繁杂的人工特征工程。微软于2014年提出专利申请US2015310862 A1,利用深度学习解析语义,进行文本分类。该方法可以用于在线网页日志分类中,从一个或多个查询点击日志获得未标记的数据。深度学习网络被训练为具有解析单词、短语或句子语义嵌入层的网络,无需人工标记,可以从未标记的数据中学习而来。该申请提出的方案在无需数据标注情况下可以良好解析几种具有相同语义的不同文本,提高分类准确性。
五、总结
本文从文本分类技术的发展概况及原理入手,从文本分类技术的专利申请趋势及国内外主要申请人分析,重点解读文本分类技术的技术演进路线。
参考文献:
[1] 张磊,文本分类及分类算法研究综述[J],电脑知识与技术,2016(34):231-232+23338.
[2] 陈祎荻,秦玉平,基于机器学习的文本分类方法综述[J],渤海大学学报(自然科学版),2010,31(2):201-205.
作者简介:
李若晨(1992-),女,理学硕士,专利审查员,从事大数据方向专利审查工作。
猜你喜欢
水运工程(2022年7期)2022-07-29
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
传感器世界(2019年4期)2019-06-26
电影(2018年8期)2018-09-21
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
化学分析计量(2013年1期)2013-03-11
