
基于FPGA的卷积神经网络动态加载SOC设计
2020-07-15 05:01许永全冯玉田
计算机技术与发展 2020年7期
许永全,冯玉田
(上海大学 通信与信息工程学院,上海 200444)
0 引 言
机器视觉正迅速成为工业4.0智能工厂基础设施的重要组成部分,是制造和质量控制的关键技术,在制造业的检测、测量、扫描和物体检测中展示了其成本效益,以提高一致性、生产力和整体质量[1]。工业化进程已经走到了一个关键的转折点,正从模仿加改进的开发模式向创新和创造的阶段转变,使用机器学习来增强机器视觉系统,使其能够快速适应并融入所部署的系统中,是应对复杂应用的一个正确的解决方案[2]。随着3D机器视觉系统的快速发展,对机器学习算法提出了越来越多的要求,同时也加速了算法迭代的速度,甚至提出随着外部应用的变换,需要在多种算法间频繁切换,这些需求的实现加速机器学习解决方案在更广泛的领域应用。
文中设计了一个基于FPGA的机器学习多重加载和动态部署系统,主要面向工业应用的实用性软硬件设计方案,充分发挥FPGA的硬件优势,弥补FPGA开发过程复杂,对工程人员要求高的缺陷[3]。
该系统的机器学习算法采用卷积神经网络为核心的深度学习算法,并采用SOC技术降低了算法实现和软件开发的难度,同时将并行处理和串行控制集成到一个平台上,提高了工业化设备的适用度[4]。另外系统实现了多重加载机器学习算法的功能,使设备具备应对多种应用场景的能力,同时系统能够通过网络实现机器学习算法的动态部署和多重预加载,提高了设备的通用性和可维护性。
1 硬件设计
硬件系统主要包括电源时序板、FPGA处理器和CMOS传感器三部分,电源板和处理器采用排插连接,CMOS传感器与FPGA处理器之间采用LVDS标准接口[5],并用定制的柔性软板连接。图1是系统核心硬件电路板框图。系统的特点是体积小,处理能力强,适合嵌入到对设备要求苛刻的各种工业设备内,比如工业机器人引导、流水线产品多维度扫描检测等[6]。
电源时序板为整个系统提供电源,输入为DC24V标准电源电压,通过STM32单片机产生时序控制信号,同时芯片会监测所有的电源电压,保障硬件模块电源的正常工作。设备的各种异常信号,芯片也会根据设定自动处理,并报告状态信息,保障系统安全可靠的运行[7],FPGA处理器板的主要功能模块如图1所示。系统采用Xilinx公司的Artix-7系列的xc7a200tfbg676芯片,此芯片是Artix-7功能比较强大的一款芯片,拥有134 600个LUT、740个DSP乘法器和365个Block RAM内存单元,非常适合进行大量浮点运算的设计。板载4 GB的DDR3,保障了设备运行流畅性[8],同时搭载MICRON公司的256 Mb的NOR flash为系统提供了足够的程序存储空间。

图1 硬件系统核心电路板
FPGA与外界的通信主要通过两种方式,TTL232低速串口用于调试设备,千兆网络接口用于数据的传输,保障了从模块调试到产品部署的通信传输。此外电路板还包含了伺服电机运动控制接口、连续激光亮度控制接口,以及为保密而专门设计的DS加密芯片。整个系统主控部分和电源部分的长宽高分别为100 mm、40 mm和15 mm,CMOS传感器电路板的长宽高分别为40 mm、40 mm和5 mm,版面面积和一般的工业相机的镜头截面大小类似[9]。
硬件部分的设计理念是嵌入到各种特殊设备的工业应用,因此体积小、处理能力强、功能灵活等特点是这个系统的基本要求。例如工业机器人3D引导应用领域,首先需要使用电机控制激光扫描,同时高速的CMOS传感器采集实时图像,FPGA对采集的图像实时进行激光线提取,并进行复杂的畸变校正和3D点云生成运算,最后通过机器学习控制机器人动作。由于快速工业流水线操作要求较高的实时性,传统的CPU无法在有限的时间处理完大量的浮点运算,因此在机器人内部通过并行处理器实时完成复杂的算法实现。
2 FPGA的RTL设计
FPGA芯片内部的RTL设计通常称为FPGA的硬件设计,硬件架构如图2所示,Xilinx公司文档称为PL(programmable logic)设计,相应的SOC处理器程序设计称为PS(processing system)端设计,文中将PL简称为RTL设计。RTL设计主要分为三部分:外部设备、SOC软核处理器设计和图像采集及卷积神经网络算法部分。
2.1 外部设备
外部设备主要包括DDR3控制器、网络协议栈收发器、串口收发器以及NOR flash控制器部分[10]。例化的DDR3控制器的主时钟为800 MHz,32 bit位宽,设计的最大传输带宽为6.4 GB/s,满足绝大多数的现场应用。网络协议栈收发器使用的TCP/IP网络协议,速度为1 000 Mb/s,所有的外部设备都连接到AXI总线上,多设备的访问使用Vivado提供的内部互联专用模块连接。

图2 FPGA的RTL SOC硬件设计架构
2.2 SOC软核处理器设计
SOC软核处理器设计采用Xilinx公司的FPGA开发工具Vivado2017.2提供的软核处理器MicroBlaze,并例化了两个独立的处理器模块,每个处理器都拥有独立的片上程序存储器,并用于存储各自的BootLoader程序[11]。0号处理器作为主处理器,它的主要功能是控制整个系统的运行,并为各个模块加载参数配置,1号处理器负责复杂数据传输,并挂载网络协议栈收发器,两个处理器之间采用MailBox中断方式进行实时通信,并且,这两个处理器通过各自的二级缓存访问全部的DDR的地址,处理器与各个设备模块之间也是采用高速AXI总线连接的。
2.3 图像采集及卷积神经网络算法部分
图像采集使用的传感器总线为16位LVDS串行总线,双边沿采样,模块包括传感器的控制程序和LVDS总线训练程序,采集到的图像首先进行抽样和截取,满足设计的算法要求,卷积神经网络算法模块同时进行机器学习算法处理,输出计算结果,其中抽样或截取后的图片也可以选择实时输出。模块的输出最后通过DMA的方式写入DDR的指定区域。
当设备工作时,0号处理器首先为配置卷积神经网络计算单元DLA加载算法的网络模型参数,使其完成指定的网络算法模型,然后通知CMOS传感器采集图像。CMOS传感器将采集的图像数据源源不断地输入到FPGA内部,经过抽样后送入到卷积神经网络计算模块中,输出的计算结果通过DMA的方式写入DDR中,同时通知1号处理器数据已经准备好。1号处理器先将数据分包,再通过DMA的方式从DDR传输到网络协议栈收发器中,最终以TCP/IP协议,将卷积神经网络算法的计算结果发送给外部设备。
3 BootLoader设计
图3是系统BootLoader的启动流程,整个系统需要多个分布式加载的子程序。
系统SOC端的可用存储器包括4部分,分别是易失性存储器DDR3、易失性片上存储器、非易失性程序存储器NOR Flash和非易失性参数存储器,其中易失性片上存储器是使用FPGA的内部Block RAM构建的,每个处理器的易失性片上存储器是独立的。

表1 系统需要加载的子程序列表
表1是系统需要加载的子程序列表,其中Bitstream.bit是系统的PL端硬件电路镜像,通过Vivado SDK提供的Generate Bitstream工具将Bitstream.bit、Boot0.elf、Boot1.elf三个程序合并为一个程序,命名为Download.bit。Boot0.elf、Boot1.elf程序作为非易失性片上存储器的初始化常量插入到Download.bit中。最终烧写到NOR Flash中的程序包括Download.bit、Ethenet.elf和多个实现不同网络模型的Conv1_n.elf镜像文件,这些镜像文件开始需要使用Vivado SDK提供的Program Flash Mermory工具单独写入NOR Flash指定的偏移地址中,以后可以使用网络升级和更换这些预置的镜像[12]。

图3 系统BootLoader的启动流程
系统上电后,PL端的程序会自动从NOR Flash加载到FPGA内部,自动加载完成后,系统开始启动卷积神经网络的BootLoader流程,如图3所示。0号处理器作为主处理器,首先将1号处理器应用程序加载到1号处理器的DDR程序运行段中,然后根据配置选择需要加载的卷积神经网络模型Conv1_n.elf到自己的DDR程序运行段中,这些配置存储在非易失性参数存储器中。加载完成后,通知1号处理启动应用程序,同时自己也启动深度学习网络应用程序,完成BootLoader的整个过程[13]。
系统的多重加载主要体现在同时拥有多个Conv1_n.elf,即多种网络模型应用,在特定的环境启动不同网络算法完成特殊功能。不仅如此,还可以通过外部PC软件为系统更换这些网络模型文件。目前设计预置网络模型的最大数量为10个,烧写在10个指定NOR Flash偏移地址中。
4 软件设计
系统的软件设计主要包括处理器的嵌入式开发和上位机软件的库文件,即双核处理器的应用程序和面向最终用户的终端软件中间件程序。
4.1 嵌入式开发
0号处理器是主控处理器,它需要初始所有的外部设备,配置自定义的卷积神经网络算法模型,分配和管理多种数据块缓存。1号处理器主要负责网络传输,它根据0号处理器发送的缓存状态信息,将FPGA产生的数据从DDR发送到TCP/IP网络协议栈。嵌入式开发使用的是Xilinx公司提供的Vivado SDK,它是一款界面十分友好的嵌入式编译器,使用C或C++编写源码程序,开发难度等同于ARM嵌入式系统开发难度[14]。
固化在硬件中的程序主要在2个MicroBlaze处理器中,包括CAM采图模块和DLA卷积神经网络计算模块,另外还包括数据传输中使用的DMA传输。由于0号处理器作为主要的控制单元,1号处理器主要负责网络传输,因此针对不同的网络模型,需要修改0号处理器对DLA模块的控制逻辑,并修改CAM采图后的图像抽样以满足特定网络需求,其他的配置都不需要变化。
0号处理器的执行流程:
(1)初始化硬件,训练LVDS接口的采图时序;
(2)建立DLA的执行网络模型,指定DLA的内存分配;
(3)设置CAM采图配置,设置采图后的数据抽样;
(4)启动卷积神经网络算法,执行采图;
(5)取出计算结果。
4.2 中间件开发
上位机软件的库文件是提供给最终用户的客户端使用的,又称为中间件程序,中间件首先将负责的配置指令重新整合,并提供给用户控制接口,方便用户调用。其次将网络数据重新打包,以整合好的包数据格式提供给终端客户,最后中间件提供了一个日志信息和错误信息接口,记录了必要的状态信息和异常情况,方便用户回溯历史行为和排查异常。
5 实验结果
文中使用自制的搭载Xilinx FPGA A7板卡和CMOS传感器,以及配套的电源、镜头等外部设备,实时采集产线上的产品,并将深度学习处理过的数据通过千兆网发送到工控机处理。其中工控机配置I5 5520双核4线程处理器,8 G内存,500 G固态硬盘,Windows7操作系统。
配置的网络模型为经典的ImageNet,其中DLA的硬件处理单元为8,传感器采集实时图像,抽样尺寸为227*227*3的ImageNet标准输入,测试结果为每秒处理155张采集图像,板卡和传感器的总功率约12 W。表2是消耗的主要FPGA资源。
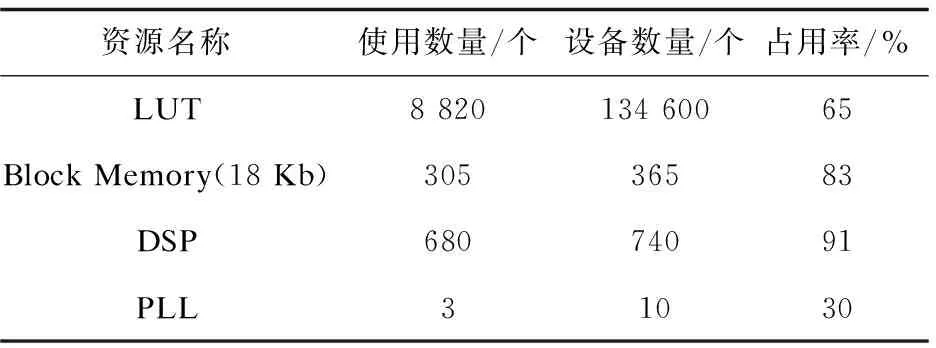
表2 PE=8的卷积神经网络计算模型占用的资源
6 结束语
文中采用DLA算法核心,在FPGA上实现了卷积神经网络。系统基于Xilinx的MicroBlaze SOC技术,在单片FPGA上集成一体化环境,将DLA的卷积算法模型集成到设备上,并提供远程算法升级和多重网络模型的动态加载,降低了工程人员将自定义机器学习算法落地到工厂的难度,提高了对机器视觉设备的可维护性,有利于推进卷积神经网络在工业化视觉领域中的应用。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
家庭影院技术(2021年6期)2021-07-28
软件(2017年6期)2017-09-23
微型计算机(2009年17期)2009-05-19
