
基于稠密自编码器的无监督番茄植株图像深度估计模型
2020-07-22 14:37周云成邓寒冰许童羽
农业工程学报 2020年11期
周云成,邓寒冰,许童羽,苗 腾,吴 琼
(沈阳农业大学信息与电气工程学院,沈阳 110866)
0 引 言
由于作物生长等,日光温室通常为不断变化的非结构化环境,在该环境下自主作业的移动机器人需要识别行进通道与障碍物[1],规划作业路径[2],同时在采摘[3]、施药[4]等生产过程中则需要定位作业目标。这要求机器人首先能够利用自身视觉系统探索出工作环境的三维空间结构信息,而深度估计是实现这一任务的关键,也是视觉系统的基本问题之一。
激光雷达(Light Detection and Ranging,LiDAR)、Kinect 等有源传感器和图像技术常被用于深度信息获取。Masuzawa 等[5]用LiDAR 感知深度,结合数码相机,开发了温室花卉收获移动机器人原型。孙国祥等[6]基于Kinect,用多视角RGB-D(红绿蓝—深)位姿自主标定法和相位相关技术,结合多光谱数据,重建温室番茄植株多模态三维模型。肖珂等[2]用形态学方法从Kinect 的RGB 图像中分割葡萄园叶墙区域,结合深度数据,基于样条区域计算叶墙平均距离,用于规划自走式农药喷施试验平台的行进路径。有源传感器可直接感知深度,但目前还存在着一些制约因素。LiDAR 成本高昂[7],且仅有深度信息,通常需要和其他成像设备集成才能构成作业平台的视觉系统。Kinect 采用光飞行时间技术获取深度信息,但其投射的红外激光极易受日光干扰,深度数据噪声大,温室环境适应性差。基于图像的立体匹配是另一种常用的深度信息获取技术。翟志强等[8]用最小核值相似算子提取棉田图像角点特征,通过基于Census 变换的立体匹配计算作物行特征点坐标,用于拟合其中心线。植株图像纹理单一、重复,人工设计的特征提取算子可区分度小,误匹配严重。近年来,以卷积神经网络(Convolution Neural Network,CNN)为代表的深度学习技术在单目深度估计中取得了重要进展[9-14],逐渐成为图像深度恢复的主要方法。区别于人工特征,CNN 用自动提取的丰富卷积特征实现基于图像的深度恢复。通过使用带有深度标注的图像,Eigen 等[9]用有监督学习法训练了一个基于CNN 的深度估计模型。然而采集大量含高精度深度信息的多样性图像数据是极具挑战性的[10],且有监督学习无法适应变化的环境。近期有学者研究仅利用同步立体图像或视频流训练单目深度估计模型。Godard等[11]提出一种基于左右目约束的无监督深度估计方法。Wang 等[12]将可微分视觉里程计集成到单目模型中,用连续视频帧做输入,通过无监督学习,实现深度和位姿变换的同步预测。Pilzer 等[13]通过知识蒸馏技术无监督训练单目深度估计模型。单目深度估计存在尺度模糊问题,深度预测值和实际值之间存在着一个未知比例系数,且用视频流训练单目模型的前提假设是场景静止[14],即只有相机相对于场景做运动。由于作物植株体为柔性材料,机器人运动以及风对植株的扰动,使得场景并非绝对静止。
鉴于温室移动机器人对深度信息获取的实际需求,以及单目深度估计模型存在的问题,提出一种基于稠密卷积自编码器的无监督植株图像深度估计模型,该模型用双目相机采集的左、右目图像进行训练,通过图像采集的同步性及相机已知参数来克服单目深度估计存在的问题。借鉴已有研究成果,优化设计深度卷积神经网络结构和模型损失函数,以模型估计的深度值误差及阈值精度等为判据,以番茄植株图像为例,验证模型的有效性,以期为温室移动机器人视觉系统设计提供参考。
1 植株双目图像数据集构建
用Stereolabs ZED 2k 双目相机采集数据,该设备可同步采集左、右目 RGB 图像,单目图像分辨率为1 920×1 080 像素,有效采样距离为0.5~20 m。为获取相机参数并矫正图像畸变问题,基于Zhang[15]的方法,采集高精度棋盘格图像,并采用MATLAB R2018a 中的立体相机标定工具箱对相机进行标定,得到双目相机的焦距f、像平面主点坐标[ cx, cy]、左右镜头光心间的基线距离(b,mm)以及畸变系数等内、外参数。
图像数据于2019 年1-3 月采集自沈阳农业大学实验基地某辽沈IV 型节能日光温室(60 m×10 m)和沈阳市辽中区某生产用日光温室(150 m×9 m),种植作物为番茄,掉蔓生长,株高1.5~2.7 m,行距0.8~1.0 m,株距0.25~0.35 m,处于结果期。分别在阴天、多云和晴朗天气的9:00-15:00时段采集多种光照条件下的植株图像并记录天气状况。在行间不同高度沿株行方向多角度对相机前方场景成像,并在离株行0.5 m 以上距离对一侧植株成像,同时沿温室行走通道对含植株的场景进行图像采集,以尽量提高样本的多样性。共采集番茄植株双目图像16 000 对。
基于相机内、外参数,采用Bouguet 法[16],对双目图像进行校正,使相机光轴平行,同一空间点在左、右目图像上所成像素行对齐(行号相同)。对于每一对校正后的双目图像,采用立体匹配法获取稀疏视差值,用尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)算子[17]分别提取左、右目图像的特征点,用K 最近邻算法对双目图像中的特征点进行匹配,并用人工走查的方式剔除误匹配点。根据匹配特征点的坐标,得到稀疏特征点间的实际视差值。全部双目图像及相应稀疏视差值共同构成番茄植株双目图像数据集。
2 无监督植株图像深度估计模型的提出
2.1 图像视差及置信度估计方法
设空间点P 在左、右目图像上的投影像素(称为对应像素)坐标分别为[ xl, yl]、[ xr, yr],根据双目视觉原理如式(1)所示

式中 d = xl- xr表示视差,[ X , Y , Z ]为P 的三维坐标,mm。如f、b、[ cx, cy]已知,通过估计对应像素间的视差,可实现场景深度Z 及三维结构信息的恢复。

式中 lpe 为对 Il~ 与 Il的相似度度量,并规定其值越小相似度越高。同理,用 rpe 表示 Ir~ 与 Ir的相似度。采用深度神经网络(Deep Neural Network,DNN)来逼近函数g,以为主要优化目标,用双目图像对其进行训练。该方法无需深度数据作标注,属无监督学习。
2.2 损失函数的定义
2.2.1 图像重构损失
现有研究采用光度误差和结构近似度指数(Structural Similarity Index,SSIM)[18]的组合作为pe 函数[11-14]。植株器官非理想朗伯体,且左、右目相机物理特性存在差异,对应像素在双目图像上的光度值可能不同,即使DNN预测的视差是准确的,重构图像与目标图像也会有差异,仅含光度、对比度和简单结构特征比较的光度误差和SSIM 组合不足以度量植株图像的相似性。本研究引入更加多样性[19]的卷积特征比较。用完成训练的Inception V3网络的前4 层[20]卷积特征来进一步度量2 幅图像的相似性,如式(3)所示
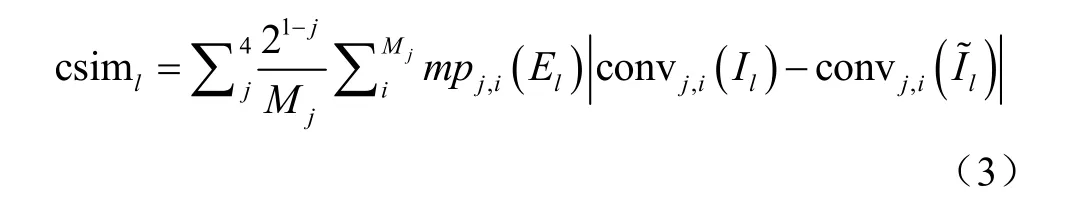
式中csiml表示l与 Il的卷积特征近似性,convj为Inception V3 网络的第j 层卷积操作,c onvj,i( Il)为图像 Il的第j 层卷积特征图的第i 个像素, Mj为第j 层特征图的像素数,mp 表示最大池化(max-pooling),用 21-j作为系数,调整各层特征对近似性度量的贡献。采用置信度 El抑制因消失点而无法重构的像素所引入的问题梯度,式(3)的计算需要置信度图与卷积特征图在空间尺度上相同,用mp 对 El进行空间降维,使 jmp 与convj的累积感受野相同。用L1(1 范数)形式光度误差、SSIM和csim 的线性组合重新定义pe 函数如式(4)所示

式中M 为图像像素数, I,li等表示 Il的第i 个像素,α 、β 、γ 为各项的比例调整系数。
2.2.2 约束项
在式(4)基础上进一步为DNN 的训练引入多个约束项。视差跳变通常在具有显著图像梯度的目标边缘区域。采用二阶Laplacian 算子2∇提取图像梯度,对低图像梯度区域的视差跳变进行局部平滑约束,如式(5)所示

式中Lsm,l表示左目视差局部平滑约束, ∂xx、 ∂yy、 ∂xy表示在x、y 方向和对角线上的二阶梯度。由像素对应关系,在 Dr上采样重构的左目视差图应和 Dl具有一致性,采用式(6)对视差一致性进行约束。


2.2.3 损失函数
以图像重构损失和各约束项的线性组合作为DNN优化训练的损失函数,如式(8)所示

式中 ,t lL 表示针对左目视差和置信度的损失,η、λ、ζ 表示各项损失的比例系数。基于 Ir、r、Dr、 Er,按式(3)~式(8)方式构建右目视差和置信度损失 ,t rL ,左、右目总损失为
2.3 视差估计精度判据
设番茄植株双目图像数据集中视差值已知的稀疏点数量为N, di为像素i(N 中的1 个)的实际视差值, di为DNN 估计视差值。由式(1)计算出i 在左目相机坐标系下的三维实际坐标[ Xi, Yi, Zi]和估计坐标。基于此,按现有研究常采用的标准评估指标评价视差估计精度[9-14],主要包括估计深度i和实际深度 Zi间的平均相 对 误 差( Mean Relative Error , Rel ) 为平方相对误差(Squared Relative Error,Sq Rel,mm)为平均绝
对 误 差( Mean Absolute Error , MAE , mm) 为均方根误差(Root Mean Squared Error,RMSE,mm)为10log RMSE(RMSElog)为阈值精度,%,即满足的点i 占总量N 的比例(本研究设置从而,进一步引入估计坐标和实际坐标间的平均距离误差(Mean Range Error,MRE,mm)为来衡量估计视差的精度。各误差指标越小、阈值精度指标越大,则说明视差估计的精度越高。
同时用重构图像 Il~ 与目标图像 Il的相似度来间接度量视差图精度。本研究采用与主观评价法具有高度一致性的特征相似性指数(Feature Similarity Index,FSIM)[21]、信息内容加权SSIM(Information Content Weighted SSIM,IW-SSIM)[22]和梯度相似性指数(Gradient Similarity Index,GSIM)[23]作为相似度(%)评价指标,指标值越高说明图像相似度越大。
3 深度神经网络结构设计
以姿态估计[24]、语义分割[25]等任务中常用的卷积自编码器(Convolutional Auto-Encoder,CAE)作为逼近函数g 的DNN 基本结构,并进行设计优化。
3.1 基于可分卷积的稠密卷积模块设计
受Jégou 等[26]的研究启发,用稠密卷积模块(Dense Convolution Block,DB)[27]作为CAE 的构建组件。对于有n 层卷积(n 为超参数)构成的DB 模块,其第j 层输出特征图 xj是定义在模块初始输入 x0及j 层之前各层输出( x1~xj-1)上的非线性变换,如式(9)所示

式中 jH 为第j 层的非线性变换,[ ]… 表示在通道维上的特征图连接。DB 模块的每层卷积均固定输出k 个特征图,k 称为增长率超参数,在通道维上连接n 层输出,构成nk个通道的特征图作为其最终输出。
用可分卷积(Separable Convolution,SepConv)[28]替换原DB 模块[27]中的标准卷积,用SepConv、批归一化(Batch Normalization,BN)和激活函数的顺序组合作为非线性变换H,构建基于SepConv 的DB 模块(图1a)。SepConv 首先在输入特征图的每个独立通道上用步长(stride,s)为1 且启用边界填充(pad)的3×3 深度卷积来映射空间相关性,然后用1×1 点卷积来映射通道间相关性。设SepConv 的输入、输出通道数分别为A 和B,其权重参数数量而对应标准卷积的参数量为当B 较大时,SepConv的参数量约为后者的1/9。因此,基于SepConv 构建 DB模块能有效降低参数数量。
3.2 卷积自编码器构建
基于DB 模块构建CAE(图1)。其中编码器包括1个输入模块(Input Block,IB)、4 个带旁路连接的DB模块(图1b)和4 个下采样层。IB(图1c)采用s 为2、启用pad 且输出通道数为2 倍增长率的5×5 卷积(conv 2k, 5×5, s=2, pad)对在通道维上连接后的双目图像进行卷积运算,使输出特征图在空间维减半[29]。下采样层采用s为2、启用pad 且输出通道数与输入相同的3×3 可分卷积(SepConv 3×3, s=2, pad),该层在对特征图进行空间降维的同时,提取和融合DB 模块的输出特征。解码器对应包含4 个上采样层、4 个DB 模块和1 个终端模块(Ending Block,EB)。上采样层采用s 为2、启用pad、输出通道数与输入相同的 3×3 转置卷积(Transposed Convolution,TransConv)使特征图在空间维扩大2 倍。EB(图1d)先用上采样层将特征图恢复为输入图像相同尺寸,再用启用pad 的SepConv k,3×3 的特征图作为输出,用于进一步的视差和置信度预测。解码器的DB 模块不采用旁路连接,避免经上采样层逐渐放大后的特征图因不断累积而带来的巨量计算和存储需求。CAE 的瓶颈层同样采用DB 模块。

图1 卷积模块 Fig.1 Convolution blocks
编、解码器之间的跨越连接[9-14]可解决下采样造成的目标边缘、位置等细节信息消失问题。假设CAE 对视差的预测依赖于对应像素在空间维上建立的相关性,则视差较大的对应像素需经过多层下采样才可建立相关性,这将降低位置信息的准确性,进而影响视差预测精度。基于该假设,提出在跨越连接上引入跨越模块(Skip Block,SKB),通过SKB(图1e)的累积感受野来降低为建立相关性而需经过的下采样层数。SKB 在内部采用DB 模块扩大累积感受野,在输入端用输出通道数为该DB 模块输出通道数一半的conv nk/2,1×1,s=1 压缩来自编码器的特征通道维数,输出端则用conv nk,1×1,s=1融合DB 模块的输出特征。
3.3 视差及置信度预测
采用conv 4,3×3,s=1,pad 标准卷积作为视差及置信度预测模块(Disparity and Confidence Block,DCB),该模块(图1f)用Sigmoid 函数对4 个输出特征图进行归一化,其中2 个作为对 Dl、Dr的归一化预测,另外2个作为对 El、 Er的预测。设归一化视差值为d˙,最大视差占图像宽度 W 的比例不高于ω ,则实际视差值归一化处理可避免DCB 预测出异常( 0d< 或d W> )视差。
fw对采样点邻近像素采样来重构图像,其回传梯度具有局部性,不利于网络在大尺度范围内探索对应像素间的相关性[10-11]。本研究通过预测多尺度视差图来克服该问题,将4 个DCB 分别连接到解码器EB 及末端3 个DB 上。与输入图像尺寸相比,DCB1~DCB4分别预测1、1/2、1/4 及1/8 尺度的视差及置信度图。同时,将DCB的预测结果在通道维上与相应DB 的输出特征图连接(图 1g)后送入下一模块,用于下一尺度视差及置信度图的预测。分别计算每一尺度视差及置信度损失网络的总损失由各尺度损失求和得到通过以式(10)为CAE 的训练优化目标,得到各尺度视差及置信度图。


图2 稠密卷积自编码器 Fig.2 Dense convolutional auto-encoder
在 L(p)t的计算中,本研究分别将DCB2~DCB4预测的视差及置信度图上采样到网络输入图像的尺度后再进行图像重构和损失计算(图3),以提高回传梯度的质量。

图3 上采样及损失计算模型 Fig.3 Up-sampling and loss calculation model
4 深度估计试验与结果分析
4.1 参数设置及网络训练
(CNT K)v2.7[29]基础上,采用其提供的Python 接口编程在深度学习计算框架 Microsoft Cognitive Tools实现无监督植株图像深度估计网络模型。 fw用空间变换网络(Spatial Transformer Network,STN)[30]的可微分双线性插值采样函数实现。根据预试验,损失函数的调整系数分别设置为 α=0.15、 β=0.85、 γ=1.0、 η=1.0、λ=0.15、 ζ=8.0可取得理想结果。根据双目图像采集设备的参数,设置最大视差占图像宽度比例系数 ω=0.3。
用在计算机视觉任务[24-27]中广泛采用的自适应矩(Adaptive Moment,Adam)优化器训练网络模型,设置1 阶矩指数衰减率 β1=0.9、2 阶矩指数衰减率 β2=0.999、权重衰减系数为10-4,用初始学习率2.5×10-4进行20 轮(epochs)迭代训练,此后每经10 轮迭代,学习率下降10 倍[14]。预试验表明,经过40 轮迭代,网络损失可收敛到稳定值。
网络模型的训练和测试试验在Tesla K40c 计算卡上进行,试验用计算机配置有32 GB 内存,双路Intel Xeon E2603 处理器,Windows Server 2012 操作系统。每个网络重复试验5 次,每次试验从由16 000 对番茄植株双目图像构成的数据集中随机选择85%的样本用于网络模型训练,其余15%的样本(测试集)用于网络精度的测试。
网络输入图像的大小设置为512×384 像素。网络训练过程中采用数据增广技术来提高其泛化效果。首先对原双目图像进行裁剪,方法为对双目图像上的相同位置进行随机裁剪(crop),裁剪后的宽、高不低于原图像的85%,然后将裁剪后的图像用最邻近插值法调整为输入大小。接着对调整大小后的图像进行随机水平翻转和垂直翻转,并对其亮度、对比度和饱和度作随机调整,用以模拟多种光环境下的RGB 成像,提高网络对光环境变化的鲁棒性。其中亮度和对比度的调整用实现,pix 为像素颜色分量,2 个参数分别用于随机调节对比度和亮度。饱和度的调整需将图像由RGB 转换为HSV(Hue-Saturation-Value,色相-饱和度-明度)空间,对饱和度S 执行[0.85,1.15]范围内的随机倍数变换后,再转回RGB 空间。增广后的图像在输入模块中用对各像素分量进行[-1,1]归一化,以加快网络收敛速度[28]。
4.2 网络测试与分析
参照Jégou 等[26],CAE 网络的DB 模块的超参数设置为n=4(瓶颈DB 除外,其n=8)、k=24,为分析网络结构对视差预测精度的影响,通过采用不同处理(表1),构建了8 种结构(A~H)的CAE。其中启用跨越模块处理指在CAE 的跨越连接上引入SKB,否则采用直连方式。预测置信度处理指DCB 同时预测视差图及相应置信度图,否则仅预测视差图(此时,置信度不再参与损失计算,相当于置信度图的所有元素为1)。连接视差图处理指图1g 所示的模块中,仅将DCB 预测的视差图连接到对应DB 的输出上,连接置信度处理指仅将置信度图连接到输出特征图上,否则不再连接视差图或置信度图。上采样视差图处理指将DCB 预测的低分辨率视差及置信度图上采样到与输入图像相同尺寸后,进行图像重构和损失计算,否则直接在低分辨率预测结果上进行损失计算。
激活函数是影响网络非线性能力和训练稳定性的重要因素。以结构A 为深度估计模型的基础网络,在DB模块的H 函数和除DCB 模块以外的其他卷积操作中分别采用指数线性单元(Exponential Linear Unit,ELU)[31]、缩放ELU(Scaled-ELU,SELU)[32]、修正线性单元(Rectified Linear Unit,ReLU)[19]、渗漏型 ReLU (Leaky-ReLU)[33]和参数化ReLU(Param-ReLU)[34]共5种在CNN 中常用的非线性变换作为激活函数,开展训练和测试试验,结果如表2 所示。

表1 采用不同处理方法的8 种网络结构 Table 1 Eight network structures with different treatments

表2 激活函数对深度估计精度的影响 Table 2 Effect of the activation function on accuracy of depth estimation
由表2 可知,激活函数影响深度估计精度。总体上含ReLU 的激活函数的各项指标都优于ELU 和SELU,这可能和后两者在输入<0 时易限入饱和区域,网络更新缓慢有关。ReLU 和Leaky-ReLU 的各项深度估计误差平均值均低于或显著低于Param-ReLU,阈值精度也显著高于后者。最小化图像重构损失是网络的主要优化目标,Param-ReLU 包含额外的可学习参数,易产生过拟合,这是其图像相似度平均值高于ReLU 和Leaky-ReLU,但误差和阈值精度指标却相对较差的原因。Leaky-ReLU 和ReLU 的各项指标均没有显著差异,但前者具有更小的误差和更高的阈值精度平均值,这与后者导致的输出偏移和部分神经元死亡有关。因此,选择Leaky-ReLU 作为网络激活函数,分别对表1 中的8 种结构模型进行训练与测试,结果如表3 所示。

表3 网络结构对深度估计精度的影响 Table 3 Influence of the network structure on accuracy of depth estimation
由表3 可知,网络结构显著影响深度估计精度。结构A 在B 的基础上启用了SKB,使A 在5 种深度估计误差平均值上低于B,在阈值精度和图像相似度上也高于后者,说明SKB 对提高深度估计精度具有一定作用。A 在C 的基础上增加了视差置信度预测,这种处理使A 的6种误差指标均显著低于C,其中MAE 和RMSE 分别降低了55.2%和33.0%,同时阈值精度显著高于后者,A 具有更高的深度估计精度。由于消失点问题,重构图像的部分像素无法采样重建,在pe 函数中缺少置信度对这些像素比较的抑制,会造成问题梯度回传,使网络在采样图像上搜索与目标图像近似的像素来降低重构误差,从而产生错误的视差预测,这可能是C 的图像相似度高于A,但模型精度却显著低于A 的原因。D 在A 的基础上,将DCB 预测的视差图连接到相应DB 模块,除RMSE 显著降低外,其他误差指标都有所升高(其中2 种显著升高),阈值精度有所下降(其中1 种显著下降),说明仅将视差图连接到DB 对提高深度预测精度是无效的。对比E和A 可知,将视差置信度图接入DB 模块也未能提高模型精度。
F 在A 的基础上,将网络预测的多尺度视差及置信度图上采样到输入图像尺寸后进行图像重构和损失计算,该处理使F 的5 种误差平均值有所下降,2 种阈值精度和3 种图像相似度指标有所提高(其中IW-SSIM 显著提高),说明上采样处理对提高深度估计精度是有一定作用的。对比G 和A、D、F,同时采用连接视差图和上采样处理的结构G,显著降低了深度估计误差、提高了阈值精度,G 对A 的MAE 和RMSE 分别降低了23.7%和27.5%。相对于在小尺度模糊图像上的损失计算,更大尺度的图像具有更高的清晰性,网络回传的误差梯度质量更高,基于更高质量梯度训练的DCB 模块能够预测出更高质量的多尺度视差图,将更高质量的视差图输入到解码器中,可进一步提高后续DCB 模块的预测能力。D 的DCB 误差梯度来源于小尺度模糊图像,梯度质量低,进而产生低精度或错误的多尺度视差图,将这种视差图输入编码器,会干扰后续DCB 对视差的预测,这可能是D 相对于A,其深度估计精度下降的原因。H在G 的基础上增加连接视差置信度图处理,但性能未能进一步提高,因此本研究以G 作为深度估计模型的最终结构。
4.3 方法比较与分析
在近几年出现的无监督深度估计方法中,Monodepth2[14]和DepthGAN[35]是2 个可以通过输入双目图像进行训练和测试的典型代表,具有最高的深度估计精度。同时,为分析网络宽度和深度对视差预测性能的影响,以G 为基础,在固定SKB 的前提下,引入G-I 和G-II,其中G-I 维持G 的超参数n 不变,减小DB 模块的增长率为k=16,即降低G-I 中DB 模块的输出通道数(网络宽度),G-II 则保持k 不变,减小DB 模块的超参数为n=3(瓶颈DB 的n=6),即降低G-II 的网络深度。对本研究网络G、G-I、G-II 与Monodepth2、DepthGAN 在番茄植株图像深度估计上的精度及计算速度进行比较,并以Stereolabs ZED 2k 双目相机软件开发包(Software Development Kit,SDK)计算的深度数据作为基准之一,结果如表4 所示。

表4 不同深度估计方法性能比较 Table 4 Performance comparison of different depth estimation methods
由表4 可知,就番茄植株图像深度估计任务而言,开发包和DepthGAN 的精度较低。开发包具有较高的计算速度,但各项深度估计精度指标均显著低于本研究网络。与DepthGAN 相比,除图像相似度外,本研究网络在其他指标上都显著优于该方法。DepthGAN 是一种生成对抗模型,而生成对抗存在着梯度消失、难以收敛到纳什均衡的问题,本研究模型的梯度主要来源于图像人工特征和卷积特征的比较,梯度稳定且无消失问题。与Monodepth2 相比,G 在5 种误差指标上显著低于前者,其中Rel、MAE 和MRE 分别降低了46.0%、26.0%和25.5%,同时在阈值精度上也显著高于前者,表明本研究模型具有更高的精度。Monodepth2 仅采用光度值和人工特征比较图像相似度,且没有采取任何措施来抑制消失点引入的问题梯度,其以最小化图像重构误差为优化目标,将产生高质量的重构图像,但也会产生部分错误的视差预测,这是该方法图像相似度指标高于本研究方法,但其视差估计性能却低于本研究网络的原因。G 的图像相似度指标显著高于G-I、G-II,其他各项精度指标虽无显著差异,但G 具有更低的误差和更高的阈值精度平均值,表明增加网络的宽度或深度可提高深度估计性能,这得益于更宽、更深的网络可提取更多和更高层的图像特征。G 和G-I、G-II 的比较也表明,通过调整超参数n、k,可对模型的精度和计算速度进行平衡。与G 相比,G-I和G-II 的速度显著提高,分别为13.9 和14.2 帧/s,同时在除RMSE 和图像相似度之外的各项性能指标上也优于Monodepth2。鉴于G 具有更高的精度,采用其对番茄植株双目图像测试集中部分图像的深度进行预测,结果如图4 和图5 所示。
由图4 可以看出,图像对应的视差(深度)图能够反映其三维结构,样本1 的视差图(图4b)反映了株与株之间的间隔,样本2 的视差图表示出了2 株行间的行走通道,以及行内目标的远近。由视差置信度(图 4c)对左目图像的遮罩(图4d)可以看出,模型对图像左边缘像素的视差预测的置信度偏低,这与由于视角原因,左目图像的左边缘像素在右目图像以外,模型无法通过对应像素匹配实现视差精确预测的实际情况相符。同时对于图像模糊(图4a 样本1 左上方)区域,其视差置信度也偏低,因此,为提高模型预测精度,应改善图像采样的清晰度。样本1 遮罩结果表明,番茄果实区域具有较高的置信度,即该区域的视差精度较高,这为模型应用于基于视觉定位的果实采摘或对靶施药等提供了可能。

图4 番茄植株图像视差及置信度预测 Fig.4 Disparity and confidence estimation for tomato plant images

图5 番茄植株图像深度估计示例 Fig.5 Examples of tomato plant image depth estimation
图5 表明,模型预测出了多个视角下的行间行走通道,这说明模型用于温室移动机器人作业导航是可行的。图5a和图5b 为在阴天、逆光条件下的成像,模型也较好的预测出了其对应的三维空间结构。图5e 和图5f 包含了纹理单一的温室后保温墙,从对应视差图可以看出,模型预测出了后保温墙的平滑的深度变化,说明模型能够克服传统立体图像匹配法无法对低纹理区域实现有效匹配的问题。由图5k 和图5l 的视差图可以看出,模型对纤细的番茄植株茎秆部分也给出了较好的预测,这为模型应用于避障提供了可能。
为明确深度估计模型预测的各尺度视差图的差异,进一步对以G 为基础的模型预测的各尺度视差图的精度进行分析,结果如表5 所示。
由表5 可知,随着视差图尺度的缩小,图像相似度指标逐渐缩小,深度估计误差整体呈上升趋势,最小尺度视差图在Sq Rel、MAE、RMSE 和MRE 误差上显著高于其他尺度,其他2 种误差则各尺度之间差异不显著。总体来看,DCB1和DCB2预测的视差精度要高于DCB3和DCB4,DCB1和DCB2之间则无显著差异,表明终端模块对DCB1视差预测精度的提高没有明显贡献,CAE 结构的优化值得进一步深入探讨。

表5 多尺度视差图精度比较 Table 5 Accuracy comparison between multi-scale disparity maps
4.4 空间点深度及光照条件对深度估计精度的影响
根据番茄植株双目图像测试集中已知视差值的稀疏点的深度值iZ ,分别提取出深度在0~3、0~6 和0~9 m的空间点,并根据模型G 估计的这些点的视差值,计算深度估计误差及阈值精度,分析空间点深度对深度估计精度的影响,结果如表6 所示。

表6 空间点深度对深度估计精度的影响 Table 6 Effect of the spatial point depth on accuracy of depth estimation
由表6 可知,除Rel 和RMSElog无显著差异外,其他误差随空间点深度的减小而显著降低。这是因为,空间点深度越小,其视差值越大,根据式(1),相同的视差偏移对小深度空间点造成的深度误差小于大深度空间点。同时,表6 表明,阈值精度不随空间点深度的变化而显著变化。在9 m 范围内,模型估计深度的MAE为140.8 mm(<14.1 cm),在6 m 范围内,MAE 为93.3 mm(<9.4 cm),在3 m 范围内,MAE 降为66.0 mm(<7.0 cm)。
按番茄植株双目图像测试集样本采样时记录的天气状况,将其分成阴天、多云和晴朗3 类,分析光照条件对深度估计精度的影响,结果如表7 所示。

表7 光照条件对深度估计精度的影响 Table 7 Influence of illumination conditions on accuracy of depth estimation
由表7 可知,就各项指标平均值而言,多云条件下的深度估计精度要好于阴天和晴朗天气,这和阴天弱光条件下采集的图像对比度差,晴朗天气强光条件下光暗对比过大,图像部分区域曝光不充分,影响了模型对图像特征的提取有关,表明光照条件对深度估计性能具有一定影响。但除GSIM 外,其他各项指标差异并不显著,这也说明本研究模型对光环境变化具有一定的鲁棒性。
5 结 论
提出一种基于稠密卷积自编码器的无监督植株图像深度估计模型,该模型可通过双目图像进行训练。以深度估计误差、阈值精度及图像相似度为判据,在番茄植株双目图像上进行训练和测试试验,结果表明:
1)深度估计模型通过预测视差置信度,抑制问题梯度回传,显著提高了深度估计精度,其平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)分别降低了55.2%和33.0%。
2)同时将网络预测的多尺度视差图接入编码器并将其上采样到输入图像尺度后参与损失计算,估计深度的MAE 和RMSE 进一步降低了23.7%和27.5%,该处理对提高深度估计精度是有效的。
3)深度估计误差随空间点深度的减小而显著降低,当空间点深度在9 m以内时,估计深度的MAE < 14.1 cm,当在3 m 以内时,则MAE < 7 cm。
4)光照条件对深度估计模型精度的影响不显著,本研究方法对光环境变化具有一定的鲁棒性。
5)与已有研究相比,本研究方法的平均相对误差、MAE 和平均距离误差分别降低了46.0%、26.0%和25.5%,深度估计精度显著提高。本研究可为温室移动机器人视觉系统设计提供参考。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
计算机应用与软件(2022年1期)2022-01-28
小型微型计算机系统(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
计算机与数字工程(2020年11期)2020-12-23
疯狂英语·新悦读(2020年6期)2020-06-28
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
