
基于特征金字塔注意力与深度卷积网络的多目标生猪检测
2020-07-22 14:37燕红文刘振宇崔清亮胡志伟
农业工程学报 2020年11期
燕红文,刘振宇,崔清亮,胡志伟
(1. 山西农业大学信息科学与工程学院,太谷 030801;2. 山西农业大学工学院,太谷 030801)
0 引 言1
随着生猪养殖模式规模化、集约化发展,现有猪场养殖环境监测与控制系统多基于传感器获取猪舍温度、湿度、光照强度等外界环境信息间接评测生猪个体状况,而生猪自身行为如饮食、站爬姿态等包含丰富的生物学信息,可用于生猪营养与健康评估,而对生猪个体研究的关键步骤和难点是将其从群养环境中检测出来。但在实际养殖环境中,生猪黏连、杂物遮挡等客观因素给多目标生猪个体检测带来较大挑战,迫切需要高效准确的检测算法进行生猪行为分析、个体识别、计数等,进而提升猪场经济效益[1-2]。
基于深度学习的卷积神经网络CNN(Convolutional Neural Network)对图像特征具有强大的表征能力[3-4],已在生猪图像分割[5-8]、行为识别[9-10]、姿态检测[11]、身份鉴定[12]等方面取得较多成果,在目标检测领域同样表现出优越性能[13-15]。基于CNN 的目标检测包括基于区域[16-19]与基于回归2 大类,基于回归思想的算法有YOLOV1、YOLOV2、YOLOV3 等系列[20-23],其将检测目标位置视作回归问题,在提升检测精度的同时保证了检测速度,适用于实际生产环境中,并已被用于苹果[24]、芒果[25]、柑橘[26]、夜间野兔[27]等对象的检测。在生猪个体检测方面,沈明霞等[28]针对仔猪个体较小、易黏连和杂物遮挡等现象,提出基于YOLOV3 的初生仔猪目标识别方法,燕红文等[29]在Tiny-YOLO 网络的基础上将通道注意力和空间注意力引入特征提取过程中,对群养生猪脸部进行高精度检测。但上述基于YOLO 网络的系列研究在特征提取过程中仅通过简单叠加方式构建卷积池化模块,未考虑池化操作前后不同大小特征图之间的信息交互问题。金字塔结构[30]可在像素级别提取不同尺度特征并行考虑多种感受野信息,对多种尺寸目标均有较好检测效果,并已在图像分割领域得到成熟应用[31-33],但金字塔结构中不同尺度特征图间仅通过简单线性叠加方式实现信息融合,忽视了不同层级分支间的非线性关联,受燕红文等[29]研究工作启发,注意力机制可通过仅关注利于任务实现的区域信息,抑制次要信息以提升模型效果,可用于高低阶特征图的非线性信息融合[34-36],因而探讨将注意力机制引入金字塔结构中并构建群养环境多目标生猪检测模型成为可能。
基于此,本文提出一种基于Tiny-YOLO 模型的非接触、多目标群养生猪检测算法,该方法结合特征金字塔注意力构建多种深度FPA 模块,将其嵌入Tiny-YOLO 模型中进行端到端训练,并研究不同超参数对模型检测效果影响,实现对无黏连无遮挡、无黏连有遮挡、有黏连无遮挡以及有黏连有遮挡等不同场景下群养生猪的高精度检测,以期为生猪身份识别和行为分析等提供模型支撑。
1 试验数据
1.1 试验数据来源
数据采集自山西省汾阳市冀村镇东宋家庄村与山西农业大学实验动物管理中心,分别于2019 年6 月1 日9:00-14:00(晴,光照强烈)与2019 年10 月13 日10:30- 12:00(多云,光照偏弱)进行2 次采集,为检验模型对不同品种生猪的检测性能,选取大白、长白及杜洛克混养品种猪作为拍摄对象,2 个猪场猪栏大小分别为3.5 m×2.5 m×1 m 和4 m×2.7 m×1 m,每栏生猪数量3~8只不等,选取其中8 栏日龄20~105 d 的群养生猪共计45 头作为试验对象。
1.2 数据采集方式
对生猪进行目标检测、个体行为分析等研究通常将摄像头固定于养殖栏顶部,采用俯视视角采集图片或视频[6,8-11,28],这种固定镜头和俯视视角的采集方式对其他视角的信息获取有限,而其他视角如平视可采集到生猪面部信息,更有利于对生猪进行目标检测等相关研究,且传统采集方式与模型的移动端拓展应用并不十分契合,为此,本研究尝试采用平视视角、镜头位置不固定的数据采集方式。试验采用佳能700D 防抖摄像头进行移动拍摄,镜头距离生猪个体0.3~3 m 不等,采集到不同大小的生猪个体和部分生猪黏连、栏杆遮挡、生猪互相遮挡等场景,共拍摄得到时长为35 s~64 min 的多段视频,每栏选取2 段拍摄时长超过30 min 的视频以保证数据源本身的连续性。相较于传统的镜头固定、俯视视角采集方式,本采集方式有2 个优势:易于采集到富含生物特征信息的生猪面部图像,可为生猪目标检测、个体识别、跟踪提供一种新的数据采集方案;适用于模型的移动端拓展应用,可为开发移动端模型提供数据采集参考方案。
1.3 试验数据预处理
对获取的视频做如下预处理以得到群养生猪多目标检测数据集:
1)对采集视频每间隔25 帧进行切割处理,得到分辨率1 920×1 080 大小的图片,为适应后续模型输入,对其边缘添加黑色像素使图像宽高比为2∶1,最终分辨率调整为2 048×1 024,并采用labelImg 作为生猪个体标注工具。如图1a~图1b。
2)为降低模型显存占用率,减少运算量,加速模型训练速度,对步骤1)获取的图片及其标注结果分别进行整体放缩及坐标变换操作,得到2 727 张分辨率512×256大小的图片。如图1b~1c 所示。
3)为丰富数据集、提升模型泛化能力,对步骤2)处理的图片进行数据增强操作,每张图片以50%的概率值执行改变亮度、加入高斯噪声以及翻转180°生成0~2 张增强图片,其中亮度修改阈值为0.8~1.2,大于1 表示调暗,小于1 表示调亮。
经上述处理后共获得标注图片4 102 张,按照通用数据集划分策略[37],以14∶3∶3 比例将数据集划分为训练集、验证集与测试集,其中训练集包括2 872 张图片,验证集和测试集各包含615 张图片。数据处理过程及效果如图1 所示。

图1 数据处理过程及效果 Fig.1 Data processing process and effects
2 检测模型
2.1 Tiny-YOLO 模型
YOLO 是由Redmon 等[20-22]提出的目标检测系列模型,包括YOLOV1、YOLOV2 和 YOLOV3 三大类。Tiny-YOLO 作为轻量化的YOLOV3,融合了最新的特征金字塔网络(Feature Pyramid Networks,FPN)[38]和全卷积网络(Fully Convolutional Networks,FCN)[39]技术,使用逻辑回归(Logistic Regression)对方框置信度进行回归,同时提出了跨尺度预测,并使用二元交叉熵损失(Binary Cross-Entropy Loss)进行类别预测,可更好地用于处理多标签任务,模型结构更简单,检测精度更高,速度更快。
Tiny-YOLO 模型的网络结构如图2 所示。该模型主要由卷积层与池化层堆叠构成。模型输入分辨率大小为512×256×3,由于不同种类目标在原始图像中所占比例差异较大,Tiny-YOLO 引入多尺度特征提取模块以保证对不同大小目标均具有较强的检测性能,因而在2 个检测尺度S 上(S 取16×8 与32×16)进行物体类别划分,每个卷积或上采样操作下方的数字代表对应操作的通道数量,其输出如图2 中①②所示,①和②分别表示获得不同尺度特征图2 种操作,其中①的S 取值16×8,原因在于获取到①对应输出时,中途对输入512×256×3 大小图像进行了5 次下采样操作,每次下采样操作均使特征图长度与宽度的分辨率降低一半,其最终特征图大小为16×8,②的S 取值32×16,对输入图像经过4 次下采样获得。通过将输入图像分成S 大小单元格,每个单元格的神经元负责检测落入该单元格的对象,并执行一系列3×3和1×1 卷积、池化以及上采样操作后分2 路得到①与②的特征图,每经过一次卷积和池化操作后,特征图分辨率缩减一半,对应特征图数目增大1 倍。引入非极大值抑制(Non Maximum Suppression,NMS)[40]剔除①与②的冗余检测框以保证对于每个目标均有唯一检测框,使预测位置信息更为准确,置信度更高。但Tiny-YOLO 模型在特征提取过程中,对于①与②多尺度特征图的获取仅通过简单的卷积池化层堆叠完成,使用不同池化层数量将使得输出特征图大小不一,截取不同池化层结果将获得不同尺度大小的输出,但这种方式忽视了高低维特征自身具有很强的特征筛选能力,简单抽取其作为后续输出势必浪费部分重要信息,若能对已抽取的特征图进行特征重校准,自动学习提取生猪个体部位有益信息,抑制诸如猪栏、猪粪等干扰因素的影响,可进一步提升生猪个体部位抽取精度。

图2 Tiny-YOLO 模型结构图 Fig.2 Tiny-YOLO model structure diagram
2.2 对Tiny-YOLO 模型的改进
经典Tiny-YOLO 模型通过卷积层与池化层层叠方式构建,在特征提取过程中未充分考虑不同尺度大小卷积层的获取特征图间的相互关系,而金字塔结构可从像素级提取不同尺度特征,并行考虑多种感受野信息,对尺寸较大或者较小的目标均有较强识别效果。但传统金字塔结构中不同尺度特征图间仅通过简单线性叠加完成信息融合,忽视了不同层级分支间的非线性关系。注意力机制可提取不同层级的非线性信息,通过仅关注利于任务实现的区域信息,抑制次要信息以提升模型效果,可用于高低阶特征图的非线性信息融合。Zhao 等[36]将特征金字塔注意力(Feature Pyramid Attention,FPA)引入图像分割领域,并取得不错的效果,受其启发,本文结合金字塔与注意力思想,提出适用于目标检测领域的FPA模块,本文FPA 模块相较于Zhao 等提出的FPA 模块进行2 点改进:为减少卷积运算量加快模型训练速度并综合考虑目标检测任务特点,去除原始FPA模块中的Global Pooling 分支;构建1~4 多种层级FPA 模块以深入探讨层级数对模型性能提升程度影响,本文FPA 模块如图3所示。
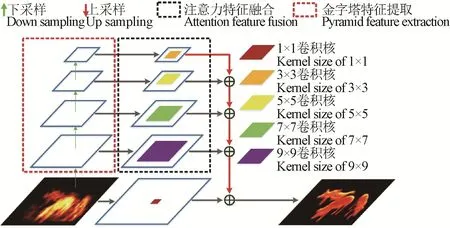
图3 FPA-4 特征金字塔注意力模块 Fig.3 FPA-4 feature pyramid attention module
特征金字塔注意力模块通过U 型结构融合多种不同尺度特征,包括金字塔特征提取组件簇与注意力特征融合组件簇2 大部分,如图3 虚线框部分所示,其中左侧虚线框表示金字塔特征提取,右侧虚线框表示注意力特征融合。金字塔特征提取组件簇共包括4层,层内执行3×3大小卷积操作进行多次特征提取,层间通过步长为2×2的池化下采样操作互连以逐步减小特征图分辨率大小,经金字塔特征提取组件处理后分别获得4 种不同尺度的特征图,且不同尺度特征图数量不相同。为了充分融合金字塔特征提取组件所获取的特征学习结果,引入注意力特征融合组件块,该组件块通过层级方式构建,从上至下分别采用3×3、5×5、7×7 和9×9 卷积核进行相应层级特征提取,将上一层特征选择结果经步长为2×2 的上采样操作生成注意力权重图与当前层对应卷积核大小的深层卷积操作结果叠加进行重校准,经该处理后,特征明显区域将得到有效加强,层与层间相连逐步集成不同尺度信息,从而能够更精确地合并上下层特征间的相邻尺度特征。为避免金字塔特征提取与融合过程对原始输入特征图带来的误判,对原始特征图经1×1 大小卷积操作后与上述金字塔特征融合模块操作结果进行线性叠加获得FPA 模块并输出。以上FPA 模块操作过程如式(1)~式(4)所示。
相较于医院院区间的信息共享,区域卫生信息共享需要克服不同医院在区域医疗体系中由于角色与定位不同带来的共建共享障碍。医联体通常由一所综合强的医院牵头,通过签署协议将一定区域内的三级医院与二级医院、社区医院等组成的一个医疗联合体,构建分级医疗、急慢分治、双向转诊的诊疗模式,促进分工协作,合理整合资源,实现信息共享[20]。

式中Input 与Output 分别表示FPA 模块的输入与输出,Inputi表示第i 层金字塔特征提取组件输入,从上至下其层数逐次增加,Convsize×size(I)表示对I 进行size×size 卷积核大小的卷积操作(如Conv1×1(Input)表示对Input 进行1×1 卷积核大小的卷积操作),size 表示卷积核的长或宽尺度大小,本文设置其长宽尺度相等,Up(I) 表示对I 进行长宽步长分别为2 的上采样操作以恢复特征图分辨率大小,Down(I) 表示对I 进行长宽步长分别为2 的下采样操作以降低特征图分辨率大小,fpa(i)表示第i 层金字塔特征提取组件与对应注意力特征融合组件的融合输出。为探究最适用于群养生猪多目标检测FPA 模块,分别构建1~4 层FPA 结构,并命名为FPA-1、FPA-2、FPA-3和FPA-4,其区别仅在于FPA 模块中金字塔特征提取组件与注意力特征融合组件内层数数量N 不同,N 取值为1~4,取1 表示FPA 中金字塔特征提取组件与注意力特征融合组件仅包含图3 中的最上面一层,N 取2~4 时以此类推,k(i)表示第i 层注意力特征融合组件卷积操作的卷积核大小,其值与当前所处层数相关。FPA 模块中不同金字塔分支将特征映射为不同子区域,不同尺度特征图具有差异化的感受野范围,通过聚合基于不同区域语义内容,挖掘全局上下文信息,有层次对先验结构进行多尺度融合,使得最终输出特征图融合全局先验信息以达到强化特征提取目的。
3 试验参数及模型结果评价指标
3.1 试验参数
试验运行平台为16GB Tesla V100 GPU,系统为Ubuntu16.04,采用keras 框架进行模型代码编写。将数据集划分为训练集、验证集和测试集3 部分,其中训练集大小为2 872,验证集与测试集大小均为615,采用批训练方式对YOLOV3 和Tiny-YOLO 模型在训练集与验证集上进行试验,一个批次训练32 张图片,遍历全部训练集数据称为1 轮迭代,试验中设置迭代轮数为200,模型均采用与Redmon 等[22]一致的loss 损失函数,采用自适应矩阵估计算法(Adaptive moment estimation,Adam)进行模型最优参数值选取。为使模型能够检测出不同大小的生猪个体,引入锚框(Anchor box)[17]思想,anchor 给出目标宽高的预设初始值,其常用于对目标个体大小进行粗判以避免模型在训练过程中盲目进行目标位置与目标尺度学习,可通过K-means 等算法在训练开始前获得,在训练过程中可通过降低真实宽高与初始宽高的相对偏移量的回归任务操作以对目标宽高大小预测更为精确。YOLOV3 系列模型采用K-means 算法共生成9 个锚框,其大小分别为(34,52)、(53,63)、(59,90)、(67,40)、(84,155)、(92,62)、(96,107)、(137,84)和(167,122),其中坐标(X,Y)分别表示锚框的宽和高,前3 个锚点框用于检测较小生猪个体,中间3 个锚点框用于检测中等大小生猪个体,后3 个锚点框适用于检测较大的生猪个体。Tiny-YOLO 模型共生成2 种不同大小的潜在锚框,每种包含3 个锚框,最终获得6 个锚框信息值,其大小分别为(35,54)、(56,82)、(65,44)、(85,136)、(96,63)和(145,106),其中前3 个锚点适用于检测较小生猪个体,后3 个适用于检测较大生猪个体。计算mAP 指标时,采用与PASCAL VOC2012 一致的指标定义方式[41],设置检测框与手动标注框的IOU 阈值超过某一数值且类别预测置信度score超过某一数值的情况下为检测正确[42],为研究不同IOU与score 数值对模型预测结果影响,分别固定score 阈值为0.5,分析IOU 阈值选取0.2、0.35、0.5、0.65 和0.8模型预测指标结果,固定IOU 阈值为0.5,分析score 阈值选取0.5、0.6、0.7、0.8 和0.9 的预测结果。
3.2 模型结果评价指标
采用精确率Precision、召回率Recall、F1 值以及平均检测精度mAP(mean Average Precision)作为评价指标,检测精度表示Precision-Recall 曲线下方面积,mAP指模型对生猪目标所有类别的检测精度平均值,实时性采用每秒传输帧数(Frames Per Second,FPS)作为评价指标,其值越大,模型实时性越佳,Precision、Recall、F1 及mAP 定义如式(5)~式(8)所示。

式中TP(True Positive)表示模型预测为生猪目标框且实际也为生猪目标的检测框数量,FP(False Postive)表示模型预测为生猪目标框但实际并不为生猪目标的检测框数量,FN(False Negative)表示预测为背景但实际为生猪个体框的样本数量,式(8)中r 表示积分变量用于求解0~1 之间Precision·Recall 的乘积积分值。
4 结果与分析
4.1 不同层级FPA 模块YOLOV3 与Tiny-YOLO 分析
4.1.1 模型检测精度与实时性
表1 为YOLOV3 与Tiny-YOLO 模型加入不同深度特征金字塔注意力模块FPA 后在测试集上的Precision、Recall、F1、mAP、FPS 预测指标情况,不同模型采用相同的训练超参数,测试时设置score 阈值为0.5,IOU 阈值为0.35,预测分数大于0.5 且交并比大于0.35 时视为预测正确,每种模型均设计不加入FPA 模块与加入深度为1~4 的FPA 模块5 种对比试验,以验证不同深度特征金字塔注意力模块的有效性,寻找最适于群养生猪多目标检测的模型。
试验结果表明:1)Tiny-YOLO 模型加入FPA 前后Precision、Recall、F1 以及mAP 值均优于加入相同模块的YOLOV3 模型。加入FPA-3 的Tiny-YOLO 模型mAP较加入相同模块的 YOLOV3 提高 8.4 个百分点,Precision、Recall 与F1 值分别提高了1.04、7.93 和5.09个百分点。效果最好的FPA-2-YOLOV3 模型各项指标仍低于未加入任何FPA 模块的Tiny-YOLO 模型,后者比前者的Recall、F1 和mAP 分别提高1.9、0.21 和1.5个百分点,与YOLOV3 模型相比,基于Tiny-YOLO 的模型性能较佳,因而后续选取Tiny-YOLO 模型进行深入研究。

表1 超参数score 和IOU 为0.5 和0.35 时的模型预测结果 Table 1 Prediction results of the models with hyperparameter score and IOU values of 0.5 and 0.35
3)不同深度FPA 模块对Tiny-YOLO 模型检测性能提升幅度有所差异。加入FPA-3 模块的Recall、F1 和mAP较Tiny-YOLO 模型提高了3.75、2.59 和4.11 个百分点,与加入FPA-4 模块的模型相比,Precision、Recall、F1 及mAP 分别提升0.73、2.76、1.88 和3 个百分点。此外,模型性能并未随着所加FPA 模块深度的增加而有所提升,可见,并非加入越深的FPA 模型就越能提取更佳的有效特征,这可能是因为一定深度的FPA 模块已经完全能够学习到较全的生猪个体信息,引入过多的注意力信息反而弱化了注意力区域的激活值。在Tiny-YOLO 模型组试验中,FPA-3-Tiny-YOLO 的Precision 虽未取得最优,但仍可达到97.58%,该模型更适用于群养状态下生猪个体目标信息的有效提取。
4)在预测实时性方面,Tiny-YOLO 和YOLOV3 模型的FPS 值为50.9、29.6,Tiny-YOLO 较YOLOV3 的FPS 提高了21.3,FPA 模块会使模型运行时长增加,各模型FPS 都有所减小,其中,Tiny-YOLO 模型增加FPA-1后FPS 减少0.2,减少幅度为0.39%,而增加FPA-4 后模块FPS 值减少7.1,降少幅度为13.95%;YOLOV3 模型增加FPA-1 后FPS 减少1.4,减少幅度为4.73%,而增加FPA-4 后模块FPS 值减少5.4,减少幅度为18.24%,减少幅度最大, 综合权衡预测精度与 FPS 值,FPA-3-Tiny-YOLO 可获得最优检测性能同时获得较优FPS 值。当FPS 大于25 时模型对图像的处理可满足实时性要求,因而加入FPA 模块的Tiny-YOLO 模型可用于生猪目标检测的实际应用中。
4.1.2 模型指标值变化原因
为探究试验模型预测差异性的深层原因,由式(5)~式(8)可知,预测TP 与FP 值与模型性能直接相关,因而对加入特征金字塔注意力模块前后模型在测试集上的TP、FP 数值进行分析。TP 与FP 值的获取需对模型预测结果类别框实施2 步过滤操作,1)以一定数值置信度去除部分低于该值的预测框(试验设置置信度值为0.5),2)对已通过置信度筛选的预测框依照置信度值进行降序排列,计算最高置信度值预测框与真实框间的IOU 值,若IOU 超过设定阈值(设置IOU 阈值为0.35),则将当前预测框加入TP中,同时将对应生猪个体标注为已检测,后续对该生猪的预测框将全部列入FP 中,最终统计结果如表2 所示。

表2 试验模型对生猪目标预测的TP 与FP 值 Table 2 TP and FP values predicted by experimental model for live pig targets
试验结果表明:TP 值越高,模型越优,由表2 可见,Tiny-YOLO 模型均优于YOLOV3 模型,未加入FPA的Tiny-YOLO 模型TP 值比YOLOV3 多173 个,预测正确类别框个数提升11%,各试验模型加入FPA 模块的TP 值均高于未加FPA 模块模型,在Tiny-YOLO 模型试验组中,TP 值大小排序为 FPA-3>FPA-1> FPA-2>FPA-4,可见并非随着FPA 深度增加,对应类别框预测准确率更高;而对于FP 值,该值越小,对应模型越佳,相同试验条件下,YOLOV3 模型试验的TP 值较Tiny-YOLO 模型小,Tiny-YOLO 模型的FP 值相较于YOLOV3 模型有一定程度增加,但与TP 指标值增加幅度相比,FP 增加幅度远低于TP 增加幅度,因而在整体预测性能上更偏向于 TP,以加入 FPA-1 为例,FPA-1-Tiny-YOLO 模型比FPA-1-YOLOV3 模型的TP值高119 个,FP 值高2 个,由FP 增加带来的性能损失仅占TP增加带来的性能提升的1.68%,可见Tiny-YOLO模型优于YOLOV3 模型主要是由TP 值提升所引起。对同一组模型,除FPA-3-YOLOV3 外,引入FPA 模块FP值均有减少,与TP 值增加相结合,使FPA 模块进一步提升模型性能。
4.2 不同超参数条件下模型检测精度
4.2.1 不同IOU 阈值对检测精度影响
为探讨IOU 阈值对模型各指标的影响,选取score阈值为0.5(考虑到数据中生猪部位与背景是一个二分类问题,因而当预测值大于等于0.5 时可认为预测类别正确),以相同试验条件在测试集上对IOU 阈值分别选取0.2、0.35、0.5、0.65 和0.8 并计算Precision、Recall、F1和mAP 指标,试验结果如表3 所示。
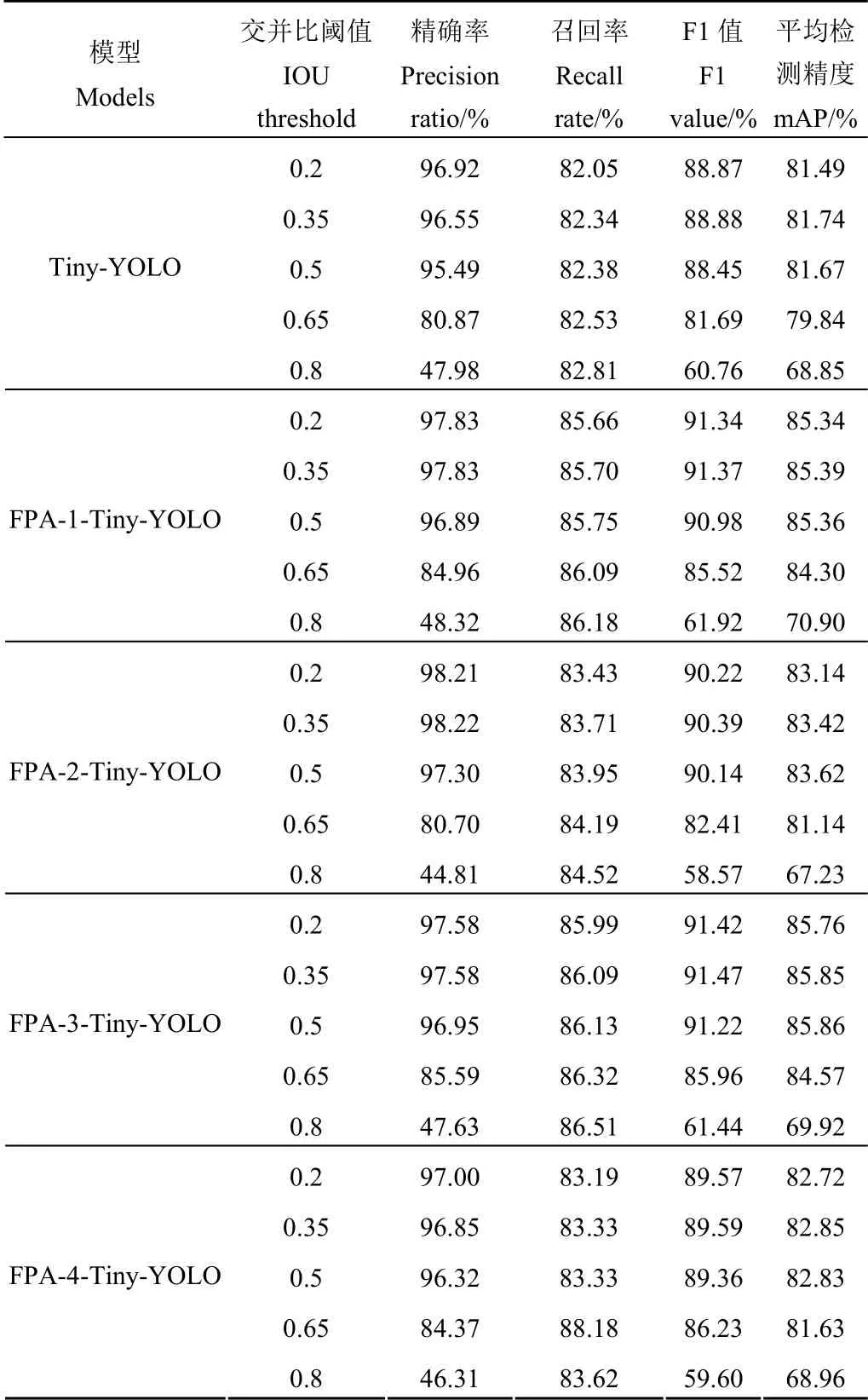
表3 IOU 取值对加入FPA 模块的Tiny-YOLO 模型预测性能影响 Table 3 Effects of IOU values on prediction performance of Tiny-YOLO model with FPA module
试验结果表明:1)随着IOU 阈值的增大,模型各指标变化差异较大。F1 与mAP 指标先增加后减少,且一般在IOU 值为0.35 时能够达到最优,FPA-2-Tiny-YOLO 和FPA-3-Tiny-YOLO 模型的mAP 指标虽未取得最佳,但其值仍具有很强竞争力;Recall 值则逐渐增大,这是由于各指标评价的侧重点不同造成的,由公式(6)可知,Recall是由TP 与TP+FN 相除所得,实际计算中TP+FN 的值始终为2 106(即测试集上所有生猪数量),随着IOU 增大TP 值逐渐增大,但这种增大现象在计算Precision 的时候受FP 值的增加而减弱,由公式(5)可知,Precision 是由TP 与TP+FP 的商所得,随着IOU 增大,FP 值也出现相应增大,因而Precision 值出现一定程度降低,F1 指标变化规律与Precision 一致,表明随着IOU 阈值的变化,FP 值的波动幅度要远远高于TP 值。
2)加入不同FPA 模块后,各模型在IOU 阈值相同时表现出不同性能。在加入FPA-3 后,各模型在不同IOU 阈值条件下均表现出较强性能,IOU 值选取0.5时FPA-3-Tiny-YOLO 比Tiny-YOLO 模型的F1 和mAP指标提升2.77 和4.19 个百分点,IOU 阈值相同时,模型指标并未随着添加不同深度的FPA 模块出现递增或者递减现象,说明FPA 模块的深度对试验效果并未有规律性影响。综上,FPA-3 模块更适用于生猪多目标检测领域。
4.2.2 不同置信度分数阈值对检测精度影响
为探讨置信度分数阈值对Tiny-YOLO 试验组模型各指标的影响,选取IOU 阈值为0.35(其在4.2.1 中试验效果最优),以相同试验条件在测试集上对score 阈值分别选取0.5、0.6、0.7、0.8 和0.9 并计算Precision、Recall、F1 和mAP 指标,试验结果如表4 所示。
试验结果表明:不同score 值对模型各指标值具有一定影响。各模型Recall、F1 和mAP 指标随着score 增大逐渐减小,以FPA-3-Tiny-YOLO 为例,score 为0.5 时各模型上述三种指标较score 为0.6 时高出3.66、1.82 和3.58个百分点,较score 为0.9 时更是高出19.38、11.53 和19.16个百分点,这是因为随着score 值的增加,相应预测为生猪个体类别框的数目急剧减少,即TP 数量减少。由公式(6)可知,分母TP+FN 值为常量,分子在减少的情况下对应Recall 指标会减少。
Precision 值则随着score 值增大逐渐增大,由公式(5)可知,Precison 值由TP 和FP 共同决定,score 增大会使TP 值减小,但相应的FP 值也会减小,而FP减小的幅度要快于TP,因而Precison 会逐渐增大,即在实际中,对生猪目标框预测正确的个数以及将某个非生猪部分预测为生猪个体框的错误个数均出现下降情况,且后者下降速度更快,这会导致某些生猪个体被漏检。
4.3 不同场景下模型检测精度与可视化
为进一步研究模型在不同场景下的鲁棒性,将测试集划分为无黏连无遮挡、无黏连有遮挡、有黏连无遮挡和有黏连有遮挡4 种情形,上述场景的生猪框个数分别为449、872、458 和327 个,在Tiny-YOLO 模型中加入不同特征金字塔注意力模块,设置IOU 阈值为0.35,score阈值为0.5,各模型指标试验结果如表5 所示。
由表5 可知,加入FPA 模块对不同场景下的多目标生猪个体检测具有积极作用。在有黏连有遮挡场景下,FPA-3-Tiny-YOLO 模型的Recall、F1 和mAP 指标较Tiny-YOLO 提升6.73、4.34 和7.33 个百分点,其余模型在部分指标上提升幅度不明显,但其性能一般优于Tiny-YOLO 模型。加入同一模块的模型在不同场景下指标值相差较大,无黏连无遮挡场景的指标优于其余3 种场景,可见生猪所处场景对模型具有很大挑战性,场景特征较为简单时可获得较好的检测结果,而场景特征较为复杂则会使模型性能有一定程度降低,且对应不同的场景,加入注意力模块后的模型总体优于未加入任何注意力信息的Tiny-YOLO 模型(如:FPA-1-Tiny-YOLO、FPA-2-Tiny-YOLO 与FPA-3-Tiny-YOLO三种模型在无黏连无遮挡、无黏连有遮挡与有黏连无遮挡三种场景下其各个预测指标值均优于Tiny-YOLO 模型),说明注意力模块对于生猪场景变化具有很强的鲁棒性;加入不同深度FPA 模块的模型在不同场景下性能表现不同,FPA-1与FPA-3 分别在有黏连无遮挡与无黏连无遮挡场景下能取得最高mAP 指标值,可见,并非FPA 模块越深模型性能越好,实际使用中需要综合考量选取合适深度以获得最适用于对应场景模型,不同场景下的部分检测结果见图4。

表5 Tiny-YOLO 模型在不同场景下的检测结果 Table 5 Test results of Tiny-YOLO models in different scenes

图4 加入不同深度FPA 模块的Tiny-YOLO 模型在多种场景下的预测效果 Fig.4 Prediction effects of Tiny-YOLO model with different depth FPA modules in multiple scenes
由图4 可见,在无黏连无遮挡和无黏连有遮挡场景下,加入FPA 模块的模型在有猪栏等杂物遮挡时,仍可提取较完整的生猪个体边框,生猪预测置信度分数更高,在有黏连无遮挡场景下,FPA-1-Tiny-YOLO 仍能有效检测到远离镜头且有遮挡的生猪个体,预测结果较完整,而其他模型均有不同程度的错检或者漏检,在有黏连有遮挡场景下,不同模型预测结果差异较大,其中FPA-3-Tiny-YOLO 对远处黏连生猪个体也能实现精准分离,且对生猪个体预测更为精细,提取效果更佳。
5 结 论
本文在Tiny-YOLO 模型中引入特征金字塔注意力信息,对Tiny-YOLO 模型进行了改进,构建包含不同深度FPA 模块的多种FPA-Tiny-YOLO 模型,研究不同超参数对模型性能影响,分析各模型对不同群养场景下生猪检测的性能,主要结论如下:
1)加入多种特征金字塔注意力信息,可使Tiny-YOLO 和YOLOV3 模型精度有不同幅度提升。与YOLOV3 模型相比,Tiny-YOLO 模型具有更高检测精度,检测实时性优于加入相同模块的YOLOV3 模型。
2)不同深度FPA 模块对Tiny-YOLO 模型指标提升幅度有所差异。在超参数固定情况下,加入FPA-3 注意力模块的Tiny-YOLO 模型效果最佳,表明并非加入的FPA 模块越深模型提取特征能力越强,应用中需根据不同场景选择添加不同深度的FPA 模块。
3)交并比IOU 和置信度score 的不同阈值对加入不同FPA 模块的Tiny-YOLO 模型有不同影响。在选定IOU值的情况下,召回率、F1 值和平均检测精度三个指标随着score 阈值的增大而减小,在选定score 值的情况下,F1 和mAP 指标随着IOU 阈值的增大先增加后减少,试验表明在IOU 阈值为0.35,score 阈值为0.5 时,加入多种层级的FPA模块的Tiny-YOLO模型各个指标取得最佳值。
4)加入FPA 模块后对不同场景下的多目标生猪个体检测均有积极作用,加入FPA-3 模块的mAP 指标值最佳,表明添加特征金字塔注意力模块的模型在复杂环境中仍能剔除冗余信息实现高效检测,对群养生猪目标所处环境具有鲁棒性。
猜你喜欢
环球时报(2022-09-19)2022-09-19
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
北京航空航天大学学报(2021年9期)2021-11-02
临床骨科杂志(2020年1期)2020-12-12
考试与评价·七年级版(2020年4期)2020-10-23
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小学教学研究·新小读者(2017年9期)2017-10-25
