
基于层次注意力模型的软件众包定价方法研究
2020-07-24 02:11常得琳
软件导刊 2020年6期
常得琳
摘要:为了解决软件众包任务定价决策阶段可用信息有限的问题,提出一种基于层次注意力模型的软件众包定价方法。利用层次注意力模型提取软件众包任务需求文本语义特征,可以在需求文本中自动发掘与任务价格相关的有效信息。此外,将文本划分成词和句两个层次对全文进行有重点的表示,可以更好地表示文本特征。实验结果表明,该方法能够有效克服生产环境的局限性,降低特征提取难度,并在一定程度上提高了预测性能。
关键词:注意力机制;软件众包;定价方法;自然语言处理
DOI:10.11907/rjdk.201188 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)006-0090-05
0 引言
近年来,随着互联网的发展,软件开发模式也发生了变革,其中基于众包的软件开发模式正逐渐兴起。众包是一种基于互联网的新兴商业模式,目前被广泛采用的众包定义由HoweC~在2006提出。众包定义为公司或机构将之前由员工完成的任务,以公开征集的形式外包给非特定大众完成的行为。基于众包的软件开发通过互联网召集全球在线开发者完成覆盖软件生命周期的多种任务,如架构设计、组件开发、软件测试及缺陷修复等,许多知名公司和机构均开始转向基于众包的软件开发模式。该开发模式可以显著提高软件生产效率和质量,同时降低开发成本。因此,基于众包的软件开发模式已成为当前一种十分流行的开发模式。但该模式目前还具有一定缺陷,在实践中仍面临着一系列挑战,例如存在软件众包任务资源配置、激励机制与质量保证机制等问题。
在资源配置方面,不合理的任务酬金可能导致资金利用低效或者较低的任务参与度,进而影响整个项目预算或产品交付。传统软件成本预测以及众包定价方法通过手工提取特征因子构建定价模型,不仅需要耗费大量时间处理复杂的数据集,而且效果并不显著。现有定价方法需要依赖较多的可用信息,而在实际生产环境中,在定价决策阶段,有些信息是无法获取的。本文从众包任务定价决策阶段可用的需求文本人手,提出一种基于层次注意力模型的软件众包定价方法。该方法可以降低特征提取难度,解决可用信息有限的问题,并在一定程度上提高预测性能。
1相关工作
(1)软件成本预测。传统软件成本预测主要研究目标是软件开发总成本,其中主要包括基于经验的方法、基于算法模型的方法以及基于机器学习的方法等。基于经验的方法一般由专家根据历史数据及当前市场形势主观决定开发成本;基于算法模型的方法以COCOMO系列模型为代表;基于机器学习的方法利用大量历史数据,结合机器学习技术自动发掘特征与价格之间的关系。
(2)一般软件众包任务。对于众包任务的发包者,合理的酬金可以提高资源配置效率以及众包任务完成质量。目前已有学者进行了相关研究,如Hu提出一种任务定价机制,该机制将众包任务定价问题转化为多臂强盗问题,并利用微型众包任务的单一特性设计优化算法,结果表明,该机制具有较强的实用性;Wang从众包从业者专业技术水平方面对众包平台定价策略展开研究,并提出根据从业者技术水平调整任务酬金。但此类研究一般只适用于微小型众包任务。
(3)软件众包任务定价。在针对软件众包任务定价的研究中,毛可的研究成果最为突出,其利用历史数据集提取16个与软件众包任务相关的定价因子,并利用不同机器学习方法构建定价模型。实验结果表明,该方法具有较好的预测性能,但在其所用数据集中,部分数据在软件定价决策阶段难以获得;Turki提出基于上下文的软件众包定价方法,从实际生产环境的可用信息出发,但由于数据集较小,预测精度不高。
(4)自然语言处理。本文方法将软件众包任务需求文本作为输入,而如何对文本进行合理表示,一直是自然语言处理领域的研究重点。在词的层面,目前较为流行的是Word2vec方法,该方法利用大量语料库训练模型,得到的词向量能够很好地表示单词语义。在文档层面,主题模型是目前的常用方法。主题模型是指利用基于词频的统计方法从大量文本中发现文本潜在主题特征,有研究者也将主题模型应用于软件工程领域。近年来随着计算机硬件的发展,计算机算力不断提高,基于深度学习的方法取得了较好效果。其中在自然语言处理领域,注意力机制得到了广泛应用。不同领域的研究者针对不同问题提出适用于各种场景的基于注意力的神经网络结构。注意力机制可以模拟人在阅读时的行为,对文章中每个词赋予不同程度的注意力,从而在提炼文本信息时可以抓住更多关键、有效的信息。
2 层次注意力模型
本文从软件众包需求文本出发构建定价模型,需要用到自然语言处理领域的常用技术。注意力机制由于具有很好的分类能力,被广泛应用于自然语言处理领域的情感分类、文本分类等问题。本文借鉴Yang提出的方法,使用软件众包任务需求文档作为输入,构造适用于软件众包定价的模型。
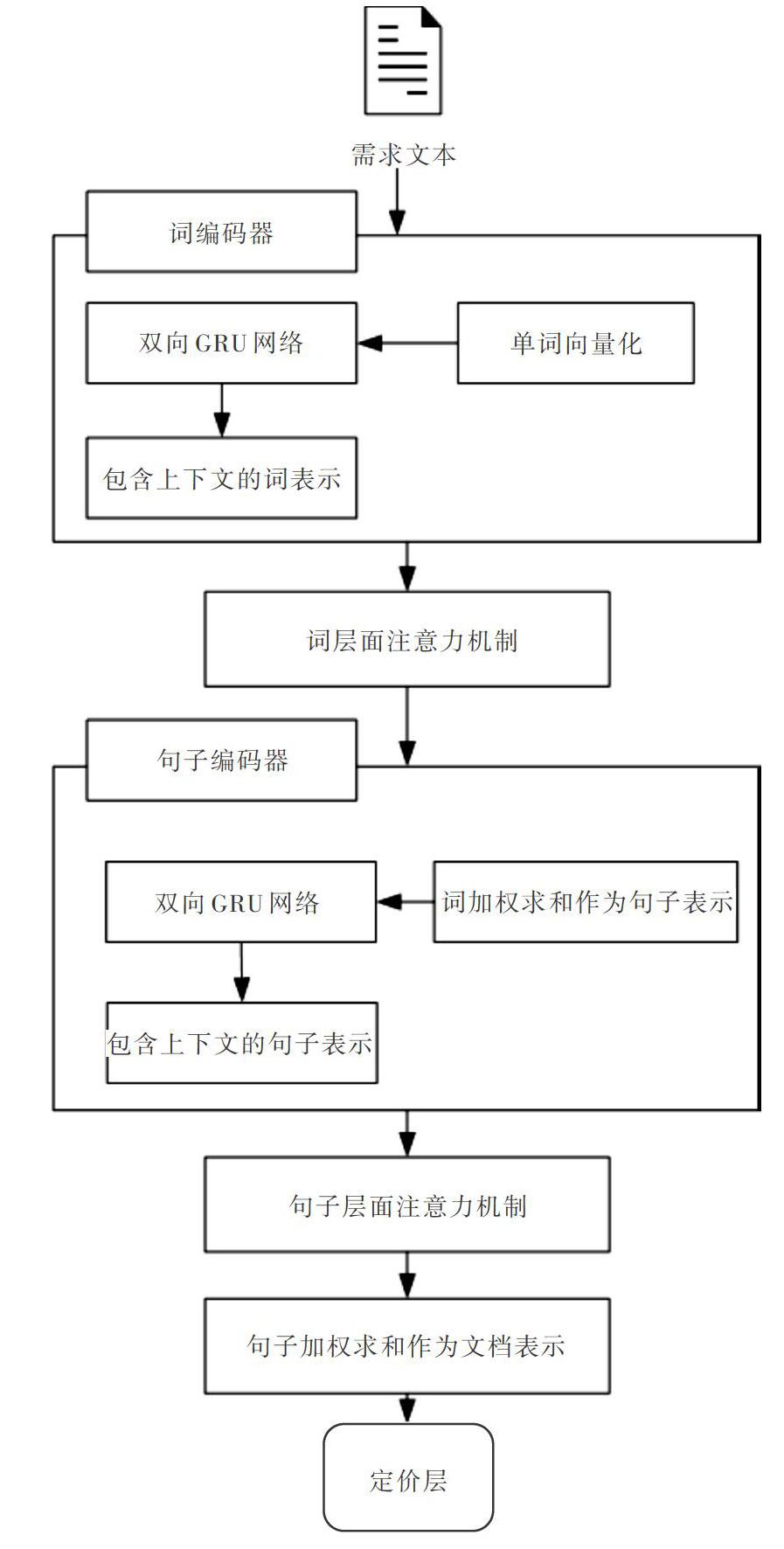
本文将需求文本分为两个层次加以考虑:第一层次是词一句层次,在阅读需求文本时,同样的词出现在不同句子中,其重要程度是不同的;第二层次是句一文层次,相同句子出现在不同的上下文环境中,其对全文的重要程度也是不同的。本文设计基于层次注意力模型的软件众包定价方法主要包括5个方面:词编码器、词注意力机制、句编码器、句注意力机制、定价层。模型概要如图l所示。首先利用Word2vec将需求文本单词序列向量化,然后利用GRU網络得到包含上下文信息的词表示;接着引入词层面注意力机制,获得单词的权重矩阵;以加权求和的方式表示句子,相应地使用GRU网络得到包含上下文信息的句子表示,并引入句子层面的注意力机制,获得句子层面的权重矩阵;以加权求和的方式表示文本,最后通过定价层获得价格预测值。
2.1 词编码器
本文的原始输人是软件众包任务需求文本,在输入需求文本后,首先得到需求文本的词序列,然后利用Word2vec方法将文本词序列转化为词向量,如式(1)所示。
xit=Wewit,t∈[1,T] (1)
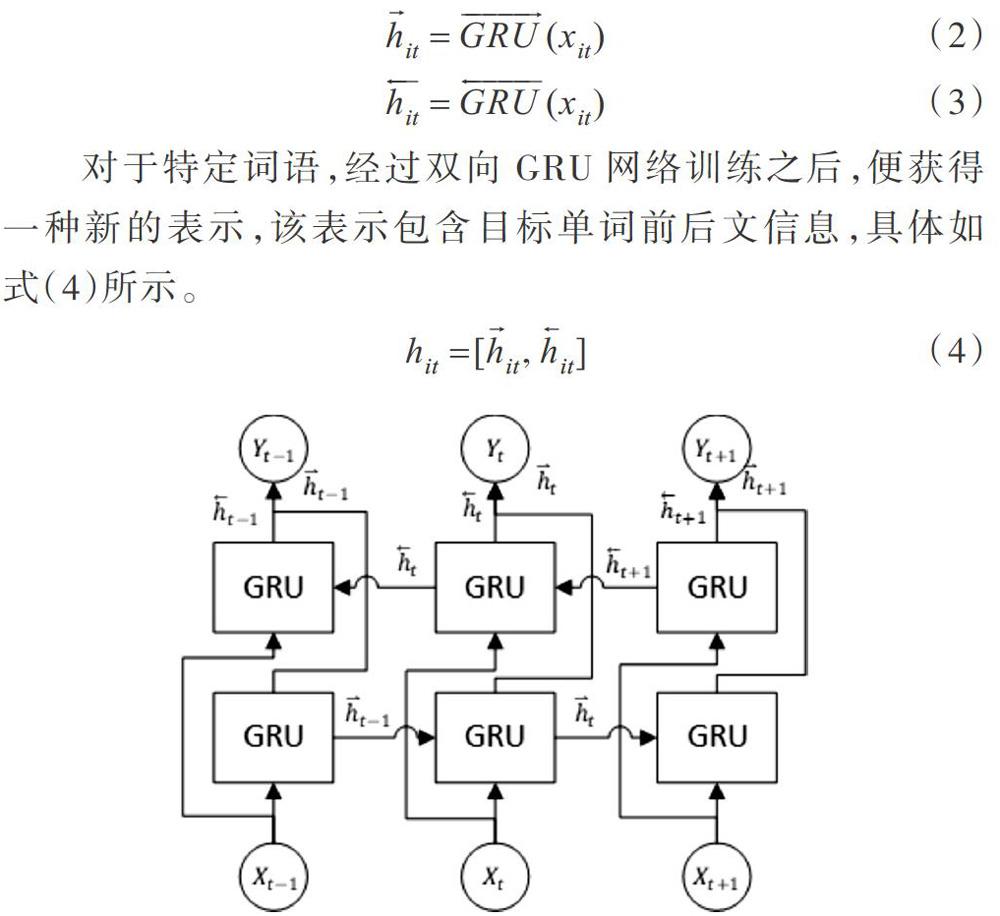
We是权重矩阵,该矩阵由Word2vec提供。接下来将词向量输入如图2所示的双向GRU网络,可以将每个单词前文与后文信息结合起来获得隐藏层输出,计算公式如式(2)、式(3)所示。
对于特定词语,经过双向GRU网络训练之后,便获得一种新的表示,该表示包含目标单词前后文信息,具体如式(4)所示。
2.2 词注意力机制
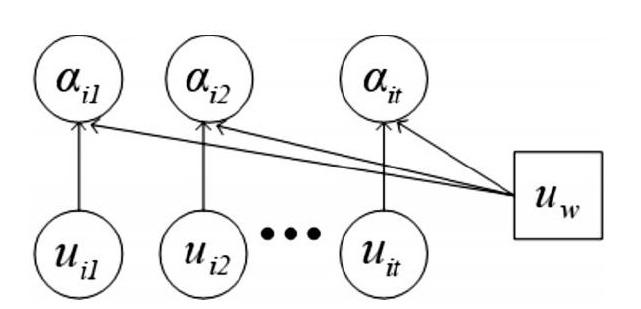
并非所有单词都能对句子作出同样贡献,而注意力机制恰好可以模仿人的阅读行为。在此引入注意力机制可以把句子中对于理解句子含义最重要、贡献最大的词找出来。注意力机制结构如图3所示。
首先输入一个只有一层隐藏层的MLP感知机,得到单词的隐含表示,如式(5)所示。
uit=tanh(Wwhit+bw) (5)
其中,tanh为网络激活函数。为了衡量每个单词的重要性,引入一个随机初始化的前后文向量uw,计算每个单词与该向量相似程度,从而获得单词的权重矩阵,如式(6)所示。
2.3 句编码器
得到句子的向量表示之后,同样将句子向量输入与前文结构一致的双向GRU网络,从而将每句话的前后文信息结合起来获得隐藏层输出,计算方法如式(5)、式(6)所示。
对于特定句子,经过双向GRU网络后获得了一种新的表示,该表示包含句子前后文信息,如式(10)所示。
2.4 句注意力机制
本文研究对象为软件众包任务定价方法,为了奖励提供重要信息的句子,再次引入句子级别的注意力机制,其结构与前文一致。首先输入一个只有一层隐藏层的MLP感知机得到单词的隐含表示,如式(11)所示。
ui=tanh(Wshi+bs) (11)
为衡量每句话的重要性,此处引入一个随机初始化的前后文向量,计算每个句子与该向量的相似程度,从而获得句子的权重矩阵,如式(12)所示。
在获得注意力权重矩阵后,对文档中每句话进行加权求和便获得全文的表示,如式(13)所示。
2.5定价层
在得到文档向量表示之后,将其输入只有一层隐藏层的神经网络,网络结构如图4所示。使用人工神经网络,可以利用大量历史数据集获得较为有效的定价模型。在训练过程中,使用评价绝对误差作为损失函数,并采用随机梯度下降法训练模型。模型训练完成后便可利用训练好的模型在测试集上完成定价任务实验。
3 实验与结果
3.1 实验环境与实验参数
本文使用的CUDA版本为8.0,实验采用的机器配置为:Intel Core i5-4430,双核四线程,主频3.0GHz,内存32GB,使用的显卡规格为双路的NVIDIA GTXl080Ti。在实现本文模型时,借助深度学习框架TensorFlow和keras对双向GRU网络、注意力机制以及定价层网络加以实现。
本文对该方法进行多次实验验证,并对参数进行针对性优化。对于Word2vec,本文使用的词嵌人维度为100维,窗口大小设置为10,使用skip-gram模型进行训练;对于双向GRU网络,前向和后向GRU单元隐藏层神经元个数为50,整个双向GRU网络隐藏层输出维度为100维;对于注意力层,本文也将其维度设置为100维;对于定价层,隐藏层维度为128维,损失函数为平均绝对误差,输出层使用ReLU函数进行激活。整个网络的batch size为32,学习率为0.001,共进行20轮训练。
3.2 实验数据集
本文利用爬虫程序爬取Topcoder众包平台上2013年1月-2018年12月间已完成的软件任务交易信息,并以此构建本文数据集。该数据集共包含38265个真实的软件众包任务交易信息,共涵盖漏洞修复、网页设计、数据库开发、软件测试、组件设计以及UI设计等60余类任务类型。本文抓取的数据信息包括:任务ID编号、任务类型、任务发布时间、任务最后提交日期、任务名称、任务赏金、任务注册人数、任务需求文档以及任务完成状态等。然而,其中有部分信息是定价决策阶段不可获取的,而本研究主要是为了解决软件众包任务早期阶段的定价问题。因此,本文仅利用任务早期便可获得的需求文档,利用不同方法尝试发现文档与价格之间的潜在联系。图5为该数据集中任务价格分布。
3.3 实验结果
本实验采用10折交叉验证对模型进行评估,同时使用平均相对误差(MMRE)和Pred(30)作为误差评估标准。Pred(30)描述的是使用当前模型在测试数据集上对价格进行预测时,平均绝对误差小于等于0.3的项目占测试数据的百分比。其计算结果越大,表示预测值越准确。本文将随机猜测法(Random Guess)及COCOMO方法作为基准方法,并与毛可和Turki提出的方法进行对比,结果如图6所示。
从图中可以看出,本文方法相较于基准方法具有明显优势,并且相较于毛可和Turki的方法,具有更大的Pred(30)以及较小的平均相对误差。与毛可的方法相比,在平均相对误差方面,预测精度提高了约8%,在Pred(30)方面,预测精度提高了约5%;与Turki的方法相比,精度提高则更加明显。需要注意的是,毛可研究中已取得相对较高的预测精度,但其研究使用了部分定价决策阶段不可获得的信息,因此在应用中具有一定局限性。本文方法使用定价决策阶段可获得的软件需求文本作为输人,不仅取得了较高的预测精度,而且具有较高的实际应用价值,能够有效地为决策者提供定价建议。
4 结语
本文提出一种基于层次注意力模型的软件众包定价方法。该方法采用软件众包早期决策阶段获得的需求文本作为输人,首先利用Word2vec将需求文本中的单词序列向量化,接着利用层次化的注意力模型获得文档的合理表示,该表示包含较为关键的词句信息,从而提高了定价方法预测精度。现有方法由于受到生产环境的局限,应用可行性较低,而本文方法从定价决策阶段可用的需求描述文本人手,提出相应定价方法,解決了定价决策阶段可用信息较少的问题。本文方法更适用于实际生产环境,能够为软件众包任务决策者在决策阶段提供合理的定价建议。但本文在研究过程中也存在一定不足,为了能够获得更好的结果,还需对以下问题作进一步研究与分析。
(1)本文数据来自Topcoder平台,未来将考虑收集更多软件众包平台数据进行实验。
(2)需求描述文本中包含许多图片性描述,该部分信息可能会对任务价格产生一定影响,未来也应将这部分内容考虑在内展开研究。
(3)随着深度学习不断取得重大突破,在未来工作中可以尝试新的技术与方法,以期获得更好的预测结果。
猜你喜欢
现代电子技术(2018年8期)2018-04-13
智能计算机与应用(2017年5期)2017-11-08
计算机应用(2016年12期)2017-01-13
求知导刊(2016年10期)2016-05-01
