
基于循环神经网络的花儿信息模型建模方法
2020-08-13 07:17赵吉山王青海
软件 2020年6期
赵吉山 王青海
摘 要: “花儿”是一种流传在青海、甘肃两省、宁夏回族自治区以及新疆个别地区的山歌,被誉为大西北之魂,是国家级人类非物质文化遗产,2009年9月被联合国列为人类非物质文化遗产。随着网络技术及机器学习的迅猛发展,对“花儿”信息的网络传播和深度挖掘至关重要。对此,笔者提出利用机器学习自然语言处理(Machine Learning-Natural Language Processing)来进行花儿唱词信息挖掘。通过构建循环神经网络(Recurrent Neural Network,RNN)青海花儿模型,展开对花儿唱词的数据挖掘,并且实现Python内置语言模块与动态网页互联,能为花儿艺术研究者及民间花儿艺术爱好者提供有效且高质量的花儿信息。利用RNN进行花儿唱词挖掘是一个非常有意义的研究课题,对未来花儿艺术的发展和传承具有重大的作用。
关键词: 循环神经网络;青海花儿;信息挖掘;动态网页
中图分类号: TP389.1 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.06.004
本文著录格式:赵吉山,王青海. 基于循环神经网络的花儿信息模型建模方法[J]. 软件,2020,41(06):1923
【Abstract】: “Huaer” is a folk song spread in Qinghai、Gansu Province、Ningxia and some areas in Xinjiang. It is known as the soul of the Northwest and is a national intangible cultural heritage. Human intangible cultural heritage. With the rapid development of network technology and machine learning, it is very important for the network dissemination and deep mining of Huaer information. In this regard, the author proposes to use Machine Learning- Natural Language Processing to perform flower singing information mining. By constructing a Recurrent Neural Network (RNN) Qinghai Huaer model, the data mining of Huaer chanting is carried out, and the built-in language module of Python is interconnected with dynamic web pages, which can be a flower art researcher and folk flower art hobby Provide effective and high-quality Huaer information. The use of RNN for the mining of Huaer lyrics is a very significant research topic, and it will have a significant effect on the development and inheritance of Huaer art in the future.
【Key words】: Recurrent neural network; Qinghai huaer; Information mining; Dynamic webpage
0 引言
伴隨着计算机技术的不断发展,国外及国内的网民获取信息的速度更加迅速,人们日益增长的精神文化需求越来越高,青海花儿民间爱好者及花儿研究者急需获取有效、全面、及数据规模较大的花儿信息。目前世界文化正处在大发展时期,各种思想文化交流交融更加频繁,文化在综合国力竞争中的作用及地位更加凸显,作为中华民族传统文化中的一部分,青海花儿的发展与传播在当下也是不可或缺的。对此,笔者利用计算机技术的优势,分析本地区特色文化——青海花儿,通过研究青海花儿的发展状况得出:互联网上对于花儿信息的收录量很少,内容不完整、不全面、且收集困难。花儿作为本地区特有的艺术,其有很大的发展空间,并且在传承及发扬的过程中收到资源限制,因此,青海花儿信息的研究在当下更显必要性和紧迫性。
1 RNN与PHP概述
1.1 RNN
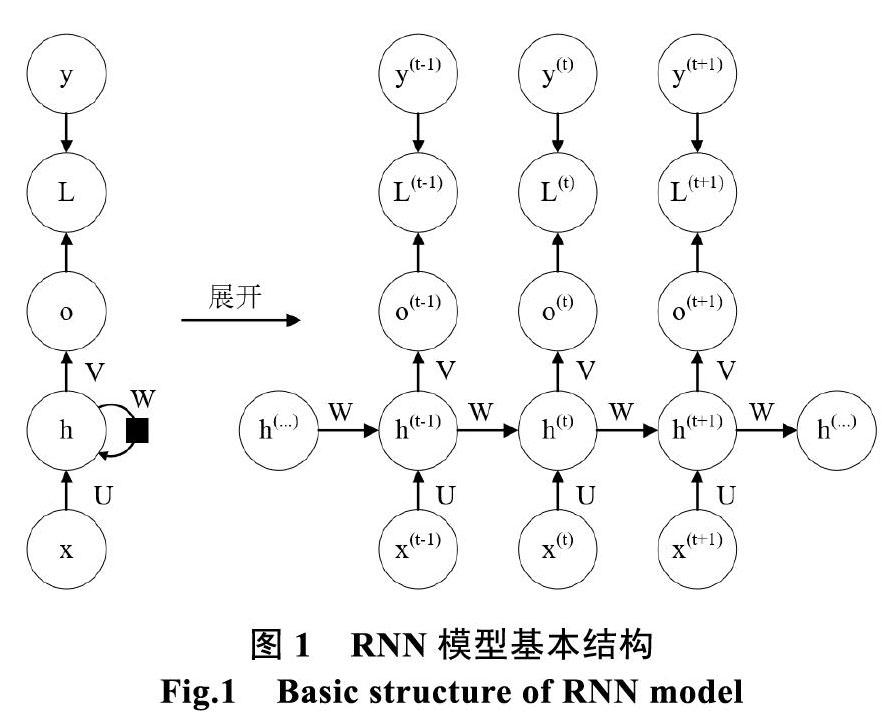
RNN是一类专门用于处理序列x(1)、x(2)、...x(t)的神经网络。RNN可以扩展到更长的序列,大多数的RNN也能处理可变长度的序列。它以不同的方式共享参数,输出的每一项是前一项的函数,输出的每一项对先前的输出应用相同的更新规则产生[1]。RNN可应用于跨越两个维度的空间数据,当某个应用涉及时间的数据,并且将整个序列数据提供给网络之前就能观察到整个序列时,RNN可具有关于时间向后的连接[2]。主流的循环神经网络模型的基本结构如图1所示。
图1.1左半部为没有按时间展开的RNN模型基本结构图(图中黑色方块表示单个时间步的延迟),右半部为按时间展开的图。在结构图中,对于每个时间步t,一般的作如下表示:
(1)x(t)表示在时间步t时训练样本的输入。而x(t–1)、x(t+1)分别表示在时间步t–1、t+1时训练样本的输入。
(2)h(t)表示在时间步t时隐藏层的激活函数。h(t)由x(t)、h(t–1)共同决定,一般二分问题采用sigmoid函数,K类别分类问题采用softmax函数。
(3)o(t)表示在时间步t时模型的输出。o(t)只由模型当前的隐藏状态h(t)决定。
(4)L(t)表示在时间步t时模型的损失函数,损失函数L(t)表示输出值o(t)与相应训练目标y(t)的长度[3]。
(5)y(t)代表在时间步t时训练样本序列的目标输出。输入层到隐藏层、隐藏层到输出层、隐藏层到隐藏层的连接分别由权重矩阵U、V、W参数化。
1.2 PHP
PHP:Hypertext Preprocessor(简称PHP)是一种通用编程语言,最初为动态网页开发而设计。语法吸收了C、Java和Perl语言的特性,语法简单利于学习,在互联网动态网页开发技术当中应用广泛,主要适用于网页开发领域。PHP独特的语法混合了C、Java、Perl以及PHP自创的语法。它可以比CGI或者Perl更快速地执行动态网页。用PHP做动态页面和其他的编程语言相比,PHP是将程序嵌入到HTML中去执行,执行效率比完全生成HTML标记的CGI要高许多[4]。PHP还可以执行编译后代码,编译可以达到加密和优化代码运行,使代码运行更快。
2 python内置模块与动态网页互联
Python是一门解释型的编程语言,因此它具有解释型语言的运行机制[5]。迄今为止Python由于其可扩展性、跨平台等特性相较于其他语言拥有诸多的优势,python的可扩展性体现为它的模块,其强大的类库为机器学习等计算机前沿学科提供了有效的幫助。本次实验涉及的Python模块包括应用于文本中自动提取语义主题的Gensim模块和Python标准库中的sys、os、time、json、process、和网络模块socket等等。
Gensim是一款开源的第三方Python模块,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达[6]。它支持包括TF-IDF、LSA、LDA、和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。在本实验中我们采用Word2vec,Word2Vec是Google公司推出的用于获取词向量的工具,该工具内部算法通过深度学习实现词到向量的转化。Word2vec模型输出的词向量可以被用来做很多自然语言处理的相关工作,比如聚类、找同义词、词性分析,预测等[7]。
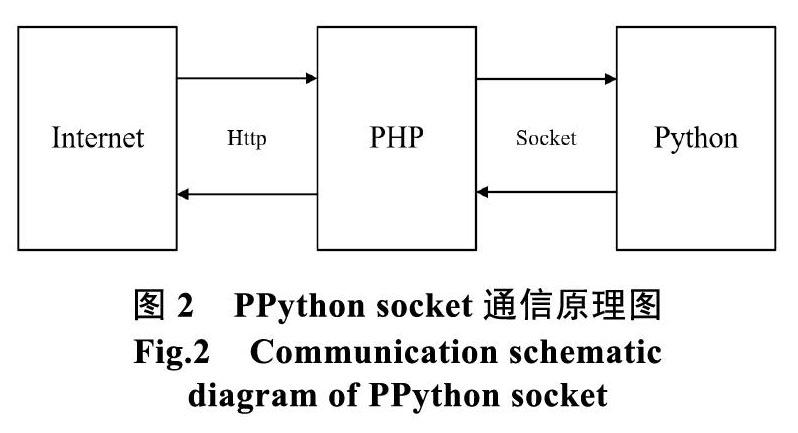
本实验采用Google公司开源项目PPython实现Python与动态网页互联,其实现对两种语言的优势互补,结合使用Python程序和PHP程序,可理解为Python语言和PHP语言相结合的技术,通俗的可以理解为Python语言和PHP语言混编技术。Python和PHP语言各有其内部定义的数据类型,当PHP端数据发送到Python端或者Python端数据发送到PHP端时在传统技术上需要转码处理,而PPython技术通过将Python和PHP不同数据类型序列化就可以直接发送数据,不用进行转码处理,大大提高开发速度。Python语言因其GIL(Global Interpreter Lock)特性,多线程效率不高,在基于由Python程序和PHP程序的混编机制实现的PPython中,Python端可进行多进程方式部署,从而提高Python程序的整体工作效率,此技术提高了Python的多线程效率。PPython技术实现基本原理为socket通信,因此需要网络模块socket支持。socket(套接字)是网络编程中的一个基本组件,套接字基本上是一个信息通道,两端各有一个程序[8]。这些程序可能都位于(通过网络相连的)不同的计算机上,通过套接字向对方发送信息。PPython中网络通信的主要原理如图2所示。
3 基于RNN的青海花儿模型构建
3.1 Python爬虫构建
循环神经网络模型的构建对数据量有较高的要求,因此本实验所用的花儿唱词信息采用Python网络爬虫技术获取。利用爬虫技术可以快速、准确的从WEB应用中获取花儿唱词信息,为后续实验的进行提供数据支持。Python网络爬虫的构建是模拟计算机网络连接,即计算机对服务器进行一次Request请求(带着请求头和消息体),相应地服务器对于计算机的Request请求进行Response回应(带着HTML文件)。爬虫程序模拟计算机对服务器发起Request请求,并且接受服务器端的Response内容并解析、提取所需的信息。
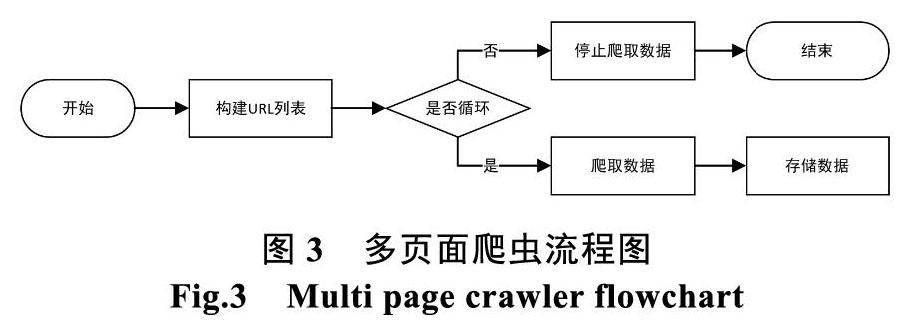
笔者通过分析花儿信息源,发现现有的花儿信息主要分布在WEB应用网易云音乐、QQ音乐上。对此根据不同平台WEB页面的结构,相应的进行爬虫程序的设计。通过分析,网易云音乐WEB页面结构为多页面网页结构,这种类型的网页爬虫流程为。
(1)手动翻页观察个网页的URL构成特点,构造出所有页面的URL存入列表中。
(2)根据URL列表依次循环取出URL。
(3)定义爬虫函数。
(4)循环调用爬虫函数,存储数据。
(5)循环完毕,结束爬虫程序。
多页面爬虫流程图如图3所示。
而QQ音乐WEB页面结构为跨页面网页结构,跨页面的爬虫流程为。
(1)定义爬取函数爬取列表页的所有专辑的URL。
(2)将专辑URL存入列表中。
(3)定义爬取详细页数据函数。
(4)进入专辑详细页面爬取详细页数据。
(5)存储数据,循环结束,结束爬虫程序。
跨页面爬虫流程图如图4所示。
本实验获取到的所有花儿唱词数据保存在文本文件中,以便后续处理。
3.2 唱词分词
中文与英文相比,英文以空格作为非常明显的分隔符,而且一个英文单词横向可按字母拆分,但是中文由于继承自古代汉语的传统,词语之间没有分隔符,并且按“永字八法”分为点、横、竖、撇、捺、折、弯、钩8种。古代汉语中除了人名、地名和连绵词等,词通常就是单个汉字,所以当时没有分词书写的必要。而现代汉语中双字或多字词居多,一个字不再等同于一个词[9]。因此给中文分词带来难度。为了得到更加有效的实验数据及更为严谨的实验结果分析,对于花儿唱词采用目前主流的分词工具jieba分词。通过分词工具jieba将爬取到的花儿唱词进行去噪处理,并且剔除唱词中含有的“,”、“。”、“_”、“《”、“》”、“[”、“]”、“(”、“)”、等特殊字符。分词结束后即可得到可以用于训练的预料库,此后进行RNN模型的训练。
3.3 系统建模
语料库规模越大,模型的训练结果就越好,而对于规模较小的语料则相反。模型训练需要Python NLP gensim包,首先需要安装gensim,但是gensim对科学技术库NumPy和SciPy的版本有要求,需要注意NumPy和SciPy版本,当导入时算法程序不出错则成功。在genism中,与训练算法相关的参数都在gensim.models.word2vec.Word2Vec中。需要注意的参数有。
(1)sentences:此参数设置当前需要分析的语料库,可以是序列、字符文件。在本实验中,采用文件遍历读取。
(2)size:此参数设置词向量的维度,默认值是100。这个维度的取值一般与当前所使用的语料的规模相关,如果语料库很小,比如小于100M的文本语料,则使用默认值。如果语料库规模较大,则增大维度。
(3)window:此参数为词向量上下文最大距离,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个参数的大小。如果是小语料则这个值可以设的更小。
(4)sg:此参数为word2vec两个模型的选择。如果是1,则是Skip-Gram模型,是0则是CBOW(Continuous Bag-of-Words)模型,默认参数值为0。
(5)hs:此参数为word2vec两个解法的选择,如果参数值是1,并且负采样个数negative大于0,则是Hierarchical Softmax。参数值为0,则是Negative Sampling。默认参数值为0。
(6)negative:此参数为使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。
(7)cbow_mean:此参数为用于CBOW在做投影的时候,为1则为上下文的词向量的平均值。为0,则算法中的xw为上下文的词向量之和。在本文中采用平均值来表示xw,默认值也是1,不推荐修改默认值。
(8)min_count:此参数为需要计算词向量的最小词频。添加此参数,可去掉生僻的低频词,默认是5。语料库太小,则调低这个值。
(9)iter:此参数为随机梯度下降法中迭代的最大次数,默认是5。对于规模较小的语料库,可以调小这个参数值,相应的规模较大的语料库,可以增大这个参数值。
(10)alpha:此参数为在随机梯度下降法中迭代的初始步长,默认是0.025。
(11)min_alpha:由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。
模型的训练调用word2vec.Word2Vec()算法即可,对于不同规模的语料库,需要对算法参数进行调整,才能达到更好的训练结果。当模型训练完成以后,需要保存模型以便重用。在word2vec中模型的保存有两种方式可供选择,一种是直接保存模型,另一种是以C语言可以解析的形式存储,对此根据需求保存。
此外,模型训练的速度受到训练程序运行环境和语料库规模的影响。当语料库特别庞大时,性能更为优良的计算机能更快的进行模型的训练。
4 RNN花儿唱词挖掘
4.1 挖掘结果
本实验模型的训练属于无监督学习,并没有太多的类似于监督学习里面客观的评判方式,更多的依赖于端应用。利用RNN对青海花儿信息处理,实现对花儿唱词信息进行聚类、找同义词、词性分析、预测。word2vec语言模型性能较高,但由于其对数据量有很高的要求。由于花儿信息搜集困难,预测的准确度不够高。实验部分结果如下:
4.2 挖掘分析
本实验采用循环神经网络,这是为了综合运用历史信息中的正向信息和反向信息所设计的优秀的神经网络,在数据采集上,由于青海花儿的历史属性及文化背景限制,笔者所搜集的花儿信息有限,加之神经网络对语料库规模的要求较高,训练结果的正确性有待提高,需要将语音识别技术把现有的花儿视频、音频的语音信号转化为相应文本或命令来获取大量花儿数据更为理想。
4.3 词云生成
作为青海传统文化——青海花儿,提取花儿唱词关键内容形成词云,词云的生成对词进行排序后,由于词语过多,仅截取了前300个高频词,词云如图5所示,观察词云图可知:“花儿”(图5的中心位置)这个词的词频最高,其他词根据词频依次从原点展开分布在各点。
5 结论
本文通过循环神经网络序列建模,将深度学习自然语言处理应用于青海花儿信息挖掘当中。在实验中发现许多有趣的特性,分析挖掘青海花儿文本信息的原理同样的可以应用到很多方面,人工智能的发展会给我们带来更多的机遇,我们也会面临着更多的挑战。合理有效的利用好计算机技术能为我们人类的方方面面带来便利,例如语音识别、DNA序列分析、情感分类、机器翻译、命名体识别等。实验中在青海花儿信息搜集过程中出现了些许困难,更大规模的语料库及优化RNN内部网络架构能更加有效地分析花儿信息。如何通过语音识别、视频行为识别技术的辅助来获取数据规模更大的语料库,及优化网络内部架构是下一部研究的问题。
参考文献
[1] The Unreasonable Effectiveness of Recurrent Neural Networks. http://karpathy.github.io/2015/05/21/rnn-effectiveness/.
[2] 邵伟明, 葛志强, 李浩, 等. 基于循环神经网络的半监督动态软测量建模方法[J]. 电子测量与仪器学报, 2019, 33(11): 7-13.
[3] 余萍, 曹洁. 深度学习在故障诊断与预测中的应用[J/OL]. 计算机工程与应用: 1-25 [2020-02-17].
[4] [美] Luke Welling, Laura Thomson. PHP and MySQL Web Development[M]. 慧珍, 武欣, 罗云峰, 等译. 北京: 机械工业出版社, 2018: X—XIV.
[5] 林信良. Python程序设计教程[M]. 北京: 清华大学出版社, 2017: 2—6.
[6] 唐晓丽, 白宇, 张桂平, 等. 一种面向聚类的文本建模方法[J]. 山西大学学报(自然科学版), 2014, 37(04): 595-600.
[7] 丁璐璐. 基于信息覓食理论的智库情报分析质量及其提升策略研究[D]. 吉林大学, 2019.
[8] 董彧先. 基于Python的网络编程研究与分析[J]. 科学技术创新, 2019(20): 85-86.
[9] 成锐. 基于Lucene面向主题的手机搜索引擎的研究与实现[D]. 电子科技大学, 2012.
