
海量时间序列数据的相关探索
2020-08-19 03:23盛文婷付国庆
通信电源技术 2020年10期
盛文婷,付国庆
(新疆农业大学 科学技术学院,新疆 乌鲁木齐 830000)
0 引 言
时间序列数据是按时间进行排序的一种数据,目前在各个领域中都有着相应的应用,而随着数据量的不断增多,人们正处在一个时间序列数据的世界中。传统的数据处理方法一般都是针对静态的数据。而目前的数据表现出数据量较大、变化较快且呈现出动态化的特征,因此传统的方法已经不能有效地实现对数据的处理和存储。本文结合MaxCompute大数据处理技术对时间序列数据进行处理,便于发现时间序列中有价值的信息,进而转换成所需要的信息。
1 海量时间序列数据的特征分析
时间序列数据带有一定的时间戳,同时数据量大,在相同的时间内数据比较接近,并具有存储后很难进行修改等特点。
1.1 时间属性
海量时间序列的一个最典型的特征是时间性,每一个数据都有一个时间区和一个时间点,同一数据源具有先后顺序和时间属性。在某个特定的空间和特定的时间里,数据值是唯一的。典型的时序数据如表1所示的Dodgers数据集,表中涵盖了时间戳和相应的值。这个数据信息来源于洛杉矶北101高速公路所通过车辆的数据,以5 min为时间节点[1]。
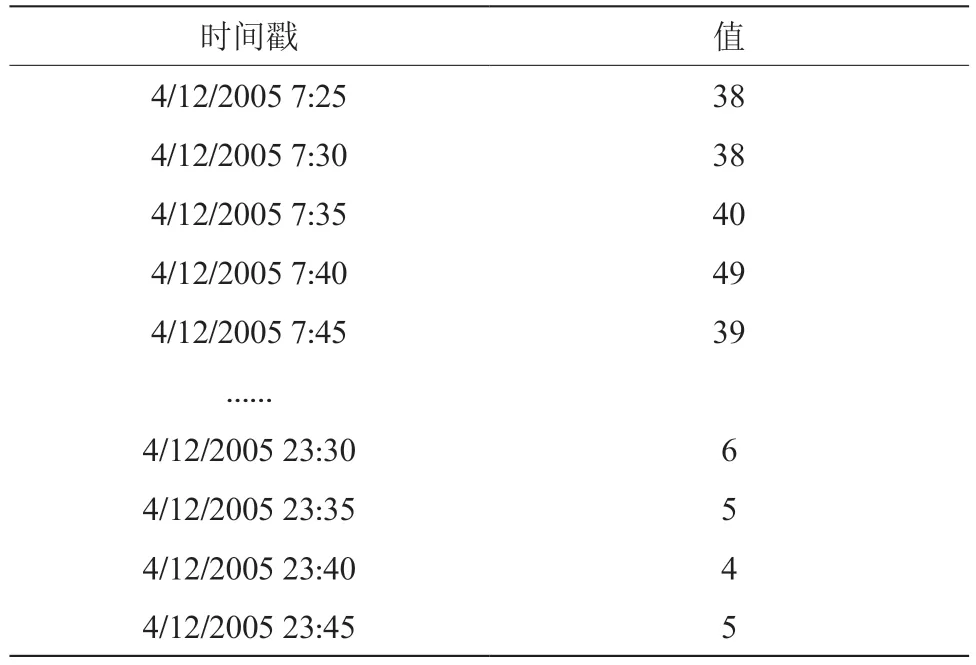
表1 Dodgers 时序数据
1.2 数据量庞大
海量时间数据之所以是“海量”,主要是随着时间的推移数据不断出现,量越来越大,并呈现出动态化的特点,是静态数据所不能比拟的。同时,如今的信息数字化技术发展越来越快,数据采集的类型也越来越多,相应的数据源也呈现出快速上升的趋势。此外,随着数据源挖掘技术的提高和监控技术的进步,存储设备和传感器等设备价格不断降低,时序数据的增长速度呈现爆发式的特征,且数量巨大。随着时间的推移,数据量越来越大,原来的旧数据也没有删除,对于快速检测到正确的数据是一个重大的考验。例如,Facebook公司每天需要处理大量的用户在平台上分享的内容,每天的数量高达25亿条,超过500 TB。
1.3 数据关注的局部性
由于海量时间数据的总量比较庞大,人们不可能对所有的数据进行关注。从实际情况来看,用户往往关注一些在特定时间段的数据,或者一定时间内的最大值、最小值和均值,造成了对数据关注的局部性。例如在查询监控系统时,人们往往会选取某个时间段的数据,或者只关注某些数据源。在检索时序数据时,只需查询到某个数据源在某个时段的数据,或者是某个时间段内特定数据源的数据。例如,查询表1的Dodgers数据,只需要统计出最高值,就可以判断出哪个时间段的交通比较拥堵,从而采取必要的措施。
1.4 采样频率固定
海量时序数据一般都有着固定的采样频率。在表1中,系统每5 min对车流量的值进行保存。也有少量的时序数据是会跟着行为的变化而发生变化,在股票市场中,股民的购买行为对股票价格的变化有着直接的影响,因此需要分析它们的行为搜索数据。
1.5 数据的不变性
海量时序数据有一个重要的特点是数据在写入后一般是不能修改的。时序数据一般是根据时间记录的每个阶段的数据,这些数据产生的时间具有唯一性的特征,且都是发生在过去的时间里,这也是时序数据与其他数据的不同之处。由于数据的不变性,可以采用压缩算法对数据进行压缩,数据也不会发生变化。在数据压缩时,不需要对整个数据信息进行压缩,只需要对直接访问的数据进行压缩,这样在解压时只需要提取部分需要的数据,不会因为要解压大量数据而影响读取速率,同时通过数据压缩还可以提高存储速率。
2 时间序列数据分析处理总体流程
对海量时间序列数据进行分析,需要有一套规范的流程,明确分析的目的,收集数据,对数据进行加工,并展示数据分析结果。其中,数据分析环节主要使用SQL命令,或者采用机器学习方法进行数据挖掘。而数据分析的结果可以通过报表的形式呈现出来,也可以通过可视化手段进行呈现。图1为时间序列数据分析处理整体流程。
在图1中,原始的时间序列数据流被收集之后,通常会采用二进制文件方式存储在本地文件系统中,同时再经过本地程序实现格式的转换,转换为时间序列文本,如txt文档并将数据上传到MaxCompute。在数据上传前,文本的格式设计要与MaxCompute表结构相匹配,匹配格式如图2所示。数据加工则是对本地存储的数据进行加工,采用排列熵的算法进行数据分析,最后对结果进行展示。
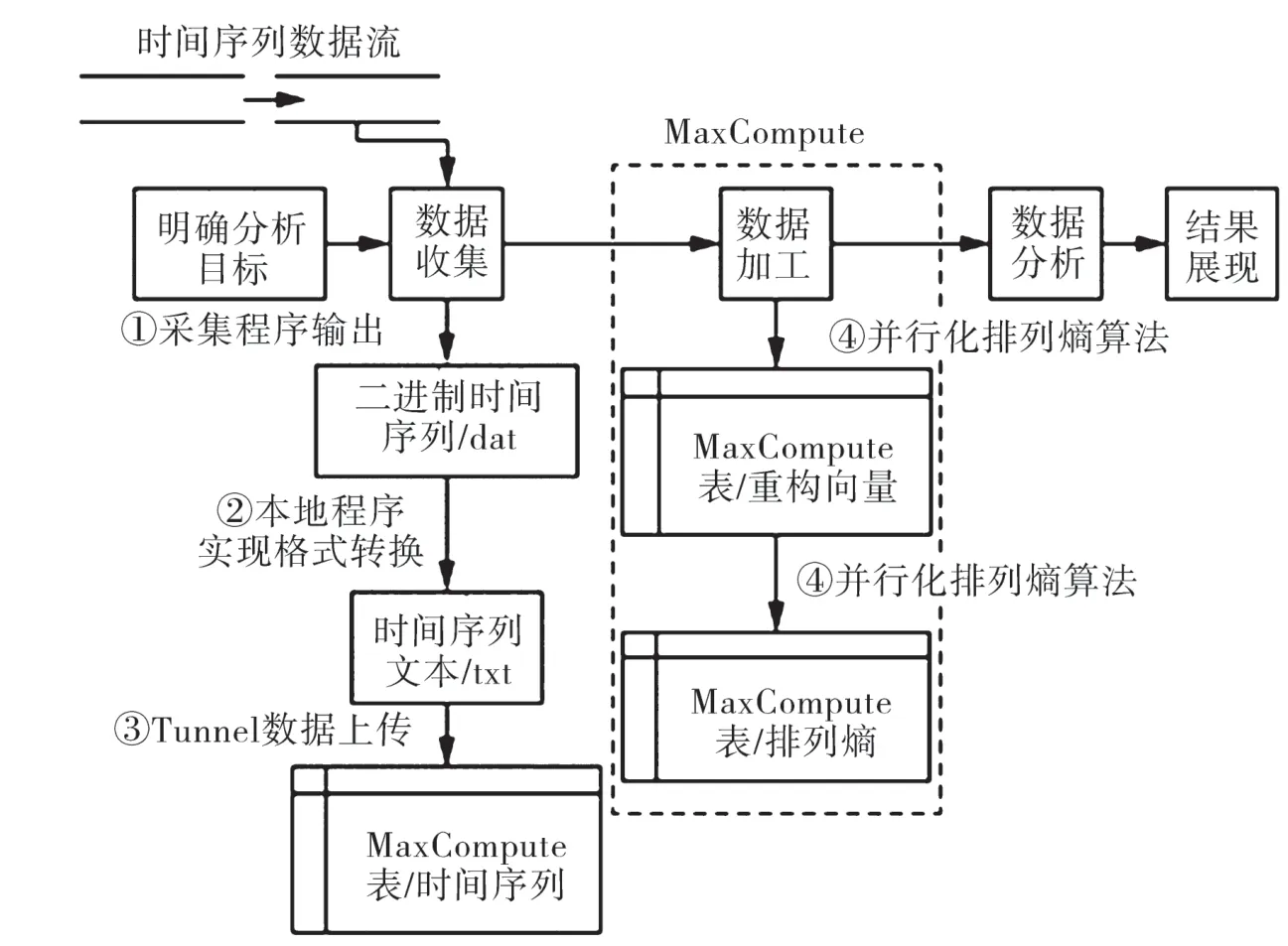
图1 时间序列数据分析整体流程
图2是文本文件和MaxCompute表结构的匹配情况,表的操作可以使用SQL DDL语句方式完成,通过Tunnel工具完成数据的上传,运用编程框架实现了并行化的排列熵算法。本地Eclipse开发环境需要对算法进行调试,再将jar包导出,导出的资源再上传到MaxCompute,运用jar命令执行。算法中输入的数据都是来源于MaxCompute表,同时进行排列熵算法后,所输出的结果,也会再进入到MaxCompute中。由MaxCompute提供的SQL接口可以直接读取表中的数据,在后续计算中可以进行展示和应用。
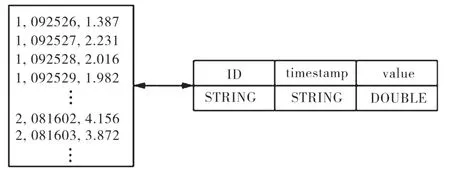
图2 文本文件和表的格式匹配
3 时序数据存储结构的设计
海量时序数据量比较庞大,但是对数据查询的过程则较为简单。而传统的关系型数据库的查询功能比较复杂,其严格遵循了ACID原则,即这种数据库在程序上比较复杂,有些功能很多时候是用不到的。因此有必要结合时序数据的特征,设计出便捷合理的存储结构,以提高存储和检索的效率。通过设计合理的存储格式,可以加快检索的速度。数据组织形式采用堆表型的方式能够大大增加写入的速度,存储结构采用列式的存储结构可以改善压缩的效果[2]。
监测系统对各个时间点进行检测,获得的数据,就是时间序列数据,较大的时间数据可以用h或d来表示,ms或μs则可用来表示较小的时间数据。以往的时间序列数据存储数据库主要是关系型数据库、文本文件数据库以及实时数据库。最常用的方式是文本文件存储方式。在大数据下,分布式的文件系统较为常用,能够实现对大文本的存储,如Hadoop分布式文件系统以及HDFS(Hadoop Distributed File System)等。关系型的数据库容量较小,存储的数据有限,且扩展性不好。而实时数据库适合监测数据的实时写入,运用压缩算法对数据进行压缩,解决存储容量不足的问题。
阿里云开发的数据库产品MaxCompute,使用二维表完成对用户层的数据存储,而分布式文件系统实现对底层数据的存储。
表是MaxCompute存储数据的基本单位,所以对表模式的设计是进行数据存储的前提。文本形式的波形信号数据采用按行存储的方式,即每行存储1条时间序列数据,用于排列熵计算。由于数据来源以及计算方式不同,各条时间序列的长度是不一样的。使用文本方式进行存储时,1条数据占据1行的空间,这1条数据的长度是不受限制的。但MaxCompute表的宽度则受到一定的限制,小于1 024列。如果某个数据长度大于1 024列,则不能进行按行存储[3]。
本文使用按列存储模式存储时间序列数据。排列熵计算过程中产生的重构向量使用按行存储的模式,如图3所示。首先需要将行存储的文件进行格式化,形成按列存储的文件。列存储文件需要与MaxCompute上的原始时间序列数据表的列进行匹配,才能执行Tunnel数据上传操作。如表2所示,表中的ID字段代表不同的时间序列信号标识。对时间序列数据执行排列熵计算的步骤1是向量重构,重构后的结果数据存储在MaxCompute的重构向量表中。重构向量的维数M通常小于1 024,因此可以进行有效的数据存储。根据计算维度需求的不同,需要分别创建多张重构向量表。以三维存储表为例,创建存储表的SQL,DDL描述如表3所示。

图3 时间序列数据的存储模式

表2 数据上传操作

表3 三维重构向量表DDL描述
在表3中,创建了包含4个字段的表d3vector,分别是ID、d1、d2、d3。其中,ID作为第一个字段,是对时间序列数据的一种标识,通过这样的标识可以对不同的排列熵计算方法进行区分;d1,d2,d3是代表的是标识上的三个维度值。排列熵的计算结果是在MaxCompute表完成存储,其中包含ID标识和排列熵结果这两列内容[4]。此外,排列熵计算结果并不是完全不能移动的,可以通过数据集成服务将其导出,以便在其他存储系统进行存储。可以直接在MaxCompute数据库上对数据进行分析,也可以在导出的系型数据库、非关系型数据库(NoSQL)中对数据进行分析,以便完成相应的数据处理业务。
4 结 论
时间序列数据存在于社会生产和生活的各个领域,且数据量越来越大,变化较快。因此,要想对数据进行有效的处理,就要把握好海量时间序列数据中的特征,如时间属性、数据量庞大特征、数据关注的局部性、采样频率固定以及数据的不变性。同时,建立一套规范的分析流程,对时间序列数据进行分析和挖掘,以不断满足社会发展的需要。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
当代陕西(2019年14期)2019-08-26
小型微型计算机系统(2019年3期)2019-03-13
消费导刊(2018年10期)2018-08-20
计算机与生活(2018年3期)2018-03-12
中学数学杂志(初中版)(2016年5期)2016-11-01
电脑爱好者(2015年20期)2015-09-10
