
电商时代线上商家的用户评价挖掘模型研究
2020-09-10 07:22谢莹伍逸兴李秦青
商展经济·下半月 2020年7期
谢莹 伍逸兴 李秦青

摘 要:作为电子商务的重要载体,互联网上的内容对商家也存在导向作用。通过对网络上顾客反馈的挖掘,商家可以及时了解市场行情,完善商品的质量和營销手段。本研究采用顾客满意度模型,以三种产品:吹风机、微波炉、婴儿奶嘴为例,对他们的文本评价进行数据分析。基于此,可以对用户的文本评论有一个大概的认识,能够充分的挖掘其中所包含的文本信息。
关键词:用户评价 评价挖掘 顾客满意度模型
中图分类号:F724.6 文献标识码:A
近年来,互联网的快速发展,网络已成为人们生活中重要的信息来源,也是人们表达个人意向的重要途径。人们在购买商品前,都习惯在网上查看他人对同一产品的评价;另外,人们也越来越喜欢在网上分享他们对使用过的产品的看法。同时,作为电子商务的重要载体,互联网上的内容对商家也存在导向作用。通过对网络上顾客反馈的挖掘,商家可以及时了解市场行情,完善商品的质量和营销手段。
进军一个新市场是有风险的,但如果事先做了周密的调查就没有相关风险。如今,产品评论对于在线销售至关重要,因为它们反映了产品的市场接受度,而这是销售策略的核心。众所周知,世界上最大的网购平台亚马逊提供了三种评论:以星级的形式进行评价(star ratings),用户的文字评论,以及用户和非用户对原始评论的意见,称为“帮助度”(helpfulness rating)。
本研究以吹风机、微波炉、婴儿奶嘴为例。公司已经准备了客户评论的数据集,这些数据集不仅包含上述类型,而且还指明了时间段。在整个分析过程中,本研究不会使用除它们之外的任何数据。
简而言之,研究的工作包括以下几方面。
任务(1)描述性地分析数据并勾勒出粗略的市场图景。任务(2)向公司营销总监展示如何衡量这些数据,并获得其想要的结果。这包括数学建模和数据处理的步骤。任务(3)确定衡量在线评论的关键因素。随着时间的推移,发现销售趋势,并确定哪种产品是真正“成功”或“失败”的。任务(4)揭示原始评论和二级评级(帮助性评级)之间的关系。任务(5)将以上步骤组织成建议。
1 模型描述
1.1 假设
由于缺乏必要的数据和知识有限,通过以下假设来帮助我们建模和分析。这些假设将是之后分析的先决条件。
(1)明星评论和客户评论同等重要,重要性权重不会随着时间而改变。(2) 顾客对三种产品的评价模式是相似的。(3)数据真实准确。
1.2 数据处理
我们删除了包含缺失值和异常值的行。经过简短的选择,我们发现三个数据集中有缺失值和离群值的行。例如,星级理论上从1星~5星,但一些产品被评为0星、10星,甚至144星。对于vine和verified purchase的标签,应该是yes或no。因此,我们删除了两者都不包含的行。与此同时,有些线条还不完整。这些行总数很小,这不会对删除后的总体数据输出产生负面影响。最后,我们得到一个过滤后的数据记录可以分析。
1.3 简要分析
在对数据进行预处理后,我们有意地从三个元素进行分析,如图1所示。
从图1可知,vine上的会员只占审稿人总数的一小部分(低于2%),这意味着高可信度的客户很少,所以我们必须仔细推测星级评分和评论之间的关系。
我们根据不同评级的人数制定三个独立的星级评级直方图。
我们还考察了验证采购在总采购中的比例。深蓝色扇区表示“N”,浅蓝色表示“Y”。可以看出,吹风机和婴儿奶嘴产品在质量和服务上都是值得信赖的,通过认证购买的产品占总交易量的86%,而微波炉的性能则值得怀疑,因为未经认证购买的产品占总交易量的30%以上。
2 顾客满意度模型
为了帮助公司更好地了解市场,我们将客户评价量化,并结合星级评分提出客户满意度模型:
总分从0~10。分数越高,客户满意度越高。
建立该模型是为了计算客户满意度得分,使公司能够实时跟踪市场情绪。
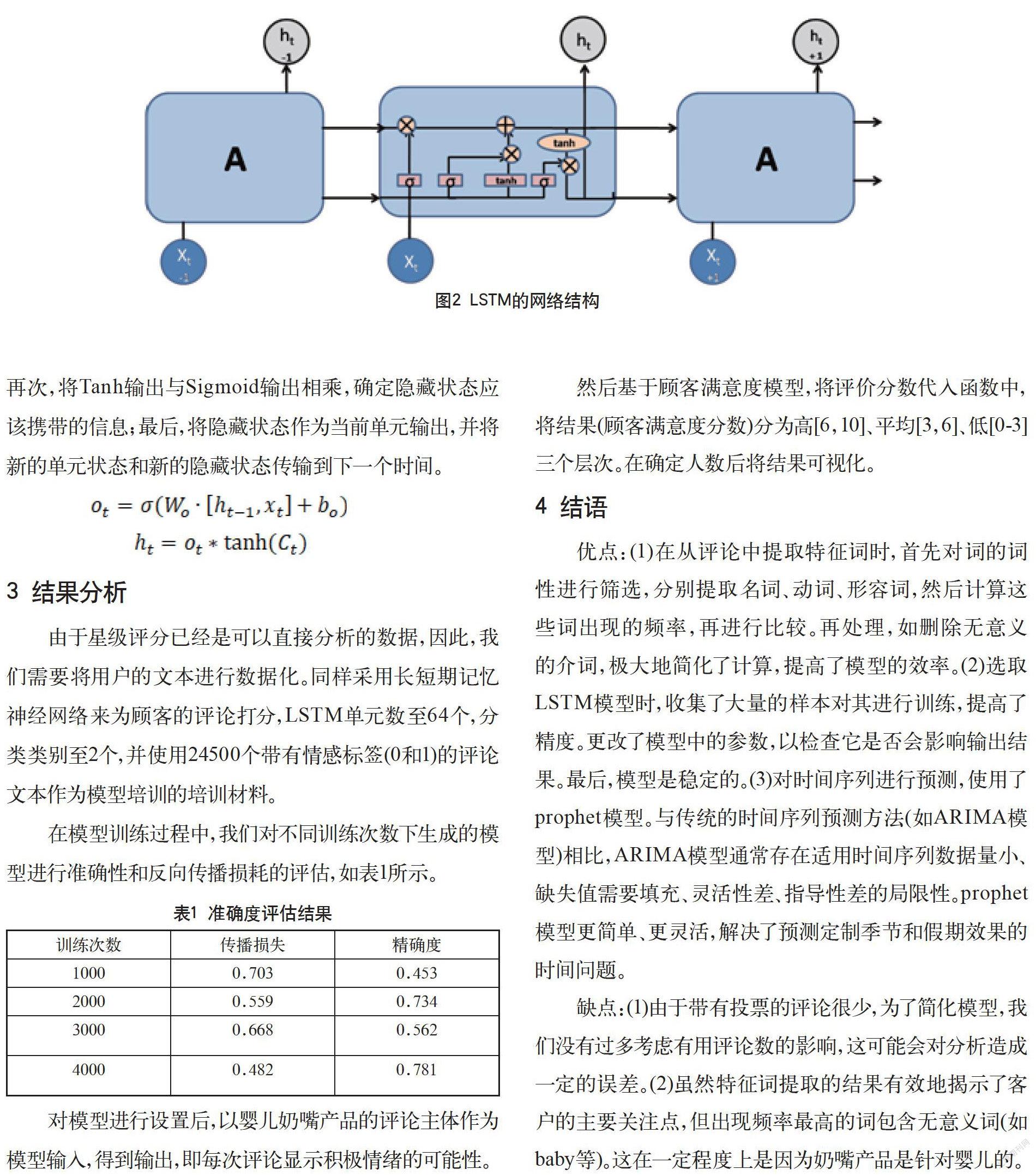
在长短期记忆神经网络(LSTM)中,每个细胞都持有已记忆的值。当我们更新当前单元格的输出时,还需要决定在当前单元格中可以记录什么。长短期记忆神经网络于1997年正式提出,包括遗忘门、输入门、输出门这三个结构,如图2所示。
遗忘门决定哪些信息应该被丢弃或保留。之前隐藏状态的信息和当前输入的信息同时加载到Sigmoid函数中。输出值在0和1之间变化。1表示“完全保留”,而0表示“完全删除”。因此,这个函数可以决定哪些信息应该删除。
输入门用于更新单元状态。之前的门已经决定了要做什么,我们只需要实际去做。首先,将之前隐藏的状态信息和当前的输入信息输入到Sigmoid函数中,并将输出值调整为0~1,以决定更新哪些信息。0表示不重要,1表示重要。另一种可能的解决方法是通过函数将隐藏状态和电脑输入放入,压缩到-1~1来调整网络,然后乘以s型门的输出。Sigmoid函数将决定输出中哪些信息是重要的,哪些信息需要保留。
控制Ct输出的门称为输出门。一个输出门决定下一个隐藏状态的值,它包含关于前一个输入的信息。隐藏状态也可以用于预测。首先,将先前的隐藏状态和当前输入到Sigmoid函数中;其次,将新得到的单位态代入Tanh函数;再次,将Tanh输出与Sigmoid输出相乘,确定隐藏状态应该携带的信息;最后,将隐藏状态作为当前单元输出,并将新的单元状态和新的隐藏状态传输到下一个时间。
3 结果分析
由于星级评分已经是可以直接分析的数据,因此,我们需要将用户的文本进行数据化。同样采用长短期记忆神经网络来为顾客的评论打分,LSTM单元数至64个,分类类别至2个,并使用24500个带有情感标签(0和1)的评论文本作为模型培训的培训材料。
在模型訓练过程中,我们对不同训练次数下生成的模型进行准确性和反向传播损耗的评估,如表1所示。
对模型进行设置后,以婴儿奶嘴产品的评论主体作为模型输入,得到输出,即每次评论显示积极情绪的可能性。
然后基于顾客满意度模型,将评价分数代入函数中,将结果(顾客满意度分数)分为高[6,10]、平均[3,6]、低[0-3]三个层次。在确定人数后将结果可视化。
4 结语
优点:(1)在从评论中提取特征词时,首先对词的词性进行筛选,分别提取名词、动词、形容词,然后计算这些词出现的频率,再进行比较。再处理,如删除无意义的介词,极大地简化了计算,提高了模型的效率。(2)选取LSTM模型时,收集了大量的样本对其进行训练,提高了精度。更改了模型中的参数,以检查它是否会影响输出结果。最后,模型是稳定的。(3)对时间序列进行预测,使用了prophet模型。与传统的时间序列预测方法(如ARIMA模型)相比,ARIMA模型通常存在适用时间序列数据量小、缺失值需要填充、灵活性差、指导性差的局限性。prophet模型更简单、更灵活,解决了预测定制季节和假期效果的时间问题。
缺点:(1)由于带有投票的评论很少,为了简化模型,我们没有过多考虑有用评论数的影响,这可能会对分析造成一定的误差。(2)虽然特征词提取的结果有效地揭示了客户的主要关注点,但出现频率最高的词包含无意义词(如baby等)。这在一定程度上是因为奶嘴产品是针对婴儿的。
参考文献
Hochreiter S, Schmidhuber, Jürgen. Long Short-Term Memory [J]. Neural Computation, 1997, 9(8).
Le J A, El-Askary H M, Allali M<i>, et al. </i>Application of recurrent neural networks for drought projections in California [J]. Atmospheric Research, 2017(188).
Sean J. Taylor &amp; Benjamin Letham. Forecasting at Scale[J]. The American Statistician, 2018, 72 (1).
Taylor S J, Letham B. prophet: automatic forecasting procedure. R package version 0.3, 2017.
