
构建慢性乙型肝炎临床终点事件预测模型的方法学考量
2020-09-28 07:47武珊珊孔媛媛
临床肝胆病杂志 2020年9期
武珊珊,孔媛媛
首都医科大学附属北京友谊医院,国家消化系统疾病临床医学研究中心,临床流行病学与循证医学中心,北京 100050
我国慢性乙型肝炎患病率高,并发症重。在我国肝硬化和肝癌患者中,由乙型肝炎引起的比例分别为60%和80%[1]。最新全国体检数据显示我国农村21~49岁男性人群HBsAg阳性率为6%[2]。据此推算,全国约有2500万人为慢性乙型肝炎患者;按照每年1.6%~4%的发病率计算,每年约有40万~100万患者可发展为代偿性肝硬化。抗病毒治疗可以降低乙型肝炎相关并发症的发生率和病死率,但即使经过有效的抗病毒治疗仍有部分患者会出现疾病进展,包括门静脉高压相关并发症和肝癌,并导致死亡[3-5]。因此,实现临床终点事件的精准预测并加强干预是降低病死率的关键措施。
目前国内外已有较多预测慢性乙型肝炎患者临床终点事件的风险预测模型,但被临床广泛应用的模型较为少见。很多预测模型在开发过程中存在一定的方法学缺陷,导致模型的精确性和外推性不高,多数预测模型长期处于“多数被建立,少数被验证,极少被应用”的情况[6-7]。为此,本文基于对目前已发表的慢乙型肝炎临床终点事件预测模型的总结,从方法学角度阐述预测模型构建的要点,以期为精准预测慢性乙型肝炎患者临床终点事件的模型研究提供参考。
1 预测模型的基本概念和研究形式
临床预测模型又称临床预测规则,是指利用医学征兆、症状或其他临床发现预测特定疾病或结局发生的概率,包括诊断模型和预后模型。预测模型类研究一般可以分为两类:诊断类预测模型和预后类预测模型[8-9]。诊断类预测模型是估计现在时间点某一个体发生特定疾病的风险或者概率,通常建立在横断面研究的基础上;预后类预测模型则是利用个体现在时刻的特征指标(如实验室检查指标、症状或体征等)去预测未来发生特定事件的风险或概率,通常建立在队列研究的基础上,尤其是前瞻性队列提供的结论更为可靠。两类预测模型的研究框架详见图1。
按照研究目的预测模型类研究又可分为模型开发研究、模型验证研究和开发验证同时进行的研究[8],其中模型验证又可分为内部验证和外部验证,取决于与模型开发使用的数据集是否相同。若使用相同的数据集去验证模型,则为内部验证;若使用与模型开发不同的数据集去验证模型,则称为外部验证。外部验证一般优于内部验证。
2 慢性乙型肝炎临床终点事件预测模型总结
慢性乙型肝炎临床终点事件预测模型属于预后类预测模型。目前国内外关于慢性乙型肝炎患者的预后模型主要以肝细胞癌(HCC)为结局,少数以复合终点即肝脏相关事件(liver related events, LRE)及肝纤维化逆转为结局[10-23]。本文共纳入了14个慢性乙型肝炎患者临床终点事件预测模型的文献,各预测模型构建的基本特征详见表1。所有预测模型的建立均采用队列研究,其中13个(92%)模型基于亚洲人群构建,只有PAGE-B[16]模型是基于多个欧洲国家的高加索人种所构建。各模型的构建人群样本量范围为212~23 851,中位数为1035,结局事件发生中位数为56,其中CAMD模型构建人群样本量超过2万,结局事件发生数目最多(596例HCC)。
各模型构建人群的关键特征,如是否接受抗病毒治疗与肝硬化状态差异性较大。在研究对象是否接受抗病毒治疗方面:GAG-HCC[10]、NGM-HCC[11]及REACH-B[13]模型是基于未进行抗病毒治疗的慢性乙型肝炎患者,mREACH-B[15]、PAGE-B[16]、mPAGE-B[18]、CAMD[19]、AASL-HCC[20]、REAL-B[21]等模型是基于抗病毒治疗的慢性乙型肝炎患者,CU-HCC[12]、LSM-HCC[14]及RWS-HCC[17]模型则同时包含了接受抗病毒治疗和未抗病毒治疗的慢性乙型肝炎患者,抗病毒治疗患者的比例为15%~36%。在研究对象肝硬化比例方面:REACH-B[13]模型是唯一针对非肝硬化患者构建的预测模型,Wu等[22]基于代偿期肝硬化的慢性乙型肝炎患者构建了LRE的2年风险预测模型,其余模型的构建人群则同时包含了肝硬化和非肝硬化的慢性乙型肝炎患者,肝硬化患者的比例为15%~47%。因而在模型应用时需要充分考虑到目标人群的基本关键特征,选择外推性较好、预测结果较准的模型进行临床应用。
关于各模型中慢性乙型肝炎患者临床终点事件的风险预测因素,大致可以分为3类。(1)传统流行病学危险因素:包括年龄、性别、HCC家族史、饮酒、糖尿病合并症、肝硬化;(2)临床检测指标:包括ALT、Alb、PLT、TBil、AFP、LSM、HBeAg、HBV DNA等指标;(3)遗传易感性检测指标:包括核心启动子突变等指标。本研究纳入模型所采用预测因素的类别情况,1个(7%)模型仅纳入传统流行病学危险因素,2个(14%)模型仅纳入临床检测指标,10个(71%)模型在传统流行病学危险因素基础上增加了PLT、HBV DNA或Alb等临床检测指标,1个(7%)模型综合了传统流行病学危险因素、临床检测指标及遗传易感性指标。在预测因素测量时间点的选择上,大部分(86%)模型均选择了纳入基线或抗病毒治疗开始时的各临床检测指标,仅有2个(14%)模型考虑了某些临床检测的动态变化。
在模型构建的方法学层面,大部分(12/14,86%)模型采用了Cox比例风险回归来构建预测模型,少数(2/14, 14%)采用了logistic 回归的方法,未见其他统计学方法的使用。所有模型都采用AUC或C-index指标进行了模型区分度的评价,但近半数(6/14,43%)模型未进行校准度的评价和报告。14个模型中,5个模型只在内部样本中进行了交叉验证,模型预测效果的外推性尚未进行评价,从而限制了模型在临床的应用和推广。此外,12个基于Cox比例风险回归构建的预测模型中,50%的模型(如CU-HCC[12]、GAG-HCC[10]、LSM-HCC[14]等)未报道各预测因素的系数及基础无病生存率,2个基于logistic回归构建的预测模型也未报告截距项和/或各预测因素的系数,从而使这些模型的临床应用受到了一定的限制,也无法基于其他外部队列对这些模型的校准度进行外部验证。由此可见规范预测模型的产生过程及报告方法,不仅有助于提升预测模型本身的质量,也能为后续预测模型的临床应用及广泛验证提供可能。
3 预测模型构建的研究思路和基本步骤
预测模型构建基本可以分为5个步骤,依次是确定研究问题、选择研究设计、模型开发和评估、模型内部验证和外部验证以及模型结果的展示和报告。
3.1 确定研究问题 确定预测模型的研究问题要从临床实践出发,从而确保构建出的模型能够真正为临床科学决策提供帮助。
3.2 选择研究设计 需要明确预测因素与结局事件的采集时间点是否相同,即需明确是诊断类预测模型还是预后类预测模型,这关系到采用的研究设计类型即横断面研究还是队列研究。
3.3 模型开发和评估 该部分是构建预测模型的关键,所涉及内容主要为统计分析,包括统计模型的选择、预测变量的转换和筛选、模型区分度与校准度的评估三部分内容。目前构建预测模型所采用的统计方法以logistic回归和Cox比例风险回归为主,前者未考虑到结局事件发生的时间,无法利用失访研究对象的数据进行分析,统计效能较Cox比例风险回归低;但当研究对象的随访时间较为统一,队列中失访率较低时二者的结果很接近。因此目前logistic回归多用在诊断类预测模型,Cox比例风险回归多用在预后类预测模型研究中。当然考虑到纵向资料的多次随访、各预测指标的动态变化、竞争风险的发生等方面,其他更为复杂的统计模型的应用也越来越广泛,如联合模型、时依协变量Cox比例风险模型、竞争风险模型等。
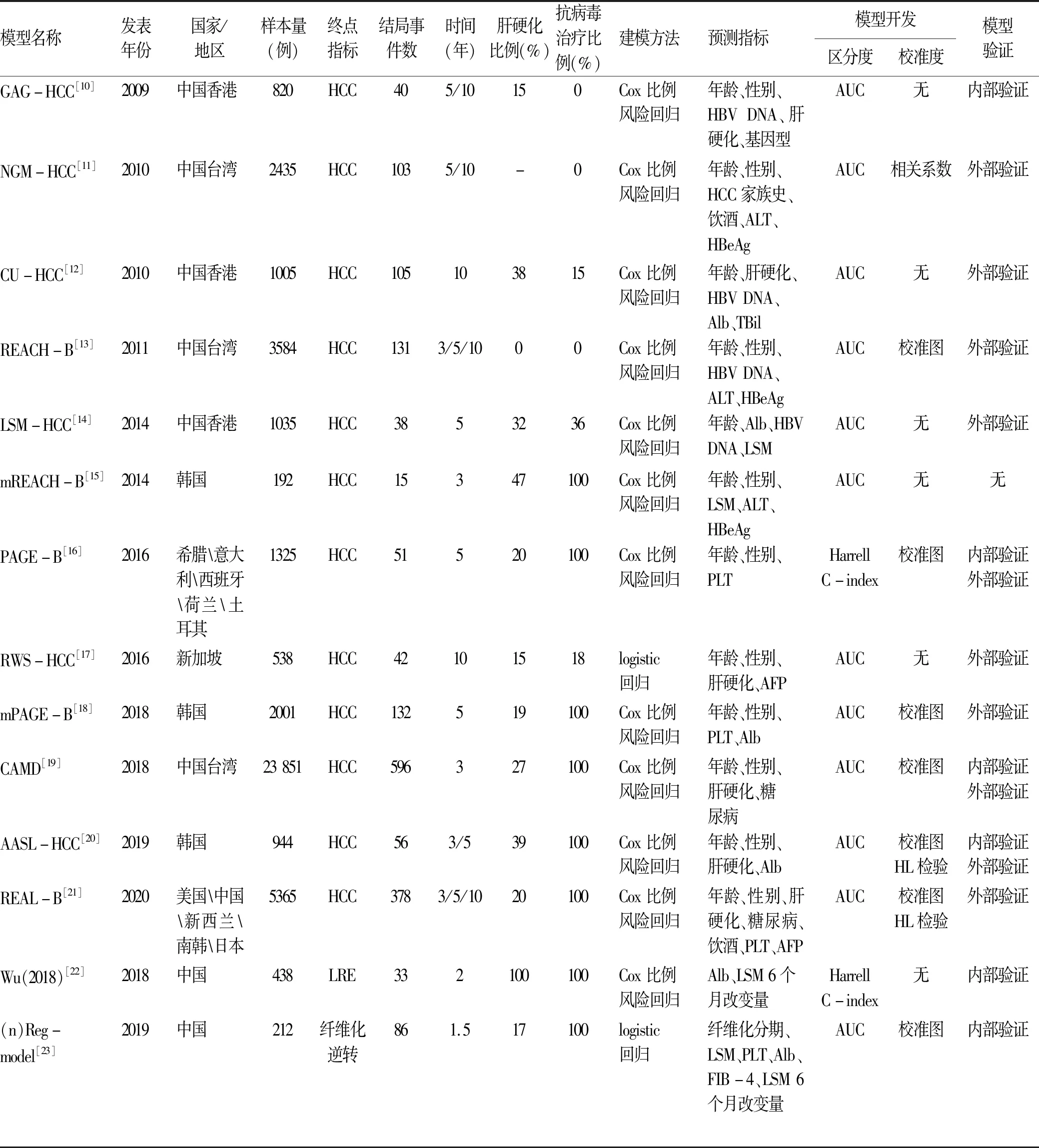
表1 慢性乙型肝炎/肝硬化患者临床终点事件预测模型构建及验证情况
预测变量的筛选是预测模型准确性的关键,贯穿于整个预测模型的建立过程。理论上来讲预测变量越多模型的准确性往往越高,但通常也意味着模型更为复杂,应用性更差,且容易导致模型过度拟合。因此考虑到临床应用的便捷性,通常会选择尽量少的且具备科学性、可操作性、实用性和成本效果比的预测指标。变量筛选的统计方法有很多种,如基于P值的方法、基于信息准则的方法、最优子集法、机器学习、LASSO等惩罚类变量筛选方法等,具体可根据相应研究问题来选择合适的变量筛选方法,但一定要注意不能只依赖于统计层面的筛选,基于既往研究、临床经验、生物学合理性等认为可能有影响的变量也应考虑纳入。
模型的评估包括诊断/预测效能评价,如区分度、校准度以及灵敏度和特异度、阳性/阴性预测值、阳性/阴性似然比等;模型统计学评价,如模型的决定系数R2、反映模型的拟合优度指标AIC/BIC等[24];卫生经济学评价,如分类改善指标(NRI)、综合判别改善指数(IDI)、成本-效果分析等[25]。有学者提出模型性能评价的“ABCD原则”[8],即模型截距(Alpha Calibration-in-the-large);校准曲线斜率(Beta Calibration slope); C统计量(C-statistics);决策曲线分析(Decision-curve analysis)。
3.4 模型内部验证和外部验证 模型验证是预测模型构建不可或缺的步骤,即对模型的区分度和校准度等进行考察的过程。一个良好的预测模型必定经过了严格的内部验证及外部验证。内部验证是基于模型开发数据集进行的验证,通常作为模型开发的一部分,其目的是检验模型开发过程的可重复性。需要注意的是,内部验证是针对整个建模过程中的所有步骤,包括模型选择、变量转换和筛选等,而不是仅针对最终模型进行验证。内部验证的常见方法包括随机拆分验证、交叉验证、重抽样验证及“内部-外部”交叉验证等。外部验证则是基于与模型开发不同的数据集进行的验证,更关注模型的外推性。根据外部验证数据来源的不同,外部验证可以分为时段验证、空间验证、时空验证和领域验证等几类。
3.5 模型结果的展示和报告 预测模型本质上是预测变量的各种数学公式的组合,为方便临床应用,通常会将不同的预测变量赋予不同的分值,采用评分表或打分卡的形式对应相应的风险。类似的,诸如列线图或EXCEL工具、网页工具或者手机App等电子方式也可进行展示和应用。在预测模型的报告方面,《个体预后与诊断的多因素预测模型报告规范》(transparent reporting of a multivariable prediction model for individual prognosis or diagnosis, TRIPOD清单)从标题和摘要、介绍、方法、结果、讨论以及其他七个方面,提出了22个条目,并一一进行了充分的说明和举例,以规范报告内容,提高研究质量[26]。研究者在开展相关研究及撰写研究报告时应注意参考。
4 总结与展望
当今医学从经验医学发展到循证医学,数据和证据的价值得到前所未有的重视。随着精准医学和大数据时代的到来,如何实现对乙型肝炎临床终点事件,尤其是抗病毒治疗后终点事件的精准预测成为亟待解决的科学问题。后续临床终点事件预测模型的构建应充分考虑到抗病毒治疗后各种临床生化指标的变化,诸如ALT、Alb、PLT、TBil、AFP、LSM、HBeAg、HBV DNA等指标在抗病毒治疗后的变化情况,从而可对抗病毒治疗后人群肝癌或失代偿等终点事件的发生进行精准预测。
近年来,随着肝穿病理量化评价技术如qFibrosis、机器学习等人工智能技术在临床研究中的应用以及新的病理评价标准如“北京标准”[27]的提出,对肝纤维化逆转的预测也将逐渐受到重视。同时,D’Amico等[28]学者提出的针对代偿期肝硬化患者临床终点事件细分为有序的1~6级分类标准也为实现肝硬化患者临床终点事件的精准预测提供了依据。
此外,应该规范预测模型构建的方法学过程,包括统计分析模型的选择、预测变量的筛选及模型区分度与校准度的评估,尽量减少模型构建过程中的偏倚风险,并规范预测模型类研究的报告,这对于提高模型的预测性能和临床应用也至关重要。目前已有学者制定了预测模型的偏倚风险评价工具PROBAST (Prediction model Risk Of Bias ASsessment Tool)[29]和报告规范清单TRIPOD[26]。随着预测模型构建的方法学规范化,临床终点评价标准的精细化,以及人工智能技术在临床研究的深入应用,相信一定会有助于加速实现慢性乙型肝炎临床终点事件精准预测的目标。
猜你喜欢
中老年保健(2022年6期)2022-08-19
肝博士(2022年3期)2022-06-30
肝博士(2022年3期)2022-06-30
医学概论(2022年3期)2022-04-24
中国典型病例大全(2022年7期)2022-04-22
今日农业(2021年21期)2021-11-26
中老年保健(2021年12期)2021-08-24
中国药学药品知识仓库(2021年18期)2021-02-28
中西医结合肝病杂志(2020年2期)2020-10-27
中国民族民间医药·下半月(2011年10期)2011-12-27
