
Fraud detection on payment transaction networks via graph computing and visualization①
2020-10-09 07:38SunQuan孙权TangTaoZhengJianbinLinJialeZhaoJintaoLiuHongbao
High Technology Letters 2020年3期
关键词:孙权
SunQuan(孙权),TangTao②,ZhengJianbin**,LinJiale***,ZhaoJintao**,LiuHongbao**
(*School of Computer Science, Fudan University, Shanghai 200433, P.R.China) (* *China UnionPay Research Institute of Electronic Payment, Shanghai 201201, P.R.China) (* * *School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai 200240, P.R.China)
Abstract
Key words: payment fraud detection, graph computing, graph embedding, machine learning
0 Introduction
Payment has been evolving to a new era whereby the mobile Apps have taken a dominant role in many emerging areas. There are multiple big giants for payment in China including Alipay, UnionPay, etc. With the propensity of the payment mobile Apps, more and more individual users, merchants, and other players have entered this area, many persons are benefiting from the advanced and convenient mobile payment technology and business.
As a matter of fact, the payment giants have spent large amounts of investment in promoting their payment tools and one of the main promoting ways is to give discount or back cash to individuals who use their payment Apps when do purchase. The payment can either be fulfilled by online and offline, while the online especially mobile Apps are becoming the major channel to attract the public to get used to the new payment habit. The promotion naturally incurs the attackers including both individual users and merchants that take advantage of the promotion events to obtain extra rewards in an unjustified way. For example, the users may intentionally repeat 10 purchase on the same goods in a merchant, which can, in turn, get back cash from the payment service provider, and the user may share this reward with the merchant. In fact, such fraud has become the major concern for payment campaign, which can cause significant loss to payment service providers. As a result, how to effectively detect the underlying fraud makers (including both individual users and merchants) has been a hot research topic in literature, though many focused on other relevant but different domains. This work also focuses on this important problem, and conducts the empirical study on a major payment service provider in China, to verify the idea and the proposed technical approach. In general, this paper aims to make the following highlights:
• A graph computing-based approach is proposed for payment fraud detection, particularly in the setting of mobile Apps payment tools. The proposed approach is unsupervised and can work on large-scale transaction networks, whereby the nodes denote both individual users and merchants, and the edges denote the transaction records.
• Specifically, the proposed approach consists of the 2 main steps: the first step is to use graph computing to break the giant network into small communities, and the second step is to adopt data visualization to help the investigators pinpoint the risk nodes and edges in a certain time period.
• Case study with preliminary experimental results is provided on the real-world dataset from a major payment player in China. The results show that the proposed approach can effectively detect suspicious frauds on large-scale payment networks.
The rest of the paper is organized as follows. This paper discusses the related work in Section 1. The major technical approach based on network analysis is presented in Section 2. Case study and preliminary experiments are given in Section 3. Conclusion is in Section 4.
1 Related work
In this section, related work on fraud detection is presented. In particular, the review will cover different business area for fraud detection as well as the technical approaches including both supervised and unsupervised learning-based methods.
1.1 Fraud detection business requirements
Fraud detection has been a long standing task in financial related business. It ranges across multiple industry sectors and researchers from different disciplines have devoted considerable efforts.
One major business scenario is credit card fraud detection, whereby unlawful transactions by credit cards need be timely detected. Ref.[1] studied the fraudulent credit card transactions occurring among the retail companies in Chile whereby the association rule method is employed. In Ref.[2], the fraud detection score was specially focused to transform it to a probability, which is important for decision making in credit card risk management. Another typical and important sector is automobile. Ref.[3] proposed an expert detection system against the group of collective automobile insurance fraudulent activities. The entities involved in the car insurance fraud can be drivers, chiropractors, garage mechanics, lawyers, police officers, insurance workers and others. In the more recent Ref.[4] showed the fraud detection experience on large-scale e-commerce platforms, based on Alibaba’s large-scale computing system called Open Data Processing Service (ODPS). An anti-fraud system has been developed and verified on 2 large e-commerce datasets with the size of tens of millions of users and items, which is further deployed to Alibaba’s online business Taobao. Fraud can also happen in the online customer reviews, which are assumed to be unbiased opinion of other consumers’ experiences with the items or services. In fact, it is possible that the publishers, writers and vendors consistently manipulate online consumer reviews. And these manipulations can incur significant bias to the potential buyers such that the customers may purchase goods under misleading. To address this issue, Ref.[5] analyzed typical patterns of review manipulation and provided an empirical study on the real-world data from Amazon and Barnes & Noble. For telecom fraud detection, it has been a serious problem in many developing countries, e.g. China, and it is rather difficult to coordinate multiple agencies to avoid fraudulent activities thoroughly. Thus machine learning methods are applied in Ref.[6] to detect the fraudsters. More specifically, they proposed to use generative adversarial network (GAN)[7]based model to estimate the likelihood of a fraud transaction, as such the bank can take some measures to prevent monetary loss. The GAN based model shows promising results against traditional supervised learning models. In the setting of healthcare service, fraud detection has also been a central issue especially given the trend that more and more online payment channels are becoming available. For instance, Ref.[8] disclosed the typical online healthcare service delivery process in China. The fraudsters i.e. third party agents use software robots and script to obtain hospital appointments from the authorized platforms, and then the agents ask for unjustified high price to resell them to the true clients. To tackle this problem, they first use clustering based models to discover the potential user groups from agents, then the profile of user groups are extracted from the event sequence of the users to provide evidence for fraud detection. Moreover, a case study is deployed in a real-world hospital to show its effectiveness and reliability.
On the other hand, unsupervised models are developed and used for fraud detection, partly due to the lack of labeled samples for training an effective supervised model. Among them, clustering[9,10]is a mainly used technique. The clustering is usually performed on the user profiles to help identify the abnormal users, and the recent advance of deep network-based clustering techniques[11]can be of more help in this direction.
There are also some technically relevant work on abnormal detection and prediction. For temporal data, Ref.[12]showed a dictionary learning-based model for robust time series anomaly detection. While a more recent work[13]showed failure prediction using both event sequence and time series data. However, this technique can be difficult to be applied in the setting. The main reason is that fraudulent transactions at the individual level are a rare event, which can hardly form a long sequence of events across a long-time period, and so for time series. In addition, it is useful to predict fraud detection rather than detection after fraudulent transactions have happened. In this sense, the early risk prediction model of fraudulent transactions are needed, and there are also a line of work[14-17]on event prediction over time, based on statistical learning models. These directions involving more complicated models are left for future study, given more data can be collected as the business spans.
1.2 Fraud detection technologies
From the technical perspective, fraud detection has been a challenging task partly due to the fact that the supervised learning-based models call for enough positive samples including transactions, client individuals and merchants, in comparison with the normal samples. However, in fact, many frauds may happen without being detected hence the positive samples are often a subset of the true whole fraud samples set. This leads to the following problems: 1) the distribution of the positive samples (fraud) and negative samples can be biased; 2) the number of positive samples becomes even smaller as some are not detected, especially compared with those unlimited number of normal samples.
In literature, different methods are adopted for fraud detection in both supervised and unsupervised learning based ways. When supervision is given, as 2 rather popular machine learning methods, support vector machine (SVM) and Logistic regression (LR) have been applied in fraud detection. While in reality, supervision information is often difficult to acquire, in such cases, unsupervised methods have attracted lots of attention whereby clustering methods have been the dominant techniques.
1.3 Remarks
As discussed above, though fraud detection has been a long-standing problem in different financial areas while the study in the context of mobile payment Apps has not been fully explored. In particular, it is an emerging area and China has been one of the major countries for payment tools promotion. Hence it is motivated to take an in-depth study based on real-world business need (as one of the biggest payment players in the world) and rich transaction-related data. In the subsequent sections, a model based on network analysis whereby graph computing has been applied is proposed and case studies are given in detail.
2 Graph computing based approach for fraud detection
In this section, the graph computing based pipeline for fraud detection for unjustified profits will be discussed. The deployed method for building the transaction graph will be first described, whereby the graph computing procedure can be performed. This section also briefly discusses other alternative techniques that have been tried while not really adopted for stability and computational tractability issues.
2.1 Transaction network construction and processing
In the approach, the transaction network for the payments on a daily basis is built. An overview working flow of the transaction network processing and visualization is shown in Fig.1. The input transaction data is used to build the transaction network first, which is followed by filtering to remove some unimportant edges and nodes. Then community detection e.g. fast-unfolding (Fig.2) is performed to narrow down the study on relatively small communities. In the final stage, there are multiple ways of further analysis, including graph embedding (Fig.3), and rule driven community visualization (Fig.4) for fraud detection.

Fig.1 Working flow of the transaction network processing and visualization
2.1.1 Transaction network construction
Specifically, when there are multiple transactions in one day for a pair of nodes, e.g. between a user and a merchant, these transactions will be aggregated into one edge (or 2 directed edges if the direction is considered), whose attributes store the average transaction amount, mean transaction time, mean transaction between time, and the total number of transactions (in one direction). Note the above statistics can also be conducted on a longer period than one day, e.g. one week or month, which can be applied dependently.

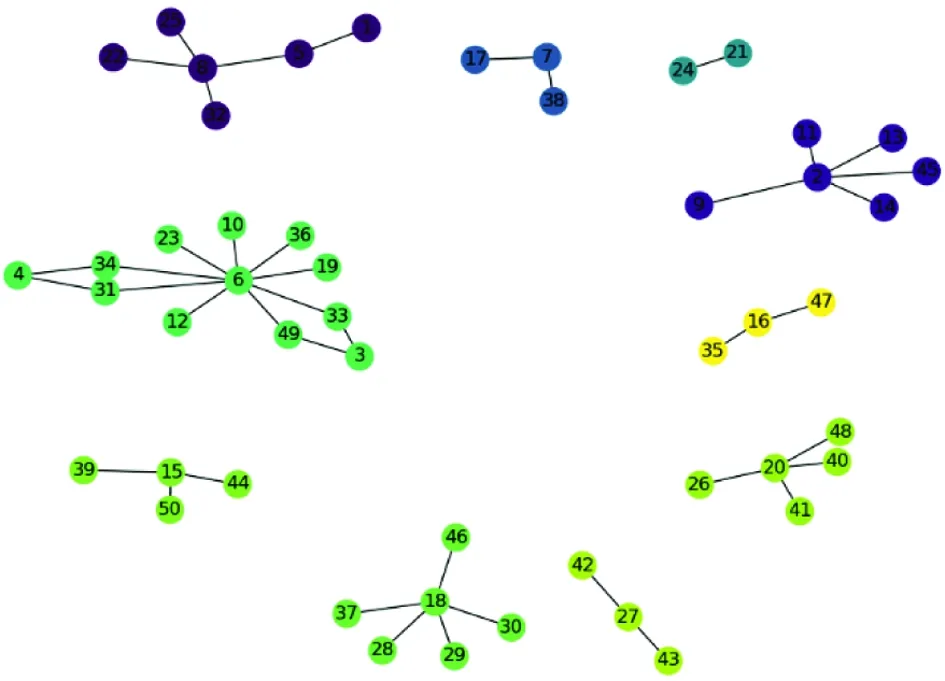
Fig.2 Illustration for network community detection e.g. via FastUnfolding[18]. The input raw network has been divided by the 3 detected communities by the FastUnfolding method

Fig.3 Network embedding on the detected community using node2vec[19] for merchants’ transaction networks
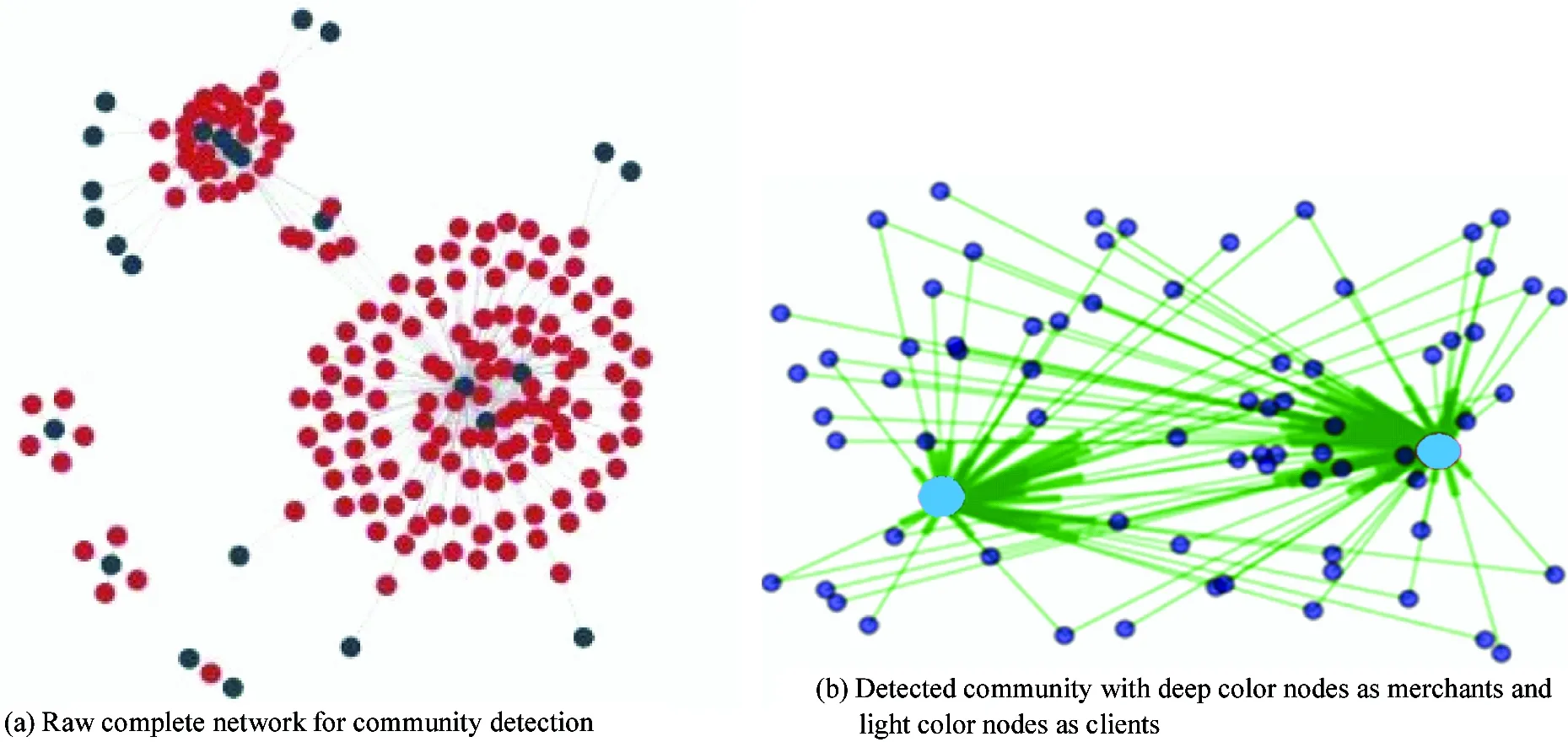
Fig.4 Network visualization and rule checking based on the detected community from the raw networks
2.1.2 Transaction network filtering
Then filtering is performed on the formed (aggregated) transaction network, whereby the typical filtering criterion includes the total transaction count, amount, discount, and the between time. The purpose of filtering is to reduce the size of the network by sparsifying its edges and removing some less important nodes. As such the whole network can be cut into a collection of sub-networks, each of which is of a reasonable size for further processing. The filtering mainly involves 2 steps: the first step is to remove the edges whose attributes as stated above are smaller than given thresholds. The nodes with a very limited number of out/in degrees will also be removed in the second step.
2.2 Fast community detection
Community detection can be applied on the filtered network as shown in Fig.2, to further break down the large-scale network into small sub networks. As such, more sophisticated measurements can be computed within a reasonable time period to quickly detect the risks. There are many available community detection algorithms, of which one popular method is FastUnfolding[18]. Here is a detailed description of FastUnfolding, whereby the modularity scoreQis defined as follows:
(1)
whereiandjindicate the 2 nodes in the network, andAi, jdenotes the weight between the 2 nodes. Whilecijdenotes the community ID that a node is tagged, and the delta functionδ(ci,cj) returns 1 if the 2 nodes are assigned to the same community; otherwise it is set 0.
• Initialization: label each node to different communities;
• For each node, label it to the community that one of its neighboring nodes belongs to, such that the corresponding modularity score by Eq.(1) is maximized. Then the differenceΔQcompared with the original modularity score is calculated;
• IfΔQ>0, accept the latest community division; otherwise, keep the original division;
• Repeat the above steps until the modularity scoreQcannot be improved anymore.
2.3 Detected community embedding and visualization
One popular method is to embed the community network into vectorized feature representation, for which the scalability issue need be particularly addressed for real-world applications. In fact, there are many new network embedding methods[19-21]which can convert graph vertex into a vectorized feature points in the new space. As such, traditional machine learning methods such as support vector machine, logistic regression and decision tree can be easily reused.
Another direct and powerful method for fraud detection based on the detected communities is visualization as will also be shown in the case studies. In general, in the detected community, the scale of the graph as well as the edge density is relatively small, hence it is easier to do graph visualization, whereby the bank card accounts and merchants can be shown in different colors to help the investigators quickly discern the abnormal patterns.
3 Experiments and case study
In this section, case study and preliminary experimental results on real-world payment data are provided. The data is collected from the major payment service player in China whose registered users have surpassed the number for 2 billion, and every day there are around 3 million transactions. In the proposed approach, the large-scale transaction network has been formed and graph based computing methods are used to detect the potential fraudsters. In consequence, subsequent followups can be taken to further verify the illness of the detected fraudsters.
3.1 Platform infrastructure
As the platform needs to support large-scale and efficient (sometimes even real-time) computing and storage, distributed system is used based on popular tools including Hadoop, HIVE, etc. The general overview of the infrastructure system is shown in Fig.5. The data is updated on a daily basis, whereby the daily records are stored on their respective nodes to ensure fast access and consistency. In addition, because the HIVE data warehouse is not friendly to interactive SQL query, the tool Impala is used for the more efficient query, which can achieve a speedup about 10 times.
3.2 Protocol
The proposed heterogeneous network involves individual users, merchants, as well as bank card for redistribution of the earned unjustified (monetary) credits.
3.3 Preliminary qualitative results
The network has been built by the definition of entities and their relationships. Then some particular sub networks can be visualized. Fig.6 shows 4 typical cases for fraudulent conspiracy among the merchants, individual users with their payment account and the bank card for monetary redistribution. More specifically:
• In Fig.6(a), there are 2 central merchants (in light color) to which many payment transactions have been conducted from a large number of individual users (in dark color), and it can be easily discovered that these 2 merchants have high risk for fraudulent behavior and appropriate measures can be taken to perform further investigation on the 2 merchants and the relevant individual accounts.
• In Fig.6(b), many individual users pay to the merchant at the promotion period, such that they receive discount or backcash from the payment service provider. And the merchant gets back the unjustified fraud money from the users by a certain ratio, e.g. 50 percentages.

Fig.5 Overview of the infrastructure system for graph computing based fraud detection on the transaction network

(a) Two fraudulent merchants (in light color) and their associated users(in deep color), best viewed in color

(b) Fraudulent patterns by the suspect single bank card for money redistribution (in light color), the users (in deep color) and the merchant (in black)

(c) Fraudulent patterns by the suspect multiple bank cards for money redistribution (in right nodes), the users (in midnodes) and the merchant (in left nodes)

(d) Group fraudulent patterns formed by the suspect redistribution bank cards (in left nodes), the users (in midnodes) and the merchant (in right nodes)
• While in the example of Fig.6(c), there is no explicit merchant in the network, while the bank cards have an active link with many shared users in a short time period. This suggests the potential fraud group among these entities, such that the earned backcash may be redistributed through this network.
• In the 4th example as shown in Fig.6(d), there are also only 4 merchants which have attracted many transactions within a group of users. In addition, there are multiple bank cards for redistribution of the money, this scenario is often more difficult to detect as more entities are involved.
The network embedding using the node2vec method[19]on a segmented network of merchants is also used. In this way, each merchant is represented by a feature vector. For the convenience and effect of the display, 50 merchants and their associated users project their feature representation further into the 2D plane. The edges in the projected network are created by certain means of the common clients shared by the 2 merchants (when the number exceeds a certain threshold). As shown in Fig.7, on the left, the raw network shows multiple clustering pattern regarding connected components, and such clustering behavior is well preserved in the projected 2D space on the right. This result shows the effectiveness of the adopted node2vec method.
(a) The input networks with 10 connected components in different colors
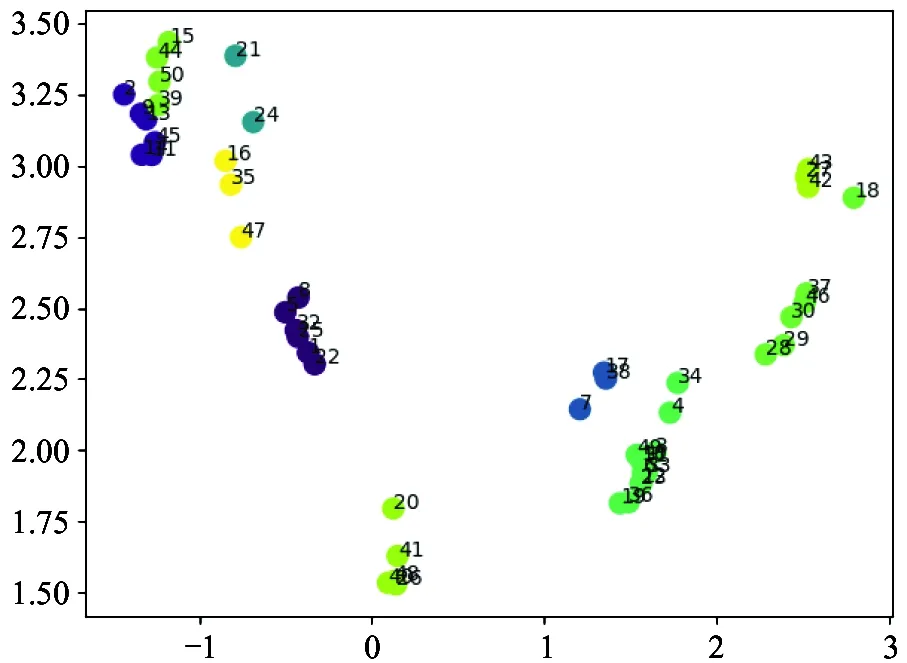
(b) The projection on 2D plane from the embedded feature
3.4 Summary and discussion
This paper gives 4 typical cases of fraud pattern which are extracted from a series of network processing including raw transaction network construction based on daily records aggregation, transaction network decomposition based on edge and node filtering and community detection to focus on suspicious networks based on data visualization.
4 Conclusions
This paper proposes a principled and effective approach for automatic payment fraud detection in the context of individuals and merchants, whereby a payment transaction network can be established for further analysis of the payment behavior to find suspicious fraud transactions and their latent individuals and merchants in an unsupervised learning manner.
Specifically, this paper develops a network analysis method to discover the abnormal patterns of transactions over the network in a certain period of time. The design is based on the fact that little labeled data samples are available and there also lacks systematic rules for summarizing the behavior of fraud.
There are many possible directions for future work. First, in this paper, an unsupervised approach is mainly adopted due to the lack of labels for fraud merchants and individuals. While as the data accumulates, more labels can be obtained and then it is possible to develop supervised learning methods such as decision tree and deep neural networks. Second, fusing multiple networks with different definitions to form a more effective detection pipeline is future direction. For this need, graph matching, especially for multiple graph matching[22,23], and online graph matching[24], can be a possible solution infusing networks with corresponding structures. Third, recently there are many temporal models for behavioral modeling, and one of the promising technique is the so-called temporal point process[25]. A variety of temporal point process models has been witnessed, ranging from classic parametric models[14]to nonparametric models[26]and to deep network based approaches[27-29]. What’s more, combining two-way exploration[30], GAN[31]with the proposed method is one of the future directions. Last but not least, how to learn an interpretable behavioral model[32,33]over time is also the immediate interest.
猜你喜欢
小天使·四年级语数英综合(2021年10期)2021-10-20
情感读本·道德篇(2018年1期)2018-01-31
读书文摘·经典(2018年1期)2018-01-10
儿童故事画报(2017年9期)2017-10-09
做人与处世(2017年12期)2017-07-27
环球人物(2017年11期)2017-06-10
高中生·青春励志(2014年8期)2014-09-21
大众考古(2014年9期)2014-06-21
文苑·感悟(2014年3期)2014-03-28
决策(2010年7期)2010-08-04
 High Technology Letters2020年3期
High Technology Letters2020年3期
- High Technology Letters的其它文章
- A novel flow control scheme for reciprocating compressorbased on adaptive predictive PID control①
- MSONoC: a non-blocking optical interconnection network for inter cluster communication①
- Research on full-period acquisition method for diesel enginebased on self-adaptive correlation analysis①
- PRF: a process-RAM-feedback performance model to revealbottlenecks and propose optimizations①
- Research on robust control strategy of single DOF supporting systemof MLDSB based on H∞ mixed-sensitivity Method①
- Research on oil film characteristics of piston pairin swash plate axial piston pump①