
一种基于YOLO 的交通目标实时检测方法∗
2020-11-02 09:00王思雨TanvirAhmad
计算机与数字工程 2020年9期
王思雨 Tanvir Ahmad
(华北电力大学控制与计算机工程学院 北京 102206)
1 引言
近年来,我国城市道路建设规模日益扩大,城市交通需求逐步增加,交通道路拥堵、交通事故猛增已成了交通管理部门所关注的重点问题[1]。随着大数据、云计算、移动互联网等技术的迅速发展,“互联网+”概念已经引起了各行各业的高度重视。“互联网+交通”[2]是将互联网新技术应用到智能交通领域,如通过传感器、通讯设备、光学影像设备等,使得机器能够识别车辆、行人、信号灯等一系列交通目标,从而为智能交通提供基础设施。人工智能[3]作为当下最火爆的科技之一,在车辆颜色、车牌识别、无牌车检测方面应用已经比较成熟。目前已经有许多大型公司投入大量资金,致力于自动驾驶汽车的研究。然而,如何能够提高车辆安全性能,提高交通目标检测准确率和检测速度是实现无人驾驶的关键。
基于上述背景介绍,交通安全问题是实现自动驾驶需要考虑的首要问题。因此,在进行交通目标检测任务时,如果可以在保持实时检测速度的情况下,还能够大幅提升检测精度,对自动驾驶技术而言是一项重要举措。本文将YOLOv3 应用于车辆、行人等交通目标检测[19],与YOLOv2 相比能够大幅提升检测精度。
2 目标检测
传统的交通目标检测技术包括基于雷达、超声波、红外线等传感器检测方法[4]。其中基于雷达的目标检测是根据雷达发射的电磁波来探测车辆目标位置;而基于超声波的目标检测无法检测低速行驶车辆;基于红外线的检测方法抗干扰能力低。随着社会的发展,视频采集设备的价格越来越低廉,采集图像的质量越来越高,基于计算机视觉[5]的目标检测技术逐渐兴起。早期的图像检测技术是根据图像的颜色[6~8]、纹理、图形特征模型[9~10]等一系列特征变化来完成特征提取。Liu et al.[11]提出了一种新的单个视频对象提取的半自动分割方法。受Hubel 和Wiesel 对猫视觉皮层研究启发,有人提出卷积神经网络[12]。Yann Lecun[13]是最早将CNN 用于手写数字识别,并一直保持了其在该领域的霸主地位。2012 年ImageNet 竞赛冠军获得者Hinton 和他的学生Alex Krizhevsky 设计了AlexNet[14]。VGG⁃Net[15]是 牛 津 大 学 计 算 机 视 觉 组 和Google Deep⁃Mind 公司的研究员一起研发的深度卷积神经网络。GoogLeNet[16]是2014 年Christian Szegedy 提 出的一种全新的深度学习结构。ResNet[17]在2015 年被微软亚洲研究院何凯明团队提出,ResNet 有152层,除了在层数上面创纪录,ResNet 的错误率也低得惊人。2015 年,Redmond J 提出了一种全新的端到端的目标检测算法——YOLO[18]。YOLO 借鉴了GoogLeNet 的分类网络结构。相比其他的检测网络,它能够达到45f/s的检测速度。
在自动驾驶系统中,目标检测任务主要是预测目标类别以及目标位置。现有的基于CNN 的目标检测方法,大多第一步是先提取感兴趣的区域候选框,然后利用卷积神经网路提取区域特征,最后将提取的区域特征送入分类器进行分类。与其他目标检测方法不同的是,YOLO 运行一次神经网络就可以得到预测边框以及所属类别,而不是区域候选框提取之后再进行分类。这样做的结果就是提高了检测速度,但以牺牲精度为代价。到目前为止,YOLO 已经经历了两次版本的更迭,最新版是YO⁃LOv3。
3 YOLO原理
3.1 YOLOv1
目标检测任务主要是分类。在YOLO 之前的目标检测方法主要是通过区域建议产生大量可能包含目标的候选框,再使用分类器进行分类,判断候选框中是否含有待检测目标,并计算目标所属类别的概率。而YOLO 是一个端到端的目标检测框架,它把目标检测任务当作回归问题来处理,通过一次图像输入就可以同时得到预测边框的坐标、边框包含目标的置信度,以及所属类别的概率。由于YOLO 实现目标检测是在一个神经网络里完成的,因此,检测目标更快。选出预测框的位置以及其含有目标的置信度和属于目标类别的可能性。
如图1 所示,YOLOv1 的核心思想是将每个图像划分成S×S 的网格。每个网格预测B 个边界框,和C 个类别概率。每个边界框负责预测目标中心位置和大小x,y,w,h,以及置信度共5 个变量。其中x,y 表示预测边界框的中心落在当前网格的相对位置。w,h 表示边界框的宽和高相对整个图像的比例。置信度则反映了目标位置预测的准确性。其计算公式如下:
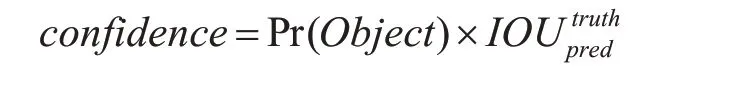
如果有目标中心落到一个网格中,公式右边第一项Pr(Object)取1,否则取0。第二项IOU 指的是预测边框和真实标注边框之间的重叠度。网络模型最后的输出维度为S×S×(B×5+C)。
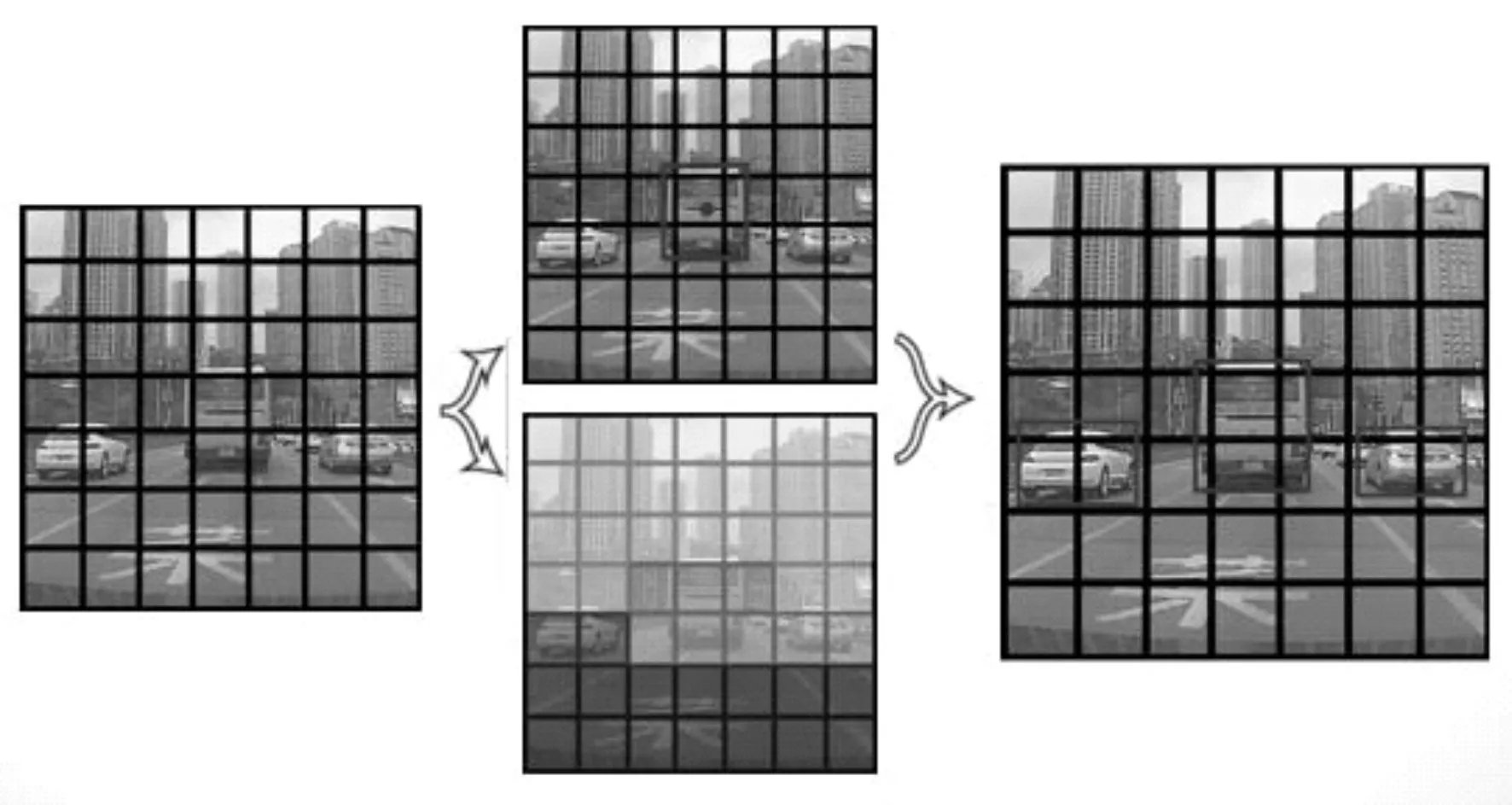
图1 YOLOv1 思想模型
检测目标时,由以下计算公式得到每个网格预测目标类别的置信度得分。
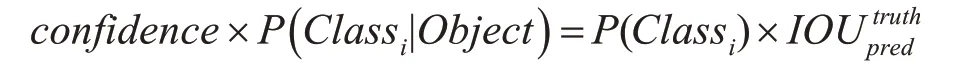
最后通过非极大值抑制,如图2 所示。过滤掉得分低的预测框,从而确定预测目标的最终位置。而置信度得分用来判断目标所属类别。
以VOC 数据为例,YOLOv1 采用7×7 网格,每个网格预测两个边界框。因为VOC 数据集待检测目标有20 个种类,所以输出张量为7×7×(2×5+20)=30,YOLOv1检测网络包括24个卷积层和两个全连接层。YOLOv1 借鉴了GoogLeNet,但是与之不同的是,YOLOv1 使用1×1 和3×3 的卷积核代替了GoogLeNet的inception module。

图2 非极大值抑制
YOLOv1 相比其他基于CNN 的网络模型而言很好地提升了检测速度,但是由于YOLOv1 的检测机制使得一个网格只能预测一个目标,此时,如果有两个物体同时落入一个网格,就会使得漏检率比较高,而且一幅图像只预测98 个边界框,对于目标定位误差较大。
3.2 YOLOv2
YOLOv2[20]则参考了YOLOv1 和SSD[21]的网络结构,采用类似VGG16 的网络结构,多次使用3×3卷积核,并且在每一次池化操作之后都会把通道数翻倍。网络使用全局评价池化,把1×1 的卷积核置于3×3 的卷积核之间,用来压缩特征。最后得到Darknet-19 的基础网络模型,其中包含19 个卷积层和5 个最大池化层。但是Darknet-19 计算量要比VGG16 小得多,在ImageNet[22]分类top-1 准确率能够达到72.9%,top-5准确率达到91.2%。
YOLOv2把初始输入图像分辨率由224×224提高到448×448,使得高分辨率的训练模型mAP 获得4%的提升。其次由于YOLOv1 最后使用全连接层预测边框和分类,导致丢失许多空间信息,导致定位不准确,YOLOv2 借鉴了RPN 中anchor 的思想,在卷积层使用下采样,使得416×416 的输入图像最终得到13×13 的特征图,最终预测13×13×9 个边框,大幅度提升了目标检测的召回率。YOLOv2 还改进了预测边框的方法。使用K-Means 聚类方法训练边框。而传统的K-Means 方法使用的是欧式距离,这意味着大的边框会比小边框更容易产生误差。因此,作者提出使用IOU 得分来评判距离大小。使得预测的边框更具代表性,从而提升检测准确率。YOLOv2采用SSD使用不同的特征图以适应不同尺度目标的思想,对原始网络添加了一个转移层,把26×26×512的浅层特征图叠加成13×13×2048的深层特征图,这样的细粒度特征对小尺度的物体检测有帮助。最后,YOLOv2 还结合单词向量树方法,能够检测上千种目标,虽然对本文检测任务来说参考意义不大,但这对多目标检测任务来说也是一个很大的突破。
3.3 YOLOv3
YOLOv3[23]相对于YOLOv2 的改进主要体现在多尺度预测。对坐标预测和YOLOv2 一样使用的维度聚类作为anchor boxes来预测边界框。在训练期间,使用平方误差损失的总和,这样计算快一些。对于类别的预测,YOLOv3再使用Softmax进行分类,而是每个边框通过逻辑回归预测该边框属于某一个类别目标的得分,这样可以检测一个目标属于两个标签类别的情况。对于跨尺度预测,主要是为了适应不同尺度的目标,使得模型更具有通用性。尤其对小目标的检测,精度有了很大提升。YOLOv3 采用了Darknet-53,网络结构相比YO⁃LOv1和YOLOv2稍大了一些,但是准确度提高了很多,尤其是对小目标的检测精度有了很大提升。并且在实现相近性能时,YOLOv3 比SSD 速度提高3倍,比RetinaNet速度提高近4倍。
4 实验与结果分析
本实验环境的操作系统是Ubuntu16.04,所有实验都是在GPU 的配置下完成的,INVIDIA 显卡型号GTX1070,显存8G。使用到的开发包有CUDA、cuDNN 以及OpenCV。OpenCV 是为了将检测结果可视化。
实验数据是根据车载摄像头捕捉的交通道路视频,利用视频分帧软件得到静态图像。并对其进行手工标注。其中用于车辆、行人、非机动车的数据集有40765张图像。
4.1 实验指标
本实验将现有的数据集划分成图像数量分别为6500、13000、19500、26000、32500、39000 的6 个不同大小的训练数据集,其余1765 张图像用作测试集。通过设定不同参数,得到多个训练模型。通过计算平均精度(AP)作为衡量模型的指标。
在本实验中,通过计算预测边框与真实边框的交并比(IOU),一般认为只要满足下述条件的就是正确的检测结果,称为正样本。
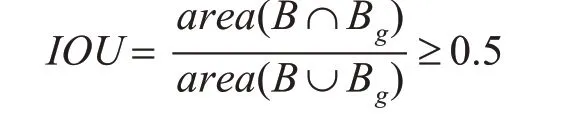
其中B 为检测模型预测的边框,Bg为人工标注的目标真实边框。
为了计算AP值,我们需要知道以下几个概念:

表1 正负样本概念
其中,准确率(Precision)的计算公式为


图3 准确率-召回率曲线图
如图3 所示,准确率-召回率(PR)曲线是根据对应的准度率召回率曲线绘制的。而AP 则是PR曲线下的面积值,可以通过准确率和召回率计算函数积分得到,计算公式如下:
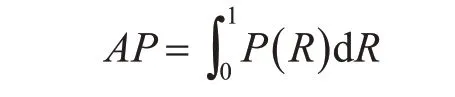
有时候为了评估模型的整体性能,需要对所有目标的AP求平均值得到mAP。计算公式为

其中,N是待检测目标类别个数。
4.2 实验结果和分析
本文使用YOLOv3和YOLOv2分别在训练集上训练模型,检测车辆、行人和非机动车三类目标。如图4 所示,是在39000 的训练集以及45000 次迭代次数的情况下,三类目标分别在YOLOv3 和YO⁃LOv2 训练模型得到的AP 值。显然,改进了的YO⁃LOv3 要比之前的检测框架精度有了大幅提升。如图5 所示,YOLOv3 对于交通目标检测的mAP 明显高于YOLOv2。而YOLOv3 检测速度相比YOLOv2减慢了1/3,如图6所示,YOLOv3和YOLOv2训练模型分别对1765 张测试集图像进行测试所耗费的时间,均达到了每秒30 帧以上的检测速度。这对于实时的目标检测任务也是足够的。因此,选择YO⁃LOv3实现交通目标检测任务再合适不过。
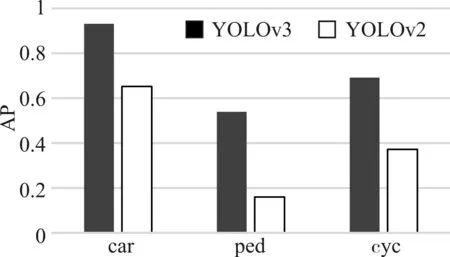
图4 两种方法的AP

图5 两种方法的mAP

图6 两种方法的检测时间
图7、图8、图9 是通过YOLOv3 在不同数据集上训练不同模型测试的结果。图中展示了对于同一类检测目标,数据集的规模大小以及迭代次数的多少对目标检测精度AP的影响。通过对比三类不同的目标发现,不同的数据集对于车辆的检测精度变化并不大,而对于行人和非机动车而言,6500 的训练集确实检测效果不佳。因此,大量的数据训练还是有必要的,随着数据集规模的增加,检测精度明显呈上升趋势。
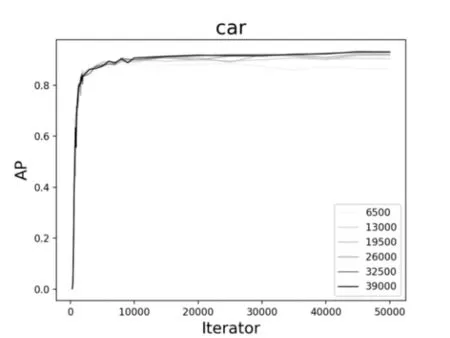
图7 不同数据集下car的AP变化曲线图
如图10、图11、图12 所示,对于同样的训练数据集,当迭代次数增加到1000 次左右的时候,AP有一个较为明显的变化,这是因为当训练模型迭代到1000次左右时loss收敛较快。其次,对于车辆而言,随着迭代次数的不断增加,AP已逐渐趋近于1,从统计结果来看,迭代次数增加对车辆的检测精度提高并不明显。而对于行人和非机动车而言,AP还有很大上升空间,从图中的趋势也可以看出,如果继续增加迭代次数,对ped 和cyc 的检测精度还是可以继续提高的。

图8 不同数据集下cyc的AP变化曲线图
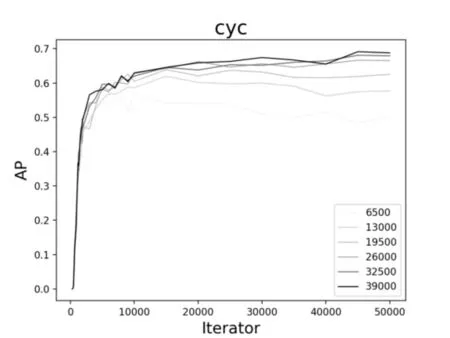
图9 不同数据集下ped的AP变化曲线图
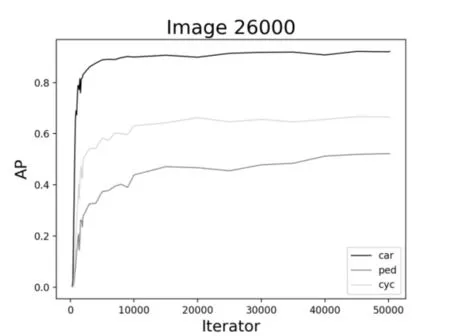
图10 26000数据集时AP的变化曲线
进一步综合图7~12,可以看到,对于车辆、行人和非机动车的检测结果是不同的。对于车辆的检测,AP 最高达到93%左右,而对于行人,AP 最高也才55%左右。究其原因可能有二:一是,在所有的数据集中,目标分配极不均衡;这也提醒我们在基于YOLO 的深度学习训练中以后要尽量保持目标均衡,效果则较好。二是,车辆特征比较明显,而行人和非机动车特征变化多端,再加上交通道路场景复杂,对于行人的检测精度还有待提高。
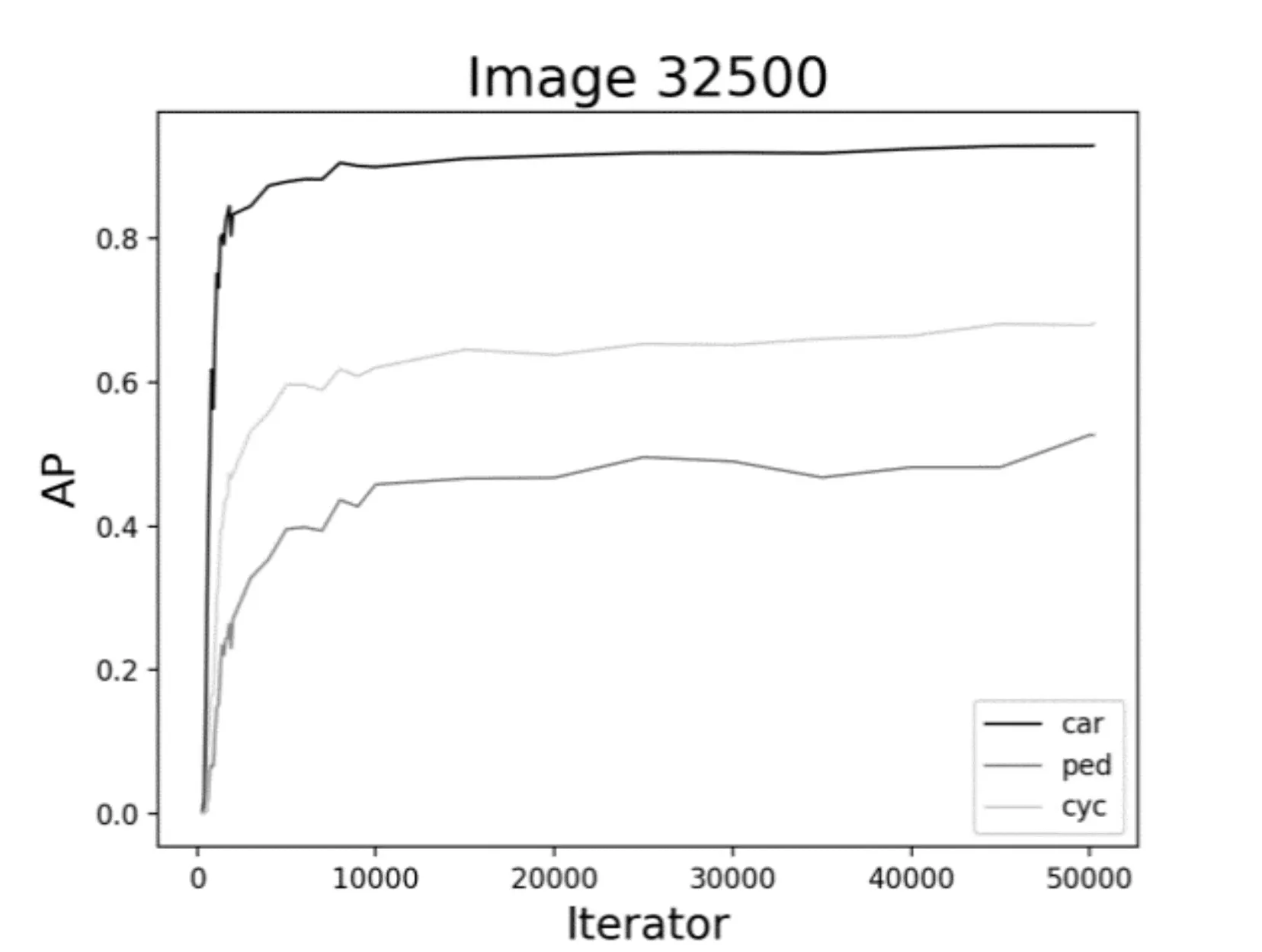
图11 32500数据集时AP的变化曲线
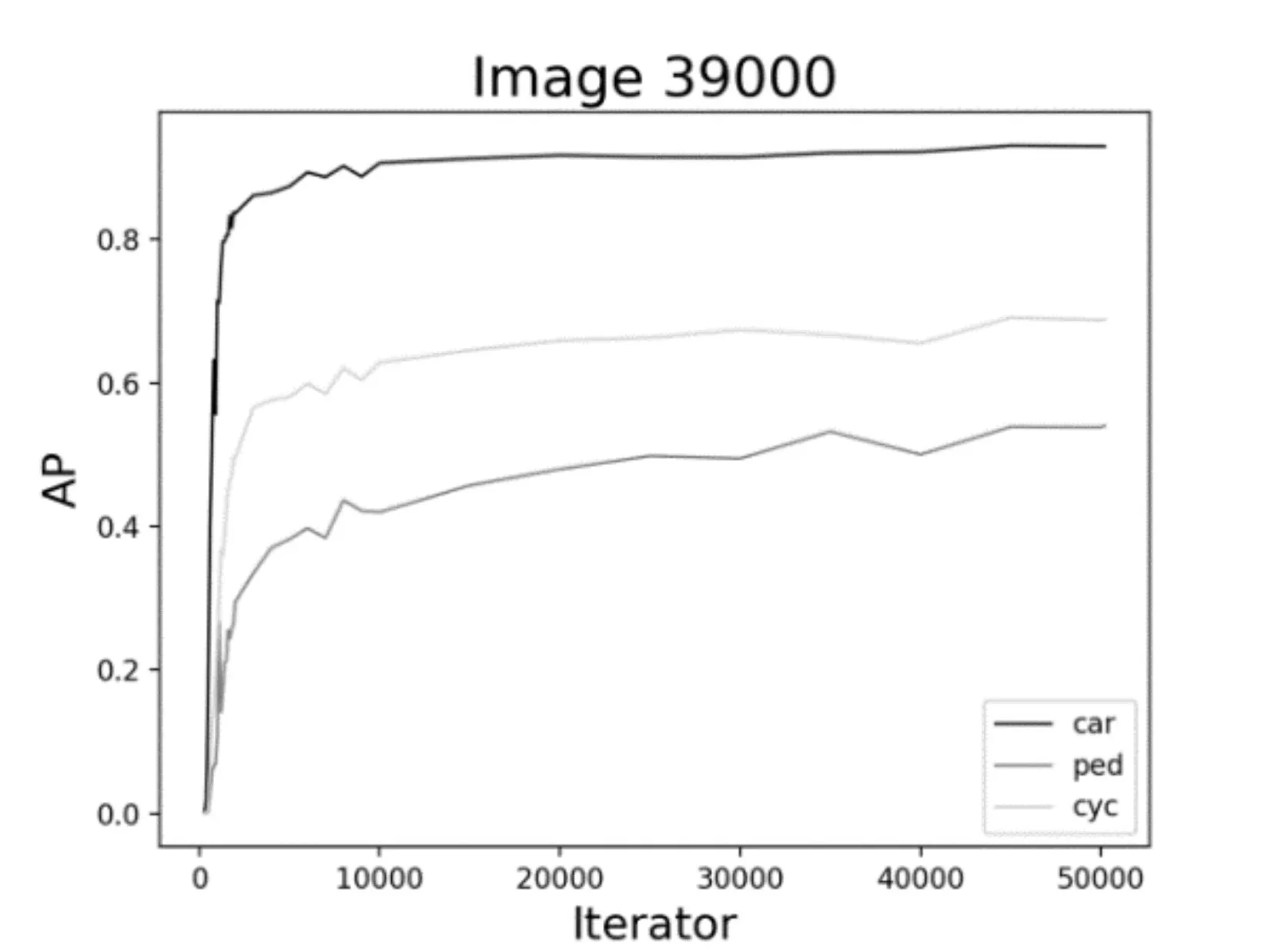
图12 39000数据集时AP的变化曲线
5 结语
本文通过在YOLOv3 和YOLOv2 上对比实验,验证了YOLOv3 应用于交通目标检测精度确实要比YOLOv2 高出很多。YOLOv3 在不同数据集和迭代次数的各种组合情况下,表现出了训练集越大,迭代次数越多,检测精度越高的特性。并且能够保证检测的实时性。尽管YOLOv3 检测精度已经有了很大提升,但是,还没有达到百分百准确的程度。由于无人驾驶与人类生命息息相关,因此,在图像目标检测应用在无人驾驶领域的方法还不够成熟,检测精度还有待提高。下一步考虑如何能够平衡不同目标的检测准确度,将模型泛化,使其能够应用到更多的领域中。并将加入和其他目标检测方法的对比,验证YOLO 在交通目标检测领域的有效性及高效性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
小雪花·成长指南(2016年9期)2016-10-12
消费电子(2015年7期)2015-12-11
读者(2010年8期)2010-08-30
