
基于分支深度强化学习的非合作目标追逃博弈策略求解
2020-11-06 06:44刘冰雁叶雄兵高勇王新波倪蕾
航空学报 2020年10期
刘冰雁,叶雄兵,高勇,王新波,倪蕾
1.军事科学院,北京 100091 2.解放军32032部队,北京 100094 3.航天工程大学,北京 101416
航天器与非合作目标的空间交会,是最优控制与动态博弈的深度融合,可描述成一种追逃博弈问题[1-3]。从航天器视角看待的追逃博弈(Pursuit and Evasion Hames,PEG)问题[4],是在仅知自身状态和非合作目标当前有限状态、未知非合作目标未来行为策略的条件下,采取最优行为并最终完成交会任务的一个动态博弈过程。
追逃博弈问题中的非合作目标,除了在一个连续且动态变化的空间环境中活动外,还具有典型的非合作性,即有信息层面不沟通、机动行为不配合、先验知识不完备等特性。针对此类双方连续动态冲突、对抗博弈问题,可通过微分方程,运用微分对策[5-6]进行数学描述。文献[7]应用微分对策理论描述了两个航天器追逃中的策略问题,并将对策研究转化为高维时变非线性两点边值问题进行数值求解。文献[3]将卫星末端拦截交会看作追踪与逃逸,并转换为零和微分对策问题,采用拦截脱靶量和燃料消耗作为二次最优目标函数,推导出了卫星轨道次优控制策略。文献[8]针对三维空间中的航天器追逃博弈问题展开研究,结合微分对策理论,得出了追踪器的最优控制策略描述式。文献[1]利用定量微分对策方法分析连续推力作用下的空间交会追逃微分对策问题,提出了用非线性规划求解该微分对策问题的方法。文献[9]对航天器追逃博弈问题运用微分对策进行描述,采用半直接配点法进行求解,可得到收敛的数值解。
关于追逃博弈问题的微分对策求解,因其涉及微分方程复杂、约束条件呈非线性、状态变量多,一直是一项比较困难而棘手的问题[10-11]。随着以深度强化学习[12]为代表的新一代人工智能方法快速发展,依其在自主学习、自我优化方面的优势,处理决策控制问题不受任务模式限制,已在军事、计算机、交通等领域广泛运用,并取得了显著成效[13]。文献[14]阐述了将深度学习和强化学习为代表的机器学习技术引入博弈对抗建模,提出了基于深度强化学习的智能博弈对抗概念,进一步探索了智能化控制决策。文献[15]将水面复杂的障碍规避问题转换为零和博弈问题,提出了一种基于模糊分类的深度强化学习方法,满足动态决策任务和在线控制过程的需求。文献[16]针对障碍物动态规避问题,将深度强化学习与优先重放模式相结合,能够依据经验对当前状态进行行为预测,从而降低运算量、提升成功率。文献[17]为提高准被动双足机器人斜坡步行稳定性,提出了一种基于深度强化学习的准被动双足机器人步态控制方法,实现了较大斜坡范围下的机器人稳定步态控制。
尽管这些研究使得深度强化学习算法在控制决策领域得以应用,但在连续空间应用中仍面临与表格强化学习相类似的问题,即需要显式表示的操作数量随着操作维数的增加呈指数增长。鉴于深度强化学习在控制决策方面的潜力和目前在连续空间的应用限制,针对与非合作目标的空间交会问题,本文提出了一种基于分支深度强化学习的追逃博弈算法,以获得与空间非合作目标的最优交会策略。
1 航天器与非合作目标的动力学模型
在二体模型中,把中心天体作为参考点,以P表示在轨航天器、E表示非合作目标,两者空间位置关系如图1所示。图中,以同轨道平面内的一参考星作为坐标原点O,参考星与中心天体连线方向为x轴,轨道平面内沿轨道速度方向为y轴,z轴垂直于转移轨道平面与x轴、y轴构成右手系。航天器与非合作目标相对距离远小于非合作目标轨道半径,其动力学模型可描述为
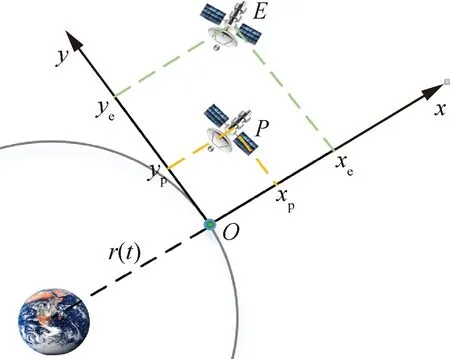
图1 航天器与非合作目标对策的坐标示意图Fig.1 Coordinate frame sketch of spacecraft and non-cooperative target
(1)
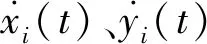
在生存型微分对策[18]中,航天器与非合作目标均采取最大推力,双方实际行为控制量为推力方向角,即up=[θp,δp]、ue=[θe,δe]。
将航天器与非合作目标的交会问题,描述为追逃博弈问题,需具备以下3个要素:博弈参与者N={P,E},各参与者行为up、ue,以及参与者的目标函数J。
在追逃博弈的目标函数中,考虑两者之间的欧式距离
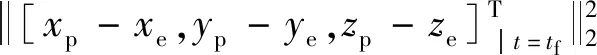
(2)

对于连续推力,燃料消耗与推力作用时间成正比,推力作用时间越长,燃料消耗越多。因此,将推力作用时间间隔作为追逃博弈目标函数的一部分,构建时间-距离综合最优控制的目标函数
(3)
式中:k为比例权重,且k∈[0,1]。
在追逃博弈过程中,航天器与非合作目标分别根据当前状态,通过独立优化目标函数J来采取行为。其间,航天器将力求获得使目标函数J最小化的行为策略,而非合作目标则期望获得使目标函数J最大化的行为策略。根据博弈论中的纳什均衡[19-20]理论,双方行为当且仅当满足不等式(4)时,行为策略达到纳什均衡
(4)
为了使该追逃博弈问题存在纳什均衡解,假设满足下列条件:“行为策略集up与ue是度量空间中的紧集,目标函数J:up×ue→R在up×ue上连续”[21]。再根据比较原理[22]可知,若在一个追逃对策中存在不同的最优策略,那么所有最优策略对应的对策值均相同[23]。
由此,求解该追逃博弈问题的目的,就是要寻求一组行为策略满足纳什均衡,即使得式(5)成立
(5)
航天器通过求解上述最优化问题,得到追逃博弈问题的纳什均衡行为,从而实现与非合作目标的最优交会。
2 空间行为的模糊推理模型
航天器与非合作目标交会是在连续状态空间进行,然而传统的深度强化学习算法可能会由于其难处理性、连续状态空间和行为空间庞大而导致维数灾难问题[24]。为避免这一问题,根据“模糊推理是一种可以任何精度逼近任意非线性函数的万能逼近器”[25]这一结论,本文构建了一种空间行为的模糊推理模型,以实现连续状态经由模糊推理再到连续行为输出的映射转换,从而有利于发挥深度强化学习的离散行为算法优势。
零阶Takagi-Sugeno-Kang(TSK)[26],作为最常用的模糊推理模型,在通过隶属函数(MF)[27]表征连续状态空间或行为空间后,利用IF-THEN模糊规则可以获得模糊集到输出线性函数之间的映射关系[28]:
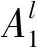
THENul=cl
(6)

图2展示了当输入量n=2、隶属函数y=3时的空间行为模糊推理模型。该模型为5层网状结构,其中以小圆圈表示变量节点,以小方框表示运算节点。推广到一般情况,假设有n个连续空间变量xi(i=1,2,…,n)作为输入,在对每个变量xi运用y个隶属函数处理后,再经过模糊化与去模糊过程便可获得精确输出u,其中各层功能如下所述。

图2 空间行为的模糊推理模型Fig.2 TSK fuzzy inference model
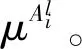
(7)
在网络第3层,为实现加权平均去模糊化,对隶属度进行了归一化处理
(8)
在网络第4层,引入模糊集中心常数cl,对在每一个节点进行点乘运算
(9)
在网络第5层,对节点进行累计处理,便可将模糊量转换成精确量[31]
(10)
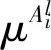
(11)
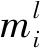
3 追逃博弈的分支深度强化学习
深度强化学习(Deep Reinforcement Learning),虽是神经网络与强化学习的有效结合,但直接运用于空间行为模糊推理模型,却会面临行为数量与映射规则的组合增长问题,这大大削弱了离散化处理后的行为控制决策能力。此外,值函数的朴素分布以及跨多个独立函数逼近器的策略表示同样会遇到许多困难,从而导致收敛问题[32]。
为此,本文提出了一种新的分支深度强化学习架构。将状态行为值函数的表示形式分布在多个网络分支上,通过多组并行的神经网络以实现离散行为的独立训练与快速处理;在共享一个行为决策模块的同时,将状态行为值函数分解为状态函数和优势函数,以实现一种隐式集中协调;给出航天器与非合作目标的博弈交互过程,经过适当的训练,可实现算法的稳定性和良好策略的收敛性。
3.1 多组并行的网络分支
依据空间行为模糊推理模型中L条规则,将状态行为值函数的表示形式分布在多个网络分支上,搭建L组并行的神经网络。多组并行的神经网络,是在单个神经网络基础上增加了多组并行神经网络。与单组神经网络[33]类似,并行神经网络在与环境的不断交互中自主训练、独立决策。结合强化学习的博弈和反馈机制,将使得多组并行神经网络具有更强的自主性、灵活性和协调性,极大地提升了离散行为的独立学习能力,整体增强了对环境的探索能力。
分支深度强化学习架构中的多组并行神经网络如图3所示。其中,各组神经网络均由输入层、隐藏层和输出层组成,当状态信息分别输入L组并行神经网络后,独立通过激励函数进行前向传输以及进行梯度下降反向训练,输出可获得离散行为的状态行为函数(简称为q函数)。
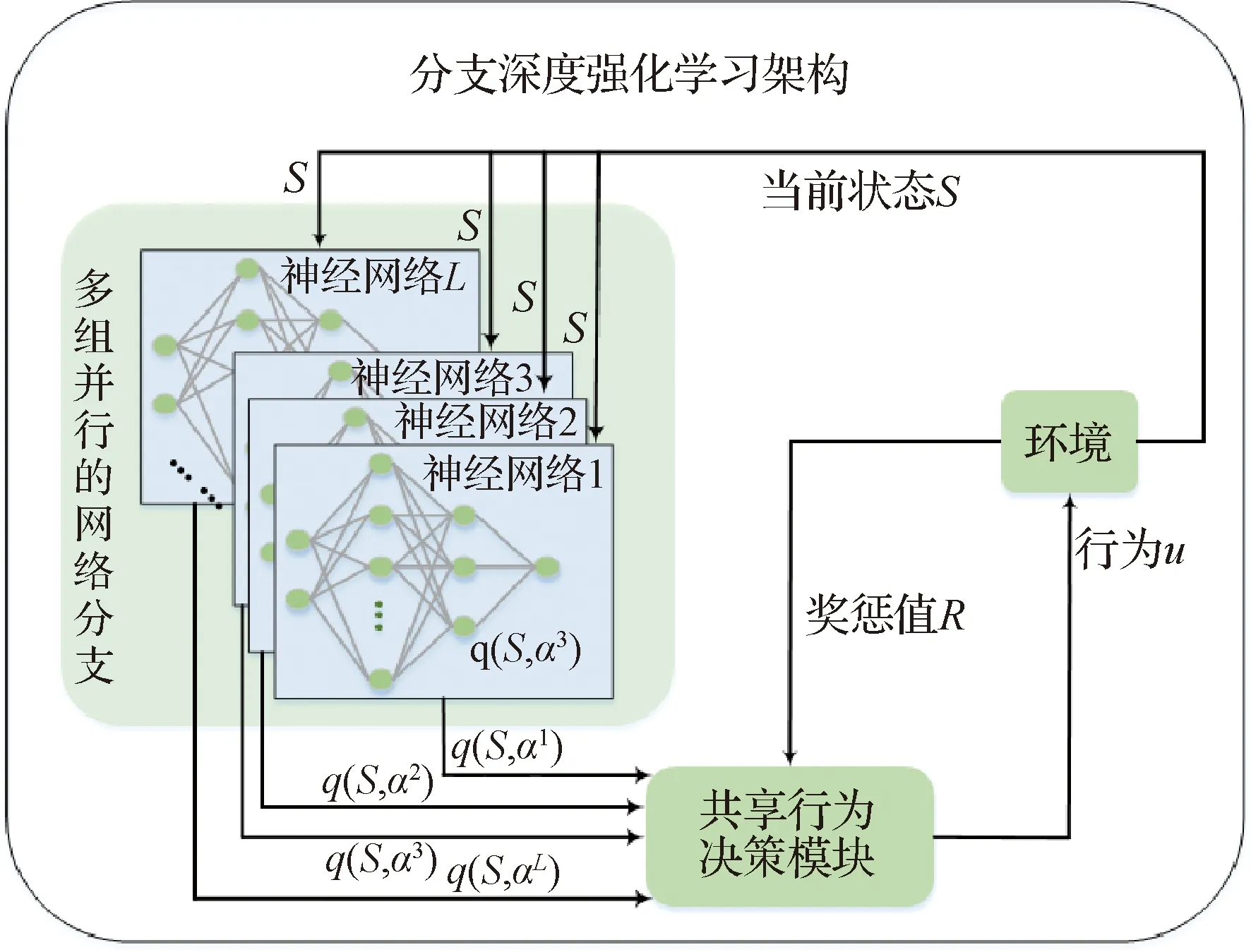
图3 分支深度强化学习架构示意图Fig.3 Schematic diagram of branching deep reinforcement learning architecture
3.2 共享行为决策模块
对于具有n个输入量和y个隶属函数的模糊推理模型,直接使用传统强化学习算法,则需要同时考虑yn个可能的q函数。这使强化学习算法在多离散行为应用中变得棘手,甚至难以有效探索[34]。
本文在所构建的共享行为决策模块中,对传统强化学习算法进行了改进。如图4为基于改进强化学习的共享行为决策示意图,其主要思想是将多组并行神经网络计算输出的q函数分解为状态函数和优势函数,以分别评估状态值和各独立分支的行为优势,最后再通过一个特殊的聚合层,将状态函数和分解后的优势函数组合起来,输出得到连续空间行为策略。详细算法如下所述。

图4 基于改进强化学习的共享行为决策示意图Fig.4 Schematic diagram of shared behavior decision based on improved reinforcement learning
在状态输入端对模糊规则稍作调整,在空间行为模糊推理模型进行L(L=yn)条IF-THEN模糊规则映射时,用al替换式(6)中的cl,即
THENul=al
(12)
式中:al为离散行为集a={a1,a2,…,aL}中对应于规则l的行为。
在行为选择阶段,为了有效解决强化学习中的探索与利用问题,即持续使用当前最优策略保持高回报的同时,敢于尝试一些新的行为以求更大地奖励,则对行为al采取ε-greedy贪婪策略[15]。该策略定义以ε的概率在离散行为集中随机选取,以1-ε的概率选择一个最优行为
(13)
式中:S为当前航天器的位置状态;q(S,al)为对应规则l和航天器行为al∈a下的q函数。q函数被定义为在ε-greedy策略下从状态S开始执行行为a之后的期望价值Gt,并将ε-greedy策略下q函数的期望称为状态函数[35]
qt(S,al)=E[Gt|St=S,at=a,ε-greedy]
(14)
vt(S)=Ea~ε-greedy[qt(S,al)]
(15)
状态函数可以度量特定状态下的行为状态,而q函数则度量在这种状态下选择特定行为的价值。基于此,将q函数与状态函数的差值定义为优势函数
ot(S,al)=qt(S,al)-vt(S)
(16)
理论上,优势函数是将状态值从q函数中减去后的剩余,从而获得每个行为重要性的相对度量,并且满足Ea~ε-greedy[ot(S,al)]=0。然而由于q函数只是对状态-行为的价值估计,这导致无法明确状态值和优势值的估计。为此,利用优势函数期望值为0这一特性,即当获取最优行为a*时qt(S,a*)=vt(S),vt(S)将实现状态函数的估计,与此同时ot(S,al)亦将实现优势函数的估计,进而可将q函数分解为一个状态函数vt(S)和一个优势函数ot(S,al)
qt(S,al)=vt(S)+
(17)
在行为输出端,可将与行为选取无关的状态函数分离出来,只需在对各优势函数进行优选操作后,再结合式(10)通过全连接层输出。这一处理既缓解了q函数的运算量,又有效避免了行为数量与映射规则的组合增长问题。
(18)
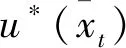
在自主学习阶段,在奖惩值的牵引下为实现反馈自主学习,定义时间差分(TD)误差函数
(19)
式中:γ∈[0,1]为折扣因子;Rt+1为t+1时刻可获得的奖惩值,并定义Rt+1=2e-u2-1。
q函数更新阶段,通过自主迭代训练进行更新
(20)
式中:η为强化学习速率。
3.3 航天器与非合作目标的博弈交互
将与非合作目标的空间交会问题,经微分策略描述成追逃博弈问题后,运用基于分支深度强化学习的追逃博弈算法,在模糊推理模型中,使得空间连续状态经由模糊推理以及追逃博弈算法,获得连续行为输出。在此以航天器视角为例,展现双方动态博弈交互过程:
过程1根据航天器当前状态S定义模糊推理模型输入量n,设定隶属函数y。依据模糊规则数,定义L(L=yn)组神经网络,并对各网络的q函数进行随机初始化。

过程3分别在与第l={1,2,…,L}条规则所对应的神经网络中,计算q函数q(S,al),根据式(13)选取离散行为al(l=1,2,…,L)。
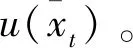
过程5计算航天器与非合作目标的欧氏距离,判断是否满足交会条件。若满足,令变量Done=1并转到过程10;若不满足,则转到过程6。
过程6令变量Done=0,非合作目标根据逃逸策略采取对自己最有利的行为,并移至新位置状态P+1。
过程7依据行为u以及位置状态变化情况,计算奖惩值R。在各分支网络中将当前状态S、离散行为al、奖惩值R以及下一步状态S+1,组合成[S,al,R,S+1]矩阵形式并存入记忆库[35-36]。
过程8共享行为决策模块中进行自主强化学习,依据式(16)~式(20),以误差函数pt为牵引,采取一定的学习率η,更新q函数。
过程9判断步数是否达到最大行动步数M。若达到,转至过程10;否则,步数加1并转入过程2。
过程10结束本轮追逃博弈交互过程。
4 算例分析
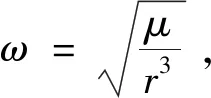

表1 航天器与非合作目标的初始状态Table 1 Initial state of spacecraft and non-cooperative target
航天器P与非合作目标E之间的空间角度差φ由俯仰角角度差Δδ与轨道平面内推力角之差Δθ构成,即φ=[Δδ,Δθ]
(21)
(22)
式中:φ′为上一状态的角度差;T是采样时间。
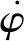
算例仿真在1.6 GHz、1.8 GHz双核CPU、8GRAM计算硬件上,运用PyCharm仿真编译环境进行。在分支深度强化学习架构中,考虑离散行为决策无需过多的高维特征信息提取,因此采用的神经网络层数为3,隐藏层神经元个数为10,激活函数为sigmoid,探索率ε=0.3,折扣因子γ=0.9,学习速率η=0.3,采样时间T=1 s。
经仿真比对,本文算法具有连续空间行为决策应用的对比优势。同样采取ε-greedy策略,分别运用本文算法和传统深度强化学习算法自主学习1 000次,运用TensorFlow的TensorBoard模块对学习过程进行检测,每隔3次对奖惩值进行采样。图5为由TensorBoard生成的学习曲线,即奖惩值随学习次数的累积变化情况。由曲线分布可知,本文算法的奖惩值增长更明显且更为平稳。
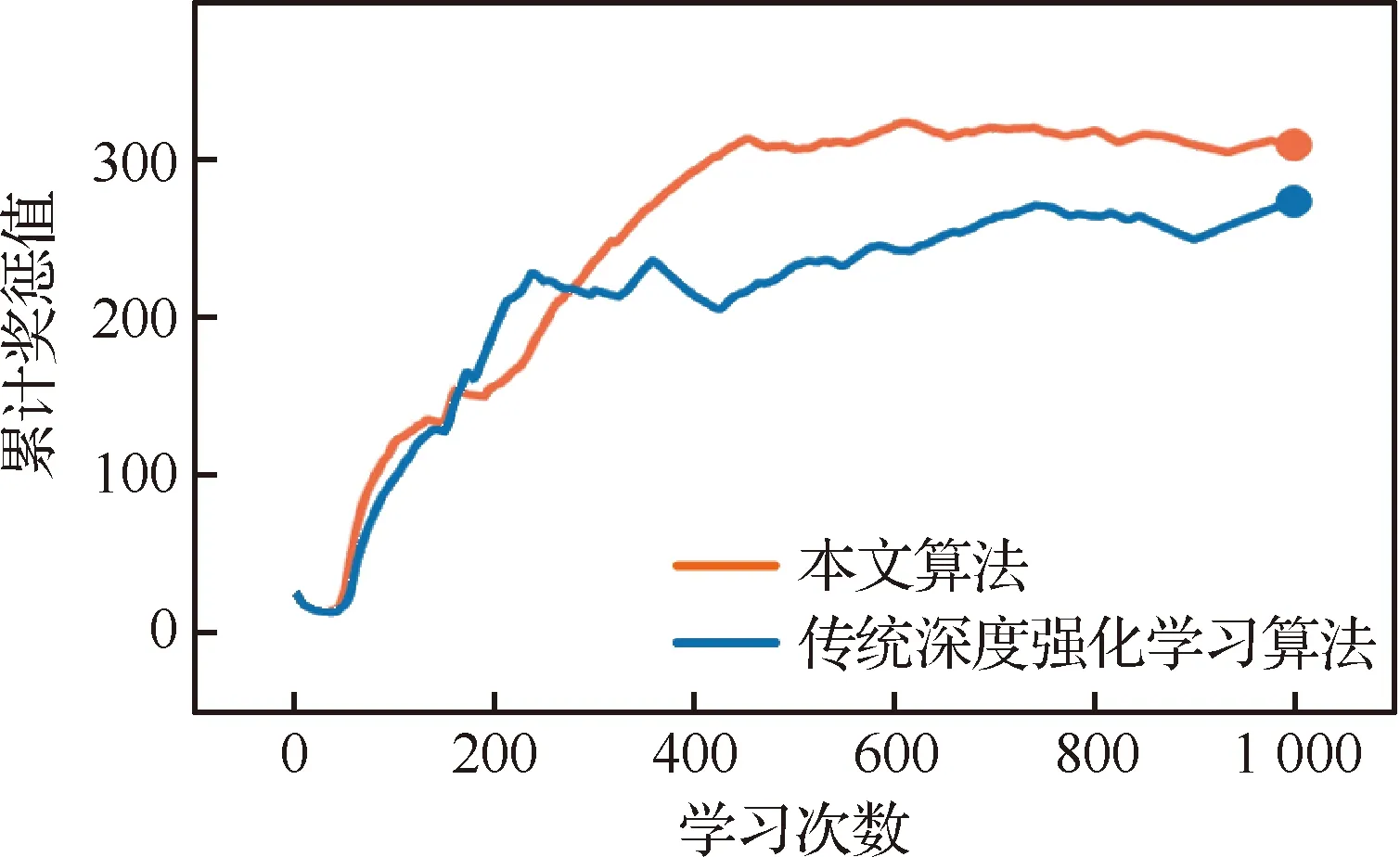
图5 两种算法的学习曲线Fig.5 Training curves of two algorithms
算例仿真表明,本文所提算法能够有效解决航天器与非合作目标的追逃博弈问题。例如,选取经过自主学习0次、500次后的追逃博弈进行比对,其轨迹分别如图6和图7所示。图6为当算法不经学习直接应用于该追逃博弈问题的轨迹变化情况。其中,航天器虽有目标函数驱使,但由于其q函数随机生成,且没有任何先验知识,导致行为举棋不定、来回浮动,非合作目标不受威胁沿原来轨道方向继续行进。最终,航天器与非合作目标距离越来越远,不能完成任务。如图7所示,当算法经过500次自主学习后,航天器能够朝着非合作目标方向逼近,途中非合作目标采取规避行为改变既定轨道,双方不断博弈在耗时2 328 s后,航天器实现与非合作目标的空间交会。

图6 学习0次后的追逃博弈轨迹Fig.6 Trajectory of pursuit-evasion game after learning 0 time
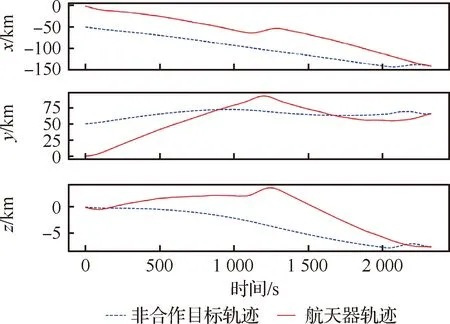
图7 学习500次后的追逃博弈轨迹Fig.7 Trajectory of pursuit-evasion game after learning 500 times
图8为自主学习中q函数误差随训练次数的变化情况,随着训练次数的不断增多,q函数误差越来越低,较快地收敛到最优行为策略,从而实现了该追逃博弈的纳什均衡。但由于采用贪婪策略,使得后期误差还存在微弱的波动。
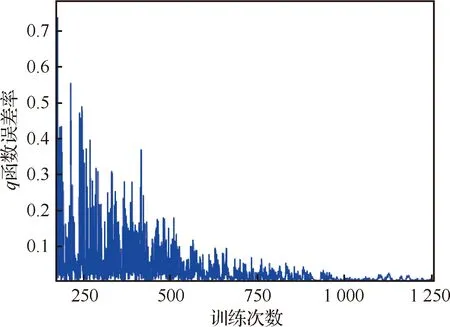
图8 q函数误差率随训练次数的变化情况Fig.8 Variation rate of q function error with training times
当算法经过1 000次自主学习后,航天器能够更好地处理非合作目标的逃逸行为,在与非合作目标博弈一段时间后很快使得相互的行为趋于稳定,双方追逃行为概率分布如图9所示。依此,在均衡策略的驱使下,航天器能够选择最佳轨迹,在最短耗时1 786 s后便与非合作目标实现空间交会,其行为控制量如图10所示,运动轨迹如图11所示。由图易知,双方在z方向的轨迹没有发生明显变化,符合航天器P与非合作目标E在追逃过程中最佳的追逃策略应发生在共面轨道的结论[9,37]。
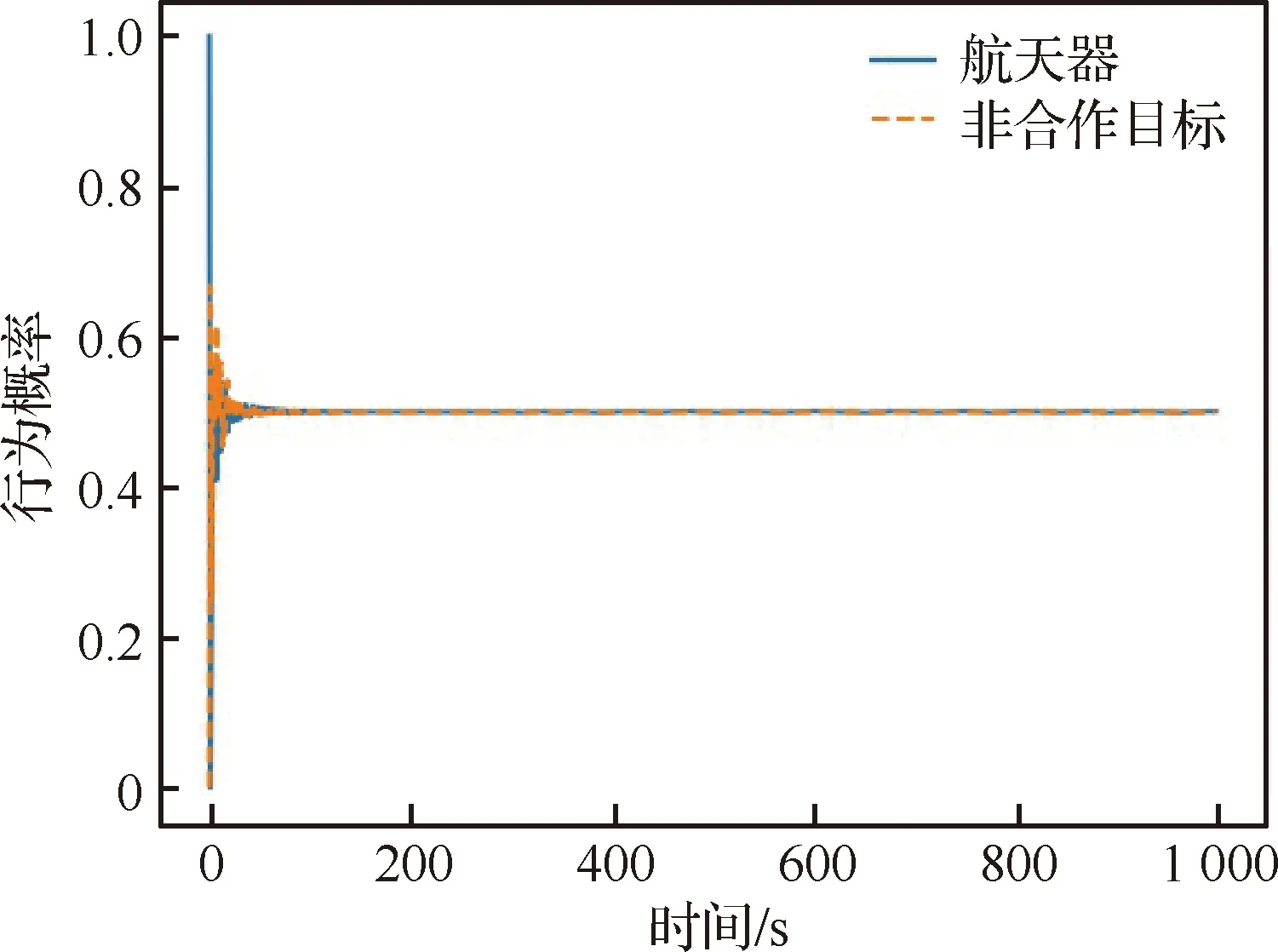
图9 追逃行为概率分布Fig.9 Probability distribution of pursuit-evasion behavior

图10 学习1 000次后的行为控制量Fig.10 Amount of behavioral control after learning 1 000 times

图11 学习1 000次后的追逃博弈轨迹Fig.11 Trajectory of pursuit-evasion game after learning 1 000 times
5 结 论
1) 构建了近地轨道航天器的追逃运动模型,给出了追逃博弈的纳什均衡策略,将非合作目标空间交会策略问题转述为微分对策问题。
2) 构建了空间行为模糊推理模型,实现了连续状态经由模糊推理再到连续行为输出的映射转换,有效避免了传统深度强化学习应对连续空间存在的维数灾难问题。
3) 提出了一种新的分支深度强化学习架构,实现了行为策略的分支训练与共享决策,有效解决了行为数量与映射规则的组合增长问题。
算例分析表明,论文算法具有连续空间行为决策应用的对比优势,能够有效应对连续空间追逃博弈问题,为非合作目标空间交会策略求解提供了新思路。同时,对于解决其他领域的追逃博弈问题具有较强的借鉴意义。
猜你喜欢
国际太空(2022年7期)2022-08-16
舰船科学技术(2022年11期)2022-07-15
国际太空(2022年2期)2022-03-15
煤气与热力(2022年2期)2022-03-09
航天器工程(2022年1期)2022-02-21
国际太空(2021年11期)2022-01-19
北京航空航天大学学报(2021年4期)2021-11-24
领导文萃(2019年8期)2019-04-19
读友·少年文学(清雅版)(2018年12期)2018-04-04
软件(2017年6期)2017-09-23
