
结合注意力机制的深度学习光流网络*
2020-11-15 11:10周海赟项学智翟明亮张荣芳
计算机与生活 2020年11期
周海赟,项学智,翟明亮,张荣芳,王 帅
1.南京森林警察学院 治安学院,南京 210023
2.哈尔滨工程大学 信息与通信工程学院,哈尔滨 150001
1 引言
光流场是计算机视觉中的重要底层信息,在自动驾驶、动作识别、视频处理等领域拥有广泛应用,因此光流估计一直是视觉分析领域里的一个热门研究课题。传统方法[1-3]通常利用亮度恒常假设和运动空间平滑假设等一系列先验约束构造能量泛函,并通过变分极小化能量泛函来求解光流,此类方法较容易集成人类对运动的先验知识,因此本文将其称为知识驱动方法。Horn 和Schunck[1]首次采用变分方法解决光流估计问题,该方法基于亮度恒常和平滑性假设构造能量泛函,此后的方法大多在此基础上通过添加新的约束项来改善能量泛函。Sun 等[2]设计了一种非局部平滑项,用于抑制运动边界的平滑。Brox 和Malik[3]将图像描述符匹配算法引入变分框架,扩展了经典的能量泛函。虽然这类知识驱动的变分方法可以通过预先定义的约束项来估计光流,但是此类方法在计算中需要通过多次迭代获得精确解,在需要高精度运动场的场合,其运行速度通常无法满足实际应用中的实时性要求。近年来,随着深度学习的兴起,卷积神经网络凭借其强大的学习能力,在图像分类[4]、目标识别[5]、语义分割[6]等多个领域取得了重大突破,其影响力也逐渐渗透到了光流计算领域。Dosovitskiy 等[7]首先将卷积神经网络引入光流估计领域,设计了两个U 型网络模型FlowNetS 和FlowNetC,并发布了一个大型合成数据集Flying-Charis,专门用于光流网络的训练。对于FlowNetS 模型,两帧图像以堆叠的方式输入网络,网络通过一系列卷积操作和反卷积操作自行学习二者之间的运动信息。对于FlowNetC 模型,两帧图像被分开处理,网络通过两个分支分别提取两帧图像的特征,之后通过相关层计算特征图之间的相关程度。FlowNetS 和FlowNetC 网络在FlyingChairs 数据集上以有监督的方式端到端地训练。两个深度学习模型可以从大量的数据中自动地学习光流,只是准确性还无法与知识驱动方法相提并论。在FlowNet经典模型被提出之后,更多的深度学习光流方法陆续被提出。Vaquero等[8]将粗到精的推理策略引入网络,将光流估计问题转化为回归和分类问题。文献[9-13]将知识驱动方法中的经典先验假设融入网络,使网络以无监督的方式学习光流。其中文献[8-9,12-13]都是基于经典的U 型网络架构设计的模型,主要特点是架构简单,易于与其他有效算法结合。除了经典的U 型网络架构之外,空间金字塔网络也是光流估计的基本网络架构之一。Ranjan 和Black[14]将空间金字塔引入深度学习光流方法中,设计了一种空间金字塔网络模型SpyNet,利用传统方法中的变形操作,将第二幅图像向第一幅图像变形,在每一层计算增量光流以解决大位移问题。与FlowNet 和Flownet2.0 方法相比,SpyNet 的参数量更小,运行速度更快,但准确率略低。基于SpyNet,Hu 等[15]设计了一种用于光流估计的循环空间金字塔网络。Dai等[16]提出了一种基于空间金字塔的新型网络架构,通过运动信息来约束视频中的时间信息。空间金字塔网络可以获得多尺度特征信息,而且使用金字塔分层计算可以解决光流估计中大位移问题,然而这种网络架构忽略了特征通道的相关性,不能学习和修改通道特征的权重。除了U 型网络和空间金字塔架构之外,级联结构也被引入到学习光流中。Ilg 等[17]在FlowNet 的基础上设计了一种堆叠网络模型FlowNet2.0,将FlowNetS 和FlowNetC 作为子网络堆叠在一起,并在子网络之间加入变形操作,以提高光流估计模型的准确率。FlowNet2.0 在FlyingThings3D 数据集[18]上对各个子网络进行微调,得到的模型具有很高的准确率,但模型的训练过程较为复杂,且其参数量是FlowNet 的5倍。Unfow[10]是一种无监督网络,它利用堆叠架构和更加鲁棒的Census 损失函数来提高光流网络的学习能力。级联架构以迭代细化的方式提高光流估计的准确性,因此训练过程复杂且耗时。上述几种深度学习光流估计方法从大量图像数据中学习运动规律,本文将其称为数据驱动方法。数据驱动方法虽然在训练阶段较为耗时,但在推理阶段速度较快,可有效解决传统知识驱动型方法实时性差的问题。但现有的数据驱动光流网络大多来源于计算机视觉中其他像素级任务的网络架构,在处理运动信息时缺乏灵活性,无法区分不同通道下运动信息的重要程度,导致网络对运动特征提取的效率不高。同时,基于编解码架构的网络采用卷积操作来提取两帧图像之间的运动特征,随着特征图分辨率的逐渐降低,会丢失大量的细节信息,这也进一步限制了稠密光流估计的准确率。
本文将通道注意力机制和空洞卷积引入U 型深度学习光流网络,并设计了一个空洞卷积和注意力单元级联的模块,以解决上述几种问题。U 型深度学习光流网络的各层卷积层提取的是多通道特征图,且每个通道下的特征图包含的运动信息并不相同,然而以往的深度学习光流网络并没有考虑到不同通道之间的区别,对所有通道下的特征都进行统一处理,这将极大地限制深度学习网络的学习能力。通道注意力机制可以自适应地调整各通道下的特征权重,在卷积层的各层之间级联上注意力单元后,网络可以在训练过程中不断地对各通道下特征图的权重进行调整,以使网络逐层提取出更具有针对性的特征图,得到更加有效的运动信息,从而提高模型的学习能力;空洞卷积已经被广泛应用于各类像素级任务中,与普通卷积相比,空洞卷积可以在增大卷积核感受野的同时保持特征图的尺寸,以避免大量细节信息随着特征图尺寸的减小而丢失,对于光流估计这一类像素级问题,细节丢失将会大幅度降低光流估计的精度,因此本文将空洞卷积引入深度学习光流网络中,保证光流细节不损失,从而有效地学习更多的空间信息;除此之外,本文还将知识驱动方法中的光流先验约束融入深度学习网络中,构建了知识与数据混合驱动的光流网络,进一步提升了光流估计精度。
2 结合通道注意力机制与空洞卷积的光流学习网络
本文提出的深度学习光流网络基于U 型网络架构,其整体架构如图1 所示。网络包含收缩和扩张两部分,收缩部分首先通过若干层卷积层分别提取两帧相邻图像的低级特征,之后在相关层计算两幅特征图的相关性,并通过级联的通道注意力单元和空洞卷积进一步提取高级运动特征,最后将得到的高级特征作为扩张部分的输入。扩张部分通过一系列反卷积操作将高级特征图恢复至原始图像分辨率,其中每层反卷积层后都级联注意力单元,并通过特征复用减少细节信息丢失。

Fig.1 Overall architecture of network图1 网络的整体架构
2.1 注意力机制
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,以获取更多所关注目标的细节信息,抑制其他无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。深度学习中的注意力机制从本质上讲与人类的选择性视觉注意力机制相似,目标也是从众多信息中选择出对当前任务目标更关键的信息。当前注意力机制目前已经广泛应用于图像分类、目标检测、行人重识别等多个计算机视觉领域。Wang等[19]提出了一种用于图像分类的残差注意力网络。Zhang 等[20]提出了一种注意力引导的递归网络,用于显著目标检测。Zhu 等[21]则设计了一种用于目标检测的全卷积注意力网络。Yang 等[22]提出了一个专用于行人重识别任务的端到端注意力网络。Chen 等[23]提出了一种语义分割的注意力机制,可以对每个像素位置的多尺度特征进行加权。袁嘉杰等[24]提出一种基于注意力卷积模块的深度神经网络,以促进网络的信息流动。孙萍等[25]在目标检测网络中引入注意力特征库,有效地提升模型的检测精度和检测速度。以上这些工作表明,注意力机制能够将网络的注意力向最具信息性的特征方向调整。然而,利用注意力机制来解决光流估计任务的工作还很少。在光流估计任务中,运动物体的不同位置具有不同的光流特性,例如运动物体的边界部位更侧重于光流的边缘特征,运动物体的内部则更侧重于光流的平滑性,深度学习光流网络利用卷积操作不断提取包含不同运动信息的多通道特征图,本文将通道注意力机制与深度学习光流网络相结合,在网络的各层卷积层之间级联上注意力单元,可以使网络逐层地调整各通道特征图的权重,针对运动物体的不同位置学习更具有针对性且更加有用的运动信息,以提升U 型网络的光流学习能力。
2.2 空洞卷积
空洞卷积的主要思想是在标准卷积核之间加入空洞,使卷积核在保证尺寸不变的情况下增大感受野,最近已被广泛应用于语义分割、图像分类以及目标检测等多个任务领域中。Chen 等[26]较早地将空洞卷积应用于语义分割领域,Yamashita 等[27]提出了由多个空洞卷积网络跳跃连接的网络模型,增强了语义分割效果。Yu 等[28]则设计了一个用于图像分类和语义分割的空洞残差网络。石祥滨等[29]利用空间卷积和时间卷积来缩减深度学习光流模型的参数量。与普通卷积相比,空洞卷积可以在提取运动特征的同时保证特征图分辨率不变。由于U 型网络包含收缩和扩张两部分,收缩部分通常利用普通卷积操作不断地缩小特征图的尺寸以增大感受野,从而导致特征图的分辨率不断降低,损失大量细节信息。本文在引入注意力机制的同时将空洞卷积集成进U 型光流网络,将U 型网络中收缩部分的普通卷积替换为空洞卷积后,使网络在不损失特征图尺寸的同时提取运动特征,以此保留重要的细节信息,提升网络的学习能力。
2.3 深度学习光流网络收缩部分
本文所设计的深度学习光流网络收缩部分负责提取输入图像对中的运动特征,由图像特征提取、相关层及级联的注意力机制和空洞卷积模块组成,其网络架构如图2 所示。
图2 为光流网络的收缩部分,收缩部分首先通过3 层标准卷积层分别提取两帧相邻图像的特征,每层卷积层之后连接一层ReLU 层,卷积核大小分别为7×7、5×5 和3×3,步长为2,输出的特征图个数分别为64、128、256,之后通过一个相关层来进行特征图匹配,找到特征图间的对应关系,相关层所表达的相关函数定义如式(1)所示。

其中,x1、x2分别表示第一帧和第二帧的特征图,N表示相关向量c1(x1)和c2(x2)的长度。相关层输出的特征图随后输入至级联的空洞卷积和注意力单元模块中,其中包含6 层空洞卷积层,即图2 中的n为6,每层卷积层之后均连接注意力单元。空洞卷积在不增加卷积核尺寸的同时增大感受野,可以避免网络在下采样过程中丢失重要的细节特征,从而提升网络学习光流的能力。注意力单元则利用不同通道之间特征图的相互依赖关系,进一步优化空洞卷积层输出的特征图,注意力单元的细节如图3 所示。
注意力单元包括压缩和激励两部分,给定尺寸为H×W的特征图X=x1,x2,…,xc,注意力单元可以自适应地调整不同通道特征图的权重,其中压缩部分对输入特征图进行全局平均池化操作,输出特征图由S=s1,s2,…,sc表示,sc的定义如式(2)所示:

Fig.2 Architecture of contracting part图2 收缩部分的网络架构

Fig.3 Attention unit图3 注意力单元

其中,sc为每个通道信息量。
激励部分包含两层卷积层和一层激活层,第一层卷积层连接一层ReLU 层,用来压缩特征图的数量,可以用1×1×C/r来表示输出特征图的数量,其中C表示输入特征图的通道数,本文将压缩参数r设置为64。第二层卷积层用来恢复通道的数量,通道权重由P=p1,p2,…,pc表示,之后将这些权重输入激活函数,并将权重值规范化到0 至1 之间。最后将输入特征图X=x1,x2,…,xc与权重P=p1,p2,…,pc分别相乘,得到优化后的特征图R=r1,r2,…,rc,其中rc的定义如式(3)所示。

注意力单元的参数细节如表1 所示。注意力单元并不会改变输入的分辨率,其中激励部分可以自适应地学习每个通道的权重。每一层空洞卷积层的输出特征图的个数分别设置为512、512、512、512、1 024、1 024,空洞参数分别设置为2、2、4、4、8、8,除最后一层空洞卷积层外,其他每一层之后均连接ReLU 层,由于空洞卷积可以在保证特征图分辨率的情况下增大感受野,收缩部分最后输出的特征图的分辨率只缩减至原始分辨率的1/8,而不是1/64,从而有效地保护了运动细节信息。

Table 1 Architecture of attention unit表1 注意力单元网络架构
2.4 深度学习光流网络扩张部分
深度学习光流网络扩张部分的架构如图4 所示,收缩部分输出的特征通过级联的注意力单元进行整合,该模块包含3 个反卷积层和1 个标准卷积层,每层反卷积层后均连接注意力单元。扩张部分可以估计出多尺度光流,将特征映射的分辨率扩大到原始分辨率的1/4。每个反卷积层的卷积核尺寸为3×3,输出的通道数分别为512、256、128、64,每个卷积层后均为ReLU 层。为了使网络能够感知多级特征,网络复用了扩张部分相应尺度下的特征图。

Fig.4 Architecture of expanding part图4 扩张部分的网络架构
2.5 网络训练的损失函数
传统的光流估计算法是通过构建能量函数来约束图像与光流之间的关系,此类知识驱动方法被称为变分光流方法。Horn 和Schunck[1]首先提出了一种用于光流估计的变分框架,该框架利用亮度恒常和全局平滑假设来约束光流。之后Brox 将更多的约束项引入能量泛函中,极大地提升了变分光流方法的估计精度[3]。
当前卷积神经网络已开始逐渐应用于光流估计任务中,此类数据驱动方法可以从大量数据中学习运动信息。给定两幅输入图像以及光流真值,训练网络的目的是让网络自行学习图像对之间的运动关系,即光流。在有监督方法中通常采用端点误差(end point error,EPE)作为损失函数来引导网络的训练过程,端点误差损失函数的定义如式(4)所示。

其中,ux,y、vx,y是点p=(x,y) 处的预测光流;是点p=(x,y)处的光流真值;H和W是图像的高度和宽度。
为充分利用运动先验知识,实现优势互补,本文引入变分光流方法中行之有效的亮度恒常假设、梯度恒常假设、全局平滑约束,并对各项使用基于全变分(total variation,TV)的鲁棒惩罚函数,最后将这些约束项与EPE损失进行求和构成新的光流损失函数。
亮度恒常假设的定义如式(5)所示。

其中,I(x,y,t)表示t时刻点p=(x,y)处的像素值,u、v分别是水平和垂直光流。应用在深度学习光流网络中的亮度恒常损失函数的定义如式(6)所示。

其中,N表示图像中像素点的总数;Ii(p)表示第i帧图像在像素点p=(x,y)处的像素值;ψ表示鲁棒惩罚函数,这里采用Charbonnier 惩罚函数(x2+0.0012)α;w=(u,v)T表示t时刻与t+1 时刻两帧图像之间的光流向量,w(p)为像素点p=(x,y)处的光流向量。
相比于亮度恒常假设,梯度恒常假设对外部光照变化更加鲁棒,梯度恒常假设的定义如式(7)所示。

其中,∇=(∂x,∂y)T表示空间梯度。空间梯度损失函数的定义如式(8)所示。

亮度恒常假设和梯度恒常假设并没有考虑到相邻像素之间的相互作用,忽略了图像中的空间信息,常用的光流空间约束项是全局平滑约束,其定义如式(9)所示。


其中,ρs表示Charbonnier惩罚函数。
最终的深度学习光流损失函数为以上损失函数的总和,其定义如式(11)所示。
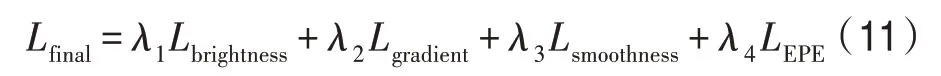
其中,λ1、λ2、λ3、λ4分别表示亮度恒常损失函数、空间梯度损失函数、图像驱动的平滑项损失函数和端点误差损失函数的权重,本文采用加权求和的方式计算Lfinal,首先在网络扩张部分的不同分辨率下分别计算Lfinal,之后将所有分辨率下的Lfinal相加得到最后的损失函数总和。不同分辨率下每一项损失函数的权重如表2 所示,由于亮度恒常损失函数、空间梯度损失函数、图像驱动的平滑项损失函数和端点误差损失函数在训练过程中的重要程度有所不同,各项损失函数所占的权重比例也有所不同,即在网络训练中起到的作用越大,权重系数越大。其中端点误差损失函数的权重参数参考FlowNetS[7]而设置,亮度恒常损失函数及空间梯度损失函数的重要程度随着分辨率尺度的不断增加而逐渐加强,因此按照等差数列的规律不断增加权重,即分辨率越大,所占权重比例越大。由于分辨率尺度并不影响图像驱动的平滑项,因此不同分辨率尺度下的图像驱动的平滑项损失函数权重全部相等。

Table 2 Parameter settings表2 参数设置
3 实验结果与分析
所设计的光流网络在FlyingChairs 和Flying-Things3D 数据集上进行训练,在FlyingChairs 数据集上训练时,批量大小设置为8,在FlyingThings3D 数据集上训练时批量大小设置为4。在FlyingChairs 数据集上训练的迭代次数为1.2×106次,初始学习率为0.000 1,在训练到4×105次之后每经过2×105次迭代,学习率缩减一半。然后,在FlyingThings3D 数据集上进行微调,初始学习率设置为0.000 01,并在迭代3×105之后每迭代105次将其减小一半。此外,分别 在MPI-Sintel、KITTI2012 和KITTI2015 数据集的训练集和测试集上测试训练得到的模型,并与近期相关工作进行了全面比较。值得注意的是,训练网络的训练集并不包含这3 类数据集中的训练集。表3和表4 显示了在不同基准数据集下测试得到的数值结果,误差度量使用平均端点误差(average end point error,AEE),在KITTI2015 数据集上使用的误差度量为光流估计错误像素点所占的百分比。
MPI-Sintel 训练和测试集分别包含1 041 和552个图像对,提供了Clean 和Final 两个版本的数据集,其中Final 版本包含运动模糊、大气变化、雾效果和噪点,比Clean 版本更加复杂,且更具挑战性。KITTI 数据集由车载立体摄像系统捕获的真实道路场景组成,KITTI2012 数据集包含194 个训练图像对和195 个测试图像对;KITTI2015包含200个训练图像对和200个测试图像对。这两个数据集仅包含稀疏的光流真值。
由表3 和表4 可以看出,本文的模型在MPISintel 的Clean 和Final 的数据集上的测试结果优于SpyNet[14]、CaF-Full-41c[8]、FlowNet2.0-S[17]、FlowNet2.0-C[17]和Dai 等[16]有监督学习方法和DSTFlow[9]、Un-Flow[10]、DenseNetFlow[11]、OccAwareFlow[12]等无监督学习方法。

Table 3 Quantitative evaluation on MPI-Sintel datasets表3 MPI-Sintel数据集上的定量评估

Table 4 Quantitative evaluation on KITTI datasets表4 KITTI数据集上的定量评估
由表3 可以看出,FlowNet2.0-S、FlowNet2.0-C 和SpyNet 的结果与本文模型很接近,但其精度并未超越本文模型,其中SpyNet 在FlyingChairs 数据集上进行训练,FlowNet2.0-S 和FlowNet2.0-C 在FlyingChairs和FlyingThings 数据集上都进行了训练。SpyNet 利用空间金字塔网络来学习光流,与本文方法一样同属于轻量级网络,然而其准确度略低于本文模型。
同时由表4 可以发现,在KITTI2012 数据集上无监督方法UnFlow 与有监督方法相比获得了更好的结果,经过分析总结出以下三点原因:首先,UnFlow与FlowNet2.0 均通过堆叠多个FlowNet 子网络来提升网络性能;其次,UnFlow 的训练数据集还包含3 个数据集SYNTHIA、Cityscapes 和KITTI raw,这些都是与自动驾驶相关的数据集,与测试集场景较为相似,可认为是进行了有针对性的优化;最后,Unflow 使用相对亮度恒常假设更加鲁棒的先验假设。因此,Unflow 在KITTI 数据集上的性能优于其他方法。此外,Unflow 和OccAwareFlow 均使用了前后向一致性校验来估计遮挡区域,这在一定程度上也有利于提升光流估计精度。
与无监督方法相比,有监督方法通常难以获得足够数量的具有真值的真实图像序列,因此大多是在合成数据集上进行训练,例如FlyingChairs 和Flying-Things3D,因此在合成数据集Sintel 上进行测试时,有监督方法FlowNetS、FlowNetC、SpyNet 和Dai 等的准确性更加接近于本文网络训练得到的模型。
之后在MPI-Sintel数据集上进一步微调了所得到的模型,并对微调后的模型标记后缀“+ft”,表5显示了微调后的模型在MPI-Sintel数据集下测试的数值结果。

Table 5 Quantitative evaluation on MPI-Sintel datasets after fine-tuning表5 微调后在MPI-Sintel数据集上的定量评估
由表5 可以看出,在MPI-Sintel 数据集上微调后的本文模型与“RecSpyNet+ft”[15]、“FlowNetS+ft”[7]、“FlowNetC+ft”[7]、“SpyNet+ft”[14]相比具有更好的结果。SpyNet+ft[14]的结果与本文模型很接近,但精度仍略低。
图5 和图6 展示了本文模型、FlowNetC[7]和Flow-Net2-C[17]在MPI-Sintel final 数据集上测试的可视化结果对比图,其中图6 为将局部细节放大后的对比图,从中可以看出,本文模型与FlowNetC 和Flow-Net2-C 相比具有更清晰的运动细节,特别是在腿部、手臂等细节部分,而且边缘处的噪声也得到了很好的抑制,这说明本文所设计的网络可以获得更好的运动边缘效果,证明了所提出方法的有效性。

Fig.5 Visual comparison on MPI-Sintel dataset(final)图5 在MPI-Sintel(final)数据集上的可视化比较

Fig.6 Comparison of enlarged local details图6 局部细节放大后的对比
4 结束语
本文提出了一个全新的深度学习光流网络,其将通道注意力单元和空洞卷积引入光流网络中,通道注意力单元可以通过各通道之间的关系自适应地调整各通道的特征,从而提高网络的运动学习能力。同时,网络可以学习特征图的权重,使网络可以学习更重要的特征。对于像素级估计任务,空洞卷积可以在保持特征图分辨率不变的情况下有效地扩大感受野,减少空间信息的丢失。在MPI-Sintel 和KITTI数据集上的测试结果证明了所设计网络的有效性。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
农业工程学报(2022年12期)2022-09-09
临床肺科杂志(2022年8期)2022-07-28
计算机研究与发展(2022年1期)2022-01-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
学生天地(2020年18期)2020-08-25
故事作文·高年级(2017年2期)2017-03-01
文苑(2015年9期)2015-09-10
