
计算机技术驱动的未识甲骨字考释研究
2020-11-16 07:46焦清局刘国英
殷都学刊 2020年3期
焦清局,刘国英
(安阳师范学院 计算机与信息工程学院,河南 安阳 455000)
一、前言
文字是文明的标志,也是一个民族的化石和印记。甲骨文是一种刻在龟甲与兽骨上的文字,是汉字汉语的鼻祖,承载着真正的中华基因。在甲骨学领域中,未识甲骨字的考释一直是甲骨学家研究的重要内容。到目前为止,在已发现的约4378个甲骨文字中,已释读字仅有1682字,剩下的字考释难度非常大[1]。传统的考释方法主要依靠甲骨文专家的知识和猜测:首先,甲骨文专家利用已有知识对未识甲骨字进行“隶定(对甲骨字进行模糊语义猜测)”,然后,通过相应的文献对“隶定”的语义进行验证。传统的考释方法存在以下缺点:一是在“隶定”和验证阶段需要研究者具备大量的甲骨文专业知识。然而,由于人的生理、认知等因素的影响,研究者无法掌握完备的专业知识;二是传统方法只是从孤立的拓片信息“隶定”未识甲骨字语义。但是,甲骨文是一种成熟的文字系统,这种孤立的研究方法可能会导致考释结果的不正确。因此,用传统的方法对甲骨字进行考释的进程缓慢。随着对甲骨学研究的日益增多,以及甲骨学知识数据的规范化和数字化,中外研究者采用计算机技术对甲骨文字进行分析,并采用人工智能方法对甲骨字的语义进行建模和计算,从而可能突破甲骨文考释瓶颈,获得新的进展,从而促进甲骨学的发展。目前计算机技术辅助的甲骨学研究文献并不多,这些文献主要集中在甲骨文的输入和可视化、识别、语义分析、甲骨拓片缀合、数据库构建等方面的研究。
与现在的汉字不同,甲骨字都是篆刻的文字,其在计算机上输入非常困难。因此,甲骨字的输入为用计算机技术研究甲骨文起着重要的作用。刘永革等人通过建立甲骨字图片化字库,实现了甲骨字的可视化输入[2]。此种输入方法可以根据图片数据输入甲骨字6199个(包含异形体)。史创明和刘永革首先把甲骨字矢量化,并把其输出为可伸缩矢量图形(Scalable Vector Graphics,SVG)格式[3];然后通过编程把SVG格式的甲骨字显示在网页中。此种方法可以作为甲骨字文本输入的一种有效补充。为了解决甲骨字输入、编辑和印刷方面的难题,栗青生和王蕾设计了方便的甲骨文图文编辑系统[4]。不仅如此,栗青生等人通过引入笔段和笔元的概念解决甲骨字异体字和合体字的输入问题[5]。肖明等人利用模糊信息分析理论对象形码编码的模型进行研究[6],得出了甲骨文编码的最佳码长大致接近于3,从而为甲骨字进行编码提供了理论基础。顾绍通等人通过对甲骨字形的拓扑结构分析后, 整理出569 个甲骨字部件[7],并把这些部件映射到26个计算机键位上,根据甲骨字部件和键位映射关系即可输入甲骨字。
在甲骨文字识别方面,早在1996年,复旦大学的李锋通过抽象甲骨字的无向图特征识别甲骨字[8]。利用相似的方法,栗青生等人首先抽象甲骨字关键点;然后连接关键点形成甲骨字图;最后通过图匹配算法识别甲骨字[9]。2014年,高峰等人首先利用语境分析生成的候选字库得到对应的甲骨文语义构件向量,然后结合Hopfield网络识别的结果计算待识别的甲骨文模糊字的匹配度,根据匹配度识别甲骨字[10]。由于甲骨异体字在拓扑结构上的稳定性,2016年,顾绍通利用拓扑图形描述甲骨文字,并结合拓扑配准的方法识别甲骨文字[11]。2017年,刘永革和刘国英通过提取甲骨字图像中的特征,并结合支持向量机(Support Vector Machine,SVM)识别甲骨字[12]。
在语义分析方面,2012年,袁冬等人提出基于实例的甲骨文释文机器翻译方案,并实现一个简易的甲骨文字与现代汉字的映射系统[13]。2015年,高峰等人在一个融合甲骨文和现代汉语的语义知识库之上,通过对甲骨卜辞的可拓语言建模分析释义问题[14]。同年,熊晶等人结合语义网络技术,利用关系资源描述框架(Resource Description Framework, RDF)抽象甲骨学中的实体及其关系,通过语义搜索发现实体间的语义关联, 为甲骨文字的语义研究提供支持[15]。
甲骨拓片是计算机学家研究甲骨文最直接和原始的数据,是构成语义的基本单元。但是由于甲骨质脆和时代久远,出土时甲骨片多已裂成碎片。只有将这些碎片缀合在一起,才能更好地了解甲骨拓片描述的事件、场景以及内容。老一代甲骨学家已成功缀合了大量的甲骨片。然而,手工的甲骨片缀合方法非常耗时,王爱民等人提出了基于甲骨片图像的轮廓信息缀合方法[16]。该算法首先提取甲骨片的边界片段;其次,计算甲骨片的轮廓特征,甲骨片的轮廓即为甲骨片的形状。甲骨片的轮廓特征在整个缀合过程中起着重要的作用。在此算法中,王爱民等人采用Freeman链码表示轮廓线段,并用傅里叶描述子计算轮廓片段的特征;最后,计算不同甲骨片的匹配程度。如果两个甲骨片的匹配程度大于0.8,那么这两个拓片应缀合在一起。从真实数据的验证结果表明该算法具有一定的有效性。
甲骨文数据库的构建为计算甲骨学研究提供坚实的数据基础,也是计算甲骨学研究的开始。甲骨文数据库的构建一般要具备5个特点:一是原始性,即数据库中的甲骨片具有原始性,最好是出土甲骨片,这样能保证图片的真实性;二是正确性,数据库收录的拓片、字库、部首、字形等信息要经过甲骨学专家的认证;三是全面性,构建的甲骨文数据库能全面提供有关甲骨文的各方面信息,如甲骨字的部首、字形、所在的拓片、拓片的出土地、现存地、相关的研究文献等全面信息;四是可共享性,构建的甲骨文数据库能提供世界上任何地点的甲骨文研究专家使用;五是及时性,即构建的数据库要根据甲骨文的研究及时更新数据库中的信息。如新发现的拓片、新的研究文献、新的甲骨片缀合信息等要及时更新到数据库中。
2004年,江铭虎等人构建了包含甲骨文字库、甲骨文知识库和句法分析、计算机甲骨文辅助辨识等信息的数据库[17]。该甲骨文字库包含甲骨文字3600余字,并对可释读的约1400个甲骨字进行了详细的计算机标注,其中包括专有名词120余个,这些甲骨文字全部可通过拼音输入,并可给出对应的现代汉语解释。安阳师范学院甲骨文信息处理教育部重点实验室开发了甲骨文大数据库(http://jgw.aynu.edu.cn),该数据库包含了甲骨拓片、拓片上甲骨字注释、甲骨文文献、甲骨字库、甲骨字输入法等信息。该数据库是一个甲骨学研究较为全面的数据库,并及时更新最新甲骨学研究文献。
尽管计算机技术辅助的甲骨学研究取得了一定的进展,但是对未识甲骨字语义预测方面进展缓慢。本文以上下文语境和字形信息入手,首先通过建模捕捉甲骨字的上下文语境和字形信息;其次把未识甲骨字语义预测转化为计算机技术可处理的问题;最后设计相应的算法预测未识甲骨字的模糊和精准语义。文中提出的研究思路有助于推动甲骨学考释的进程。
二、未识甲骨字的模糊语义预测
2.1 甲骨字上下文语境信息的建模
在甲骨学研究中,甲骨字的上下文语境信息和字形在预测语义的过程中起着重要的作用。上下文语境主要表现为甲骨字在拓片中与其它甲骨字的邻近关系,以及甲骨字与其它甲骨字在所有拓片中共同出现的频率。字形主要表现为整体甲骨字、部首、构件(可能是不代表任何语义的字的一部分)在不同时代的演变过程。在以计算机技术辅助的未识甲骨字语义预测过程中,我们需要建模捕捉甲骨字的上下文语境信息和字形信息。
复杂网络是抽象复杂系统最为有力的工具。在复杂网络中,结点代表某个事物或概念,边代表事物与事物或概念与概念之间的相互关联关系。通过构建甲骨字的网络可以捕捉甲骨字的上下文语境信息。在自然语言处理领域,共现网络可以反映文字在段落中的线性关系。在共现网络中,结点表示文字,边表示文字在一个窗口中的邻接关系。在构建文字的共现网络过程中,一是要确定在多大的窗口内表示文字之间的邻接关系;二是如何确定邻接关系。在构建甲骨字网络时,窗口的大小为一个甲骨拓片中所有甲骨字的个数。而两个字的邻接关系可以是紧密相连的两个字,即只计算相邻两个字之间的权重(m=2)。图1[18]给出了构建共现网络时需要计算的两个字之间的权重(m=2,上图)。下图给出的m=6时,计算的文字之间的权重值:即要计算6个字(w1,w2,w3,w4,w5,w6)中任意两个字之间的权重。在构建甲骨字共现网络时,m值设置为一个拓片中甲骨字的总个数。因此,对于一个拓片,我们需要计算拓片中任意两个甲骨字之间的权重。与构建以往共现网络不同,焦清局等人计算的两个甲骨字之间(甲骨字i和j)的权重[19],不是甲骨字i和j在一个拓片上的权重,而是它们在不同拓片上的权重和。构建甲骨字共现网络(网络矩阵为M)的步骤如下[19, 20](见图2):第一,选定一片甲骨拓片,假设此拓片上的两个甲骨字i和j,我们可以使用公式(1)和(2)定义甲骨字i和j之间的权重wij,并把wij值赋予Mij。公式(1)中的interal值可以用公式(2)计算,如果甲骨字i和j之间没有残缺甲骨字,那么interal的值为lj-li;在一些拓片中,有些甲骨字之间存在残缺情况。如果甲骨字i和j之间有残缺的情况,那么interal的值之间除了lj-li,可加入一个参数β,β表示残缺甲骨字之间的权重。在文献[20]中,焦清局等人把β的值设置为2。在甲骨字共现网络构建过程中,两个甲骨字i和j之间的权重由i和j在不同拓片上的权重相加得到。
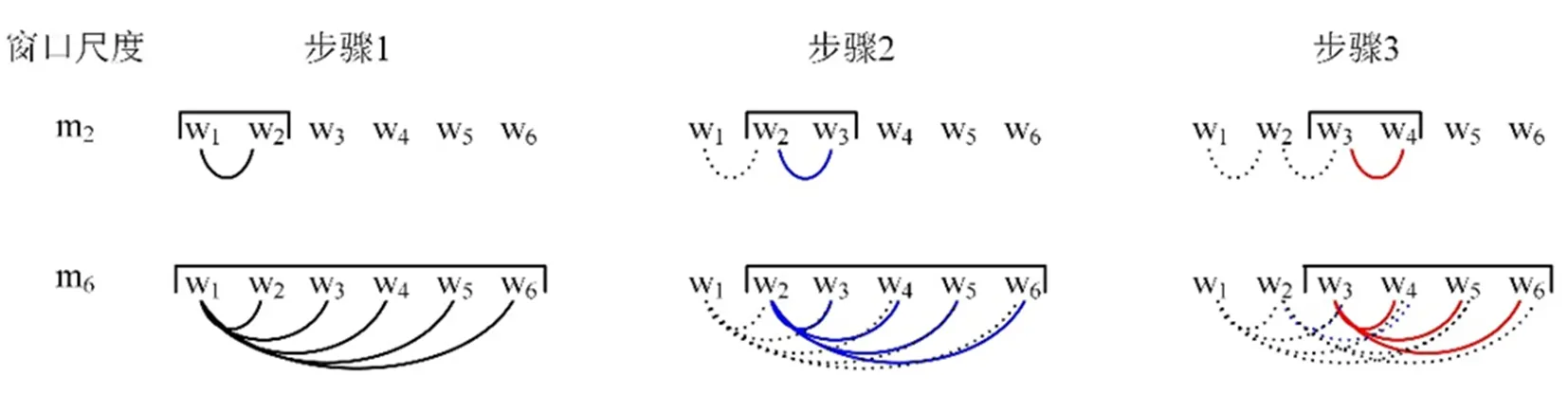
图1 共现网络构建示意图[18]
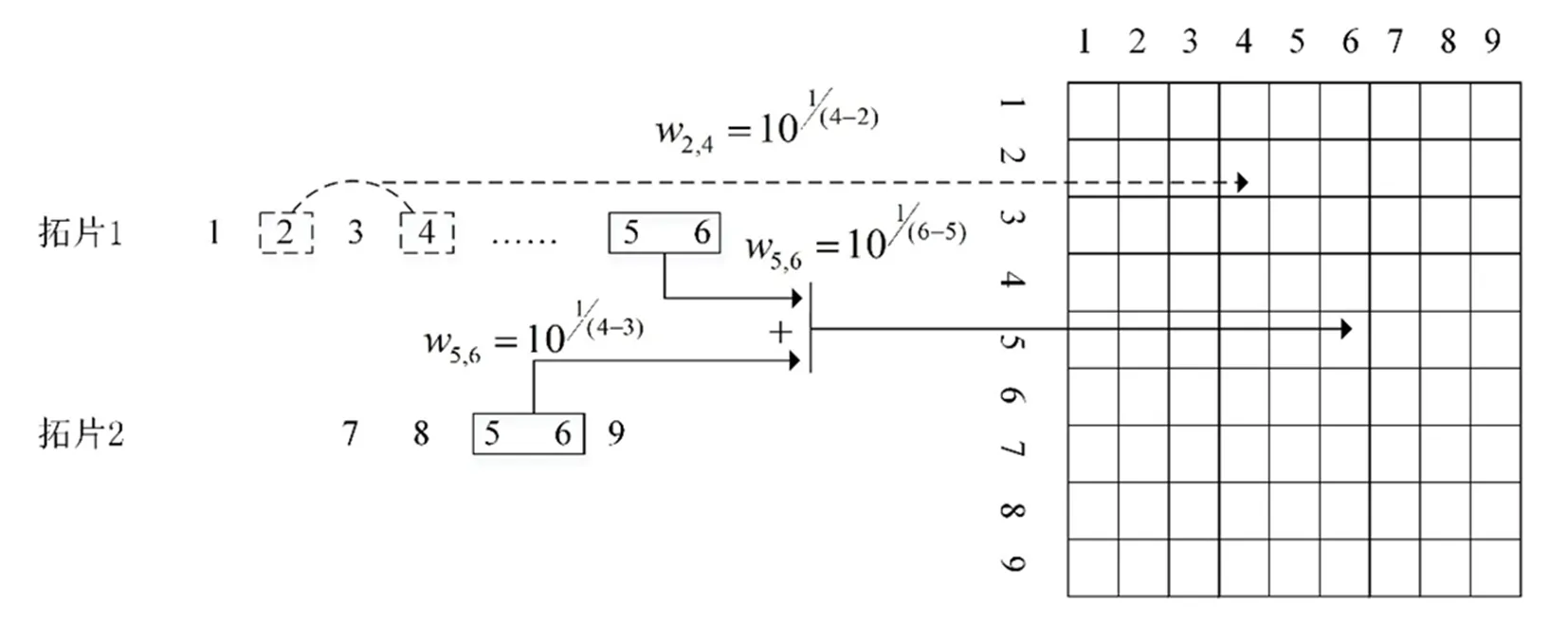
图2 甲骨字网络矩阵构建示意图[19]
(1)
interal={lj-li
β+(lj-li)
(2)
在公式(2)中,lj和li表示甲骨字j和i在拓片中的顺序位置,并且lj的位置在li的后面。
2.2 未识甲骨字考释难易程度
在预测未识甲骨字语义之前,我们应该确定哪些未识甲骨字容易考释。容易考释的未识甲骨字应具备以下特点:一是未识甲骨字应该在不同的拓片中多次出现;二是未识甲骨字的信息丰富,即未识甲骨字所在的拓片应含有多个甲骨字;三是未识甲骨字的可用信息较多,即未识甲骨字周围的甲骨字尽可能是已识字。总之,一个未识甲骨字的可用信息越多,此字被破译的可能性就越大。在甲骨字网络中,参数S[20]可以计算未识甲骨字的考释难易程度。
(3)
在公式(3)中,Si表示甲骨i字的考释难易程度系数,Nn和Un分别表示已识和未识甲骨字的个数,wih和wik分别表示甲骨字i与已识和未识甲骨字连接的权重。由于连接的权重和值较大,我们对其取对数。在S中我们可以看出,如果一个未识甲骨字i与已知甲骨字连接个数越多,并且权重越大,分子就越大;并且此未识甲骨字i与未知甲骨字连接个数越少,权重越小,分母就越小,S值就越大。未识甲骨字i可利用的信息就越多,i字的语义被预测的可能性就大。如果一个已识甲骨字j与其它已识甲骨字连接的权重越大、而与其它未识甲骨字连接的权重越小,Sj的值就越大,为预测其它未识甲骨字提供的信息就越少。总之,在甲骨文字系统中,对于一个已识甲骨字j,如果它的Sj值越大,甲骨字j对破译未识甲骨字提供的可用信息就越少;对于一个未识甲骨字i,如果它的Si值越大,说明可用信息越多,被破译的可能性就越大。
2.3 基于模块结构的未识甲骨字模糊语义预测
模糊语义是甲骨字的较为笼统的语义,如甲骨字描述了哪种场景:战争、祭祀、打猎等。在甲骨学领域,描述某一场景往往需要多个甲骨字。而在计算机领域,描述同一场景的甲骨字往往具有很强的局部性,进而形成一个类别。我们可以把描述同一场景的甲骨字识别问题转化为计算机领域中的分类问题。特别是在本文中,由于我们用甲骨字网络捕捉上下文语境信息。因此,我们可以用网络分割的方法预测未识甲骨字的模糊语义。在复杂网络中,模块识别是网络分割的一种典型的方法。模块结构[21]是复杂网络的一种重要属性。模块是网络的一个子网络,它要求模块中的结点紧密相连,而模块间的结点连接稀疏。以图3中的网络为例,根据模块的定义和模块挖掘算法,网络可以分为3的模块:结点1、2、3、4(简写为1-4)构成一个模块,结点5-7、8-12分别构成另外两个模块。模块结构的重要特点是模块内的结点具有相同的属性。利用此特点可以预测网络中未知结点的属性(见图3):在含有8-12结点的模块中,如果结点12的属性未知,而结点8-11描述的是殷商时代“祭祀”的场景语义,那么可以预测结点12也是用来描述“祭祀”的场景。
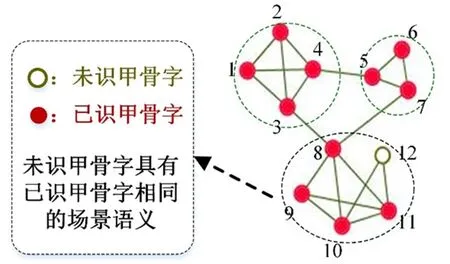
图3 基于模块结构的未识甲骨字场景语义预测模型
基于模块结构的未识甲骨字模糊语义预测的核心任务是设计有效的模块识别算法。在设计模块识别算法时需要注意甲骨字网络模块的独特性,即甲骨文字系统的两个特点:一是描述场景语义所使用的甲骨字个数较少;二是同一个甲骨字可能会参与不同场景语义的描述。甲骨文字系统中的两个特点在复杂网络中表现为:一是甲骨字网络中的模块尺度较小,模块中含有的结点较少;二是模块中的结点具有一定的重叠性。这些特性说明,甲骨字网络的模块结构具有很强的局部网络性质。
2.4 语境和字形信息融合的未识甲骨字语义预测
基于模块结构的未识甲骨字模糊语义预测只使用上下文语境信息,并没有使用甲骨字的字形信息。因此,预测的语义准确度并不高。为了提高语义预测的准确度,需要引入字形信息。在网络分割的算法中,我们可以把字形信息作为网络分割的辅助信息加入到算法中,进而提高分类的准确性。甲骨文字的部首在甲骨文系统中具有统领的含义,即具有相同部首的甲骨字可能描述相似的场景。在上下文语境信息中加入部首信息可以有效提高未识甲骨字语义预测的正确性。
深度学习由于其强大的功能,被应用到各个领域,并产生了一些高性能的算法,如深度卷积网络,递归神经网络等。这些算法在图像、视频和语音的识别等领域都取得了成功地应用。卷积神经网络[22]是深度学习应用最成功的领域之一。卷积神经网络首先利用卷积抽取图像的局部特征;然后利用池化过程减少冗余信息,保留重要信息,达到降低时间复杂度的目的;最后采用非线性激活函数输出图像特征。卷积、池化和非线性激活函数构成一个卷积层,而卷积神经网络通过融合较深的卷积层抽取图像的有效特征。卷积神经网络在图像分类、目标检测、图像分割方面均取得前所未有的准确率。虽然卷积神经网络具有良好的性能,但是对图(或称网络)数据中结点特征的抽取性能不佳。如语言网络、社会网络和生物网络等图数据。这些数据属于非欧式空间的数据,传统的离散卷积无法提取结点特征。图卷积网络[23]借鉴卷积神经网络的思想对图数据进行卷积,并完成图的结点分类。图卷积网络主要任务是把图中的结点以及结点特征输入到一个函数中,输出为图中各个结点的特征信息,并利用这些结点特征实现结点分类、链路预测等任务。我们可以以图卷积网络为工具,以甲骨字网络为输入参数,甲骨字部首信息为结点特征向量,实现甲骨字网络的分割,进而预测未识甲骨字的模糊语义。
三、未识甲骨字的精准语义预测
精准地预测未识甲骨字的语义比预测模糊语义难度要大。精确预测未识甲骨字的语义需要推理甲骨字到现代汉字的演变过程。如果一个具有演变过程的甲骨字,再辅助上下文语境信息即可精确预测未识甲骨字的语义。因此,利用计算机技术学习甲骨字的演变规律是精准预测未识甲骨字的主要任务。我们可以先使用先验知识训练人工智能方法的模型,然后利用训练的模型预测未识甲骨字的演变过程,进而精确推理其语义。但是,利用人工智能的方法学习甲骨字的演变过程存在很大的挑战性。比如,在演变过程中,有些字使用了假借字,而假借字在演变过程中具有很强的字形波动性,字形的波动性会导致训练模型不准确。
四、总结
未识甲骨字的语义预测是甲骨文信息处理研究中最为重要的内容。上下文语境信息和字形信息是预测未识甲骨字语义的重要因素。本文通过构建甲骨字共现网络捕捉上下文语境信息,并利用图卷积网络为工具,以甲骨字部首为特征预测未识甲骨字的模糊语义。除此之外,我们以甲骨字演变为线索提供给读者一个精准预测未识甲骨字语义的思路。
猜你喜欢
安阳师范学院学报(2022年2期)2022-04-22
电子制作(2022年1期)2022-01-28
殷都学刊(2021年4期)2021-11-27
电子制作(2021年14期)2021-08-21
教育周报·教育论坛(2021年21期)2021-04-14
文物季刊(2021年1期)2021-03-23
养生保健指南(2018年3期)2018-04-13
大观周刊(2017年4期)2017-07-06
火花(2015年6期)2015-02-27
