
Bootstrap方法在统计推断中的应用
2020-11-24 08:56尤亦玲广东财经大学
消费导刊 2020年47期
尤亦玲 广东财经大学
一、背景
统计推断是从样本出发推断相应的总体, 可以分为参数法和非参数法。早期的统计推断是以大样本为基础的。自1908年,英国统计学家威廉·戈塞特(Willam Gosset)发现了t分布后,就开启了针对小样本的研究。1920年,费希尔(Fisher)提出了“似然(likelihood)”的概念,为世人提供了一种更为高效的统计推断思维方法。1979年,美国斯坦福大学统计学教授Efron,提出了一种新的增广样本系统的方法,为解决小样本的评估问题提供了新的思路,这种方法就是Bootstrap方法,也叫自助法。
统计学中“Bootstrap”法是指从原样本自身的数据中不断重复抽样,从而获得新的样本及统计量。它的优势在于根据给定的原始样本复制观测信息,因而不需要进行分布假设或增加新的样本信息就可以可对总体的分布特性进行统计推断,属于一种非参数统计方法。
二、方法理论介绍
(一)Bootstrap重抽样理论
Bootstrap重抽样的基本思想是:在原始数据的范围内作等可能的、有放回的再抽样, 样本容量仍为n,原始数据中每个样本每次被抽到的概率均为1/n , 我们将这种抽样方法所得的样本称为Bootstrap样本。每次抽样可得到参数的一个估计值,这样重复若干次。
设随机样本是独立同分布的,。假设为总体分布F的某个参数,是观测样本的经验分布函数,是的估计,则可以通过以下步骤来实现Bootstrap估计:
第一步,对Bootstrap重复的第b次(b=1,2,…,B),先有放回地从中抽样得到再抽样样本,然后根据计算;
第二步,的Bootstrap估计为的经验分布函数。
(二)Bootstrap方法的标准差、偏差估计
估计量的标准差的自助法估计,是Bootstrap重复的样本标准差:
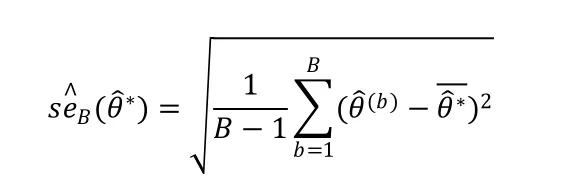
其中。我们将估计量的偏差定义为
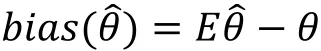
事实上,根据上式计算偏差有一个很明显的难点在于,当的分布未知,或者形式很复杂时,期望的计算也就变得很困难甚至不可能,因此在这种情况下偏差就是未知的。但是当我们拥有样本数据时,就是的一个估计,而期望可以通过Bootstrap方法进行估计,从而得到偏差的估计:
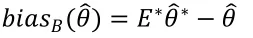
表示Bootstrap的经验分布。
可见,一个估计量的Bootstrap偏差估计,就是通过已有样本的估计量来代替,并使用的Bootstrap重复来估计。对一个有限样本,有的B个独立同分布的估计量,则的均值是期望的无偏估计,因此偏差的Bootstrap估计为
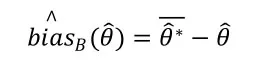
其中。若偏差为正,则说明在平均水平上过高估计了,反之,则说明在平均水平上低估了。因此,可以对估计量进行偏差修正,得到
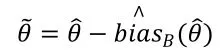
(三)Bootstrap区间估计的四种类型
1.标准Bootstrap
假设是参数的估计量,它的标准差为。如果的分布服从或近似服从正态分布,那么,当显著性水平为,并且是的一个无偏估计时,就有的(1-)标准正态Bootstrap置信区间为
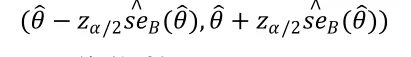
2.百分位数Bootstrap
该方法的核心在于:统计量在(1-)水平下的置信区间的上下限,分别为估计量的Bootstrap经验分布的第和第()分位点。
事实上,可以对百分位数区间做进一步修正,得到更好的Bootstrap置信区间,使其具有更好的理论性质和实际覆盖率。其原理是对(1-)水平下的置信区间,使用两个因子来调整和()分位数,其一为对偏差(bias)的修正,另一个是对偏度(skewness)的修正。前者记为,后者记为a。我们将这种估计方法估计的结果称为更优的Bootstrap置信区间,简称为BCa。
在计算(1-)BCa置信区间时,首先计算Bootstrap重复经验分布函数的分位数,即BCa区间的上下界,则上述中的偏差修正因子的估计为
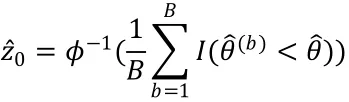
而加速因子是从Jackknife重复中估计得到的。
3.基本Bootstrap
在的分布未知时,由于Bootstrap重复下的样本分位数满足
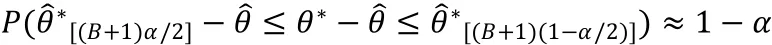
因此,(1-)置信区间为

4.t区间Bootstrap
在多数情况下,即使满足正态分布假设,且是的一个无偏估计时,也未必服从正态分布,这是因为是我们认为估计出来的。同时,由于Bootstrap估计的分布是未知的,因此也不能认为Z服从t分布。在这种情况下,前人就通过再抽样的方法得到了一个“t类型”的统计量的分布,以此来改进标准Bootstrap区间估计。
假设观测样本,则(1-)水平下的Bootstrap t置信区间为:
根据以往的设计经验来看,城市居民供水系统多会采取管道分流方式,从城市给水系统中分流至各大住宅小区当中,目的在于及时供给人们日常饮用水源。针对于此,建筑施工单位在进行给排水设计过程中,需要在住宅小区的管道处安装倒流防止阀装置,这样做的主要目的在于避免水流出现严重的倒流问题,造成供水压力的明显提升。
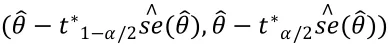
其中通过以下方法得到:
第一步,计算观测到的;第二步,从X中有放回地抽样得到第b个样本,从中再抽样计算得到,以及Bootstrap标准差估计,据此可以计算第b个重复下的“t”统计量;第三步,重复上述过程,将的分布作为推断分布,找出样本分位数;第四步,根据Bootstrap重复可得标准差估计;第五步,计算置信区间。
从上述计算过程可以发现,Bootstrap t区间法需要进行Bootstrap嵌套,严重影响了计算速度。
三、方法分析讨论
(一)Bootstrap重抽样法的应用
假设我们观察到一组样本,从中再抽样,依照抽到1,2,3,4,5的概率分别为0.2,0.3,0.2,0.1,0.2 进行。因此,从中随机选择的一个样本,其分布函数就是经验分布函数。 事实上,样本可以看作是从Poisson(2)中随机产生的,因此利用R软件我们可以实现对的估计,并与Poisson(2)的分布相比较,结果如下:

图3.1 Bootstrap重抽样的估计
(二)标准差、偏差的Bootstrap估计
R软件中bootstrap程序包里的law82数据集,记录了美国82所法律学校入学考试的平均成绩(LSAT)和GPA,估计二者之间的相关系数,并求样本相关系数的标准差和偏差的Bootstrap估计。
对于成对数据可以通过样本相关系数估计相关系数,计算结果显示,样本相关系数为0.80,使用bootstrap方法估计的标准差的结果。
此外,在重复2000次下的boot函数计算的标准差估计为0.05,该结果与之前的结果相差无几。同时,boot函数还给出了该组数据的样本相关系数bootstrap偏差估计,其结果为-0.000727641。
通过偏差的定义自行编程进行求解,得到的结果bias=-0.0009563065,与boot函数的运算结果非常接近。
(三)Bootstrap区间估计
继续针对上述law82数据集讨论相关系数统计量的95%置信区间,利用boot包里的函数boot.ci可以直接计算得到基本bootstrap区间、标准正态bootstrap区间、百分位数bootstrap区间和BCa区间。我们还可以根据Bootstrap t区间法的定义,利用自编函数来计算相关系数置信区间,结果如下表所示:

表3.1 law82相关系数统计量bootstrap置信区间估计结果
由上表结果可以看出,前两种估计方法和后三种方法的结果有较大差异,而在后三种方法中,可以看到BCa置信区间的区间长度是最小的,可以认为它的估计是较为准确的。
四、实际数据
考虑bootstrap包里的scor考试成绩数据,利用pairs函数绘制每对变量的散点图,观察相关性。
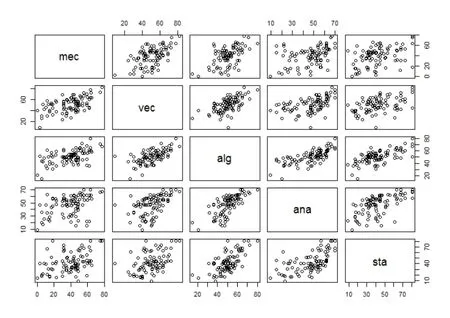
图4.1 scor数据集各变量散点图
根据上图所示结果,我们可以猜测(mec,vec),(alg,ana),(alg,st a),(ana,sta)这四组变量间可能具有较强的相关性,利用R软件计算其相关系数分别为0.55,0.71,0.66,0.61,利用Bootstrap估计样本相关系数标准差。

表4.1 四组变量相关系数的Bootstrap标准差估计结果
在scor数据下,记协方差矩阵为,其特征根为 ,则
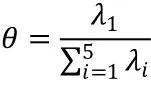
表示了主成分中第一主成分对方差的解释比例。现令为样本协方差矩阵的特征根,可以利用boot函数直接得到的Bootstrap偏差和标准差估计,程序运行结果显示的偏差为0.0022,标准差为0.0472。
利用Bootstrap重复样本,对的95%置信区间,分别采用百分位数和修正的百分位数Bootstrap置信区间进行估计,并更改重复次数观察结果,如下表所示:

表4.2 的95%置信区间估计结果
由上表可知,不同的模拟次数会对置信区间的结果造成一定的影响,但总体来说差别不大。
五、总结
本文基于对Bootstrap统计推断方法的理论介绍,利用实际案例实现了在总体分布未知情况下,对样本统计量的标准差、偏差估计,以及置信区间估计。其核心思想在于重复抽样,应用的关键在于理解“子样本之于样本,等于样本之于总体”,优势之处在于小样本增强。总的来说,Bootstrap是一种应用十分简便的非参数统计推断方法。
猜你喜欢
内江师范学院学报(2022年4期)2022-04-27
湖北师范大学学报(自然科学版)(2021年3期)2021-09-08
数学物理学报(2021年1期)2021-03-29
当代医药论丛(2021年3期)2021-03-17
铁道通信信号(2018年9期)2018-11-10
现代营销·学苑版(2016年12期)2017-01-23
电测与仪表(2015年6期)2015-04-09
赤峰学院学报·自然科学版(2015年15期)2015-03-21
数学物理学报(2014年3期)2014-03-11
医学理论与实践(2012年4期)2012-12-09
