
基于低通滤波模型的行人再识别算法
2020-11-30 05:48王庚润
计算机应用 2020年11期
花 超,王庚润*,陈 雷
(1.信息工程大学,郑州 450001;2.解放军31101部队)
(∗通信作者电子邮箱wanggengrun@gmail.com)
0 引言
随着监控设备的普及,大规模的摄像机网络逐步在机场、地铁站、校园以及商业办公区等公共区域被广泛部署,因此多摄像机跟踪技术越来越被人们所重视。而如何在多摄像机中对同一个行人进行关联,是多摄像机跟踪分析的基础。鉴于行人再识别广阔的应用前景,目前有许多学者对其进行了深入的研究。
由于各个摄像机的光线、角度、遮挡和背景等所处的环境不同,同一行人在不同的摄像机图像中存在较大的差异,导致行人再识别存在识别精度较低的难题。为了提高其识别精度,目前主要有两种解决思路:一是从特征描述的层面致力于寻找更加有效描述目标的特征。Zhang等[1]利用行人的衣服、姿态、步态等信息构建行人模型;Wang 等[2]根据正样本的特有特征和负样本共有的全局特征,提出基于区域交互排序的算法;Satake 等[3]从各个方向采集行人图像,利用尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)特征构建行人外观模型,以此解决行人姿态变化的问题;Liu 等[4]对每一个模板的行人图像提取特征,并根据它们自身和相互间的显著性给予不同的权重;曾明勇等[5]根据人体的结构信息,提取行人图像的空间直方图和区域协方差特征,再融合这些外观特征对目标进行建模。由于行人的整体特征易受遮挡和背景的干扰,目前大多数学者都倾向于将行人图像进行部件分割或者分块再进行特征提取。Bhuiyuan 等[6]将行人图像进行分割,再提取不同部位的特征,然后再根据识别能力强弱,对身体各部位进行排序和选择。文献[7]中的SDALF(Symmetry-Driven Accumulation of Local Features)方法对图像进行分割和检测等预处理,从中提取出最大稳定颜色区域、重复纹理块和色调饱和值(Hue,Saturation,Value,HSV)颜色直方图特征后再对行人图像进行识别。范彩霞等[8]利用行人外观模型对行人图像进行预识别,通过k-means 方法将行人图像分为躯干、腿和头,忽略头部特征,再提取各部分主色区域的局部颜色和形状特征。Huang等[9]对行人图像进行分块,利用稀疏模型对每一个行人图像进行描述,并采用自适应的方式赋予不同图像不同的权重。
二是采用度量学习的方法,寻找能够度量同一行人不同外观空间的变换矩阵,使变换后同一行人图像间的距离尽可能小,同时最大化不同行人图像之间的距离。杜宇宁等[10]不仅利用了行人图像的特征差分空间,还关注了图像中每个个体的外貌特征,通过学习二次相似度函数来估计行人间的相似度;Liong 等[11]同时利用正样本信息和负样本信息,以解决训练图像不足的问题,然后再用标准贝叶斯学习度量矩阵;杜宇宁等[12]利用统计推断学习行人图像间的度量函数,根据此函数度量图像间的相似度;齐美彬等[13]利用不同子空间中的行人特征学习度量矩阵和相似度矩阵,并给予不同权重,构造出最终的相似度函数;Guillaumin 等[14]从度量估计的可能性角度提出LDML(Logistic Discriminant Metric Learnin)算法,该算法将每一对图像在梯度方向的影响控制在可能性之内;Davis 等[15]提出ITML(Information-Theoretic Metric Learning)算法,通过信息论的方法规范估计度量,从而最小化预先定义的度量间的距离。
特征能增加行人的辨识度,而度量学习方法则可以使辨识度得到进一步的提升。当提取行人特征时,常见的行人再识别算法将先对行人图像进行部件分割,以获取更精细的特征。但行人部件检测和分割准确率是难以保证的,针对这一问题,Zhao 等[16]提出基于块匹配的行人再识别算法,通过行人图像分成若干个小块,再在小块图像上提取显著度特征。由于利用了更为精细的粒度,因此该算法可以取得较好的识别效果;但该算法假定每一个小块都是行人的特征小块,而实际上因为遮挡和背景的干扰,有一些小块并非某个行人的独有特征,而多数行人图像中都具有的相似小块在行人间相似度计算上是无意义的,在数据稀疏时反而会影响正常的行人再识别。
针对上述多数行人图像中所共有的相似小块问题,本文利用通信系统中的低通滤波器原理,通过低通滤波系统对行人图像进行处理。计算时,先将行人图像进行分块,通过计算各个小块的相似性,得到相似小块的个数,个数较多的被认为是高频噪声特征,个数较少的则被认为是有益特征;通过设置低频截止频率对高频的噪声特征进行抑制,同时对低频有益特征进行适当增益;最后利用滤波后的行人图像进行行人间相似度计算。实验结果表明,本文算法可以取得较高的识别精度。
1 系统模型
1.1 相关定义
本文中的噪声特征、噪声频率和截止频率等概念具体定义如下:
噪声特征 将行人图像分成若干个小块。不同行人图像中都具有的相似特征小块是不具有代表性的,对于行人间相似度的计算没有太大帮助;而在数据稀疏的情况下,甚至会影响最终的识别结果。这些特征小块被定义为噪声特征,记为nos。
噪声频率 计算各小块与图像中其他小块的欧氏距离,若小于一定值,则认为它们是相似的。统计各小块在其他行人图像中的相似小块数目,定义为噪声频率,记为f(nos)。因为噪声特征至少具有2 个相似小块,所以f(nos) ≥2,否则不认为其为噪声特征。f(nos)越大,该特征小块具有越多的相似小块,其越有可能为遮挡物或背景,在计算行人间的相似度时干扰越大、越有害;而f(nos)越小,则说明该小块是某个行人的特有特征,具有较强的区分性。
截止频率 低通滤波器中设置的低频频率值,称为截止频率,记为fq。
小块权重 特征块Pij经过低通滤波器时进行衰减或者增益的数值,记为
小块相似度阈值 小块间的相似度数值,小于等于这个值则认为它们是相似的,记为dq。
1.2 系统设计
常见的行人再识别方法不能很好解决遮挡和背景干扰问题,而实际上因为遮挡和背景的干扰,有一些小块并非某个行人的独有特征。大多行人图像都具有的相似小块在行人间相似度计算上是无意义的,在数据稀疏时,甚至会影响最终识别结果。本文针对这一问题提出一种低通滤波行人再识别系统,该系统的组成框图及图像处理流程如图1所示。

图1 基于低通滤波的行人再识别系统Fig.1 Person re-identification system based on low-pass filtering
该系统中各模块的作用如下:
行人图像块特征 对行人图像进行分块,再对小块提取特征向量。
小块间相似度 用L1 范数距离计算目标行人图像P 中的小块与其他行人图像中小块的相似度。
查找小块 对目标行人图像P 中的所有小块查找在其他行人图像中的相似小块,服务于后面的噪声提取和权重评分模块。
噪声提取 根据小块与其他行人图像中相似小块的个数,提取该小块的噪声频率。
低通滤波 对噪声进行低通滤波,使得频率高于截止频率的高频噪声特征小块迅速衰减,同时使低于截止频率的有益特征小块得到适当增益。
权重评分 低通滤波后得到的各个小块的权重值。
小块权重 经过权重评分后得到的目标图像P 中各个小块权重值矩阵。
乘法器 低通滤波得到的各个小块的权重值与行人图像中对应特征小块相乘。
行人间相似度 计算出行人间相似度大小。
1.3 系统中相关处理
行人图像分块及特征提取 在行人图像的垂直和水平方向上,分别用分辨率为v × h 的固定窗口进行滑动操作,滑动步长相应为v/2和h/2。因此,将得到m × n个小块,其中m和n分别为水平和竖直方向上的小块个数。该步长的设计,使小块可以完整覆盖行人图像。本文将图像分辨率统一标准化为128×48,窗口大小为8×24,滑动步长在垂直方向为12、水平方向为4。通过对分块后的小块进行提取特征,行人图像P可以表示为:

其中Pij是图像P中第i行、第j列的小块所对应的特征向量。
小块间相似度 利用L1 范数计算不同小块间的相似度,例如行人图像P中小块Pij和行人图像Q中小块Qab,二者的相似度计算如下:

噪声提取 Zhao 等[16]证明行人图像在垂直方向上变化不大,而在水平方向上变化比较显著。因此在计算图像小块间的相似度时,考虑到计算的复杂度,可以不用计算目标小块与图像中所有小块间的距离,只需计算与该小块在同一水平及上下位置小块的相似度,即计算Pij与Qab(a=i -1,i,i +1;b=1,2,…,m)的相似度。若d(Pij,Qab)≤dq,则认为小块Pij和Qab相似,其中dq是相似度阈值。
假设有l 张行人图像,则图像P 中小块Pij的噪声频率f(nos)ij计算如下:

其中,噪声基数fαPij定义为:

小块相似度阈值 dq是小块相似度阈值,小于等于这个值,则认为两个小块相似。dq值是预先定义的,找一个行人的2 张不同图像,计算小块间的相似度,取小块间的相似度的均值 记作在ETHZ(Eidgenössische Technische Hochschule Zürich)[17]、VIPeR (Viewpoint Invariant Pedestrian Recognition)[18]和 i-LIDS(imagery Library for Intelligent Detection Systems)[19]数据集中各提取个行人的不同图像,共β个行人的图像来计算初始阈值dq′,计算如下:

低通滤波处理 低通滤波是本文的核心,是根据通信原理中的低通滤波器设计的。利用截止频率,使得高于截止频率的噪声特征迅速衰减,低于截止频率的有益特征得到适当增益。低通滤波的核心是设计滤波函数f和设置截止频率fq,使得上述条件能够得到满足。
本文利用改进的Logistic 函数进行低通滤波。Logistic 函数常用于机器学习中,可以很好地表征人类学习和种群发展等过程。标准的Logistic函数定义如下:

其定义域为(-∞,+∞),值域为(0,1)。Logistic 函数图像如图2所示。
取flogistic关于y=0.5对称的函数,其在x ≥0时的图像如图3所示。

其中:γ 是常数,用来调节衰减增益幅度的大小;f(nos)Pij∈[1,β]为小块Pij的噪声频率,β 是行人图像个数;fq为截止频率。f函数是以f(nos)Pij为自变量的单调递减函数。
图2 Logistic函数的图像Fig.2 Figure of Logistic function
图3 在x ≥0时的图像Fig.3 Figure of when x ≥0
改进的低通滤波函数f需要满足以下3个条件:
1)f(nos)Pij<fq时,特征小块Pij的权重得到适当增益,且随着f(nos)Pij的增大增益逐渐减少。为防止过度增益和自激,设定最大增益为1.1,即f(nos)Pij=1 时,f=1.1。该设定可满足对行人特有特征进行适当增益的要求;
2)f(nos)Pij=fq时,f=1;
3)f(nos)Pij>fq时,f会快速衰减,且随着f(nos)Pij的增大,f趋近于0。这样可满足对于共有的无用高频噪声特征小块进行快速衰减的要求。
要满足以上3 个条件,关键是选择合适的γ 和fq。经计算当γ=5 时,f 可得到较好的效果。下面将推导以获取合适的fq。
系统中需要一个合适的fq,使得不同频率下的衰减和增益数值适当。令fq=0.5% × β、1% × β、2% × β(β 为所有行人图像个数),即fq的选择与图像的个数有关,图像越多则fq取值越大,这是符合实际的。考虑到ETHZ 数据集共有8 000 多张图像、VIPeR 数据集共有1 264 张图像、i-LIDS 数据集共有479 张图像,为提高系统的普适性本文选取β=1000 进行实验,即 fq=5、10、20。定义函数 g(fq),使得g(fq)=max(f(f(nos)Pij),则有:

g(fq)是以fq为自变量的函数,其含义是在噪声频率最低时的小块可得到的最大增益。当fq=5 时,g(5) ≈1.124 3,即最大增益值为1.124 3;此时门限过低,在一些单个行人图像数目较多情况下,会将一些行人有益特征小块当成噪声特征小块。当fq=10 时,g(5) ≈1.11,即最大增益值为1.11,此时衰减合适,能较好满足系统要求;当fq=20 时,g(5) ≈1.104,即最大增益值为1.104,此时衰减过于缓慢,当噪声频率较大时,不能有效抑制噪声特征小块。因此本文选择fq=10,此时函数f设定为:

当fq=5、10、20 时,函数f随自变量f(nos)Pij变化如图4 所示。可以看出,本文提出的低通函数f 在定义域是单调递减,且迅速衰减趋于0 的。在噪声频率低于截止频率时,特征小块得到适当增益;而在噪声频率高于截止频率时,特征小块又得到快速衰减,这说明本文的函数符合低通滤波处理要求。
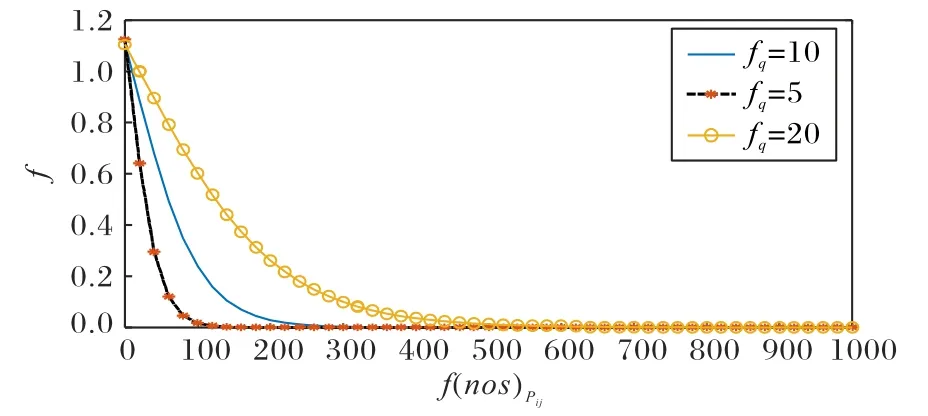
图4 滤波函数f随自变量f(nos)Pij变化Fig.4 Filtering function f varying with f(nos)Pij
小块权重处理 行人图像的小块Pij经过低通滤波处理后得到的该小块的权重为:

经过计算得到行人图像中小块权重WP为:

行人间相似度 经过前面的步骤计算出行人图像P各个小块的权重值,利用Zhao 等[16]的方法查找行人图像Q 中与图像P中对应的小块,并计算小块间的相似度,再乘以该小块的权重,累计小块间的距离即为2行人图像间的相似度。
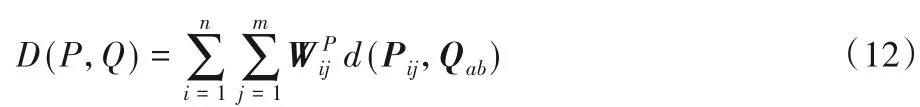
其中:D(P,Q)为图像P 和Q 间的相似度,Qab为利用Zhao 等[16]的方法查找出的图像P中小块Pij在图像Q中的对应小块。
2 实验结果
2.1 实验数据集及评价准则
Schwartz 等[17]首先将ETHZ 数据集用于行人再识别研究。在ETHZ 数据集中,共有ETHZ1、ETHZ2 和ETHZ3 三个数据库,这三个数据库中分别有83、35 和28 个行人以及4 875、1 936 和1 762 张图片。ETHZ 数据集中的行人图像大小不一,实验时需要先将所有图像标准化为128×64像素。
VIPeR 数据集[18]是在学校中采集的,包含632 个行人,每个行人有2 张图像。每个行人的图像都来自2 个不同的摄像头,因此该数据集的视角变化比较明显。此外,该数据集的行人图像姿态和光照变化比较显著。同样地,也需将所有图像标准化为128×64像素。
I-LIDS 数据集是由Zheng 等[19]在i-LIDS 视频数据集基础上发布的。该数据集在机场大厅采集,其中的行人图像由多个不同角度的摄像头所拍摄,共有119 个行人479 张图像,每张图像也将被标准化为128×64 像素。该数据集的大部分行人图像都存在遮挡的情况。
评价行人再识别算法的性能通常采用累计匹配特性曲线(Cumulative Match Characteristic,CMC)衡量。在CMC 中,曲线值表示前k个可能匹配行人结果里包含目标行人的概率。
2.2 实验特征
在实验中,利用文献[16]中提到的显著性特征和颜色直方图来表示行人图像的特征,对应的算法称为显著性特征的低通滤波方法和颜色特征的低通滤波方法。其中颜色直方图用RGB(Red,Green,Blue)和HSV颜色空间表征,每个颜色通道都单独提取一个8间隔(bin)的直方图特征。
2.3 参数选择
选取β 个行人的图像来进行实验,取β=90,150。当β=90 时,结果如图5(a)所示。从图中可以看出,当dq=dq′时,大多数小块的噪声频率都很高,即大多数小块都会被认为是噪声特征,说明此时小块相似度阈值设置过大;当dq=dq′/2时,噪声频率大于10 的特征块数与小于10 的数近似相等,而实际中噪声特征只是占很少一部分,因此说明此时小块相似度阈值还是过大;当dq=dq′/3 时,特征块的噪声频率大多在10 以下,同时有少部分噪声特征的频率在10 以上,这是符合实际噪声分布的;而当dq=dq′/4 时,特征块的噪声频率只有极少数是大于等于10 的,这与实际噪声分布不符。因此,当β=90时可以选取dq=dq′/3作为小块相似度阈值。
当β=150 时,噪声频率和行人特征块数目关系如图5(b)所示。从图可以看出,噪声频率和特征块数目的关系和β=90时二者的关系基本相似。
综上,本文选取dq=dq′/3作为小块相似度阈值。

图5 β为90或150时,噪声频率和特征块数的关系Fig.5 Relationship between noise frequency and the number of feature blocks when β is 90 or 150
2.4 实验结果与分析
下面对本文算法与常见行人再识别算法在数据集上的识别效果进行比较。其中,SDALF 方法[7]、曾明勇方法[5]、范彩霞方法[8]分别如前所述,而eSDC_knn 和eSDC_ocsvm 为Zhao等[16]根据不同的训练方法提出的两种不同的方法。为减少偶然性,每次实验进行10次取均值作为最终结果。
首先,为了验证前文选取的截止频率fq和小块相似度阈值dq的有效性,本文在ETHZ 数据集上对不同选值所能达到的识别精度分别进行了测试。实验中,将ETHZ数据集3个子库融合为一个,在其他参数不变的情况下,本算法所得到的实验结果如图6 和图7 所示,结果表明,前述的fq和dq取值是符合预期的。

图6 不同fq取值下的识别精度Fig.6 Identification accuracy with different fq

图7 不同dq取值下的识别精度Fig.7 Identification accuracy with different dq
几种常见算法在ETHZ 数据集上的累积匹配特性曲线如图8 所示。从图中可以看出本文算法的识别结果好于常见的算法。在排名等级为1(k=1)时,在几种方法中显著性特征的低通滤波算法识别率最高,达到了84%,高于eSDC_knn 的82%和eSDC_ocsvm 的81%,同时显著性特征的低通滤波器比经典的SDALF 方法提高了近20%,而简单的颜色直方图特征低通滤波方法相比SDALF 方法也有近15% 的提高,与eSDC_ocsvm 相当。这对于实际应用是十分重要的,因为行人再识别就是在多个行人中查询出目标行人。由于ETHZ 数据集比较简单,遮挡和背景干扰较少,不能很好地体现本文算法的优越性,而接下来存在遮挡和背景干扰较多的VIPeR 和i-LIDS数据集,可以进一步展现本文算法的优势。
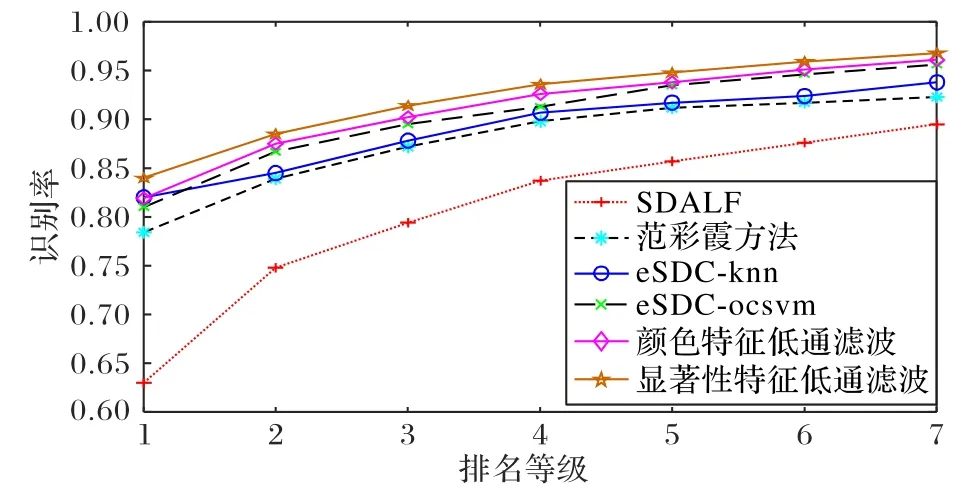
图8 几种算法在ETHZ数据集上的累积匹配特性曲线Fig.8 Cumulative matching characteristic curves of several algorithms on ETHZ dataset
VIPeR数据集比ETHZ数据集复杂得多,因为该数据集中的行人图像视角、姿态和光照变化比较明显。实验结果如图9 所示,从图中可以看出本文算法在该数据上的优势比较明显。在排序等级为1 时,本文的2 种算法识别率是最高的,其中显著性特征的低通滤波方法比SDALF 方法有了近22%的提升,比其他几种方法也有近15%的提升。排名等级为5 的识别率也是很重的,因为在现实应用中,为了提高最终识别精度,通常要令机器先给出排名靠前的几张行人图像,然后再人工选取出目标图像。而在排名等级为5 时,本文的算法对几种经典算法性能也有着显著的提升,显著性特征的低通滤波算法对SDALF 方法有着近25%的提升;对范彩霞和曾明勇的方法也有着近5% 和13% 的提升;与本文方法相近的eSDC_knn和eSDC_ocsvm相比,更有近15%和10%的提升。

图9 几种算法在VIPeR数据集上的累积匹配特性曲线Fig.9 Cumulative matching characteristic curves of several algorithms on VIPeR dataset
i-LIDS 数据集中遮挡物较多,这是其他数据集中所没有的,虽然这更加符合实际情况,但也增加了识别难度。本文的算法主要解决的是遮挡和背景的干扰问题,因此在该数据集可以明显体现出本文算法的优势。该数据集上的识别结果如图10 所示,图中清晰地展示了本文算法比其他算法的优势,特别是本文提出的显著性特征的低通滤波方法。排序等级为1 时,显著性特征低通滤波算法优势明显,比eSDC_knn 提高了近20%,比eSDC_ocsvn 提高了近15%;而颜色直方图特征低通滤波算法识别率也明显高于其他算法。当排序等级大于8时,本文的2种算法识别率均高于其他算法。

图10 几种算法在i-LIDS数据集上的累积匹配特性曲线Fig.10 Cumulative matching characteristic curves of several algorithms on i-LIDS dataset
为了进一步验证本文算法在遮挡和背景干扰下的效果,研究中把i-LIDS 数据集上由于行人视角、姿态和光照方面的变化,存在大的光照变化和遮挡影响的95 个人的348 张图像单独制作成一个数据集,并在该数据集上对本文算法进行了测试。此时的测试结果如图11 所示。可以看出,虽然由于图像变差导致几种算法的识别精度均有所下降,但本文算法仍取得了相对较高的识别率。
上述3 个数据集是行人再识别中比较常用的,如果某个算法能对这3 个数据集都能取得较好的识别结果,则可以说明该算法能较好地解决行人再识别问题。本文的行人再识别算法在上述3 个数据集中都取得了较好的识别结果,这在一定程度上说明了本文算法的优越性和实用价值性。实验结果还证明本文算法比其他经典算法识别率更高,更能适应实际应用的需求。

图11 几种算法在修剪的i-LIDS数据集上的累积匹配特性曲线Fig.11 Cumulative matching characteristic curves of several algorithms on modified i-LIDS dataset
3 结语
行人再识别技术在实际生活中的重要作用,已经引起了广泛的关注。理想中的行人再识别可以实现类似《速度与激情》中的“天眼”系统、《碟中谍》中根据行人图像查询特定的目标那样的功能。然而现阶段遮挡和背景的干扰是行人再识别研究的难点和热点之一,针对这一问题,本文提出了基于低通滤波的行人再识别方法。通过利用背景和噪声出现在行人图像中的频率较高这一特征,结合改进的低通滤波算法,可以有效降低遮挡和背景的干扰。通过在常见的行人再识别数据集上进行验证,本文算法达到了比现有算法更好的识别效果。在接下来的研究中,可以考虑在大数据背景下提升行人再识别技术的实时性,这将是该技术真正应用于实际的重要因素。
猜你喜欢
电脑爱好者(2021年12期)2021-06-22
意林(2021年5期)2021-04-18
舰船科学技术(2021年12期)2021-03-29
天天爱科学(2020年6期)2020-09-10
劳动保护(2019年3期)2019-05-16
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
探索科学(2017年4期)2017-05-04
哈尔滨理工大学学报(2016年2期)2016-09-12
饮食科学(2016年7期)2016-07-27
