
基于Python的数据爬虫的设计与实现
2020-12-09 05:43杨国军
数字技术与应用 2020年10期

摘要:本文针对互联网的海量数据信息查找、搜索繁琐的问题,提出通过网络爬虫的理念,模仿人的过程来帮助人们查找更有价值的数据信息,节约时间,提高工作效率。并针对网络爬虫的概念,工作原理,以及系统分析设计与实现进行了详细的分析和讨论,并提出行之有效的实现方案。
关键词:python;爬虫系统;设计;实现
中图分类号:TP312.1 文献标识码:A 文章编号:1007-9416(2020)10-0000-00
当代万维网和互联网技术发展迅猛,海量数据让人们的工作和生活反而变得繁琐,为了更好的找到对我们有利用价值的数据和信息,使用手动操作会过于繁琐。如在浏览微博网站时,发现很多评论比较有值得我们分析的地方,需要下载到本地,为此通过网络爬虫的理念,模仿人来帮助人们查找数据,减轻搜索时间,提高工作效率。
1 网络爬虫
网络爬虫其实就是模仿人来对我们想要访问的网页内容进行访问,模仿人来获取我们需要的数据,并将这些数据下载并保存到我们想要存放的地方,有时我们需要获取的数量很庞大而依靠我们自己进行操作就会显得很繁琐,所以我们需要用到爬虫来获取大量的数据[1]。
本网络爬虫设计是一个能够对网页实现自动提取的程序,在搜索引擎中,从万维网上它能为其下载网页,也是组成搜索引擎的重要部分。本软件由Python语言进行开发,并采用已有的比较成熟的requests模块、pandas模块对指定新浪微博评论的获取以及进行简单的分析,将我们所需要的数据下载到本地,并将我们获得的数据以TXT和Excel的形式更加清晰的呈现出来。
网络爬虫(web crawler)又称为网络蜘蛛(web spider)或网络机器人(web robot),另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或蠕虫,同时它也是“物联网”概念的核心之一。网络爬虫本质上是一段计算机程序或脚本,其按照一定的逻辑和算法规则自动地抓取和下载我们所需要的万维网的网页,是搜索引擎的一个重要组成部分。网络爬虫类似于一个搜索引擎来模仿人浏览网页是的状态,并将我们需要获取到的内容下载并保存下来。网络爬虫一般是根据预先设定的一个或若干个初始网页的URL开始,然后按照一定的规则爬取网页,获取初始网页上的URL列表,之后每当抓取一个网页时,爬虫会提取该网页新的URL并放入到未爬取的队列中去,然后循环的从未爬取的队列中,取出一个URL再次进行新一轮的爬取,不断的重复上述过程,直到队列中的URL抓取完毕,或者达到其他的既定条件,爬虫才会结束。
2 网络爬虫模型的分析与设计
2.1 模型分析
首先建立URL任务列表,即开始要爬取的URL。由URL任务列表开始,根据预先设定的深度爬取网页,抓取网页的过程中,不断从当前的页面上抽取新的url放入队列中,直到满足一定的停止条件。同时判断URL是否重复,按照设定爬取的微博内容搜索页面,然后对页面进行分析,并提取我们所需要数据的相关URL,最后将所得URL返回任务列表[1]。之后将任务列表中URL重新开始爬取,从而使网络爬虫进行循环运行。
2.2 概要设计
确认了需要爬取的网站之后,下一步就是使用requests模块对获取到的url对应的网页内容进行抓取。首先需要遍历整个网页的Html代码,寻找我们需要下载的信息,包括评论者名称,评论人的微博主页链接,评论的内容,评论的时间,点赞数回复数以及我们爬取的微博链接,将其中的评论者的名称,评论的内容还有爬取的微博链接生成一个TXT的文件,并将这个文件使用pandas中的DataFrame方法进行一个分析,将其他所有爬取到的内容提取出来使用openpyxl方法将所爬取到的所有内容导出到Excel并保存在Excel里面[2]。
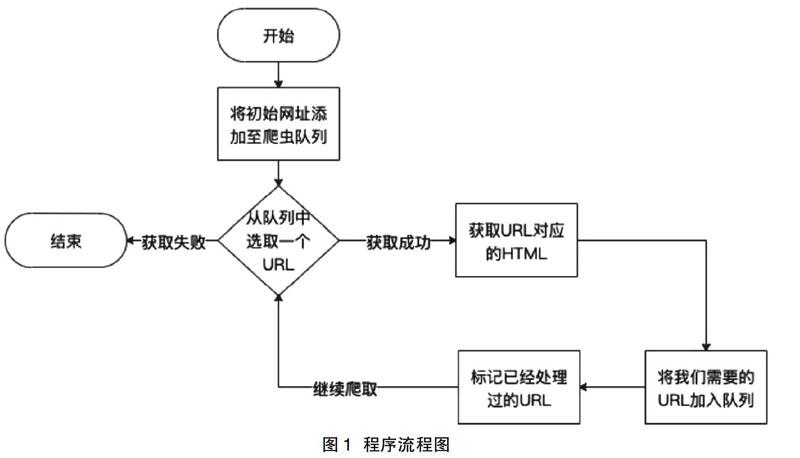
2.3 程序流程设计
程序流程图主要用来将程序在计算机上运行的具体步骤用图形来表示,程序流程图如图1所示。
3 详细设计与实现
3.1 目标网站URL
因为网页端新浪微博的反爬虫措施特别严厉,所以我们采取爬取相对难度较小反爬虫措施不那么严厉的手机端新浪微博,目标网站的url地址为:“https://m.weibo.cn/”。
为了更加有效的找到关键字对应的信息,本项目中所有的URL不仅仅是目标网站的URL。由于遍历整个网站需要消耗更多的资源,也并不能很好的体现Python的优势,更是添加了开发的难度,选择使用目标网站论坛自身的搜索板块的URL,作为程序读取的内容。这样既可以降低工作量,也可以更加方便的抓取相关的信息。后续需要爬取其他微博下面的评论我们只需要将“https://m.weibo.cn/detail/***********”中的*****部分更换为我们需要爬取的相应的微博ID即可[3]。目标网站的URL地址如图2所示。
3.2 爬取模块
Requests是用python语言基于urllib编写的,采用了Apache2Licensed开源协议的一个HTTP库,与urllib相比起来requests使用起来更加的方便和简洁,也可以为我们节约大量的时间。这里使用到了requests的get方法和post方法,其中get方法用來向我们需要访问的微博URL传递访问的请求,post方法用来向HTML网页发送一个post请求。导入requests模块如图3所示。
3.3 伪装time模块
在实际使用中,因为不少的网站都具有反爬虫的措施,为了能够不被识别,将我们判定为爬虫程序并将我们的IP封禁,我们需要将每次访问伪装成浏览器进行操作,并设置时间限制来访问我们需要爬取数据的网站,防止被判定为程序抓取并屏蔽IP,这里就需要用到time模块,使用time.sleep()方法来传递一个我们想要延迟几秒来响应的参数。爬虫中Time模块的主要功能就是我们按照自己的意愿来设置爬虫程序访问我们需要访问网站的时间间隔。另外本文中的time模块也用来提取评论者评论该微博的详细时间[3]。导入time模块如图4所示。
3.4 數据处理模块
Pandas模块是python中用于数据导入以及整理数据的模块,对数据挖掘前期数据的处理十分有用。在Python中,pandas是基于numpy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而numpy更适合处理统一的数值数组数据,由于本文是爬取的手机端新浪微博评论,所以这里没有使用到numpy而使用了pandas这种处理多种类型的数据的方法。pandas主要有series(一维数组),dataframe(二维数组),panel(三维数组),panel4D(四维数组),panelND(更多维数组)等数据结构,其中Series和DataFrame的应用最为广泛。Series 是一维带标签的数组,它可以包含任何数据类型。包括整数,字符串,浮点数,Python 对象等。Series 可以通过标签来定位。DataFrame是二维的带标签的数据结构,我们可以通过标签来定位数据。本文也主要是使用了pandas中的DataFrame方法来使我们生成的TXT文件进行一个二维数组的处理,使我们能更清晰的看见我们爬取的数据。导入pandas模块如图5所示。
本文主要的研究内容是基于Python的数据爬虫的设计与实现,在爬虫开发前期,分析了几个类似的爬虫程序,在开发过程中,也运用互联网查找相关技术方法解决一些问题,基本完成了爬虫的主要功能。
参考文献
[1] 川郭涛,黄铭钧.社区网络爬虫的设计与实现[J].智能计算机与应用,2012,2(4):65-67.
[2] 廉捷,周欣,曹伟,等.新浪微博数据挖掘方案[J].清华大学学报:自然科学版,2011,51(10):1300- 1305.
[3] 刘艳平,俞海英,戎沁.Python模拟登录网站并抓取网页的方法[J].微型计算机应用,2015,31(1):58-60.
收稿日期:2020-09-12
作者简介:杨国军(1974—),男,四川内江人,硕士,副教授,研究方向:软件工程,工作流技术。
Design?and?Implementation?of?Data?Crawler?Based?on?Python
YANG Guo-jun
(Neijiang?Normal?University, Neijiang Sichuan 641112)
Abstract: This paper puts forward the idea of web crawler and imitates human process to help people find more valuable data information, save time and improve work efficiency. The concept, working principle, In view of the tedious problem of searching and searching massive data information on the Internet, system analysis, design and implementation of web crawler are analyzed and discussed in detail, and an effective implementation scheme is proposed.
Keywords: python; spider system ; design; realize
猜你喜欢
艺术启蒙(2018年7期)2018-08-23
海峡姐妹(2017年7期)2017-07-31
Coco薇(2017年5期)2017-06-05
办公室业务(2016年9期)2016-11-23
中国新通信(2016年16期)2016-10-18
舒适广告(2008年9期)2008-09-22
