
医学观察性研究设计讲座(连载四)
2020-12-21 03:37徐应军
现代养生·下半月 2020年10期
徐应军


3.5.4 深入分析
是否有关联、关联的强度、关联的范围是病例对照研究必须要分析的3个基本内容,有时为了进一步解释因素的作用,还需要进行一些深入分析。
3.5.4.1 分层分析(stratification analysis)
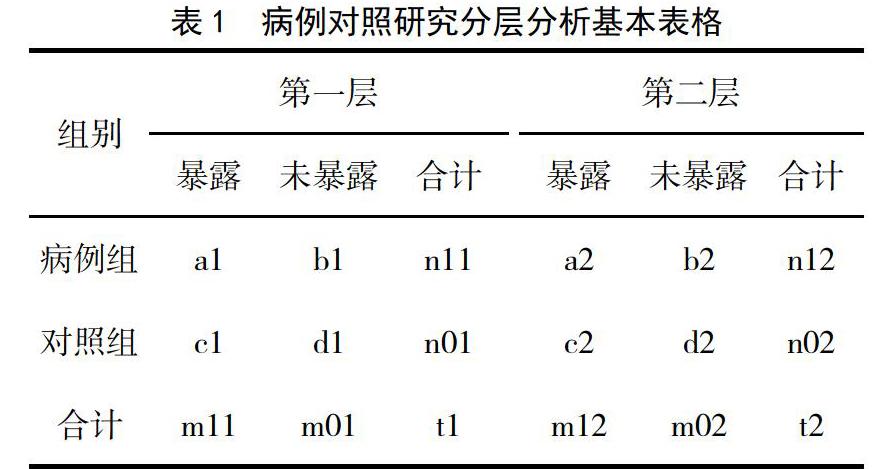
是将均衡性检验中分布不均的那些因素,即缺乏可比性的因素选来,按照因素的有无或等级分成若干层,再对各层人群进行暴露与疾病联系的分析,这种方法称为分层分析,如对性别分层后,分别在男性间,或女性间分析暴露与疾病的关系,此时各比较组间性别构成完全相同,可以排除由于性别构成不同对研究结果的混杂作用。所以分层分析是对资料缺乏可比性的一种处理手段,是单因素水平控制混杂偏倚的有效方法。分层分析的步骤如下:
(1)分析表格:根据分层因素的有无可以将资料分成两层,其分析表格的形式见表1,如果按照分层因素的等级可以继续分为第三层,……,第n层等,表格的形式是一样的。
(2)计算各层的OR值:第一层OR1=( a1 d1)/( b1 c1);第二层OR2=( a2 d2)/( b2 c2),依次类推。如果各层的OR值比较接近,如OR1≈OR2,表明两层资料是同质的,可以计算分层后总的效应。
(3)计算总的指标:分层分析不是为了分别计算各层的效应,而是希望得到控制了分层因素影响后总的指标,即总的χ2检验、OR值及其95%可信区间。总的指标计算采用Mantel-Haensel方法,分别以χ2MH、ORMH、ORMH 95%可信区间表示,计算公式分别为:
(4)分层分析的意义:分层分析的目的是控制混杂因素,分层后使各因素处于同一水平进行比较,从而克服了混杂因素在病例组与对照组分布不均造成的偏倚。通常将分层前的OR值称为粗的OR,分层后计算的ORMH是调整了分层因素的混杂影响后的OR值,也称为调整的OR值。
如果OR=ORMH则表明分层因素不起混杂作用。如果OR>ORMH,或OR (5)示例:上期表2分析的是没有考虑其他任何因素干扰时的收缩压与心肌梗死的关系。实际上,有很多因素同时与心肌梗死及收缩压有关系,如性别,因此在下结论前必须排除性别的混杂影响。根据性别分层的资料见表2。 1)分别计算各层的OR值 男性OR=(107×124)/(92×101)=1.43 女性OR=(38×125)/(43×77)=1.43 分层后各层的OR值相同,说明两层资料具有同质性。 2)计算 =5.17 自由度为1, >3.84,具有统计学意义,说明分层后收缩压与心肌梗死仍有关联。 3)計算ORMH ORMH= 与分层前的OR比较,ORMH有所降低,可以认为这是性别混杂作用的结果,性别夸大了关联的强度,相对而言,ORMH更能真实反映暴露与疾病的关联程度。 4)计算ORMH 95%可信区间 ORMH=95%CI= 此区间不包含1,收缩压与心急梗死有关联。 3.5.4.2 剂量反应关系分析 在病例对照研究中,对于定量的,或分等级的因素可以分析暴露的剂量或等级与OR值的关系,即剂量反应关系(dose-effect relationship)。暴露因素与疾病之间存在剂量反应关系是判断二者因果关系的重要证据之一。因此在调查中要尽量收集暴露因素的暴露剂量或暴露的程度等资料。 (1)分析表格:等级资料可以直接根据暴露的级别由低到高列表,如表3所示。如果是定量资料,需要先划分若干个数量组,再由低到高列表,如每日吸烟量与肺癌的关系,吸烟量可分为每日“0”,“1~”,“6~”,“11~”支4个组。 (2) 检验:利用R×C(行×列)表检验公式进行检验,判断病例组与对照组暴露程度构成有无统计学意义。 (3)计算各暴露程度的OR值:以不暴露或最低暴露为参比,令其OR0=1,其他各暴露水平的OR值分别为:OR1=( a1c)/( b1d);OR2=( a2c)/( b2d),依次类推。 (4)线性趋势χ2检验:暴露等级与各OR之间的剂量反应关系需要通过线性趋势χ2检验后进行判断,公式为: (公式4) (公式5) 式中xi为暴露的水平,可直接取值0,1,2……。检验的自由度为1,如果χ2≥3.84,则说明暴露程度与OR值存在线性趋势,即剂量反应关系。 (5)示例:体重指数(BMI)与脑卒中复发关系的病例对照研究结果见表4。 以BMI<24.0为参比,计算各水平的OR值。结果显示,脑卒中的危险性随体重指数增加而升高,但是否存在剂量反应关系,需要进行线性趋势检验,检验过程如下: T1=60×1+15×2=90 T2=308×1+64×2=436 T3=308×12+64×22=564 自由度为1,χ2=1.81<3.84,P>0.05,无统计学意义,表明根据该研究结果还不能认为体重指数与脑卒中复发之间存在剂量反应关系。 3.5.5 匹配设计资料分析 频率匹配设计的资料分析与成组设计相同,个体匹配时,对照的数目越多,分析方法越复杂,下面仅介绍1:1匹配的资料分析。 3.5.5.1 分析表格 1:1匹配设计的分析表格基本形式见表5。成组设计的四格表中,a、b、c、d分别代表人数,而1:1匹配设计表格中的a、b、c、d分别代表病例与对照的对字数,即a为病例与对照均为暴露的有a对,均不暴露的有d对,实际上a和d在分析中是没有贡献的,只有b和c对分析有意义。 3.5.5.2 分析内容 (1)有无联系:仍然以 检验判断暴露与疾病有无关联,检验采用McNemar公式: χ2=(b-c)2/(b+c) (公式6) 如果(b+c)<40时,采用校正的公式: χ2=(|b-c|-1)2/(b+c) (公式7) 自由度为1,如果 ≥3.84,具有统计学意义,暴露与疾病有关联。 (2)关联强度:OR的计算公式为: OR=c/b (公式8) (3)关联范围:仍应用Miettinen公式计算OR95%可信区间。 OR95%CI= (公式9) 3.5.5.3 示例 在一項关于服用雌激素与子宫内膜癌关系的研究中,共计发现病例63人,采用1:1配对设计,组成63个对子,资料见表6。 (1) χ2检验:采用McNemar校正公式计算: χ2=(29-3-1)2/(29+3)=19.53 自由度为1,P<0.001,具有统计学意义,可以认为服用雌激素与子宫内膜癌有关联。 (2)计算OR值: OR=29/3=9.67 说明服用雌激素者发生子宫内膜癌的危险性是未服用者的9.67倍,关联非常密切。 (3)计算OR95%可信区间: OR95%CI= 区间不包含1,服用雌激素与子宫内膜癌存在关联。 3.6 注意事项 3.6.1 代表性 病例对照研究要求病例代表目标人群所有该病的患者,对照代表全部非该病人群,这是一种理想的状态。在实际研究中,病例可以是任何一类我们感兴趣的病例,例如家庭微小环境与女性肺癌的关系,病例只是女性;青年脑梗死危险因素研究,病例只是青年人。此时的病例并不代表全部患病人群,而只代表这一类病例。由于病例被局限在某一个范围,选择能够代表这一类的病例,以及确定病例的源人群相对容易做到。对照的代表性不一定是未患该病的全人群,应该是病例的源人群。以医院为基础的病例对照研究,几乎无法保证样本代表性,能够做的是尽量扩大研究的样本量,提高病例组与对照组的均衡性。 3.6.2 可比性 应该承认病例对照研究的设计是存在缺陷的,即病例与对照并非同一个人群的两个部分,而是分别单独选来的,这样就很难做到两组的同质性,因此外部因素对研究结果的干扰与混杂影响的程度要大于其他类型研究。基于这种原因,病例对照研究的结果解释和评价,必须不十分谨慎,有时需要借助一些资料分析技术,如分层分析、多因素分析等,对一些重要特征进行处理,保证病例与对照在同质的基础上进行比较,使研究结果得到合理解释和评价。 3.6.3 对照选择 在病例对照研究中普遍在的一个问题是对病例选择比较重视,忽视对照的选择。这是因为研究者往往认为研究的目标变量是疾病,而且是单一病种,数量有限。因此把精力几乎全部投入到病例的选择上。实际上,对照的选择有时更加困难和重要,许多研究是由于合适的对照不好选而影响了研究的进度和质量。因此,在设计和实施过程中,病例和对照应同等对待,最好是同时进行、同时完成。 3.6.4 偏倚控制 由于病例对照研究的设计特点,决定了这种方法更加容易出现偏倚,因此控制偏倚是病例对照研究的关键技术。 3.6.4.1 选择偏倚的控制 病例对照研究选择研究对象时很难做到随机抽样,另外由于条件等的限制,多数是在医院患者中选择研究对象,因此极易产生选择偏倚。常见选择偏倚有入院率偏倚、现患病例偏倚、无应答偏倚等。控制选择偏倚的主要措施有: (1)尽量采取以人群为基础的研究。如果只能选择医院病例时,可以考虑在多家医院选,疾病的就诊率越高,包含的医院越多,样本的代表性就越高。 (2)尽量选择新发病例研究对象。特别是对于那些病程较长的慢性疾病,存活的现患病例可能是一个有偏性的特殊群体,以他们为对象研究进行研究,缺乏代表性。另外新发病例距离暴露时间相对较短,获取的暴露信息也相对准确和丰富,可以排除患病后发生的个人行为改变及环境变化的影响。 (3)尽量选择多病种或多种对照。在以医院为基础的病例对照研究中,对照应该由多病种的病人组成,可以淡化单病种人群的某些特性对研究结果的影响,提高代表性。如果采用多种对照的设计,可以通过比较不同对照的研究结果,判断选择偏倚的有无及大小。 3.6.4.2 信息偏倚 病例对照研究最主要的信息偏倚是回忆偏倚,可以产生于调查员和调查对象的心理作用及对往事记忆的准确性。控制信息偏倚的主要措施有: (1)盲法(blind)调查:是控制由于调查员和调查对象心理因素对调查结果影响的有效方法,分为单盲设计、双盲设计和多盲设计。单盲(single blindness)设计是只有调查员或调查对象不清楚设计方案,例如聘请与课题无关的,经过培训的调查员进行调查;双盲(double blindness)设计是调查员与调查对象均不清楚设计方案,但病例对照研究不易做到双盲,因为所研究的疾病往往要比对照重,而病例又是在确诊后选定的,所以病例的心理作用难以控制;多盲设计是不仅调查员、调查对象对课题设计处于盲的状态,而且资料的分析人员等也不清楚,例如聘请非项目组成员担任调查员和资料处理员,在患者入院确诊前调查等。 (2)充分利用历史记录:个人的病历、职业、保险等档案资料是获取既往信息的重要来源,既可以弥补个人回忆的不足,又可通过对相同内容的对比,分析个人回忆的资料的真实性,例如将个人回忆的职业史(开始工作年龄、工种变迁时间等信息)与档案记录比较,如果准确无误,可以认定调查资料的回忆偏倚较小,资料可信;但是,如果差别较大,该份问卷的资料误差不可忽视,最好重新调查核实。 3.6.4.3 混杂偏倚 病例对照研究中的外部因素难以控制是产生混杂偏倚的主要原因。混杂偏倚可通过匹配设计、率的标准化、分层分析及多因素分析等方法加以控制。 3.7 病例对照研究实例 1950年前后,英国的两位内科医生Doll和Hill针对吸烟与肺癌的关系进行了病例对照研究,成功地揭示了吸烟的危害作用,成为肺癌病因学研究史上经典的范例。 3.7.1 设计要点 3.7.1.1 病例选择 以伦敦市20所医院1948~1952年期间确诊的肺癌患者为病例组。由于肺癌是一种危害极其严重的疾病,住院率几乎为100%,同时研究所包含的醫院基本涵盖了伦敦所有能够接诊肺癌的医院,因此该研究所选病例可以认为接近伦敦市人群全部病例,具有一定代表性。 3.7.1.2 对照选择 每确定1例病例,在同一医院选择年龄、性别、居住地等因素相匹配的胃癌等消化道癌症为对照。 3.7.1.3 调查表设计 调查表的重点是关于吸烟,包括是否吸烟、吸烟开始年龄、平均每日吸烟量、吸烟类型、是否戒烟、戒烟年数等,同时也包含了大量人口学等资料。 3.7.1.4 调查 由经过统一培训的调查员,使用同一调查表,采用相同的方式方法,对病例与对照进行调查收集资料。 3.7.2 资料分析 3.7.2.1 均衡性检验 对病例组与对照组的年龄、性别、社会经济地位、居住地等因素的构成进行对比分析,结果均无统计学意义,表明组间特征具有均衡可比性。 3.7.2.2 吸烟与肺癌的关系 分析结果显示,肺癌患者中吸烟的比例为97%,高于对照组的92%,差异具有统计学意义( χ2=19.13,P<0.001),表明吸烟与肺癌有联系;联系的强度OR=2.97,即吸烟者肺癌的危险性是不吸烟者的2.97倍,区间估计下限值为1.79,上限为4.95,结果见表7。 3.7.2.3 分层分析 性别是一个既与吸烟有关联,又与肺癌有关联的因素,为了进一步认识吸烟与肺癌的关系,需要对性别进行分层分析。结果显示,分层后男性OR=14.0,女性OR=2.5,层间OR值相差较大,不适宜计算Mantel-Haensel总的和,因为病例组与对照组性别构成是均衡的,性别的混杂影响已经排除,所以这里可以分别计算各层 ,结果显示两层均有统计学意义(男性χ2=22.04,P<0.0001;女性χ2=5.76,P<0.05),表明无论男性女性,吸烟均与肺癌有关联,吸烟增加了肺癌的危险性,但对男性的危险性大于女性,见表8。 3.7.2.4 剂量反应关系分析 以平均每日吸烟的支数作为暴露的剂量单位分组,分析吸烟与肺癌之间的剂量反应关系。结果显示,男性平均每日吸烟的支数,病例组与对照组构成差别有统计学意义(χ2=43.15,P<0.001),病例组吸烟量大的比例大于对照组,而且OR值随着暴露剂量的增加而升高,线性趋势检验有统计学意义(线性趋势 χ2=40.01,P<0.001),表明男性每日吸烟量与肺癌危险性间存在剂量反应关系,见表9。 3.7.3 结论 经过病例对照研究发现吸烟与肺癌有关联,吸烟者肺癌的危险性是非吸烟者的2.97倍;吸烟对男性和女性均可增加肺癌的危险性,但对男性的危险性高于女性;肺癌危险性随每日吸烟支数增加而升高,存在剂量反应关系。因此,吸烟是肺癌的危险因素,控制吸烟有利于肺癌的预防。 4 队列研究 队列研究(cohort study)与病例对照研究同是分析性研究方法。队列原是古罗马军团中的一个方队,作战时方队成员同步冲锋陷阵。队列研究中的队列通常是指在某个问题上具有相同起点一个人群,例如同年出生,或同时暴露,或同时观察的一群人。由于队列研究的设计是先看到人群的暴露情况,并以此为起点追踪到果,就像队列一样,研究人群同步走向将来某一时刻,等待结局的发生。因此,从因果时序关系上是先“因”后“果”的研究方法,因而有时也称为前瞻性研究(prospective study)、随访研究(follow-up study)、纵向研究等(longitudinal study)。队列研究所获得的因果关系证据的力度大于病例对照研究,是更深层次的研究方法。 4.1 原理与特性 4.1.1 基本原理 队列研究是先选定一个研究人群,即建立队列,再根据某因素的暴露情况,将研究对象分成若干个组,如暴露组和非暴露组,或不同暴露水平组等,剔除各组内已经有结局事件(如发病或死亡等)或不可能再发生结局事件的个体,随访观察一段时间,统计各组研究事件结局的发生情况,如发病人数、死亡人数等,计算和比较各组结局事件的发生率,如果暴露组的发生率与非暴露组的发生率存在统计学差异,则可推断暴露与事件可能存在因果关系,当暴露组的率高于非暴露组,该因素是为危险因素,当暴露组的率低于非暴露组,该因素为保户性因素。 在建立队列时,必须保证队列成员没有结局事件发生,且将来有发生结局事件的可能,否则不符合进入队列要求。队列可分为固定队列和动态队列两种。固定队列(fixed cohort)是指队列成员均在短时间内进入队列,随访观察开始后到终止观察期间,没有成员退出队列和新成员加入队列。动态队列(dynamic cohort)是观察期内新成员可随时加入队列,但加入队列后,同时随访观察结局。 4.1.2 基本特性 4.1.2.1 观察法研究 与现况研究、病例对照研究相同,队列研究的暴露因素也是研究前已经存的,或过去某一时期暴露过的。 4.1.2.2 先“因”后“果” 队列研究的设计特点是先确定暴露状态,再随访观察结局的发生,是前瞻性的,是由“因”到“果”的设计,这种设计模式与实验性研究相似,区别是实验性研究的暴露是人为决定的。 4.1.2.3 设立对照组 队列研究必须设立不同暴露状态的对照组,以便对比分析暴露对结局事件的作用。为了合理比较,暴露组与对照组必须有可比性,理论上对照组与暴露组除了暴露状态不同,其他方面都应该保持一致。暴露组与对照组来自同一个人群,这种对照为内对照,可比性较好。对照来自其他人群,这种对照为外对照,需要关注对照的可比性。 4.2 队列研究类型 4.2.1 前瞻性队列研究 前瞻性队列研究(prospective cohort study)是从研究对象目前的暴露状态开始,随访到将来某一时刻,结局事件需要等待一段时间才能观察到,这种设计模式称为前瞻性队列研究,是队列研究的基本模式。前瞻性设计暴露和结局资料是直接通过调查得到的,相对比较可信,偏倚较小。但对于发病率较低、需要长时间随访的疾病,前瞻性设计需要的样本量大、观察期长、投入多,执行难度大,可行性较差。 4.2.2 历史性队列研究 历史性队列研究(historical cohort study)是以过去某个时点的人群为基础建立队列,并根据当时资料记载的每个对象的暴露情况进行分组,在剔除该人群已经发生过研究事件的个体后,开始模拟随访到现在,比较各人群事件的发生率,这种设计模式为历史性队列研究。历史性队列研究是利用已经发生过的资料,不需要等待事件的发生,因此可以在短时间内完成。虽然是回忆过去,但是根据历史记载仍可判断先“因”后“果”的时序关系。因此,较前瞻性设计而言,是一种快速、节省的队列研究方法。历史性队列研究必须依据详实的历史资料,而且目前已经有结局发生,常见于职业人群的研究,因为每个人的职业档案可以提供确切的职业暴露史和健康体检资料,是建立历史性队列和随访的重要凭证。 4.2.3 双向性队列研究 雙向性队列研究(ambispective cohort study)是将历史性队列研究与前瞻性队列研究结合应用的设计模式,即在历史性队列的基础上,从现在起继续前瞻性随访一段时间,通常是因为历史性队列随访的时间不够,结局事件尚未出现,需要补充随访至结局事件出现。双向队列研究可以充分利用历史资料提供有价值的信息,最大限度地节省研究的时间和投入。 4.3 研究目的及优缺点 4.3.1 研究目的 4.3.1.1 检验病因假设 因为队列研究能够提供先“因”后“果”的时序关系证据,所以检验病因假设的能力要远远大于病例对照研究。一般经过队列研究检验假设成立,是因果关系的可能性就更大了。但队列研究执行起来难度大,需要大量的人力、物力和时间的投入,因此多是在病例对照研究获得比较确切假设的基础上,采取的更为深入的研究方法。 4.3.1.2 探究疾病自然史 通过人群长期的随访观察,可以掌握疾病在个体和人群中发生、发展、消亡的自然过程,例如早期血压、血脂水平及变化规律,以及遗传学的某些特征与今后心脑血管事件的关系等。研究疾病自然史有助于制定疾病防治策略和措施。 4.3.1.3 评价防治效果 人群中那些自觉或不自觉采纳的,或者是传统经验的防治疾病的措施及方法,到底效果如何,可以通过队列研究进行评价,例如观察戒烟人群是否会降低肺癌的危险性,健康饮食对心血管疾病的影响等。队列研究评价的措施是研究前人群已经存在,或自发的行为,而非研究开始后人为干预,这是与实验性研究最大的区别之一。 4.3.2 优缺点 队列研究的优缺点,多数是与现况研究和病例对照研究比较而言。 4.3.2.1 优点 (1)回忆偏倚较小:因为暴露是在事件发生前调查到的,属于双盲调查,因此资料受调查员和调查对象心理影响较小,而且所调查的暴露是调查对象当时的情况,资料相对准确可靠。 (2)可以直接计算相对危险度:队列研究是观察队列人群疾病的发生情况,可以计算出各暴露人群的发病率或死亡率,因而可以直接计算各危险因素的相对危险度(RR)。 (3)可以证实先“因”后“果”的时序关系:在队列研究中所有的暴露因素均是在发病前确定的,通过随访一个潜伏期(incubation period),或潜隐期(latency period),观察疾病的发生情况,可以确定“因”在前,“果”在后的时序关系。 (4)可以同时研究多种疾病:队列人群在随访过程中,可以发生各种疾病,因此所观察到的每一种疾病均可以分析与暴露因素的关系。 4.3.2.2 缺点 (1)实施难度大:队列研究需要对一个较大规模的人群进行随访,如果所研究的疾病的潜伏期(潜隐期)较长,不仅需要花费较多的时间,而且失访难以控制,没有大量的人力、物力和技术保障,几乎是不可能完成的。因此队列研究往往是在反复的病例对照研究的基础上,有充分的把握前提下设计实施的。 (2)资料处理复杂:队列研究的资料包含了时间的因素,在随访过程中,每个人的年龄在变化,由于失访和结局事件的发生,每个人在队列中贡献的观察时间不同,这些因素在资料处理中均需要考虑,造成队列研究资料处理复杂,尤其是人年计算。 (3)不适合发病率较低疾病研究:每种研究方法都需要一定数量的具有阳性事件的个体,如果所研究的疾病发病率较低,只有扩大队列规模,才能满足研究的要求。当队列过于庞大,失访及随访质量难以控制,偏倚和误差将会增大,导致研究失败,因此发病率低的疾病,尤其是非常罕见的疾病只能采用病例对照研究设计。 4.4 研究设计与实施步骤 4.4.1 设计思路及技术要点 4.4.1.1 技术路线 队列研究过程的主要环节及流程图1。 4.4.1.2 技术要点 (1)队列建立:队列是开始进行追踪观察研究的人群,必须含有暴露组和对照组,或不同暴露剂量组。进入队列的成员必须保证无结局事件和今后有发生结局的可能,各组之间除了研究的暴露因素外,其他因素尽量保持均衡可比。 (2)随访(follow-up):从研究对象进入队列开始至研究终止,这一期间内跟踪观察的过程为随访,是队列研究的重要特征和关键环节。随访期的长短取决于所研究的疾病的潜伏期或潜隐期,潜伏期越长,随访的难度越大。随访期间两项关键任务是发现结局事件和控制失访。 (3)失访偏倚(follow-up bias):队列成员随访期间失去联系,研究终止时无法判断结局为失访(loss to follow-up),是队列研究偏倚的重要来源。当研究的队列规模越大,随访期越长,失访越多。控制失访是保证研究质量,降低偏倚的重要技术。 (4)人时(person time)计算:如果队列成员进入和退出队列的时间相差较大,在资料处理时需要引入一个新的概念“人时”,即人和时间的乘积,例如1个人观察10年为10人年(person year),10个人观察1年也为10人年,以人时为单位计算发病率是队列研究一项重要技术和繁琐的任务。 `(未完待续)
猜你喜欢
中国药学药品知识仓库(2022年1期)2022-03-23
考试与评价·八年级版(2020年4期)2020-10-26
考试与评价·八年级版(2020年1期)2020-10-26
考试与评价·八年级版(2020年1期)2020-10-26
科学导报·学术(2020年26期)2020-10-21
养生阅刊(2020年7期)2020-08-16
饮食与健康·下旬刊(2019年10期)2019-03-09
电子技术与软件工程(2018年23期)2018-02-28
中老年健康(2016年12期)2017-01-18
青年文学家(2016年32期)2016-12-23
