
一种基于超体积指标的多目标进化算法
2020-12-23 06:33王学武魏建斌顾幸生
华东理工大学学报(自然科学版) 2020年6期
王学武, 魏建斌, 周 昕, 顾幸生
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
多目标优化问题通常是指具有多个目标同时具有多个最优解的一类问题,解决这类问题需要同时对相互作用、相互冲突的多个目标进行优化和综合考虑,因此多目标优化已经被广泛应用于电力调度[1]、网络优化[2]、化工过程[3]、结构设计[4]、数据挖掘[5]等领域。
以焊接机器人路径规划问题为例,衡量焊接路径好坏的指标往往不止一个,通常有路径长度、焊接用时、能量消耗、焊接变形量等,因此可将焊接机器人路径规划问题看作一个多目标优化问题。进化算法是一类模拟生物自然选择与自然进化的随机搜索算法[6],通过种群迭代来协调局部与全局搜索能力,从而获得收敛性和分布性均较好的解集,能够有效地解决多目标优化问题。王学武等[7]通过将基于分解的多目标进化算法与自适应邻域相结合,以焊接路径长度和能量消耗为优化目标,较好地解决了弧焊机器人路径规划问题。Mac 等[8]基于Pareto 支配关系提出了改进的多目标粒子群优化算法,以焊接路径长度和路径平滑度为优化目标求解移动机器人路径规划问题,在不同种类的环境中均得到了较好的仿真结果。
多目标优化算法是解决多目标优化问题的核心,关键在于如何设计算法以获得较好的综合性能,而超体积(Hypervolume,HV)指标是唯一一个在Pareto 支配关系上严格单调的度量指标[9],超体积值越大,对应算法的综合性能越好,因此超体积可以作为归档策略、多样性机制或选择标准来指导算法搜索[10],从而考虑将评价算法性能的超体积指标整合到算法中来解决多目标优化问题[11]。Bader 等[9]提出的HypE 算法通过蒙特卡洛模拟来近似精确的超体积,能够大大降低算法的时间复杂度、平衡估计的准确性和算法的计算复杂度。Igel 等[12]提出的MO-CMAES 算法将具有协方差矩阵自适应的精英进化策略与基于非支配排序的多目标选择相结合,实验结果表明基于超体积贡献的s-MO-CMA 比基于拥挤距离的c-MO-CMA 具有更好的性能。Beume 等[13]提出的SMS-EMOA 算法采用在每次迭代中只产生和淘汰一个个体的稳态进化策略,在二维和三维的测试问题上表现出较好的综合性能。
上述基于超体积指标的算法具有计算复杂度高、程序运行效率低的缺点,因此选择有效计算超体积的方法来提升算法的运行效率并且获得较好的综合性能对基于超体积指标的进化算法来说具有重要意义。
1 相关工作

通过超体积指标来指导算法搜索,其HV 性能指标普遍较高,但仍然存在运行效率低、分布性不好的缺点,而基于参考点的NSGA-Ⅲ搜索的解分布均匀,因此本文提出了一种基于超体积指标的多目标进化算法(MOEA-HV),针对二维和三维的多目标优化问题,采用分治递归思想的切片法来精确计算超体积,同时在基于指标的进化算法(IBEA)[11]前对所有种群个体进行非支配排序提前删除被支配的个体,从而减少个体独立贡献超体积的计算量,提升运行效率,通过与NSGA-Ⅲ结合来优化算法的分布性。
2 MOEA-HV 算法
2.1 IBEA
IBEA 主要包括两个部分:一是将超体积指标与适应度评价函数进行结合,计算种群中每个个体的适应度值,公式如下:

其中: I ({x2},{x1}) 表示计算个体的独立贡献超体积;k是一个大于0 的比例缩放因子[31],用于淘汰适应度值小的个体,即在原种群中删除对总的超体积的独立贡献最小的个体,如图1 和图2 所示(以二维为例)。

图 1 在非支配关系下 BHV > AHV > 0Fig. 1 BHV > AHV > 0 in non-dominated relationship

图 2 在支配关系下BHV > AHV = 0Fig. 2 BHV > AHV = 0 in dominated relationship
在图 1、2 中,A 和 B 均表示一个个体,H 表示计算超体积的参考点,阴影部分AHV和BHV表示个体A 和B 的独立支配区域面积,其中图1 表示个体A 和B 在互不支配时的独立支配区域面积,图2 表示个体B 支配个体A 时的独立支配区域面积,均有BHV>AHV,因此不论是根据个体的支配关系还是个体对总的超体积的独立贡献,更应该淘汰个体A。事实上,超体积指标在Pareto 支配关系上是严格单调的,因此能够作为指导种群进化的有效度量指标[9]。
重新计算种群中每个个体的适应度值,其更新公式为

通过二元锦标选择父代进行交配从而产生新的个体,与原种群一起构成新的种群,继续进行迭代。
IBEA 通过将超体积指标和适应度评价方法相结合来指导种群进化,与基于超体积指标的其他典型算法 HypE[9]、MO-CMA-ES[12]和 SMS-EMOA[13]相比,在保证综合性能最优或次优的前提下,其运行效率是最高的,这也是本文选择IBEA 作为算法基础框架的主要原因。
2.2 NSGA-Ⅲ
NSGA-II[32]是基于拥挤度距离建立偏序集来筛选个体指导种群进化,能够有效处理多目标优化问题。NSGA-Ⅲ[33]在NSGA-II 的基础上通过使用一组预定义的参考点在临界层选择个体来确保种群良好的分布性,该算法在最坏情况下的时间复杂度为O(N2lgM-2N)或 O(N2M)。
基于参考点方法的NSGA-Ⅲ能够维持种群个体分布的多样性和均匀性,因此将NSGA-Ⅲ整合到IBEA 框架中,获得的解能够同时具有良好的收敛性和分布性,使得程序的运行效率更高,同时解也能够均匀分布在整个Pareto 前沿面。有两种方法可以将NSGA-Ⅲ和IBEA 结合:一是在IBEA 运行完成的基础上再运行NSGA-Ⅲ,也就是IBEA 先迭代更新完成,获得收敛性较好的种群,然后将获得的种群作为NSGA-Ⅲ的初始种群继续进行迭代优化,以期获得分布性也较好的解;二是先运行NSGA-Ⅲ,然后将获得的分布均匀的种群作为IBEA 的初始种群、利用超体积指标指导种群进化来继续对选择过程增压,以期获得综合性能均较好的解。
本文选择第1 种结合方式。因为在基于超体积指标的算法中,IBEA 的收敛速度较快,分布性较差,因此重点在于改善IBEA 的分布性,在IBEA 运行的基础上再运行NSGA-Ⅲ能够实现此目的。而对于第2 种方式,先利用NSGA-Ⅲ获得分布性较好的解,然后在此基础上通过IBEA 继续进行个体的迭代选择,很可能会破坏之前已经均匀分布的解,反而降低了算法的综合性能。
2.3 非支配排序
IBEA 通过计算种群中每个个体的独立贡献超体积及其适应度值淘汰适应度值最小的个体,并依次进行迭代,使得算法最终能获得一个较好的解集,但计算复杂度高,主要原因在于IBEA 计算了每个个体的独立贡献超体积。本文的改进之处是先通过Pareto 支配关系对个体进行筛选,得到一组非支配解集,然后计算非支配解集中每个个体的独立贡献超体积,淘汰贡献值最小的个体并依次迭代。通过提前删除质量不好的个体而避免计算其独立贡献超体积,能够有效节约个体的超体积计算量,而且减小了计算复杂度,提升运行效率。以二维为例,图3 示出了非支配排序后的解集分布情况,很容易计算出每个个体的独立贡献超体积(即面积)。图4 示出了经过初始化后产生的种群个体分布情况,处于乱序状态,此时要淘汰独立贡献超体积最小的个体仍然需要计算每个个体的贡献值,浪费了部分计算资源,因此本文考虑在IBEA 前引入非支配排序来提升算法的运行效率。

图 3 非支配排序后的解集Fig. 3 Solution set after non-dominated sort

图 4 乱序下的解集Fig. 4 Solution set in chaos
三维的非支配排序情况与二维类似,但个体独立贡献超体积的计算更加复杂。本文采用切片法来精确计算三维个体的独立贡献超体积,基本思想是计算整个解集的超体积与去除该个体后的超体积之差。具体来说,先利用某一维度(本文选择第一维度)对整个超体积进行切片以达到降维的目的,通过计算切割面的面积与切片在第一维度上的深度的乘积得到整个解集的超体积,然后用同样的方法计算去除该个体后的超体积,两个超体积之差即为三维情况下的个体独立贡献超体积(即体积)。假设解集中有 4 个个体 P1、P2、P3、P4,图 5(a)、(b)、(c)和(d)分别示出了整个解集的超体积、经过切片后的子超体积、个体P1和P2的独立贡献超体积。通过精确计算每个个体的独立贡献超体积,淘汰独立贡献超体积最小的个体来指导种群进化。
2.4 MOEA-HV 算法步骤
通过精确计算种群中个体的独立贡献超体积来指导种群进化,在IBEA 前对所有种群个体进行非支配排序并与NSGA-Ⅲ结合,共同组成了MOEAHV 算法。算法步骤如下:
输入:种群数量、组合迭代次数、参数k、参考点输出:Pareto 前沿面
(1)初始化。获得初始种群,并生成参考点。
(2)非支配排序。对种群进行非支配排序,提前删除被支配的个体,减少超体积的计算量。
(3)计算非支配排序后种群中每个个体的适应度值,并淘汰适应度值最小的个体。
(4)选择、交叉、变异,产生新的种群。利用二元锦标法选择最优的两个个体到交配池进行交叉变异,产生新的个体与原种群合并为新的种群。
(5)嵌入 NSGA-Ⅲ。将新得到的种群作为NSGA-Ⅲ的初始种群继续进行迭代,满足迭代要求则停止迭代并输出。
3 实验结果及分析
仿真实验使用Lenovo-PC 计算机,处理器为Intel(R) Core(TM) i5-4200M CPU @ 2.50 GHz,内存为4.00 GB,操作系统为基于x64 处理器的64 位操作系统Windows 8.1 中文版,软件版本为 MATLAB R2018a,程序运行均在PlatEMO[34]平台实现。
为检验MOEA-HV 的运行效率和综合性能,与其他典型的基于超体积的算法IBEA[11]、HypE[9]、MO-CMA-ES[12]、SMS-EMOA[13]以 及 NSGA-Ⅲ[33]进行对比实验,选择2 个目标的ZDT 和3 个目标的DTLZ 系列中具有代表性的典型测试函数ZDT1~ZDT6 和 DTLZ1~DTLZ7 进行实验,通过运行时间评价算法的运行效率,通过IGD[35]和HV[36]指标评价算法的综合性能,其中IGD 值越小说明算法的综合性能越好,HV 值越大说明算法的综合性能越好,这两个评价指标都能够综合评价算法的收敛性和分布性。设置种群大小为100,迭代次数为500,所有算法在相同条件下独立运行10 次,k=0.03。表1~3 分别列出了各算法的运行时间、IGD 均值(IGDm)和HV 均值(HVm),其中黑体数字为最优值。图6 示出了MOEA-HV 算法在测试函数ZDT2、ZDT3、DTLZ2和DTLZ7 上的Pareto 前沿面。

图 5 三维情况下个体独立贡献超体积的计算Fig. 5 Calculation of the individuals’ exclusive hypervolume contributions in three dimension
从表1 中各算法的运行时间均值来看,MOEAHV 的运行效率要远远高于其他基于超体积的典型算法,在IBEA 的基础上提升近两倍,但比NSGA-Ⅲ要慢,究其原因在于NSGA-Ⅲ不需要计算超体积,而对于基于超体积的算法来说,不论采用何种策略、何种计算方法,超体积的时间计算成本仍然非常大。对于基于超体积的算法来说,计算复杂度高是制约算法性能最重要的因素,因此MOEA-HV 最大的突破就是在保持良好收敛性和分布性的同时能有效降低计算复杂度,节约计算超体积的时间成本,提高算法的运行效率。

表 1 各算法运行时间均值Table 1 Mean runtime of each algorithm

表 2 各算法 IGD 均值Table 2 Mean IGD of each algorithm

表 3 各算法 HV 均值Table 3 Mean HV of each algorithm

图 6 MOEA-HV 算法在部分测试函数上的Pareto 前沿面Fig. 6 Pareto fronts of MOEA-HV on some test functions
从表2 和表3 中各算法的IGDm和HVm可以看出,MOEA-HV 的收敛性和分布性要明显优于IBEA,同时与NSGA-Ⅲ结合后算法综合性能与NSGA-Ⅲ相比也更优,与其他算法相比能够取得最优或次优的综合性能,且性能稳定。总体来看,MOEA-HV 在DTLZ 系列测试函数上的性能要优于在ZDT 系列测试函数上的性能,因为加入非支配排序和基于参考点的NSGA-Ⅲ算法后,三维解集中的非支配个体要比二维的多,因此MOEA-HV 的解集在Pareto 前沿面上分布会更加均匀。具体来说,MOEA-HV 在测试函数 ZDT1、ZDT2、ZDT5、ZDT6 和 DTLZ1~DTLZ7上的综合性能最优或次优,说明该算法能够较好地处理具有凹性、多模态、偏好的问题,但在测试函数ZDT3、ZDT4 上性能表现不佳,算法在处理不连续以及多模态混合问题时尚且有待改进,同时测试函数ZDT5 具有欺骗性,导致算法容易陷入局部最优,解的分布性较差,测试函数DTLZ5 和DTLZ6 具有退化性,比较难收敛,因此测试的所有算法在这两个测试函数上表现的收敛性均较差。与其他基于超体积的典型算法相比,MOEA-HV 的运行效率更高,且能够保持较好的收敛性和分布性。
3.1 参数 k 的影响
MOEA-HV 算法是基于IBEA 的框架,其中,适应度值计算函数中的参数k 对算法的综合性能有一定影响,因此有必要对k 的选择进行独立的对比实验,选择使算法表现出最好性能的参数值。设置种群大小为100,迭代次数为500,IBEA 在相同条件下独立运行 10 次,参数 k 分别为 0.030、0.035、0.040、0.045、0.050、0.055、0.060,进行 7 组对比实验,测试函数为 ZDT1~ZDT6和 DTLZ1~DTLZ7,分别比较不同参数下算法IBEA 的运行时间均值、IGDm和HVm,结果如图7 所示。
相同条件下程序的运行时间越短说明算法的运行效率越高。从图7(a)中可以看出参数 k 取0.030时,在 ZDT3、DTLZ1~DTLZ4、DTLZ6 上能够得到最小值, k 取0.035 时运行时间均值也较短,说明参数设置得较小能够在一定程度上节约算法的时间成本,且对于ZDT 系列测试函数来说,运行时间受参数设置影响较小,而对于DTLZ 系列测试函数来说,k取0.030 具有较大优势。从图7(b)可以看出,测试函数ZDT5 的分布性较差,不论参数取何值,其IGDm值都远远超过其他测试函数的IGDm值,因此考虑去掉ZDT5 测试函数来比较不同参数对算法IGDm值的影响。如图 7(c)所示, k 取 0.030 时在 DTLZ1、DTLZ7 上的IGDm值明显小于其他参数的IGDm值,且比较稳定,说明 k 取 0.030 时算法的解集在Pareto 前沿面上分布更加均匀。从图7(d)可以看出k 取 0.030时,算法在测试函数 ZDT3 和 DTLZ1 上的HVm值最大,在其他测试函数上也好于其他参数,且性能稳定,收敛性更好,综上可认为在比较的7 个参数中, k 取0.030时IBEA 的运行效率更高,且具有良好的综合性能,因此为了获得最好的算法性能,MOEA-HV中的参数 k 也取为0.030。

图 7 不同参数 k 对IBEA 运行时间、IGDm 值和HVm 值的影响Fig. 7 Influence of different k on runtime, IGDm and HVm of IBEA
3.2 非支配排序的影响
IBEA 的计算复杂度高,主要原因是需要计算每个个体的独立贡献超体积,而通过Pareto 支配关系对个体进行筛选能够提前删除质量不好的个体从而降低了整个解集中个体的超体积计算量,能够有效提高程序的运行效率。设置种群大小为100,迭代次数为500,在相同条件下独立运行10 次,对在IBEA中是否加入非支配排序进行对比实验以探究非支配排序对算法的影响。实验的测试函数为ZDT1~ZDT6和DTLZ1~DTLZ7,分别比较IBEA 中是否加入非支配排序的运行时间均值、IGDm值和HVm值,如图8所示,其中NDSort+IBEA(Mean)和NDSort+IBEA(Sd)分别表示算法IBEA 加入非支配排序后所获得的平均值以及标准差,而IBEA(Mean)和IBEA(Sd)则表示没有加入非支配排序得到的平均值和标准差。
对于2 个目标的ZDT 系列测试函数来说,计算的超体积为二维的(即面积),比较简单,使得加入非支配排序程序的算法运行时间与IBEA 相近甚至更长。因为加入非支配排序后算法的运行效率更高,但同时算法的程序也更长,导致前者节约的时间与后者所消耗的时间刚好抵消,因此在迭代之后两者的运行时间相近。从图8(a)中可以看出,对于3 个目标的DTLZ 系列测试函数来说,加入非支配排序后算法的运行时间显著降低,是因为三维的超体积更难计算,经过非支配排序之后能有效删除不好的个体,从而大大减少超体积的计算量。同时,从图8(b)、(c)中可以看出,加入非支配排序后算法的性能更加稳定,且能在一定程度上提高算法的综合性能。
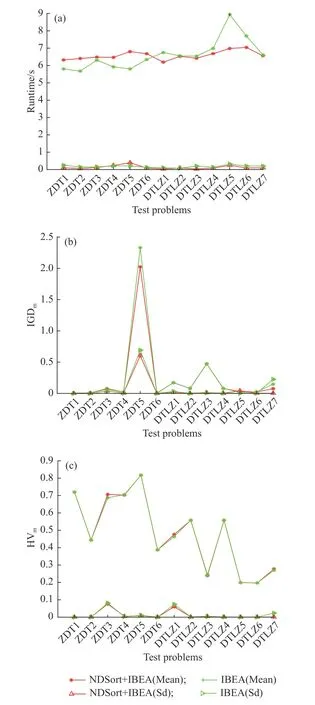
图 8 非支配排序对 IBEA 运行时间均值、IGDm 值和HVm 值的影响Fig. 8 Influence of non-dominated sort on runtime, IGDm and HVm of IBEA
3.3 NSGA-Ⅲ的影响
将IBEA 与NSGA-III 结合能明显改善算法的分布性,但关键在于如何结合,本文主要考虑两种结合方式:一是IBEA 先迭代更新完成获得收敛性较好的种群,然后将获得的该种群作为NSGA-III 的初始种群继续进行迭代优化,以期获得分布性也较好的解(简称 IBEA+NSGA-III);二是先运行 NSGA-III,然后将获得分布均匀的种群作为IBEA 的初始种群,利用超体积指标进化继续增压选择,以期获得综合性能均较好的解(简称NSGA-III+IBEA)。设置种群大小为100,两种结合方式中IBEA 迭代次数均为100,NSGA-III 迭代次数均为500,在相同条件下独立运行10 次,通过实验分析决定何种方式更有利于整合到MOEA-HV 算法中。实验的测试函数为ZDT1~ZDT6 和 DTLZ1~DTLZ7,分别比较 IBEA 与两种不同结合方式 IBEA+NSGA-III、NSGA-III+IBEA 的运行时间均值、IGDm值、HVm值和标准差(Standard deviation,Sd),如图 9 所示。
从图9(a)中可以看出,与NSGA-III 结合后算法的运行时间大幅下降,且IBEA+NSGA-III 比其他两者的综合运行时间更短,但从图9(b)的标准差数据来看,NSGA-III+IBEA 比 IBEA+NSGA-III 的运行时间更加稳定,因为算法NSGA-III 的运行速度快,且分布性好,所获得的初始种群较好,因此第2 种结合方式(NSGA-Ⅲ+IBEA)的运行时间浮动更小、更稳定。图 9(c)~(f)表明 IBEA+NSGA-III 在所有测试函数上的IGDm值最小、HVm值最大,性能最稳定,且在ZDT5、DTLZ1 和 DTLZ3 测试函数上要明显优于NSGA-III+IBEA,因此本文的组合算法选择IBEA+NSGA-III 结合方式。

图 9 NSGA-Ⅲ对IBEA 运行时间、IGDm 值和HVm 值的影响Fig. 9 Influence of NSGA-Ⅲ on runtime, IGDm and HVm of NSGA-Ⅲ
4 结 论
针对二维和三维的多目标优化问题,本文提出了一种基于超体积指标的多目标进化算法(MOEAHV)。利用分治递归思想的切片法精确计算种群中个体的独立贡献超体积来指导种群进化,通过在IBEA 前对所有种群个体进行非支配排序提前删除被支配的个体,从而减少个体独立贡献超体积的计算量来提升运行效率,同时通过与NSGA-Ⅲ结合来优化算法的分布性,主要有3 点改进之处:(1)设计对比实验选择更好的参数;(2)通过非支配排序提前删除不好的个体,能有效节约计算超体积的时间成本;(3)与NSGA-Ⅲ结合来优化算法的分布性。
在今后的研究中,考虑将算法MOEA-HV 应用于解决焊接机器人多目标路径规划问题和更高维的问题,并会继续研究精确计算和近似估计超体积的方法,更加有效地提升算法的运行效率,同时结合其他的优化策略持续改善算法的综合性能。
猜你喜欢
太原科技大学学报(2022年1期)2022-02-24
计算机仿真(2021年1期)2021-11-18
意林(2021年9期)2021-05-28
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
东北大学学报(自然科学版)(2020年1期)2020-02-15
时代风采(2019年3期)2019-03-23
时代英语·高一(2019年1期)2019-03-13
小天使·一年级语数英综合(2019年2期)2019-01-10
物联网技术(2017年5期)2017-06-03
