
一种基于k近邻的密度峰值聚类算法
2020-12-24 08:01罗军锋锁志海郭倩
软件 2020年7期
罗军锋 锁志海 郭倩

摘 要: 密度峰值聚类算法(DPC算法)虽然具有简单高效的优点,但存在着需要人为确定截断距离的不足,从而造成聚类结果出现不准确。为解决这一问题,本文提出了一种基于K近邻的改进算法。该算法引入信息熵,采用属性加权的距离公式进行聚类,这样就解决了不同属性的权重影响问题;在聚类过程中通过计算数据点的近邻密度,再利用KNN近邻算法实现自动求解截断距离,据此得到聚类中心再进行聚类,通过实验证明,该算法在准确性、运行效率上均有不同程度的提升。
关键词: 聚类;密度峰值;局部密度;聚类中心;信息熵;K近邻;截断距离;相对距离
中图分类号: TP311 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.07.037
本文著录格式:罗军锋,锁志海,郭倩. 一种基于k近邻的密度峰值聚类算法[J]. 软件,2020,41(07):185-188
A Peak Density Clustering Algorithm Based on K-nearest Neighbor
LUO Jun-feng, SUO Zhi-hai, GOU Qian*
(Net&Information center, xian jiaotong University, Xian 710049, China)
【Abstract】: Although DPC algorithm is simple and efficient, it needs to determine the truncation distance manually, which results in inaccurate clustering results. To solve this problem, an improved algorithm based on K-nearest neighbor is proposed. In this algorithm, information entropy is introduced, and attribute weighted distance formula is used to cluster, which solves the problem of weight influence of different attributes. In the process of clustering, the nearest neighbor density of data points is calculated, and then KNN algorithm is used to automatically solve the truncation distance, and then clustering is obtaine.
【Key words】: Clustering; Density peak; Local density; Clustering center; Information entropy; K-nearest-neighbor; Truncation distance; Relative distance
0 引言
聚類是数据挖掘中重要的课题之一。它是将目标数据对象分组为由类似的对象组成的多个族的过程。其目标是同一个族的对象是最大可能的相似,不同族的对象最大可能的不相似。
2014年6月,ARodriguez 和Laio等提出了一种新型密度峰值聚类算法(Density Peaks Clustering,DPC)[1],这个算法的主要优势在于其的算法简单又高效、所需参数少、能解决各种形状的簇聚合等。因此该算法得到研究者广泛关注,已经在多个领域 得到成功应用,但DPC算法还存在某些缺点:如需要人工输入截断距离、需要依据决策图人工选取聚类中心这两个关键不足。
针对DPC算法的改进,研究者提出了许多的改进方法:贾培灵等[2]针对某个类存在多个密度峰值导致聚类不理想问题,提出一种基于簇边界划分的 DPC 算法,来解决多个密度峰值问题导致的聚类不理想问题;薛小娜等[3]提出了结合k近邻来改进密度峰值聚类算法;WangSL等[4]提出了一种利用数据场的潜在熵来自动提取最优值的新方法;Mehmood R等[5]提出了一种采用非参数估计给定数据集的概率分布,对截断距离的选择进行校正。
目前,DPC算法研究虽取得了一定的成效,但截断距离需要人工输入、簇心选取及未分配点分配准确率仍然不高,针对这些问题,因此本文提出一种基于K近邻的密度峰值聚类算法,引入距离信息熵,自动计算截断距离,优化了聚类中心点的选择算法. 通过实验证明,该算法具有更好的聚类效果和聚类准确率.
1 DPC算法
密度峰值聚类算法[6-11]是基于以下两个重要原理:(1)其聚类中心的密度高于其邻近的样本点密度;(2)聚类中心与比其密度高的数据点的距离相对较远。
DPC算法的具体步骤描述如下:
步骤1 根据上述公式和输入的参数截断距离分别计算所有数据点的局部密度和相对距离;生成关系决策图;
步骤2 根据关系决策图手动选取聚类中心点。
步骤3 将其他数据点按照距离最近原则分配到对应的聚类中心点。。
步骤4 对聚类结果进行除噪处理,最后完成聚类。
从上述算法描述中可以看到,参数![]() 对算法的聚类效果影响很大,同时算法在聚类过程中,没有考虑到数据点属性间的权重问题,这样会造成聚类效果出现偏差,本文就是试图改进DPC算法中的距离公式,同时引入基于k近邻的
对算法的聚类效果影响很大,同时算法在聚类过程中,没有考虑到数据点属性间的权重问题,这样会造成聚类效果出现偏差,本文就是试图改进DPC算法中的距离公式,同时引入基于k近邻的![]() 的计算方法,以达到改善聚类效果的目的。
的计算方法,以达到改善聚类效果的目的。
2 基于K近邻的密度峰值聚类算法(KDPC)
本文针对DPC算法的改进主要包括:引入距离熵,改善距离计算公式;借鉴文献[11]中的思想引入K近邻,来计算截断距离。下面从算法的基本概念,思想,步骤等分别加以描述。
2.1 算法基本概念
定义1 对象p的k距离
对于任意一个正整数k,数据对象p的k距离我们记作k-distance (p).
在数据集D中, 数据对象o距离数据对象p之间的距离,我们记为:d(p,o)。
当同时满足以下条件时,k-dist(p)等于d(p,o):
(1)至少存在k个数据对象满足
(2)至多存在k-1个数据对象满足
定义2 对象p的k近邻邻居
如果已知数据对象p的k距离,那么,数据对象p的k近邻邻居则就为数据集中所有到p的距离小于等于k的数据对象的集合,定义如下:![]()
![]()
定义3 对象p关于对象o的近邻距离
假设d(p,o)表示数据对象d和数据对象o之间的距离,那么对象p关于对象o的近邻距离计表示为:
定义4基于k近邻的截断距离如下:
2.2 算法的思想
首先为提高算法聚类的效果,我们对数据集中计算数据对象距离时采用加权距离,权重值的计算使用信息熵来确定。
其次,我们引入K近邻以此来计选截断距离,以防止认为指定的不足。
下面是算法的详细介绍。
一般来说,数据集中的各维属性对聚类结果的影响程度肯定不同。于是,本文借鉴文献[12],引入信息熵的概念以度量属性权重的大小,并进一步求得数据对象之间的权重系数,最终得到基于熵权重的距离计算公式。
具体步骤如下:
(1)假設某个数据集X有以下属性值矩阵,不失一般性,其具有n个对象,m维属性:
(2)构造属性对应的比重矩阵
由于属性值单位的不同无法直接比较,为了方便比较,我们对属性值进行了归一化处理。处理方法如下:
从上述公式中可以得出,相邻数据对象的权重系数取决于该对象的所有属性,由其所有邻居的属性共同决定的,因此,在接下来计算数据对象间的距离时就尽最大可能、最大限度的考虑了相邻数据对象之间的相互影响及其自身所有属性的影响。
根据以上分析,最终不难得出,基于信息熵的加权距离计算公式为:
利用改进的距离计算公式可以更为准确的计算出各个数据对象之间的差距程度,在一定程度上提高了聚类的精确度。
2.3 算法步骤
改进后的算法分三大步骤:
(1)根据公式3的加权距离公式来计算所有数据点的近邻密度距离矩阵;
(2)根据公式1计算截断距离;
(3)计算局部密度![]() 和相对距离,同时进行归一化处理后生成关系决策图;
和相对距离,同时进行归一化处理后生成关系决策图;
(4)确定聚类中心数量及聚类中心;
(5)按密度的降序对其余数据点进行分配。
3 实验结果与分析
为了验证本算法的性能,我们分别在人工数据集和UCI数据集上进行了对比实验。
3.1 人工数据集实验结果分析
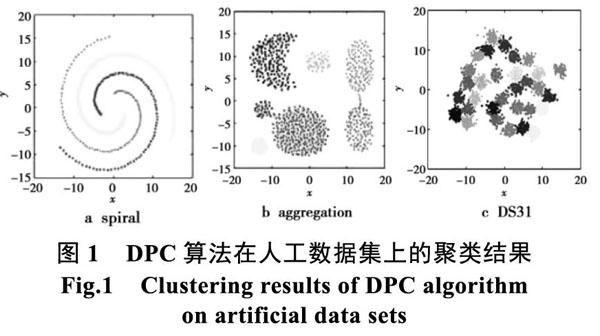
在我们的仿真实验中,使用的数据集为如表1所示,实验的最终效果如图1所示。
图1为DPC算法在人工数据集上的聚类结果,图2为KDPC 算法在人工数据集上的聚类结果。从结果上看,DPC 算法要得到理想状态下的聚类结果,需要人工的多次尝试,这是因为截断距离的合适与否直接影响聚类的效果,因此算法不够稳定。而KDPC算法,自动解决截断距离的计算问题,能够较快的得到理想的聚类效果。
上述实验证明, KDPC算法避免了 DPC 算法需要手动经验选取合适的截断距离的不足, 能够更准确地选取数据集的聚类中心。
3.2 UCI数据集实验结果分析
实验二选取UCI机器学习数据库中的Test,Wine,Seeds作为实验数据。
实验方法:分别采用DPC算法,本文算法进行实验。
实验指标:采用调整兰德系数(adjusted rand index)ARI聚类评价指标[13-14],该指标结果值在[-1,1]之间,值越大说明聚类效果越好,其计算公式为:
3.3 RI表示兰德系数
实验结果:由于传统的k-means算法对初始点的选取比较敏感,初始聚类中心的随机性导致聚类准确率不稳定,因此采用运算8次后所求的平均准确率来判断,实验结果的精确度如表2所示。
从表中可以看到,改进后的DPC算法准确度比传统算法提高了接近10个百分点。
4 结束语
本文针对DPC算法的不足,引入信息熵,采用属性加权的距离公式进行聚类,这样就解决了不同属性的权重影响问题;在聚类过程中通过计算数据点的近邻密度,再利用KNN近邻算法实现自动求解截断距离,据此得到聚类中心再进行聚类,通过实验证明,该算法在准确性、运行效率上均有不同程度的提升。
参考文献
-
Rodriguez A, Laio A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 492-1496.
-
贾培灵, 樊建聪, 彭延军. 一种基于簇边界的密度峰值点快速搜索聚类算法[J]. 南京大学学报(自然科学), 2017, 53(2): 368-377 .
-
薛小娜, 高淑萍, 彭弘铭, 等. 结合K近邻的改进密度峰值聚类算法[J]. 计算机工程与应用, 2018, 54(7): 36-43.
-
Wang S L, Wang D K, Li CY et al. Clustering by fast search and find of density peaks with data field[J]. chinese Journal of Elec-tronics, 2015, 25(3): 397-402.
-
Mehmood R, Bie R, Dawood H, et al. Fuzzy clustering by fast search and find of density peaks[C]//International Conference on Identification, Information and Knowledge in the Internet of Things( IIKI), Beijing, China, 2016: 258-261.
-
趙燕伟, 朱芬, 桂方志, 等. 融合可拓关联函数的密度峰值聚类算法[J]. 小型微型计算机系统, 2019, 12(12): 2512-2518.
-
丁志成, 葛洪伟, 周竞. 基于KL散度的密度峰值聚类算法[J]. 重庆邮电大学学报, 2019, 31(3): 367-374.
-
王万良, 吴菲, 吕闯。自动确定聚类中心的快速搜索和发现密度峰值的聚类算法[J]. 模式识别与人工智能, 2019, 32(11): 1032-1041.
-
王军华, 李建军, 李俊山, 等. 自适应快速搜索密度峰值聚类算法[J]. 计算机工程与应用. 2019, 55(24): 122-127.
-
王洋, 张桂珠. 自动确定聚类中心的密度峰值算法[J]. 计算机工程与应用, 2018, 54(8): 137-142.
-
伏坤, 王珣, 刘勇, 等. 基于K近邻改进密度峰值聚类分析法的岩体结构面产状优势分组[J]. 水利水电技术, 2019, 50(11): 124-130.
-
唐波. 改进的K-means 聚类算法及应用[J]. 软件, 2012, 3: 036.
-
Vinh N X.Epps J.Bailey J.Information theoretic measures for clusterings comparison: Is a correction for chance necessary[C]// Proc of the 26th Annual International Conference on Machine Learning. New York: ACM Press, 2009: 1073-1080.
-
Vinh N X.Epps J, Bailey J.Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance[J]. Journal of Machine Learning Research, 2010, 11(1): 2837-2854.
猜你喜欢
少先队活动(2022年9期)2022-11-23
军民两用技术与产品(2022年1期)2022-06-01
电子测试(2017年15期)2017-12-18
电子测试(2017年12期)2017-12-18
雷达学报(2017年6期)2017-03-26
雷达学报(2017年6期)2017-03-26
通信电源技术(2016年6期)2016-04-20
通信电源技术(2016年5期)2016-03-22
池州学院学报(2015年3期)2016-01-05
电子设计工程(2015年6期)2015-02-27
