
基于Stacking集成学习的流失用户预测方法
2021-01-04 06:23金永红程云辉
应用科学学报 2020年6期
郑 红,叶 成,金永红,程云辉
1.华东理工大学信息科学与工程学院,上海200237
2.上海师范大学商学院,上海200234
互联网的高速发展摧生了互联网应用市场的繁荣,也使互联网行业的竞争愈发激烈.客户的消费行为是企业获利的重要渠道,用户群体越大,企业获利的空间越大[1].当用户流失的速度低于获取新客的速度时,用户量呈增加状态.研究表明,吸引一个新用户的成本是维护一个老用户成本的4 至5 倍[2],如果用户留存率提高5%,利润率将提高25%[3].
用户流失现象可以解释为在一段时间内用户从当前平台转移到其他平台的现象[4].大量的用户流失,不仅会影响企业盈利,而且也会带来一系列的负面影响,比如:损害公司估值、使企业市场规模缩水、伤害企业信誉和影响市场情绪、与同行竞争中处于下风等.因此,提前预测可能的流失用户并及时发出用户流失预警对降低用户流失率具有重要的现实意义.
流失用户预测问题本质上是将用户分类成流失和留存两种类别的问题[5].国内外学者提出了许多方法试图提高流失用户预测准确率,如决策树、支持向量机(support vector machine,SVM)、聚类算法以及人工神经网络等.文献[6]通过对电信行业用户流失的研究,提出了一个基于决策树和逻辑回归比较的统计生存分析工具进行用户流失预测.文献[7]基于逻辑回归模型,通过对电子商务客户流失行为的研究,建立了电子商务用户流失预测模型.文献[8]利用K-means 聚类算法探究了电信行业用户细分及其在实际营销中的作用.文献[9]提出了一种基于支持向量机的客户关系管理规则提取方法,并在银行信用卡客户流失预测数据集中进行测试,实验结果表明所提出的方法优于其他测试方法.文献[10]通过贝叶斯网络对电信行业的流失用户进行预测可知,用户通话时间与用户流失有很大关系.文献[11]利用卷积神经网络(convolutional neural networks, CNN)来预测客户流失,并在测试集中取得了较高的AUC(area under ROC curve)得分.文献[12]将客户行为看作是一种时序行为,从而利用长短期记忆网络(long short-term memory, LSTM)进行用户流失预测,所得实验结果与随机森林算法相当,且优于逻辑回归算法.
在上述流失用户预测方法中,大多只使用了单一的分类模型,或者是不同模型之间的简单融合,而没有进行过多的优化.受随机森林自助采样法的启发,本文提出一种基于自助采样法的Stacking 集成算法(bootstrap sampling stacking, BS-Stacking).实验结果表明,该集成算法相对于简单集成方法具有更高的流失用户预测准确率.
1 集成学习常用算法
1.1 Boosting 算法
Boosting 算法的主要思想是将弱分类器提升为强分类器.Adaboost 算法是Boosting 最具代表性的算法之一,它允许不断加入新的弱分类器并要求弱分类器在性能上至少要优于随机猜想,直到满足规定的训练误差值为止.Adaboost 算法在开始训练时为每一个训练样本赋予相同的权重,该权重表示被某一个分类器选中并进入其训练集的概率大小.如果某一个训练样本被准确分类,那么它在下一轮的分类器构造中被选中的概率就会降低;反之,如果它被错误分类,那么它在下一轮的分类器构造中被选中的概率就会变大[13-14].算法步骤如下:
步骤1训练数据集D={xi,yi}(i=1,···,n),初始化训练数据权值分布,W1(i)=1/n,i=1,2,3,···,n,训练k轮;
步骤2使用按权重Wk(i)采样的数据训练弱分类器Ck,Ck表示第k轮训练得到的分类器;
步骤3计算Ck在训练数据集上的分类误差Ek=P(Ck(xi yi));
步骤4计算Ck(x)的系数αk=12ln[(1−Ek)/Ek];
步骤5更新训练集数据的权重,即

步骤6最终的判决结果由各个分类器加权得到,即
Boosting 算法的基分类器具有训练顺序的相关性,因此只可以串行训练,从而导致其训练速度较慢.
1.2 Bagging 算法
Bagging 算法即装袋法,其典型代表为随机森林算法.随机森林算法通常选择CART 决策树作为基分类器,通过对样本进行自助采样来训练基分类器,最终的预测结果由所有基分类器投票决定[15].随机森林算法的流程如图1所示.

图1 随机森林算法流程Figure 1 Process of random forest algorithm
在样本层面,随机森林算法通过自助采样法对数据集进行样本子集的随机选取,从而实现样本扰动,增加基分类器的差异性;随后对属性进行随机选择,选择出一个包含N个属性的集合以增加属性扰动.这种做法减少了基分类器间的相关性,提高了算法抗噪声能力和鲁棒性.另外,随机森林算法的基分类器训练顺序没有相关性,因此可以进行并行训练,从而可以缩短训练时间.
1.3 Stacking 集成学习算法
Stacking 集成学习方法最初由Wolpert 于1992年提出[16].它与Bagging 和Boosting 集成方法不同,后两种方法只可以集成同种分类器,而Stacking 集成可以集成异构的分类器.假设有数据集D={xi,yi}(i=1,···,n),其中xi代表一个样本,yi表示样本xi的类别标签,则Stacking 可以用以下2 个步骤描述:
步骤1基于数据集分别训练基模型BM=(BM1, BM2,..., BMT);
步骤2将基模型的输出y(i,t)(i=1,···,n;t=1,···,T)组成的新的数据集作为元分类器(meta model, MM)的输入.
Stacking 集成通常为两层,有时也有多层的情况,但是多层Stacking 一般较为复杂且在实际情况中较少使用.为了防止过拟合情况的发生,在训练基模型时还会结合交叉验证.图2给出了经典Stacking 集成的框架图.
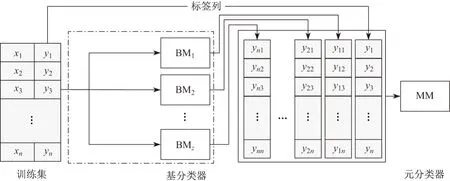
图2 Stacking 集成框架Figure 2 Framework of Stacking ensemble
1.4 BS-Stacking 算法
受随机森林算法提升分类准确率方法的启发,本文改进了经典Stacking 集成方法,提出了BS-Stacking 模型.对Stacking 算法中的每一个基分类器BM 进行T次拷贝,使用自助采样法并加入属性扰动得到T个数据子集,分别对基分类器的副本进行训练,该基分类器的最终预测结果由该基分类器的所有副本投票决定.本文所采用的基分类器有SVM、LDA、AdaBoost、KNN、Native-Bayes,元分类器为逻辑斯蒂回归(logistic regression,LR).基于bagging 的随机森林算法同样会对样本进行采样,如果将随机森林也作为一个基分类器,将会发生随机森林的基分类器会在已采样的样本子集上再次采样的情况,因此不再将随机森林作为基分类器.
BS-Stacking 算法
输入训练集数据Dn×m={(x1,y1),(x2,y2),···,(xn,yn)};
基分类器BM1, BM2,···, BMT;
次级学习算法MM;
参数如下:
MS 表示最大样本采样比例(maximum sample)∈(0,1];
MF 表示最大属性采样比例(maximum feature)∈(0,1];
S表示基分类器副本数量;
过程如下:

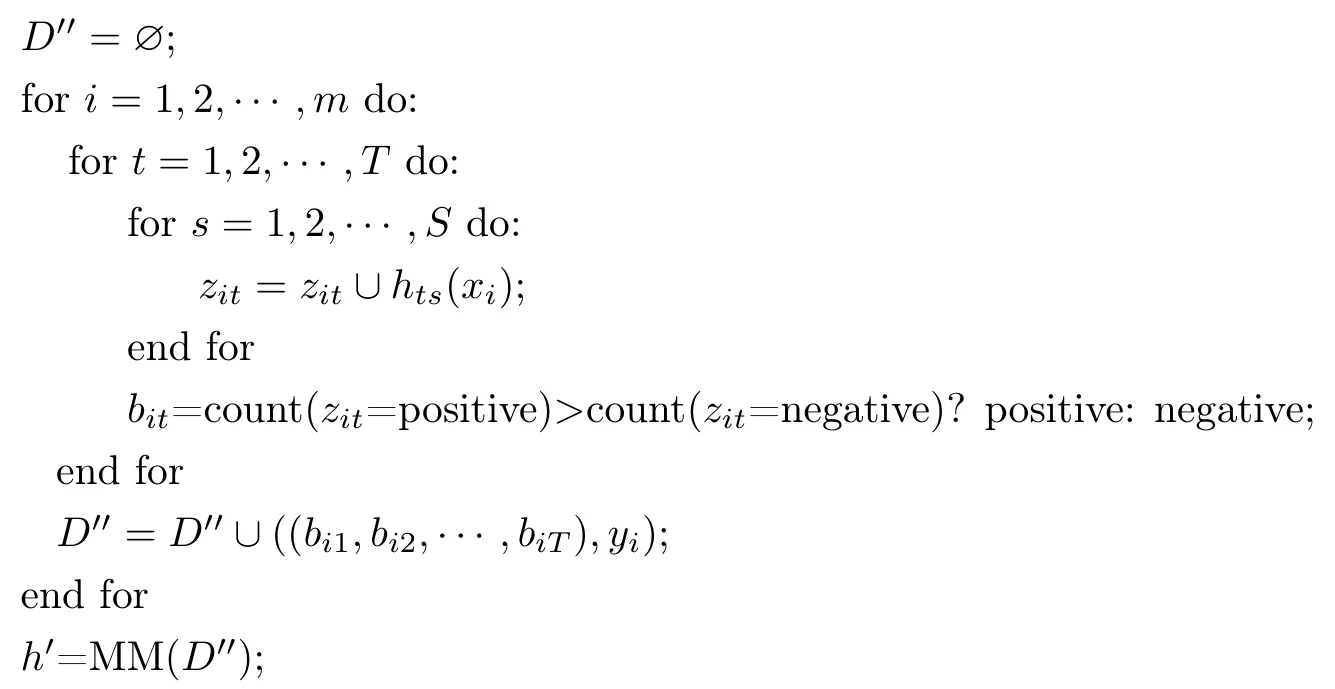
输出
第1 行计算了在采样过程中样本子集的样本数和属性数,当MF 和MS 都取1 时,BSStacking 退化成经典的Stacking 算法.
第2~7 行实现了对样本的随机采样并训练基分类器的副本.
第9~16 行完成了在基分类器副本的预测结果中使用投票得到该样本的预测过程,其结果可作为元分类器的训练集.
第18 行是以基分类器的预测结果训练元分类器,并得到最终训练模型的过程.
BS-Stacking 对数据集做自助采样并训练对应基分类器的副本,当数据集的样本数和维度过小时,都不利于对数据的采样,所以BS-Stacking 更适合于数据集足够大且数据维度够高的情况.
2 数据准备与评价指标
2.1 问题描述
本文目的是预测未来7 d(天)内的流失用户,这是一个二分类问题,即将当前用户分为留存用户和流失用户.用户是否流失可以通过分析用户行为数据来确定.流失用户由留存用户转化而来,但留存用户通常不会突然变为流失用户.对于大多数用户来说,期间一般会有一个平滑的过渡过程,这个用户群体可以称为具有流失倾向的用户.这3 个用户群体在时间轴上的活动规律是不同的,表现为留存用户有连续的活动记录,有流失倾向的用户一般正处于兴趣衰退阶段,活动频率逐渐开始降低,直到不再活动、完全流失为止.基于这个特点,本文可以确定用户的标签,具体过程如下:
设p为某一时间节点,[1,q]区间为用户活动区间,[p+1,p+7]为标签区间.在用户活动区间内注册的用户集合为R,在标签区间内所有存在活动记录的用户集合为A,则用户类别标签的计算公式为

即根据某一个时间节点T开始至此后7 d 内用户有无活动记录来确定用户是否为流失用户,若在活动区间内注册的用户在标签区间内有活动记录则该用户为留存用户;若无活动记录,则该用户记为流失用户.
2.2 数据集处理
2.2.1 数据集描述
本文选用的数据集来源于国内某视频APP 公司.数据为用户行为数据,由4 个日志文件构成,其数据描述和字段信息如表1所示.

表1 实验所用的数据集文件Table 1 Dataset used in the experiment
数据集共包含30 d 的用户数据,不包括在开始时间节点之前注册的用户.日期按照1∼30 进行编码,所有属性类型均为数值型.注册方式有手机号注册、微信注册、微博注册等;注册设备有手机、电脑、平板电脑等;活动类型有点赞、评论、转发等.
2.2.2 数据集扩充
数据集为一个月内所有用户的行为数据,共51 709 条.利用2.1 节中的规则判断用户标签,第24∼30 d 的数据无法判断是否流失,因此可用的数据为1∼23 d,样本数量为37 456 条.可采用类滑动窗口的方法来增加数据量,具体过程如图3所示.

图3 窗口滑动过程Figure 3 Window sliding process
下面以滑窗1 为例说明类别标签判定过程.设置滑窗1 的窗宽为7,区间为1∼7 d,标签区间为8∼14 d.在滑窗区间内注册的用户如果在标签区间内有活动记录,则该用记为活跃用户;每一个滑窗都是一个单独的特征构造过程,互不影响.滑窗4 的区间为1∼23 d,标签区间为23∼30 d.经过滑窗处理后,总的数据集数据量为4 个滑窗的数据量之和,相比于滑窗处理前,数据量增加至94 059 条.
初始窗宽和滑动步长可以有多种选择,但是滑动步长不宜太大或太小:太大会导致滑动次数减少,数据量得不到有效扩充;滑动步长太小会导致滑动过密,数据之间的区分度变小,影响最后的预测准确率.
2.2.3 特征提取
特征提取阶段的主要原则是所提取的特征要有实际含义.特征提取的主要方式有以下3 点:
1)用户活动时间间隔,包括应用启动时间间隔、互动时间间隔、视频上传时间间隔等;
2)用户最后一次活动(应用启动、视频上传、互动点赞、转发等)与当前时间节点的差值;
3)用户的注册时间是否在周末.
从直观上来说,用户的活动间隔是描述用户活跃程度的最好特征,活动间隔越大表示用户越不活跃,流失的可能性越大;相反,用户的活动间隔越小则表示用户活动频繁,流失可能性较小.考虑到用户的活动具有一定黏性,所以用户最后一次活动时间与当前时间的差值可以用来描述用户活动的黏性,差值越大说明黏性越小,用户再次活动的可能性也越小;反之,则很有可能会再次活动.经过对数据的统计发现,在周末注册的用户比在工作日注册的用户平均每天少活动34.9 次,可见用户的注册时间与用户的活跃程度有一定的相关性.
2.3 特征选择
特征选择的主要目的是过滤冗余特征、构造效率更高且消耗更低的预测模型[10].本文采用方差过滤的方式进行特征选择,提前过滤方差较小的特征.方差对于特征的取值范围比较敏感,因此在进行特征选择之前需要对数据进行归一化,将数据统一映射到[0,1]区间上.数据归一化x∗和方差s2的计算公式分别为

式中,M为样本平均数,n为样本数量.
2.4 评价指标
本文旨在用户群体中准确识别有流失倾向的用户,预测用户是流失用户还是留存用户是一个典型的二分类问题.二分类问题的混淆矩阵如表2所示.
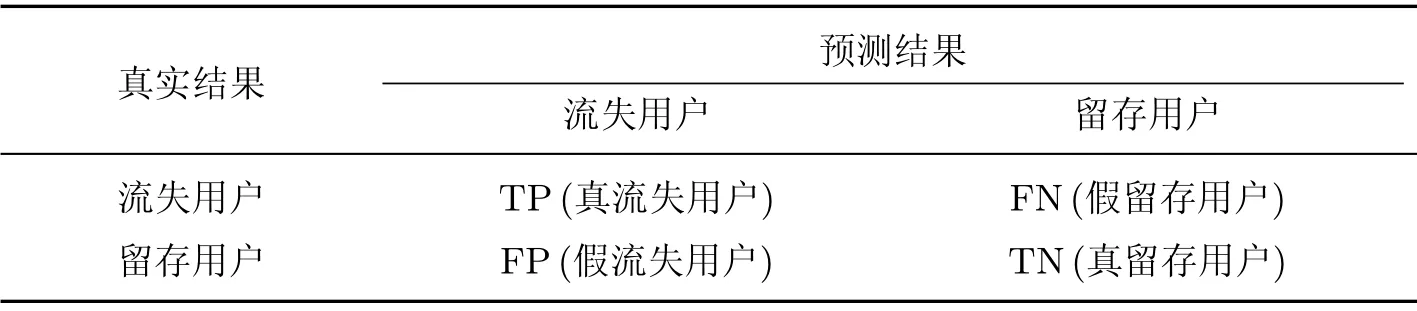
表2 分类结果混淆矩阵Table 2 Confusion matrix of classification results
实验中,模型结果采用准确率、查准率、查全率和流失用户的F1 值作为评价指标.准确率是模型预测正确的样本数量与所有样本数量的比值;在流失预测模型中,与留存用户相比,本文更加关注流失用户,因此查全率是一个重要的指标.但是如果只关注查全率而不关注查准率有可能会使模型的结果变得虚高.一般来说,查准率和查全率是一对相互矛盾的量,若一个升高,则另一个就会下降.F1 值是P和R的调和平均值[17],可以更全面地评价模型的效果.
准确率A定义为

查全率(召回率)R定义为

查准率(精确率)P定义为

F1 值定义为

3 实验与结果分析
本次实验使用的数据是用户一个月的行为数据.特征构造后共产生174 维特征,样本数量为94 059 条.采用过滤式的低方差筛选方式进行特征选择,方差阈值设置为0.001,低于阈值的特征将被删除.特征选择后数据降为104 维.同时,将数据集按2∶1 的比例随机切分为训练集和验证集,用来验证模型的分类效果.
3.1 模型参数调整
合适的参数值选择会使得模型具有更高的分类准确率.BS-Stacking 有3 个超参数,分别为最大样本采样比例MS、最大特征采样比例MF 以及基分类器副本数量S.调参方法采用GridSearchCV(网格调参法),交叉验证为5 折.网格调参会重复构建模型,以确定合适的模型参数.因此,当参数候选值过多或数据量大时,网格调参往往效率不高.在BS-Stacking 模型中,MS 和MF 有固定的取值范围(0,1],而基分类器副本数量S的取值范围较大,3 个参数同时用网格调参会使得调参过程非常缓慢.为了避免这种情况,将调参过程分为两步:
步骤1固定S的值,找到使BS-Stacking 具有最高分类准确率时的MF 和MS 的取值;
步骤2固定MF 和MS 的值,比较S取不同值时模型的分类准确率.S取分类正确率最高时的值.
这种方法的优点是可以加快参数搜索过程,快速得到合适参数值;缺点是找到的参数组合是局部最优组合,而不是全局最优组合.
在步骤1 中,将S的初始值设置为21(奇数是为了防止在投票过程中出现流失与非流失票数相同的情况).MS 和MF 的取值范围均为0.1∼0.9,每次增加0.1.此时的模型最优参数如下:MS 取值为0.1,MF取值为0.3,S取值为21.
在步骤2 中,固定MS 和MF,S取值范围定为3∼60,每次增加2 个分类器副本,使用网格搜索寻找最佳S的值.当给定最大样本和最大特征取样比例时,模型正确率随基分类器副本数量变化的折线图如图4所示.前期副本数量较少时模型的正确率不高,随着副本数量的增加,模型的正确率也随之增加;当副本数达到27 时,模型的分类正确率达到最高;随后副本数量增加,基分类器对数据的采样逐渐接近于样本全集,模型的正确率趋于平衡.
经过网格调参后,BS-Stacking 在预测流失用户中最优的超参数如下:MS 取值为0.1,MF 取值为0.3,S取值为27,准确率为0.812.

图4 基分类器副本数量与分类正确率的变化Figure 4 Trend of classification accuracy with number of base classifier’s copies
3.2 分类器分类效果比较
集成学习的目的是通过一定的策略集合各个分类器的优势,达到博采众长、提高分类效率的目的,因此集成后的分类效果应好于单个基分类器的分类效果,否则就是没有意义的集成.本节将比较BS-Stacking、经典Stacking 以及所有基分类器、决策树、随机森林、聚类方法、神经网络在验证集上的表现,比较指标为2.4 节中的准确率、查准率、查全率和流失用户的F1值.
表3给出了各个分类模型的得分.其中经典Stacking 集成方法在测试集中的得分比其最好的基分类器在F1度量上差0.3%,可见集成后分类效果没有提升,造成这种情况的一种可能是:基分类在训练集中对某些相同的样本均分类错误,使元分类器在错误的数据中训练,从而导致最后样本的分类错误.实验结果表明,BS-Stacking 具有较高的分类准确率及流失用户的F1值得分.在基分类器中,Logistic Regression、SVC 和AdaBoost 具有相近的得分,其中得分最高的为Logistic Regression.BS-Stacking 与Logistic Regression 相比,F1值提高0.8%,准确率提高0.2%;与经典Stacking 相比,F1值提高1.1%,准确率提高0.4%;与LSTM 相比,F1值提高0.5%,准确率提高0.4%.BS-Stacking 具有最高的准确率、查准率和F1值,具有最高召回率的是Native Bayes 模型和K-Means 模型,但是这两个模型的查准率远低于其他模型.

表3 分类结果比较Table 3 Comparison of classification results
4 结 语
本文针对互联网行业的用户流失预测问题,提出了一种基于自助采法的Stacking 集成学习方法(BS-Stacking).在数据预处理方面,首先利用类滑窗的方式进行数据的扩充,每次滑动都从3 个方面对用户的行为数据进行特征提取,删除方差较小的特征项之后将其他特征作为模型的输入数据.在模型方面,对数据集进行多次的自助采样并加入属性扰动得到多个数据集的子集,使用得到的样本子集训练基分类器的副本,基分类器的最终分类结果由所有的基分类器的副本投票决定.最后将该方法与其他机器学习算法进行比较.
实验结果表明BS-Stacking 的流失用户预测能力优于其他模型,同时也说明针对流失用户的特征提取方法是有效的,从而为企业提前预测流失用户、制定用户留存策略、挽回用户流失提供了新的思路.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
中国交通信息化(2018年5期)2018-08-21
小型微型计算机系统(2018年3期)2018-03-27
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
航天返回与遥感(2014年5期)2014-07-31
